Bảng 2.1. Tổng hợp các nhân tố giúp phát hiện sai phạm báo cáo tài chính
Tên | Ký Hiệu | Trong Nghiên Cứu | Ảnh Hưởng Đến Gian Lận BCTC | |
1 | Biến kế toán có thể điều chỉnh | DA | Mô hình dồn tích có điều chỉnh của DeAnglo (1986),Friedlan (1994) và Healy (1985) | 2 tác giả kết luận kế toán có thể điều chỉnh (DA) chính là phần lợi nhuận do nhà quản trị điều chỉnh. Nói cách khác khi DA #0 đồng nghĩa với có khả năng sai phạm báo cáo tài chính. |
2 | Biến kế toán không thể điền chính | NDA | Mô hình dồn tích của Healy (1985) và Jones (1991) | NDA thay đổi qua các năm đồng nghĩa với có nghi ngờ sai phạm báo cáo tài chính. |
3 | Tỷ số phải thu khách hàng trên doanh thu thuần | DSRI | Mô hình M-score Beneish (1999) | DSRI có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tài chính. |
4 | Tỷ số lãi gộp | GMI | Mô hình M-score Beneish (1999) | GMI có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tài chính. |
5 | Tỷ số tăng trưởng doanh thu bán hàng | SGI | Mô hình M-score Beneish (1999) | SGI có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tài chính |
6 | Tỷ số chất lượng tài sản | AQI | Mô hình M-score Beneish (1999) | AQI có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tài chính |
7 | Tỷ số khấu hao tài sản cố định hữu hình | DEPI | Mô hình M-score Beneish (1999) | DEPI có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tài chính |
8 | Tỷ số chi phí bán hàng và quản lý doanh nghiệp | SGAI | Mô hình M-score Beneish (1999) | SGAI có mối quan hệ ngược chiều với xác suất xảy ra sai phạm báo cáo tài chính |
9 | Tỷ số đòn bẩy tài chính | LVGI | Mô hình M-score Beneish (1999) | LVGI có mối quan hệ ngược chiều với xác suất xảy ra sai phạm báo cáo tài chính |
10 | Tỷ số biến dồn tích kế toán so với tổng tài sản | TATA | Mô hình M-score Beneish (1999) | TATA có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tài chính |
12 | Chi phí tài chính | FEI | M-score của Burcu Dikmen và Güray Küçükkocaoğlu (2005) | FEI có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tài chính |
13 | Quy mô doanh nghiệp | Size | Rhee và các cộng sự (2013) | Xu hướng thao túng thu nhập phụ thuộc vào quy mô công ty, tuy nhiên nghiên cứu chưa đưa ra mô hình định lượng cụ thể. |
Có thể bạn quan tâm!
-

 Nhận diện gian lận báo cáo tài chính các công ty xây dựng niêm yết trên thị trường chứng khoán Việt Nam - 2
Nhận diện gian lận báo cáo tài chính các công ty xây dựng niêm yết trên thị trường chứng khoán Việt Nam - 2 -
 Các Mô Hình Nhận Dạng Gian Lận Báo Cáo Tài Chính.
Các Mô Hình Nhận Dạng Gian Lận Báo Cáo Tài Chính. -
 Các Công Trình Nghiên Cứu Trong Nước Về Gian Lận.
Các Công Trình Nghiên Cứu Trong Nước Về Gian Lận. -
 Thực Trạng Gian Lận Trong Báo Cáo Tài Chính Của Các Công Tyxây Dựng Niêm Yết Trên Thị Trường Chứng Khoán Việt Nam
Thực Trạng Gian Lận Trong Báo Cáo Tài Chính Của Các Công Tyxây Dựng Niêm Yết Trên Thị Trường Chứng Khoán Việt Nam -
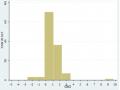 Tổng Quan Thực Trạng Gian Lận Báo Cáo Tài Chính Ở Các Nước Trên Thế Giới.
