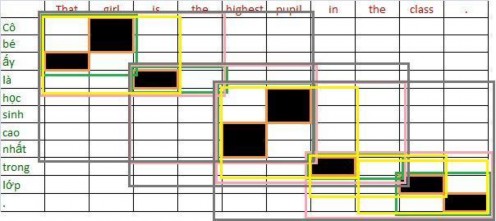
(That, ấy), (girl, Cô bé), (is, là), (highest, cao nhất), (pupil, học sinh), (in, trong), (class, lớp), (., .), (That girl, Cô bé ấy), (is the, là), (highest pupil, học sinh cao nhất), (the class, trong lớp), (That girl is, Cô bé ấy là), (highest pupil in, học sinh cao nhất trong), (in the class, trong lớp), (the class . , trong lớp .), (That girl is the, Cô bé ấy là), (is the highest pupil, là học sinh cao nhất), (highest pupil in the, cao nhất trong), (in the class, trong lớp), (That girl is the highest pupil, Cô bé ấy là học sinh cao nhất), (is the highest pupil in the, là học sinh cao nhất trong), (highest pupil in the class ., học sinh cao nhất trong lớp .)
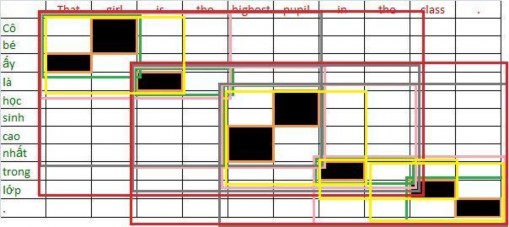
(That, ấy), (girl, Cô bé), (is, là), (highest, cao nhất), (pupil, học sinh), (in, trong), (class, lớp), (., .), (That girl, Cô bé ấy), (is the, là), (highest pupil, học sinh cao nhất), (the class, trong lớp), (That girl is, Cô bé ấy là), (highest pupil in, học sinh cao nhất trong), (in the class, trong lớp), (the class. , trong lớp .), (That girl is the, Cô bé ấy là), (is the highest pupil, là học sinh cao nhất), (highest pupil in the, cao
nhất trong), (in the class, trong lớp), (That girl is the highest pupil, Cô bé ấy là học sinh cao nhất), (is the highest pupil in the, là học sinh cao nhất trong), (highest pupil in the class ., học sinh cao nhất trong lớp .), (That girl is the highest pupil in the, Cô bé ấy là học sinh cao nhất trong), (is the highest pupil in the class ., là học sinh cao nhất trong lớp .)
Có thể bạn quan tâm!
-

 Tích hợp thông tin hình thái từ vào hệ dịch máy thống kê Anh-Việt - 1
Tích hợp thông tin hình thái từ vào hệ dịch máy thống kê Anh-Việt - 1 -
 Tích hợp thông tin hình thái từ vào hệ dịch máy thống kê Anh-Việt - 2
Tích hợp thông tin hình thái từ vào hệ dịch máy thống kê Anh-Việt - 2 -
 Mô Hình Dịch Máy Thống Kê Dựa Trên Ngữ
Mô Hình Dịch Máy Thống Kê Dựa Trên Ngữ -
 Các Hướng Tích Hợp Tri Thức Ngôn Ngữ Vào Dịch Máy Thống Kê
Các Hướng Tích Hợp Tri Thức Ngôn Ngữ Vào Dịch Máy Thống Kê -
 Tích Hợp Thông Tin Cú Pháp Vào Mô Hình Dịch
Tích Hợp Thông Tin Cú Pháp Vào Mô Hình Dịch -
 Thêm Thông Tin Hình Thái Từ Cho Tiếng Anh Và Tiếng Việt
Thêm Thông Tin Hình Thái Từ Cho Tiếng Anh Và Tiếng Việt
Xem toàn bộ 104 trang tài liệu này.
