Biến DSRI- Tỷ số phải thu khách hàng trên doanh thu thuần có giá trị trungbình là 0,84925, giá trị nhỏ nhất là 0, giá trị lớn nhất là 3,88, độ lệch chuẩn là 0,5947885, đồ thị phân bố cho thấy giá trị của biến này giao động trong mức 1 ±0,5, giá trị của biến tập trung ở giá trị 1,giá trị lớn nhấtkhiến đồ thì lệch sangtrái.
4.1.5 TATA- Tỷ số biến dồn tích kế toán so với tổng tài sản (Total Accruals to Total Assets)
Hình4.6: Đồ thị TATA- Tỷ số biến dồn tích kế toán so với tổng tài sản
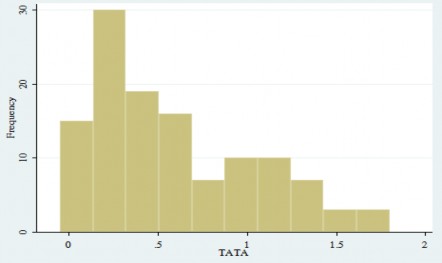
(Nguồn: Tính toán của tác giả từ phần mềm STATA 13)
Biến TATA- Tỷ số biến dồn tích kế toán so với tổng tài sản có biến trung bình là 0,5805833, độ lệch chuẩn là 0,4518464, giá trị nhỏ nhất là -0,05, giá trị lớn nhất là 1,8 các giá trị của biến phân phối giảm về phía phải của đồthị.
4.1.6 DA- Tỷ số biến kế toá dồn tích có thể điều chỉnh (Discretionary Accruals)
Hình4.7: Đồ thị DA- Tỷ số biến kế toán dồn tích có thể điều chỉnh
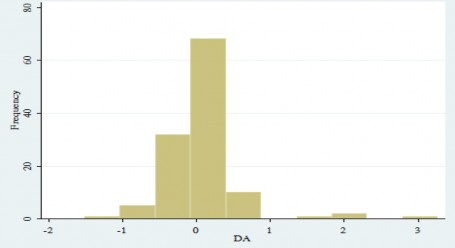
(Nguồn: Tính toán của tác giả từ phần mềm STATA 13)
Biến DA- Tỷ số biến kế toán dồn tích có thể điều chỉnh, biến DA có giá trịtrung bình là 0,0485, độ lệch chuẩn là 0,5281464, giá trị nhỏ nhất là -1,51 giá trị lớn nhất là 3,27. Các giá trị của biến DA phân bố đều hai bên của trung bình biếnsố.
Để xây dựng mô hình phù hợp và có ý nghĩa ta xem xét mối quan hệ tuyến tính giữa các biến đầu vào tỏng mô hình.
4.2 Phân tích tương quan
Phân tích tương quan là thước đo độ lớn của các mối liên hệ giữa các biến định lượng trong nghiên cứu. Thông qua thước đo này người nghiên cứu có thể xác định mối liên hệ tuyến tính giữa các biến độc lập, biến phụ thuộc với nhau trong nghiên cứu. Nếu hệ số tương quan khác 0 chứng tỏ các khái niệm nghiên cứu có mối liên hệ thực sự, hệ số tương quan dương phản ánh mối quan hệ cùng chiều và tương quan âm phản ánh mối quan hệ ngược chiều.
Phân tích tương quan giúp sớm nhận diện được các biến có mối quan hệ, có ý nghĩa thống kê với M-core, cũng như nhận biết dấu hiệu của hiện tượng đa cộng tuyến giữa các biến độc lập.
Kết quả phân tích cho thấy M-core mối tương quan có ý nghĩa thống kê với : mối quan hệ tương quan ngược chiều với biến độc lập SGI- biến tỷ số tăng trưởng doanh thu bán hàng và mối quan hệ tương quan cùng chiều với biến độc lậpDA- tỷ số biến kế toán dồn tích có thể điều chỉnh,với hệ số tương quan lần lượt là -0,1164 và 0,1799 tại mức ý nghĩa 5%.