Tổng Quan Thực Trạng Gian Lận Báo Cáo Tài Chính Ở Các Nước Trên Thế Giới. -
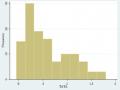 Tata- Tỷ Số Biến Dồn Tích Kế Toán So Với Tổng Tài Sản (Total Accruals To Total Assets)
Tata- Tỷ Số Biến Dồn Tích Kế Toán So Với Tổng Tài Sản (Total Accruals To Total Assets)
Xem toàn bộ 84 trang tài liệu này.

Nguồn: Thống kê của tác giả
2.7 Phương pháp nghiên cứu sai phạm BCTC ngành Xây dựng
2.7.1 Quy trình nghiên cứu
Bài nghiên cứu sử dụng phương pháp định lượng để kiểm định lý thuyết khoa học đề ra. Quy trình định lượng kiểm định tính lý thuyết khoa học của bài nghiên cứu được xây dựng như sau:
Lý thuyết => Mô hình, giả thuyết
Thu thập số liệu
Kiểmđịnh mô hình, giả thuyết
Kết quả, kiến nghị
Hình 2.2: Quy trình nghiên cứu
Bước 1: Tham khảo các nghiên cứu trước, từ đó xác định vấn đề nghiên cứu, Có được vấn đề nghiên cứu tác giả xây dựng mục tiêu cựu thể và câu hỏi nghiên cứu, phần này được trình bài ở chương 1.
Bước 2: Tổng hợp lý thuyết => Xây dựng mô hình giả thuyết nghiên cứu. Dựa vào phần tổng quan các nghiên cứu trước, xây dựng mô hình nghiên cứu về ảnh hưởng của các nhân tố tài chính đến gian lận BCTC.
Bước 3: Thu nhập các chỉ tiêu tài chính trên BCTC của các công ty xây dựng niêm yết trên 2 sàn chứng khoán HOSE và HNX.
Bước 4: Kiểm định mô hình, giả thuyết bằng phân tích tương quan ( correlation analysis ), phân tích hồi quy Logistic. Đồng thời xác định tính dự báo của mô hình qua dữ liệu ngành xây dựng năm 2016.
Bước 5: Kết quả mô hình được trình bài thông qua chạy mô hình logistic, đồng thời kiến nghị với các bên sử dụng BCTC.
2.7.2 Dữ liệu và phương pháp thu thập số liệu
Quy trình chọn mẫu
Để chọn được mẫu nghiên cứu, tác giả thực hiện theo quy trình sau:
Bước 1: Đầu tiên tác giả xác định mẫu nghiên cứu là 44 công ty ngành xây dựng có cổ phiếu niêm yết trên sàn giao dịch chứng khoán Hồ Chí Minh và Hà Nội.
Bước 2: Thu thập dữ liệu về lợi nhuận trước kiểm toán từ năm 2013- 2015 và lợi nhuận sau kiểm toán từ năm 2012 – 2014.
Dữ liệu được thu thập từ trang web tài chính: www.cafef.vn. Đây một trong những trang website lớn và có danh tiếng về cung cấp thông tin các doanh nghiệp niêm yết trên thị trường chứng khoán Việt Nam, nên báo cáo tài chính thu thấp từ trang này có độ tin cậy cao.
Bước 3: Tính toán chênh lệch tiêu chí trước và sau kiểm toán theo công thức: Lợi nhuận trước kiểm toán – Lợi nhuận sau kiểm toán
Chênh lệch lợi nhuận =
Lợi nhuận sau kiểm toán
Bước 4: Các khoản mục trên báo cáo tài chính cần thu thập: Lợi nhuận sau thuế, Tổng tài sản, Các khoản phải thu khách hàng, Doanh thu thuần, Giá vốn hàng bán, Chi phí bán hàng, Chi phí quản lý doanh nghiệp, dòng tiền thuần từ hoạt động kinh doanh.
Dữ liệu bao gồm báo cáo trước và sau kiểm toán của 44 công ty ngành xây dựng niêm yết trên hai sàn HOSE và HNX. Báo cáo tài chính trước kiểm toán 2013- 2015 và báo cáo sau kiểm toán năm 2012-2014.
Bước 5: Loại bỏ các doanh nghiệp không đủ dữ liệu để thực hiện bước phân tích tiếp theo và chốt lại mẫu.