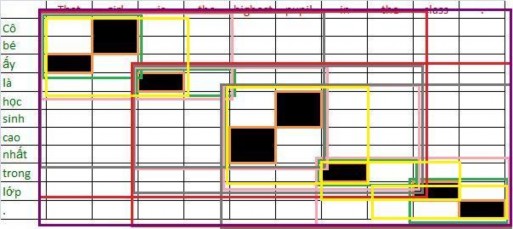
(That, ấy), (girl, Cô bé), (is, là), (highest, cao nhất), (pupil, học sinh), (in, trong), (class, lớp), (., .), (That girl, Cô bé ấy), (is the, là), (highest pupil, học sinh cao nhất), (the class, trong lớp), (That girl is, Cô bé ấy là), (highest pupil in, học sinh cao nhất trong), (in the class, trong lớp), (the class. , trong lớp .), (That girl is the, Cô bé ấy là), (is the highest pupil, là học sinh cao nhất), (highest pupil in the, cao nhất trong), (in the class, trong lớp), (That girl is the highest pupil, Cô bé ấy là học sinh cao nhất), (is the highest pupil in the, là học sinh cao nhất trong), (highest pupil in the class., học sinh cao nhất trong lớp.), (That girl is the highest pupil in the, Cô bé ấy là học sinh cao nhất trong), (is the highest pupil in the class., là học sinh cao nhất trong lớp.) (That girl is the highest pupil in the class ., Cô bé đó là học sinh cao nhất trong lớp .)
Từ các cặp ngữ rút ra được, mô hình dịch dựa trên ngữ sẽ lưu lại bảng ngữ (phrase- table) chứa các cặp ngữ rút ra từ các cặp câu song ngữ cùng với xác suất 𝜙(𝑒𝑖|𝑣 𝑖 ).
2.1.3. Mô hình dịch thống kê factored (Factored SMT)
Một hạn chế của hệ dịch thống kê dựa trên ngữ là vẫn chưa sử dụng thông tin ngôn ngữ vào hệ dịch. Đối với các ngôn ngữ biến đổi hình thái, hệ dịch xem các dạng biến cách như là những từ phân biệt, do hệ dịch chỉ nhận diện bề mặt chữ chứ không có thông tin liên hệ nào giữa các dạng biến cách.
Ví dụ, trong tiếng Anh, houses (những ngôi nhà) là biến cách danh từ số nhiều của house (ngôi nhà). Tuy nhiên, hệ dịch dựa trên ngữ sẽ xem đây là hai từ riêng biệt. Nếu trong quá trình huấn luyện, hệ thống đã gặp từ house nhưng chưa gặp từ houses thì sẽ không dịch được từ này.
Nhóm nghiên cứu của [27] đã đề xuất mô hình dịch factored (đại diện) tích hợp trực tiếp tri thức ngôn ngữ vào mô hình dịch. Mô hình này được phát triển dựa trên cách tiếp cận dịch máy dựa trên ngữ. Cải tiến của mô hình này là các thông tin về tri thức được tích hợp vào hệ thống ở mức độ từ. Một từ trong mô hình này được xem như là một vector đại diện chứa nhiều thông tin khác nhau.
Ví dụ, mỗi từ trong câu nguồn và câu đích có thể thêm các factor: từ nguyên mẫu, từ loại, biến cách
Câu nguồn
Câu đích
![]()
![]()
Từ Từ
![]()
![]()
Nguyên mẫu Nguyên mẫu
Từ loại ![]() Hình thái
Hình thái ![]()
![]() Từ loại Hình thái
Từ loại Hình thái
![]()
Hình 2.5. Mô hình dịch factored SMT
Mô hình này có quá trình huấn luyện và dịch giống mô hình dịch dựa trên trên ngữ. Tuy nhiên, bước tạo mô hình dịch của hệ factored SMT sẽ được chia ra thành ba bước nhỏ.
Ví dụ từ tiếng Đức häuse khi được dịch sang tiếng Anh sẽ được xử lý như sau:
Từ häuse được thêm các thông tin hình thái từ: Từ häuse | nguyên mẫu hause | từ loại NN | số đếm Plural và được dịch theo các bước:
- Dịch từ nguyên mẫu của câu đích sang từ nguyên mẫu của câu đích haus → house, home, building, shell
- Dịch các factor nguyên mẫu, từ loại, hình thái NN|plural → NN|singular, NN|plural
- Phát sinh từ từ kết quả dịch từ nguyên mẫu và các factor house + NN|singular → house|house|NN|singular house + NN|plural → houses|house|NN|singular home + NN|singular → home|home|NN|singular home + NN|plural → homes|home|NN|singular
…
Quá trình dịch từ nguyên mẫu và các factor giống như dịch dựa trên ngữ. Hệ thống sẽ rút các cặp ngữ từ kết quả gióng hàng từ và tính xác suất có điều kiện dựa bằng cách thống kê tầng suất xuất hiện của các ngữ. Ứng với mỗi bước dịch, hệ thống sẽ tạo ra một bảng dịch.
Bước phát sinh chỉ thực hiện trên mức độ từ và xử lý trên câu đích, không liên quan đến kết quả gióng hàng từ.
