Gọi gióng hàng từ 𝑎𝑗 : 𝑗 → 𝑖 liên kết từ tiếng Anh thứ 𝑗 sang từ tiếng Việt thứ 𝑖 và 𝑎
là tập các liên kết từ tất cả các từ trong câu e
𝑎 = 𝑎1, 𝑎, … 𝑎𝑚
Từ xác suất gióng hàng từ, ta có thể tính được xác suất dịch theo công thức:
𝑝 𝑣 𝑒 = 𝑝 𝑎, 𝑒 𝑣
𝑎
(2.6)
Có thể bạn quan tâm!
-

 Tích hợp thông tin hình thái từ vào hệ dịch máy thống kê Anh-Việt - 1
Tích hợp thông tin hình thái từ vào hệ dịch máy thống kê Anh-Việt - 1 -
 Tích hợp thông tin hình thái từ vào hệ dịch máy thống kê Anh-Việt - 2
Tích hợp thông tin hình thái từ vào hệ dịch máy thống kê Anh-Việt - 2 -
 Mô Hình Dịch Thống Kê Factored (Factored Smt)
Mô Hình Dịch Thống Kê Factored (Factored Smt) -
 Các Hướng Tích Hợp Tri Thức Ngôn Ngữ Vào Dịch Máy Thống Kê
Các Hướng Tích Hợp Tri Thức Ngôn Ngữ Vào Dịch Máy Thống Kê -
 Tích Hợp Thông Tin Cú Pháp Vào Mô Hình Dịch
Tích Hợp Thông Tin Cú Pháp Vào Mô Hình Dịch
Xem toàn bộ 104 trang tài liệu này.
Xác suất gióng hàng từ giữa các từ trong cặp câu, 𝑝 𝑎, 𝑒 𝑣 được tính như sau:
𝑚
𝑝 𝑎, 𝑒 𝑣 = 𝑡 𝑒𝑗𝑣𝑖
𝑗 =1
(2.7)
Trong đó, 𝑡 𝑒𝑗𝑣𝑖được tính dựa trên các gióng hàng từ (ngữ) trong ngữ liệu song ngữ. Tuy nhiên, để tạo ra ngữ liệu gióng hàng từ (ngữ) đòi hỏi rất nhiều công sức cho việc gán nhãn. Do đó, thật toán Expectation Maximization (EM) đã được [24] đề xuất để ước lượng các gióng hàng từ (ngữ) này.
Ý tưởng của thuật toán EM như sau:
Đầu tiên, với mọi cặp câu song ngữ có trong ngữ liệu, ta giả định tất cả các từ trong câu nguồn đều có gióng hàng từ với tất cả các từ trong câu đích, các xác suất gióng hàng từ được khởi tạo giá trị ban đầu như nhau.
… my house … small house … my mobile …
… nhà của tôi … nhà nhỏ … điện_thoại của tôi …
Sau đó, qua mỗi lần lặp, các cặp từ thường gióng hàng với nhau nhất sẽ được xác định.
Liên kết giữa “my” và “của tôi” được xác định:
… my house … small house … my mobile …
… nhà của tôi … nhà nhỏ … điện_thoại của tôi …
Liên kết “house” và “nhà” được xác định:
… my house … small house … my mobile …
… nhà của tôi … nhà nhỏ … điện_thoại của tôi …
Các liên kết khác được xác định:
… my house … small house … my mobile …
… nhà của tôi … nhà nhỏ … điện_thoại của tôi …
Kết quả gióng hàng từ cuối cùng:
… my house … small house … my mobile …
… nhà của tôi … nhà nhỏ … điện_thoại của tôi …
Cuối cùng, các xác suất gióng hàng từ sẽ hội tụ, giá trị không thay đổi nhiều. Khi đó ta được cả hai thông tin là thông tin về gióng hàng từ và giá trị xác suất tương ứng.
Sử dụng thuật toán EM, Stephan Vogel đề ra các mô hình IBM có tên gọi lần lượt là IBM1, IBM2, IBM3, IBM4, IBM5 và Franz-Joseph Och đề ra mô hình 6 để tạo ra gióng hàng từ trên các cặp câu song ngữ.
Hiện tại, công cụ phổ biến nhất để gióng hàng từ là GIZA++. Công cụ này được xây dựng dựa trên các mô hình IBM. Tuy nhiên, công cụ này có hạn chế là chỉ cho phép gióng hàng một từ thuộc ngôn ngữ nguồn với một hoặc nhiều từ thuộc ngôn ngữ đích.
[10] đề xuất cách tiếp cận dựa trên heuristic để cải tiến kết quả gióng hàng từ có được từ GIZA++. Tất cả các điểm nằm trong vùng giao của hai gióng hàng từ sẽ được giữ lại và vùng gióng hàng từ được mở rộng tối đa không vượt quá vùng giao của hai gióng hàng từ.
