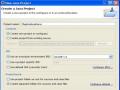
Sau đó chọn loại export là file jar.
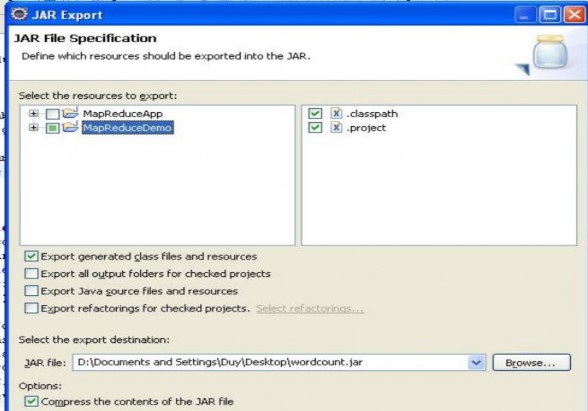
Tiếp theo ta chọn project để export và chọn đường dẫn output cho file jar, rồi chọn Finish
Sau khi có được file jar, ta thực hiện nó bằng command của hadoop như sau:
Có thể bạn quan tâm!
-
 Nghiên cứu mô hình kiểm soát truy xuất cho dữ liệu lớn - 11
Nghiên cứu mô hình kiểm soát truy xuất cho dữ liệu lớn - 11 -
 Nghiên cứu mô hình kiểm soát truy xuất cho dữ liệu lớn - 12
Nghiên cứu mô hình kiểm soát truy xuất cho dữ liệu lớn - 12 -
 Nghiên cứu mô hình kiểm soát truy xuất cho dữ liệu lớn - 13
Nghiên cứu mô hình kiểm soát truy xuất cho dữ liệu lớn - 13
Xem toàn bộ 119 trang tài liệu này.
![]()
o WordCount: Lớp chứa hàm main để đệ trình job
o /inputtext.txt: File input nằm trên HDFS
o /output/ : Thư mục chứa các file output nằm trên HDFS (Số file output bằng với số reduce task). Vào trình quản lý của MapReduce ta xem tiến độ của thực thi job này. (Cluster ở đây gồm một master và 2 slave. Do dữ liệu inputtext.txt chỉ gồm vài KB nên chỉ có một map task thực thi)
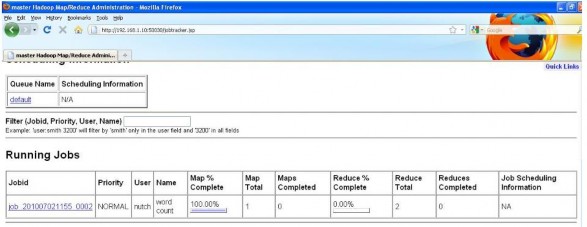
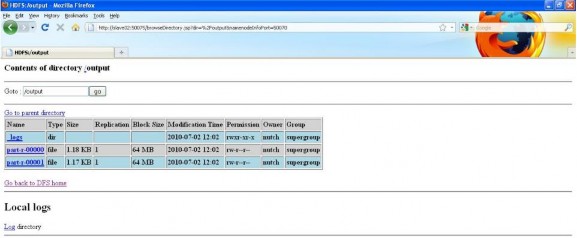
Và kết quả đạt được sau khi thực hiện job wordcount thông qua trình quản lý HDFS. Do có 2 reduce task nên có 2 file output cuối cùng.