Trong quá trình giải mã, tìm kiếm câu dịch thích hợp, thay vì chỉ sử dụng một bảng dịch ngữ như mô hình dịch máy dựa trên ngữ, mô hình factored phải sử dụng nhiều bảng, quá trình tính toán cũng phức tạp hơn. Công thức tính xác suất 𝑝 𝑣 𝑒 như sau:
𝑛
𝑝 𝑣 𝑒 = 1 𝑒𝑥𝑝 𝜆 𝑣, 𝑒
𝑍
𝑖=1
𝑖 𝑖
(2.8)
Trong đó, Z là hằng số chuẩn, có thể bỏ qua trong thí nghiệm. Như vậy, để tính xác suất dịch từ câu 𝑒 sang câu 𝑣, ta phải tính từng hàm đặc trưng 𝑖 bao gồm hàm đặc trưng về mô hình ngôn ngữ, mô hình chuyển đổi trật tự, các bước dịch và phát sinh.
Hàm đặc trưng cho mô hình ngôn ngữ bigram sẽ là:
𝐿𝑀 𝑣 𝑒 = 𝑝 𝑣 = 𝑝 𝑣1 𝑝 𝑣2 𝑣1 … 𝑝 𝑣𝑚 𝑣𝑚 −1
(2.9)
Đối với các bước dịch, mỗi câu 𝑒, 𝑣 sẽ được tách ra nhiều cặp ngữ 𝑒𝑗, 𝑣 𝑗. Cách tính xác suất cặp ngữ 𝜏 𝑒𝑗, 𝑣𝑗cũng tương tự cho mô hình dịch trong dịch máy thống kê dựa trên ngữ. Hàm đặc trưng cho bước dịch được tính như sau:
𝜏 𝑒, 𝑣 = 𝜏 𝑒𝑗 , 𝑣𝑗
𝑗
Hàm đặc trưng cho bước phát sinh như sau:
𝐺 𝑒, 𝑣 = 𝛾 𝑣𝑘
𝑘
(2.10)
(2.11)
𝛾 𝑣𝑘là phân phối xác suất có điều kiện giữa factor đầu vào và factor đầu ra của từ
𝑣𝑘 . Ví dụ, hệ thống phát sinh từ nguyên mẫu house và từ loại NN và số đếm Plural
thành từ ở dạng đầy đủ houses sẽ học xác suất 𝑝 𝑜𝑢𝑠𝑒, 𝑁𝑁, 𝑃𝑙𝑢𝑟𝑎𝑙|𝑜𝑢𝑠𝑒𝑠 và
𝑝 𝑜𝑢𝑠𝑒𝑠| 𝑜𝑢𝑠𝑒, 𝑁𝑁, 𝑃𝑙𝑢𝑟𝑎𝑙 . Các giá trị phân phối này hệ thống thống kê từ ngữ liệu đơn ngữ của ngôn ngữ đích.
Mô hình này thích hợp đối với hệ dịch cho cặp ngôn ngữ giàu hình thái, dạng của từ phụ thuộc vào các yếu tố hình thái như từ loại, số đếm, giới tính, thì (quá khứ, tương lai…)
2.1.4. Mô hình dịch máy thống kê dựa trên cú pháp
Mô hình dịch máy thống kê dựa trên cú pháp là một mô hình dịch kết hợp giữa thống kê và những tri thức, ràng buộc về ngữ pháp vào trong quá trình dịch.
Dịch thống kê dựa trên cú pháp có nhiều mô hình, sau đây là một số mô hình tiêu biểu:
- Dịch từ cây cú pháp sang câu (tree-to-string ) [34]
o Quá trình học: Từ câu nguồn, tác giả phân tích thành cây cú pháp. Mô hình này học xác suất chuyển đổi trật tự giữa các nút có nút con trong cây, xác suất chèn từ vào các nút và xác suất dịch các nút lá thành câu đích.
o Quá trình dịch: Với mỗi câu đầu vào, hệ dịch phân tích cú pháp. Dựa vào bảng xác suất chuyển đổi trật tự, mô hình sẽ đổi trật tự giữa các nút. Từ cây cú pháp mới, mô hình thêm các từ của ngôn ngữ đích dựa vào xác suất chèn từ. Cuối cùng, hệ dịch các từ ở nút lá ra ngôn ngữ đích, nút lá có thể dịch ra thành từ rỗng (NULL).