Đầu tiên, ngữ liệu song ngữ được gióng hàng từ cả hai phía, từ ngôn ngữ nguồn sang ngôn ngữ đích và từ ngôn ngữ đích sang ngôn ngữ nguồn. Quá trình này tạo ra hai gióng hàng từ. Nếu lấy phần giao hai gióng hàng từ này, chúng ta sẽ có gióng hàng từ với độ chính xác cao (high-precision). Ngược lại, nếu lấy phần hợp của hai gióng hàng từ, chúng ta sẽ có gióng hàng từ với độ bao phủ (high-recall) cao.
Hình 2.2 minh họa quá trình này. Trong hình, các điểm nằm trong vùng giao có màu đen, các điểm mở rộng có màu xám.
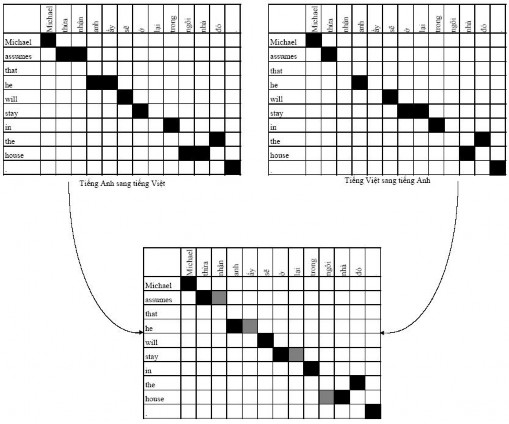
Hình 2.3. Hình minh hoạ quá trình cải tiến gióng hàng từ
2.1.1.3.Quá trình giải mã (decoding)
Nhiệm vụ của của quá trình này là tìm câu dịch thích hợp nhất khi biết câu nguồn.
- Chia câu nguồn thành nhiều từ hoặc cụm từ.
- Tra trong bảng ngữ để tìm các ngữ dịch tương ứng.
- Kết hợp các ngữ tìm được lại thành câu và chọn những câu có xác suất mô hình dịch nhân với xác suất mô hình ngôn ngữ lớn nhất.
2.1.2. Mô hình dịch máy thống kê dựa trên ngữ
Hệ dịch thống kê dựa trên từ có khuyết điểm là không lấy được thông tin ngữ cảnh mà chỉ dựa trên các phân tích thống kê về từ. Mô hình dịch máy thống kê dựa trên ngữ cải tiến hơn ở chỗ thay vì xử lý trên từ thì xử lý trên ngữ. Điều này cho phép hệ thống có thể dịch các cụm từ tránh được dịch word-by-word.
Trong hệ dịch máy thống kê dựa trên ngữ [26], câu ở ngôn ngữ nguồn e được tách
thành nhiều ngữ 𝑒 𝑖
(là một dãy nhiều từ, không nhất thiết phải là ngữ đúng ngữ
pháp, dấu câu cũng được xem như là một từ). Mỗi ngữ 𝑒 𝑖 được dịch thành ngữ
𝑣 𝑖 tương ứng dựa vào phân phối xác suất 𝜙(𝑒𝑖|𝑣 𝑖 ). Sau đó các ngữ 𝑣 𝑖
sẽ được
chuyển đổi trật tự dựa trên mô hình chuyển đổi 𝑑(𝑎𝑖 − 𝑏𝑖−1), với 𝑎𝑖 là vị trí bắt đầu của ngữ 𝑒 𝑖 và 𝑏𝑖−1 là vị trí kết thúc của ngữ 𝑣 𝑖. Do vậy, hệ dịch thống kê trên ngữ sẽ học được các cặp cụm từ song ngữ, đặc biệt là các câu thành ngữ.
Như vậy, câu dịch tốt nhất thoả công thức (2.1) sẽ được viết lại thành:
𝑚
𝑝 𝑒 𝑖𝑣 𝑖= 𝜙(𝑒𝑖|𝑣 𝑖 ) × 𝑑(𝑎𝑖 − 𝑏𝑖−1)
𝑖=1
(2.6)
takes a
small green box
.
chiếc hộp nhỏ màu xanh
.
She
Hình 2.4 minh hoạ quá trình dịch máy thống kê dựa trên ngữ. Câu đầu vào tiếng Anh được tách thành nhiều cụm từ, hay còn gọi là ngữ. Các ngữ được dịch sang ngữ tiếng Việt tương ứng, các ngữ tiếng Việt đầu ra có thể chuyển đổi trật tự trong câu cho phù hợp với tiếng Việt.
Cô ấy
lấy một
Hình 2.4. Ví dụ về dịch thống kê dựa trên ngữ
Do thống kê trên các cặp ngữ, hệ dịch này có thể chuyển đổi trật tự giữa các từ trong ngữ, nhưng vẫn chưa tự động chuyển đổi trật tự các cụm từ ở xa nhau trong câu.