Bảng 4.2 Ma trận hệ số tương quan giữa các biến trong mô hình
Mcore | GMI | SGI | SGAI | DSRI | TATA | DA | |
Mcore | 1,0000 | ||||||
GMI | 0,1183 | 1,0000 | |||||
SGI | -0,1164 | -0,1313 | 1,0000 | ||||
SGAI | -0,0385 | -0,2335 | -0,3028 | 1,0000 | |||
DSRI | 0,0045 | -0,0250 | -0,5324 | 0,0885 | 1,0000 | ||
TATA | -0,1718 | 0,0154 | 0,1912 | -0,1182 | -0,1510 | 1,0000 | |
DA | 0,1799 | -0,0512 | 0,2479 | -0,1688 | -0,0821 | 0,0112 | 1,0000 |
Có thể bạn quan tâm!
-

 Tổng Hợp Các Nhân Tố Giúp Phát Hiện Sai Phạm Báo Cáo Tài Chính
Tổng Hợp Các Nhân Tố Giúp Phát Hiện Sai Phạm Báo Cáo Tài Chính -
 Thực Trạng Gian Lận Trong Báo Cáo Tài Chính Của Các Công Tyxây Dựng Niêm Yết Trên Thị Trường Chứng Khoán Việt Nam
Thực Trạng Gian Lận Trong Báo Cáo Tài Chính Của Các Công Tyxây Dựng Niêm Yết Trên Thị Trường Chứng Khoán Việt Nam -
 Tổng Quan Thực Trạng Gian Lận Báo Cáo Tài Chính Ở Các Nước Trên Thế Giới.
Tổng Quan Thực Trạng Gian Lận Báo Cáo Tài Chính Ở Các Nước Trên Thế Giới. -
 Nhận diện gian lận báo cáo tài chính các công ty xây dựng niêm yết trên thị trường chứng khoán Việt Nam - 9
Nhận diện gian lận báo cáo tài chính các công ty xây dựng niêm yết trên thị trường chứng khoán Việt Nam - 9 -
 Nhận diện gian lận báo cáo tài chính các công ty xây dựng niêm yết trên thị trường chứng khoán Việt Nam - 10
Nhận diện gian lận báo cáo tài chính các công ty xây dựng niêm yết trên thị trường chứng khoán Việt Nam - 10
Xem toàn bộ 84 trang tài liệu này.
Nguồn: Kết quả từ phần mềm STATA 13
Bên cạnh mối tương quan giữa biến phụ thuộc và các biến độc lập còn có sự tương quan giữa các biến độc lập với nhau.
Tại mức ý nghĩa 1%: DA và TATA có tương quan cùng chiều; DA và GMI, DSRI có tương quan ngược chiều. DSRI có tương quan ngược chiều với GMI có tương quan cùng chiều với SGAI, T ATA.
Tại mức ý nghĩa 5%: SGI có quan hệ ngược chiều với SGAI và GMI; SGAI có quan hệ ngược chiều GMI; DSRI có tương quan ngược chiều với SGI, TATA; TATA, DA có tương quan cùng chiều SGI và có tương quan ngược chiều SGAI.
Ma trận hệ số tương quan cho thấy các biến độc lập đưa vào mô hình không có mối quan hệ tương quan chặt chẽ với nhau.
4.3 Kết quả phân tích hồi quy
Trong phần này, kết quả nghiên cứu được trình bày theo 3 bước tương ứng với phương pháp nghiên cứu đã nêu ở trên:
Bước 1: Lựa chọn những biến có ý nghĩa trong mô hình.
Bước 2: Xây dựng mô hình M-score phù hợp dựa trên dữ liệu ngành xây dựng 2013
– 2015.