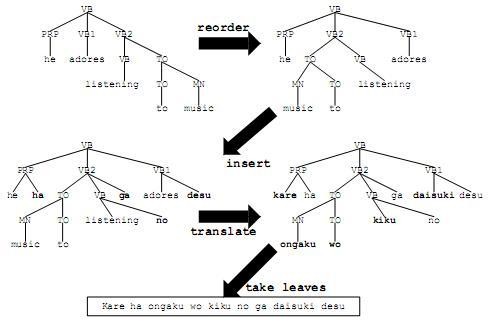
- Chuyển đổi dựa trên cây cú pháp của cả hai ngôn ngữ (tree-based transfer) [33]
o Câu nguồn và câu đích được phân tích ra thành cây cú pháp, thường là cây nhị phân để giảm độ phức tạp khi chuyển đổi trật tự.
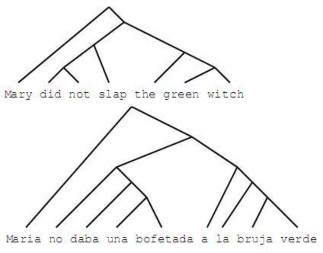
o Cây cú pháp của câu đích được đổi trật tự và kết hợp với cây cú pháp của câu nguồn.
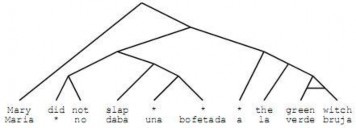
- Chuyển đổi dựa trên cấu trúc kế thừa (hierarchical transfer)
Trong mô hình này, tác giả tập trung biến đổi trật tự cho các ngữ có chứa ngữ con.
- Dịch dựa trên mệnh đề (clause level restructuring)
Do cấu trúc câu của tiếng Đức khác các ngôn ngữ khác: không có trật tự, vị trí của trạng từ, mệnh đề phụ. [7] phân tích câu ra thành các mệnh đề và áp dụng sáu bước chuyển đổi trật tự trên cây cú pháp của câu nguồn nhằm tạo sự tương đồng về trật từ từ giữa câu nguồn và câu đích.
Đánh giá mô hình dịch dựa trên cú pháp, [18] đã chỉ ra ưu điểm của phương pháp này như sau:
- Có thể chuyển đổi trật tự dựa trên thông tin cú pháp. Chẳng hạn như chuyển tân ngữ của câu tiếng Anh sang cuối câu trước khi dịch sang tiếng Đức.
- Dịch những từ chức năng (giới từ, mạo từ,...) tốt hơn.
- Có thể lấy thông tin về quan hệ cú pháp giữa các từ trong câu. Chẳng hạn như chuyển đổi trật tự giữa chủ ngữ và tân ngữ.
- Có thể khai thác mô hình ngôn ngữ cú pháp:
o Cây cú pháp đúng sẽ tạo ra câu dịch đúng.
o Cho phép chuyển đổi trật tự ở xa. Chẳng hạn như chuyển động từ chính về cuối câu.
Tuy nhiên, [18] cũng cho rằng những mô hình hiện tại vẫn chưa khai thác hết thông tin cú pháp vì các mô hình về cơ bản vẫn là dịch dựa trên ngữ, nghĩa là xem các từ trong câu là chuỗi token. Tác giả đưa ra lý do của thông tin cú pháp chưa thật sự có ích vì: hệ dịch cần công cụ phân tích cú pháp tốt, có độ chính xác cao. Ngoài ra, thông tin cú pháp khá là phức tạp, khó để con người theo dõi khi huấn luyện cũng như khi dịch và ít có nhà nghiên cứu nào vừa nắm vững về các mô hình thống kê lại hiểu rõ về lý thuyết ngôn ngữ.
2.2. Các tiêu chuẩn đánh giá chất lượng dịch
Việc đánh giá chất lượng dịch rất phức tạp vì mỗi câu nguồn thường có thể có nhiều câu dịch khác nhau. Tuỳ theo cách chọn từ, văn phong mà ta có thể tạo ra câu dịch khác nhau cho cùng một câu nguồn.
Phương pháp đáng tin cậy nhất là để con người đánh giá. Tuy nhiên, để người đánh giá sẽ chậm và tốn nhiều chi phí. Mặc khác, mỗi người sẽ có cách nhìn nhận chủ quan khác nhau. Do vậy, đánh giá bằng máy được sử dụng vì khách quan và nhanh chóng, ít tốn chi phí.
Để ước lượng hiệu quả của hệ dịch, phương pháp đánh giá tự động thường đo độ tương tự giữa câu máy dịch và câu dịch tham chiếu trong ngữ liệu.
Trong khuôn khổ của đề tài, luận văn sử dụng ba độ đo để khảo sát kết quả dịch: BLEU, NIST và TER.