Có nhiều cách khác nhau để rút trích các cặp ngữ từ ngữ liệu song ngữ. [16] đã thử nghiệm 3 phương pháp sau:
i. Lấy ngữ dựa vào kết quả gióng hàng từ
Tác giả sử dụng công cụ GIZA++ để gióng hàng từ trong ngữ liệu song ngữ. Sau đó, Koehn dùng một số heuristic để cải tiến thêm kết quả gióng hàng và lấy toàn bộ các cặp ngữ chứa những từ có liên kết. Khi đó, 𝜙(𝑒𝑖|𝑣 𝑖 ) được tính như sau:
𝜙𝑒 𝑣 = 𝑐𝑜𝑢𝑛𝑡(𝑒 |𝑣 )
ii. Tách ngữ cú pháp
𝑖 𝑖
𝑒 𝑐𝑜𝑢𝑛𝑡(𝑒 |𝑣 )
(2.7)
Trước tiên, tác giả gióng hàng từ cho cặp câu song ngữ, sau đó phân tích cặp câu ra cây cú pháp. Tác giả rút trích các cặp ngữ song ngữ bằng cách lấy chuỗi từ nằm trong cây con của cây cú pháp và có liên kết gióng hàng từ. Xác suất dịch của cặp ngữ được tính tương tự như mô hình trên.
iii. Dùng mô hình kết hợp do Marcu, D. và Wong, W đề xuất: Hình thành ngữ trực tiếp trên ngữ liệu song ngữ
Thông qua các thí nghiệm, tác giả kết luận rằng mô hình dựa trên gióng hàng từ cho kết quả tốt nhất trong 3 mô hình.
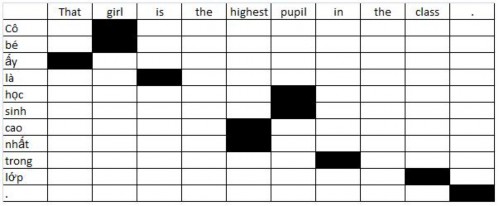
Xét cặp câu song ngữ:
That girl is the highest pupil in the class.
Cô bé đó là học sinh cao nhất trong lớp.
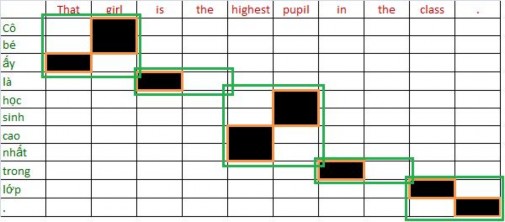
Mô hình rút các cặp ngữ từ kết quả gióng hàng từ sau: Từ kết quả gióng hàng từ của cặp câu:
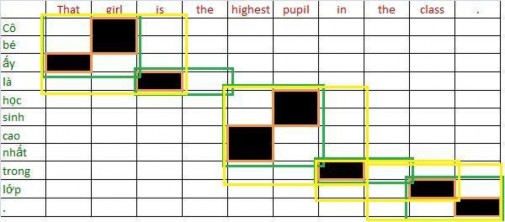
Các cặp ngữ rút ra phải nhất quán như hình (a), những từ có liên kết với từ trong ngữ nguồn thì cũng được đưa vào trong ngữ đích. Cách rút ngữ trong hình (b) là sai vì từ “là” có liên kết với từ “is” nhưng không được đưa vào ngữ.

Ban đầu, ta có thể lấy các ngữ từ các liên kết gióng hàng từ

(That, ấy), (girl, cô bé), (is, là), (highest, cao nhất), (pupil, học sinh), (in, trong), (class, lớp), (., .)
(That, ấy), (girl, Cô bé), (is, là), (highest, cao nhất), (pupil, học sinh), (in, trong), (class, lớp), (., .), (That girl, Cô bé ấy), (is the, là), (highest pupil, học sinh cao nhất), (the class, trong lớp)
(That, ấy), (girl, Cô bé), (is, là), (highest, cao nhất), (pupil, học sinh), (in, trong), (class, lớp), (., .), (That girl, Cô bé ấy), (is the, là), (highest pupil, học sinh cao nhất), (the class, trong lớp), (That girl is, Cô bé ấy là), (highest pupil in, học sinh cao nhất trong), (in the class, trong lớp), (the class . , trong lớp .)
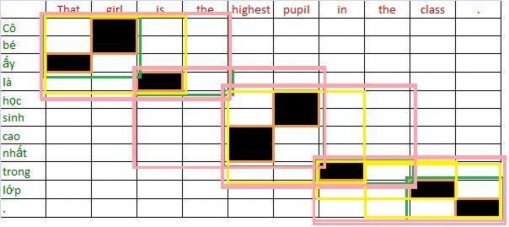
(That, ấy), (girl, Cô bé), (is, là), (highest, cao nhất), (pupil, học sinh), (in, trong), (class, lớp), (., .), (That girl, Cô bé ấy), (is the, là), (highest pupil, học sinh cao nhất), (the class, trong lớp), (That girl is, Cô bé ấy là), (highest pupil in, học sinh cao nhất trong), (in the class, trong lớp), (the class . , trong lớp .), (That girl is the, Cô bé ấy là), (is the highest pupil, là học sinh cao nhất), (highest pupil in the, cao nhất trong), (in the class, trong lớp)