Bước 3: Ước lượng ngưỡng giá trị phù hợp để phân loại các công ty sai phạm báo cáo tài chính đồng thời xác định tính chính xác của mô hình qua dữ liệu ngành xây dựng 2016.
Kết quả bước 1: Lựa chọn những biến có ý nghĩa trong mô hình
có:
Mô hình nhận diện sai pham báo cáo tài chính đã được xây dựng như trên gồm
- Biến phụ thuộc là biến ngẫu nhiên rời rạc có thể nhận giá trị 1 hoặc 0 tương
ứng với có sai phạm và không sai phạm báo cáo tài chính.
- 5 biến độc lập dựa trên nghiên cứu M-score của Beneish về nhận diện sai phạm báo cáo tài chính và thêm biến DA để phù hợp với tính hình Việt Nam các chế độ kế toán còn lỏng lẻo và các công ty ngành xây dựng là các công ty nhỏ hơn so với khu vực.
Mô hình logistic để nhận diện sai phạm báo cáo tài chính ngành xây dựng Việt Nam - với các biến đã trình bày ở trên, có dạng như sau:
M = β0 +β1(GMI) +β2(SGI) +β3(SGAI) +β4(DSRI) +β5 (TATA) +β6 (DA) (1)
Ước lượng mô hình (1) bằng phần mềm STATA 13 ta được:
Bảng 4.3 Kết quả mô hình hồi quy logistic (1)
Hệ số Bêta (Coef) | Sai số chuẩn(Std.Err) | Giá trị tstat (z) | Mức ý nghĩa (p>IzI) | |
Hằng số | 1,168979 | 1,255699 | 0,93 | 0.352 |
GMI | 0,178881 | 0,2209307 | 0,81 | 0,418 |
SGI | -1,108232 | 0,6775471 | -1,64 | 0,102 |
SGAI | -0,2828698 | 0,4471667 | -0,63 | 0,527 |
DSRI | -0,4509398 | 0,4136313 | -1,09 | 0,276 |
T ATA | -0,8145813 | 0,529683 | -1,54 | 0,124 |
DA | 0,9638427 | 0,441783 | 2,18 | 0,029 |
Frob >chi2 | 0.0495 | Log likelihood = - 66,993078 | ||
Pseudo R2 | 0.0861 |
Nguồn: Kết quả từ phần mềm STATA 13
Kết quả chạy hồi quy logistic nhị phân mô hình (1) trên phần mềm Stata được trình bày ở Bảng 4.3. Theo thông tin ở Bảng 4.3, kiểm định Chi – bình phương cho thấy độ phù hợp tổng quát của mô hình, Chi – bình phương = 12,62 với Frob > Chi2 = 0,0495 các yếu tố trong mô hình có tác động đến khả năng gian lận BCTC . Hệ số Pseudo R2 = 0,0861 có nghĩa là 8,61% biến phụ thuộc được giải thích bởi các biến độc lập trong mô hình. Mặt khác với Log likehood = -66,993078 không cao lắm và khả năng dự đoán khá cao của mô hình cho thấy sự phù hợp khá tốt của mô hình phân tích. Hơn nữa, nhiều yếu tố trong mô hình ảnh hưởng ở mức có ý nghĩa thống kê.
Kết quả hồi quy của mô hình cho thấy trong số 6 biến giải thích có biến SGI- tỷ số tăng trưởng doanh số bán hàng, có ý nghĩa thống kê với mức 10% hệ số của biến này lần lượt là -1,108232 và biến DA- tỷ số biến kế toán dồn tích có thể điều chỉnh có mức ý nghĩa thống kê 5% với hệ số góc 0,9638427. Biến TATA có ý nghĩa thống kê ở mức 15%. Các biến còn lại trong mô hình của Beneish không có ý nghĩa thống kê ở mức 15%.
Tỷ số tăng trưởng doanh số bán hàng, với mức ý nghĩa thống kê 10%, với 2=
-1,108232 cũng cho thấy mối tương quan nghịch giữa biến Tỷ số tăng trưởng doanh số bán hàng và khả năng gian lận BCTC. Cho thấy nếu các yếu tố khác không đổi, khitỷ số tăng trưởng doanh số bán hàng sẽ làm giảmkhả năng gian lận BCTC.
Tỷ số biến kế toán dồn tích có thể điều chỉnh có mức ý nghĩa thống kê 5% với
hệ số góc 0,9638427, cho thấy mối tương quan thuận giữa biến tỷ số biến kế toán dồn tích có thể điều chỉnh và khả năng gian lận BCTC. Khi tỷ số biến kế toán dồn tích có thể điều chỉnh tăng đồng thời làm khả năng gian lận BCTC củng tăng.
Theo kết quả tính toán phần trước, các biến trong mô hình không tương quan lẫn nhau. Như vậy ta có thể chấp nhận kết quả những biến có thể giải thích cho M gồm có; SGI, DA; Với các biến này thực hiện hồi quy để xác định mô hình mới gồm tất cả các biến đều có ý nghĩa giải thích cho mô hình.
Kết quả của bước 1: các biến được lựa chọn là SGI, DA.
Bước 2: Xây dựng mô hình M-score phù hợp dựa trên dữ liệu ngành xây dựng 2013 – 2015.
Từ hai biến SGI, DA được xác định có ý nghĩa ở trên, xây dựng mô hình logistic gồm:
- Biến phụ thuộc là biến giả M nhận giá trị 1 khi có sai phạm và 0 khi không có sai phạm.
- Biến độc lập là 2 biến: SGI – tỷ số tăng trưởng doanh số bán hàng, DA – tỷ số biến kế toán dồn tích có thể điều chỉnh (Discretionary Accruals).
Mô hình có dạng:
M = β0 +β1(SGI) +β2(DA) (2)
Ước lượng mô hình (2) bằng phần mềm STATA 13 ta được:
Bảng 4.4 Kết quả mô hình hồi quy logistic (2)
Hệ số Bêta (Coef) | Sai số chuẩn(Std.Err) | Giá trị tstat (z) | Mức ý nghĩa (p>IzI) | |
Hằng số | 1,168979 | 1,255699 | 0,93 | 0.352 |
SGI | -0,9011911 | 0,5079251 | -1,77 | 0,076 |
DA | 0,9532511 | 0,4278473 | 2,23 | 0,026 |
Prob >chi2 | 0.0260 | Log likelihood = - 69,654967 | ||
Pseudo R2 | 0.0498 |
Nguồn: Kết quả từ phần mềm STATA 13
Kết quả chạy hồi quy logistic nhị phân mô hình (2) trên phần mềm Stata được trình bày ở Bảng 4.4. Theo thông tin ở Bảng 4.4, kiểm định Chi – bình phương cho thấy độ phù hợp tổng quát của mô hình, Chi – bình phương = 7,30 với Prob > Chi2 = 0,0260 các yếu tố trong mô hình có tác động đến khả năng gian lận BCTC . Hệ số Pseudo R2 = 0,0498 có nghĩa là 4,98% biến phụ thuộc được giải thích bởi các biến độc lập trong mô hình.Hơn nữa, nhiều yếu tố trong mô hình ảnh hưởng ở mức có ý nghĩa thống kê.
Kết quả hồi quy của mô hình cho thấy cả 2 biến đều có ý nghĩa thống kê, SGI có ý nghĩa thống kê với mức 10% với hệ số góc là -0,9011911 và và DA với mứcý nghĩa 5% hệ số góc là 0,9532511. Vì cả mô hình chứa cả 2 biến đều có ý nghĩa thống kê nên có thể kết luận đây là mô hình phù hợp để nhận diện sai phạm báo cáo ngành xây dựng niêm yết tại Việt Nam.