Những quan sát bị lọc bỏ là những quan sát gặp phải một trong các vấn đề như sau:
-Những quan sát không đủ dữ liệu: Cụ thể những quan sát bị lọc bỏ là những quan sát thiếu một trong những khoản mục cần thu thập như đã nêu ởtrên
- Những doanh nghiệp đã bị hủy niêm yết hoặc không công bố báo cáo tàichính
-Những giá trị của quan sát có sai lệch quá lớn (phương sai, độ lệch chuẩn quá lớn), những quan sát này làm tăng giá trị trung bình (mean) của dữ liệu biến, gây nhiễu và ảnh hưởng đến độ chính xác của môhình.
Phân tích dữ liệu
Trình tự nghiên cứu các yếu tố ảnh hưởng đến gian lận báo cáo tài chính được thực hiện qua các bước sau đây:
Bước 1: Thống kê miêu tả.
Bước 2: Phân tích tương quan (correlation analysis). Phân tích tương quan sớm nhận diện được các biến có quan hệ có ý nghĩ thống kê với M-score, củng như nhận biết dấu hiệu của hiện tượng đa cộng tuyến giữa các biến độc lập.
Bước 3: Phân tích hồi quy Logistic.
Hồi quy logistic sử dụng biến phụ thuộc dạng nhị phân( hai biểu hiện 0 và 1) để ước lượng xác suất một sự kiện sẽ xảy ra với những thông tin của biến độc lập mà ta có được.
2.7.3 Giả thuyết nghiên cứu
Giả thuyết khoa học hay giả thuyết nghiên cứu (/research hypothesis) hypothesis) là một nhận định sơ bộ, kết luận giả định về bản chất sự vật do người nghiên cứu đưa ra để chứng minh hoặc bác bỏ. Giả thuyết là khởi điểm của mọi nghiên cứu khoa học, và phải dựa trên cơ sở quan sát, không trái với lý thuyết và có thể kiểm chứng.
Sau khi xác định mục tiêu và đối tượng nghiên cứu, tác giả dựa trên cơ sở tổng quan tài liệu nghiên cứu và lấy ý kiến chuyên gia để đưa ra sáu giả thuyết nghiên cứu như sau:
-Giả thuyết H1 : GMI – tỷ lệ lãi gộp của doanh nghiệp có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tàichính.
-Giả thuyết H2 : SGI – tốc độ tăng trưởng doanh thu có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tàichính.
- Giả thuyết H3 : SGAI – tỷ lệ chi phí bán hàng và quản lý doanh nghiệp có mối quan hệ nghịch chiều với xác suất xảy ra sai phạm báo cáo tài chính.
-Giả thuyết H4 : DSRI – tỷ lệ phải thu của doanh nghiệp có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tàichính.
- Giả thuyết H5 : TATA – Tỷ số biến dồn tích kế toán so với tổng tài sản có mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tài chính.
Giả thuyết H6 : DA – Tỷ số biến kế toán dồn tích có thể điều chỉnhcó mối quan hệ thuận chiều với xác suất xảy ra sai phạm báo cáo tài chính.
2.7.4 Mô tả các biến trong mô hình
Mô hình được sử dụng để nhận diên sai phạm báo cáo tài chính ngành xây dựng niêm yết trên thị trường chứng khoán Việt Nam là mô hình logistic với biến phụ thuộc là biến phân loại (có sai phạm hoặc không sai phạm), biến độc lập là các biến định lượng.
Biến phụthuộc:
M= |
0 nếu báo cáo tài chính không sai lệch |
Biến phụ thuộc được phân loại theo báo cáo tài chính các công ty trước và sau kiểm toán với giả định kết quả kiểm toán là kết quả chính xác về tình hình côngty.
Mẫu có gian lận được định nghĩa là các công ty có trên lệch lợi nhuận trước và sau kiểm toán lớn hơm 10%. Chênh lệch lợi nhuận được tính dựa vào công thức sau:
Lợi nhuận trước kiểm toán – Lợi nhuận sau kiểm toán
Chênh lệch lợi nhuận =
Lợi nhuận sau kiểm toán
Lợi nhuận sau kiểm toán được xem là lợi nhuận đúng ( vì được kiểm toán viên chấp nhận) . Công thức trên nhằm tính mức độ gian lận trên giá trị lợi nhuận đúng. Tác giả sử dụng giá trị tuyệt đối vì không phân biệt chênh lệch dương ( khai cao lợi nhuận
) hay chênh lệch âm ( che giấu lợi nhuận ), chúng đều được phân loại là gian lận nếu tỷ lệ chênh lệch lớn hơn 10%.
Biến độclập:
Mô hình được xây dựng trên cơ sở mô hình M-score 8 biến của Beneish (1999). Tuy nhiên với tình hình Việt Nam, các chế độ kế toán còn lỏng lẻo, các công ty nhỏ hơn so với khu vực nên mô hình lấy 5 biến trong mô hình M-score 8 biến của Beneish (1999). Đồng thời đưa thêm biến kế toán dồn tích có thể điều chỉnh (DA) theo lý thuyết Friedlan (1994), để đánh giá tác động của các yếu tố này tới khả năng nhận diện sai phạm của mô hình. Thêm nữa, theo nghiên cứu của Hoàng Khánh và Trần Thị Thu
Hiền (2015) sau khi bổ sung biến DA có được mô hình có kết quả nhận diện cao hơn mô hình gốc đối với các công ngành xây dựng niêm yết trên thị trường chứng khoán Việt Nam, bởi vậy ta đưa thêm biến DA này để tìm kiếm một kết quả cao hơn đối với ViệtNam.
Như vậy mô hình nhận diện gian lận các công ngành xây dựng niêm yết trên thị trường chứng khoán Việt Nam từ năm 2013 đến 2015 có 6 biến: GMI, SGI, SGAI, DSRI, TATA, DA.
Bảng 2.2: Danh sách các biến đầu vào được xem xét
Biến độc lập | Mô tả | |
1 | GMI | Tỷ số lãi gộp (Gross Margin Index) |
2 | SGI | Tỷ số tăng trưởng doanh thu bán hàng (Sales Growth Index) |
3 | SGAI | Tỷ số chi phí bán hàng và quản lý doanh nghiệp (Sales, general and administrative expense Index) |
4 | DSRI | Tỷ số phải thu khách hàng trên doanh thu thuần (Days Sales in Receivables Index) |
5 | TATA | Tỷ số biến dồn tích kế toán so với tổng tài sản (Total Accruals to Total Assets) |
6 | DA | Tỷ số biến kế toán dồn tích có thể điều chỉnh (Discretionary Accruals) |
Nguồn: Thống kê của tác giả
Tỷ số lãi gộp (Gross Margin Index)
(Doanhthut−1–Giávốonhàngbánt−1)/Doanhthut−1
GMI =
(Doanhthut−Giávốonhàngbánt)⁄Doanhthut
GMI là tỷ số lợi nhuận biên giữa năm t chưa kiểm toán và năm t-1 đã kiểm toán. GMI<1 nghĩa là lợi nhuận biên đang giảm, đây được cho là một dấu hiệu tiêu cực về triển vọng tăng trưởng của công ty. Khi đó công ty sẽ có nhiều khả năng gian lận để che dấu tình hình thực tại. Bởi vậy, GMI được kỳ vọng sẽ có quan hệ thuận chiều với khả năng sai phạm báo cáo tàichính.
Tỷ số tăng trưởng doanh thu bán hàng (Sales Growth Index)
Doanh thut
SGI =
Doanh thut−1
Việc tăng trưởng doanh thu bất thường có thể là một trong các dấu hiệu sai phạm nếu xem xét trên khía cạnh hai động cơ như sau: Thứ nhất, bóp méo doanh thu
nhằm tạo ra một kết quả đẹp, phù hợp với mục tiêu đề ra sẽ thu hút các nhà đầu tư. Thứ hai, nếu doanh thu giảm công ty có thể đối mặt với giảm giá cổ phiếu trên thị trường.