Kết quả bước 2: Mô hình nhận diện sai phạm báo cáo tài chính ngành xây dựng :
M = 0,0229031 – 0,9011911 (SGI) + 0,9532511 (DA) (2)
Hệ số góc của biến SGI bằng – 0,9011911 và có ý nghĩa thống kê ở mức 10%, Đây là biến có hệ số góc trái với kỳ vọng ban đầu. Có nghĩa là tăng trưởng doanh thu tăng thì khả năng sai phạm giảm. Điều này có thể được giải thíchbằng nghiên cứu “Are Financing Needs a Constraint to Earnings Management? Evidence for Private Portuguese Firms”của José A. C. Moreira (2006). Trong nghiên cứu, Moreira nhận định rằng có mối qua hệ chặt chẽ giữa hệthốngkếtoánvàthuế:cácưuđãithuếlàđộngcơkhiếndoanhnghiệpcốý làm giảm doanh thu.
Tuy nhiên động cơ này chỉ xuất hiện trong trường hợp doanh nghiệp không có nhu cầu tài chính cao, bởi giảm doanh thu đồng nghĩa cổ phiếu doanh nghiệp giảm sức hấp dẫn trong mắt các nhà đầu tư hay ngân hàng sẽ cân nhắc việc cho vay. Như vậy, lý do khiến tăng trưởng doanh thu nghịch chiều với khả năng gian lận báo cáo tài chính có thể là các doanh nghiệp ngành xây dựng Việt Nam không có nhu cầu vốnlớn.
Hệ số góc của biến DA bằng 0,9532511 và có ý nghĩa thống kê ở mức 5%. Điều này phù hợp với kỳ vọng về dấu của hệ số trong mô hình đã trình bày ở chương trước. Cho thấy hai giả định (1) sự thay đổi do tăng trưởng và (2) sự thay đổi do lựa chọn kế toán của tổ chức phát triển được thỏa mãn thì phần biến kế toán có thể điều chỉnh (DA) chính là lợi nhuận được điều chỉnh. Như vậy, DA có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tài chính.
Vậy các nhân tố ảnh hưởng đến khả năng sai phạm báo cáo tài chính của công ty là:, tỷ lệ tăng trưởng doanh thu – SGI và biến kế toán có thể điều chỉnh DA. Trong hainhân tố ảnh hưởng, chỉ có biến kế toán có thể điều chỉnh DA có chiều ảnh hưởng giống như kỳ vọng ban đầu. Còn lại là SGI ảnh hưởng nghịch chiều đến khả năng sai phạm báo cáo tài chính của các công ty ngành xây dựng.
Bước 3: Ước lượng ngưỡng giá trị phù hợp để phân loại các công ty sai phạm báo cáo tài chính đồng thời xác định tính chính xác của mô hình qua dữ liệu ngành xây dựng 2016.
Nghiên cứu gốc, Beneish đã xác định từ 1 - 2,5% miền phân phối bên trái của phân phối chuẩn Mt tương ứng với khả năng sai phạm báo cáo tài chính cao. Tương ứng với tỷ lệ này là giá trị phân loại -1,96 cho tới -2,32. Công ty có M nằm trong khoảng này thì được đánh dấu là có dấu hiệu sai phạm và ngược lại.
Bởi vì có sự khác biệt giữa Việt Nam và Mỹ - nơi mô hình M-score của Beneish (1999) được ra đời nên cần xác định một giá trị ngưỡng mới để phù hợp với thực trạng ngành xây dựng ở Việt Nam.
Vận dụng mô hình M-score của nghiên cứu “ Nhận diện sai phạm báo cáo tài chính ngành nguyên vật liệu 2015” ở Việt Nam. Ngưỡng xác suất được lựa chọn là 1% đến 20% miền phân phối, ứng với giá trị phân loại(-2.32 ; -0,84). Tại giá trị này độ chính xác của mô hình là cao nhất cho phép nhận diện chính xác 79,68% báo cáo tài chính sai lệch theo kết quả kiểm toán.