Tỷ số chi phí bán hàng và quản lý doanh nghiệp (Sales, general and administrative expense Index)
Chi phí bán hàng và quản lý doanh nghiệpt ⁄Doanh thut SAGI =
Chi phí bán hàng và quản lý doanh nghiệpt−1⁄Doanh thut−1
SGAI được tính bằng cách sự thay đổi của tỷ số chi phí bán hàng quản lý doanh nghiệp trên tổng doanh thu giữa năm t và năm t-1. Nếu SGAI>1 có nghĩa chi phí bán hàng và quản lý doanh nghiệp đang tăng lên so với doanh thu, điều này có thể là một dấu hiệu của sai phạm.
Tỷ số phải thu khách hàng trên doanh thu thuần (Days Sales in Receivables Index)
DSRI =
Các khoảng phải thut ⁄Doanh thut
Các khoảng phải thut -1 ⁄Doanh thut-1
Chỉ số DSRI so sánh sự thay đổi các khoản phải thu trên doanh thu giữa năm t chưa kiểm toán và năm t-1 đã kiểm toán. Trong trường hợp không có sự thay đổi về chính sách tín dụng thương mại, chỉ số này sẽ tăng hoặc giảm dưới dạng tuyến tính.Sự gia tăng không chỉ dựa trên kế toán ghi nhận bán hàng ủy thác mà còn phụ thuộc vào việc phát sinh các tài khoản vãng lai của các công ty liên doanh, liên kết. Theo Beneish, một sự gia tăng bất thường tỷ số phải thu khách hàng trên doanh thu hoặc là do công ty đã thay đổi chính sách tín dụng thương mại hoặc là một dấu hiệu của sai phạm báo cáo tài chính doanhnghiệp.
Tỷ số biến dồn tích kế toán so với tổng tài sản (Total Accruals to Total Assets)
Thu nhậpt − Dòng tiền từ hoạt động kinh doanht
TATA =
Tổng tài sảnt
TATA được tính bằng chênh lệch giữa thu nhập và dòng tiền từ hoạt động kinh doanh trên tổng tài sản. Theo Beneish, các khoản kế toán dồn tích càng lớn thì khả năng sai phạm càngcao.
Tỷ số biến kế toán dồn tích có thể điều chỉnh (Discretionary Accruals)
Biến kếtoán dồn tícht (TAt) Doanh Thut | - | Biến kếtoán dồn tícht−1 (TAt−1) Doanh Thut-1 |
Mô hình dồn tích điều chỉnh của Friedlan (1994) được phát triển dựa trên mô hình của DeAngele (1986). Mô hình này được sử dụng với giả định sự thay đổi trong tổng số trích trước giữa hai kỳ kế toán là do sự ảnh hưởng của hai nhân số: (1) sự thay đổi do tăng trưởng và (2) sự thay đổi do lựa chọn kế toán của tổ chức phát triển.
2.7.5 Phương pháp nghiên cứu
Bước 1: Lựa chọn những biến có ý nghĩa trong mô hình.
Bước 2: Xây dựng mô hình M-score phù hợp dựa trên dữ liệu ngành xây dựng 2013 – 2015
Bước 3: Ước lượng ngưỡng giá trị phù hợp để phân loại các công ty sai phạm báo cáo tài chính đồng thời xác định tính chính xác của mô hình qua dữ liệu ngành xây dựng 2016.
Bước 1: Sử dụng mô hình logistic để tìm ra những biến độc lập thực sự ảnh hưởng đến biến phụ thuộc trong mô hình.
Xét mô hình:
Yi = β0 + β1X1i + Ui Trong đó:
X1 – biến độc lập
Y – biến ngẫu nhiên rời rạc có thể nhận giá trị 0 hoặc 1
Gọi pi = P (Y=1|X1i) là xác suất để Y=1 với điều kiện X = X1i; 1-pi = P (Y=0|X1i). Suy ra, Yi phân bố A(pi)
Giả thiết E(ui) = 0, khi đó E(Yi) = pi = β0 + β1X1itức mô hình trở thành mô hình xác suất tuyến tính.
Vì các xác suất chỉ được giới hạn từ 0 đến 1: 0 ≤ pi ≤ 1 nên 0 ≤ E(Y|X1i) ≤ 1
Đối với mô hình hồi quy, các yếu tố ngẫu nhiên trong mô hình cần thỏa mãn đồng thời các giả thiết: