Tìm quan hệ diễn ngôn với những đơn vị không xuất hiện dấu hiệu diễn ngôn
Với những đơn vị không xuất hiện dấu hiệu diễn ngôn, dựa trên đặc điểm của tiếng Việt, luận án dùng giải thuật tìm các từ cùng xuất hiện được Marcu [89] đề xuất. Khi ấy, các quan hệ diễn ngôn sẽ được gán là Kết nối hoặc Liệt kê.
Xây dựng cây diễn ngôn
Để có thể xây dựng được một cây cấu trúc văn bản hợp pháp, phải chọn từ những quan hệ tìm được ra bộ các quan hệ tạo thành một cấu trúc văn bản hợp pháp. luận án xây dựng cây cấu trúc văn bản hợp pháp nhờ phương pháp proof-theoretic[89], sử dụng các phép biến đổi để quy dẫn về cấu trúc hợp pháp.

Phương pháp proof – theoretic sinh ra tất cả các tập cây cấu trúc hợp pháp, với mỗi tập có các thông số: Hạt nhân hay Vệ tinh, lá hay là gốc, tên quan hệ và các thành phần của cây. Mỗi cây được mô tả với cấu trúc Tree (status, type, promotion, left, right), trong đó:
- status: mô tả trạng thái của nút, là Hạt nhân (N) hoặc Vệ tinh (S).
- type: tên của quan hệ diễn ngôn.
- promotion:Tập các giá trị từ 1 đến n là số hiệu của các mệnh đề nổi bật nhất trong cây. Mệnh đề nổi bật nhất là mệnh đề đóng vai trò quan trọng nhất trong đoạn văn bản được biểu diễn bởi nút đang xét.
- left: mô tả của cây con trái.
- right: mô tả của cây con phải.
Nút lá có thể được mô tả dưới dạng cây bằng cách gán cho giá trị Left và Right bằng NULL và type là LEAF.
Theo [89], phương pháp proof-theoretic cho phép xây dựng nên cấu trúc văn bản từ 14 tiên đề. Dưới đây là ví dụ một tiên đề:
[S(l, b, Tree1(Hạt nhân, type1, p1, left1, right1), rr1) ^
S(b+1, h, Tree2(Hạt nhân, type2, p2, left2, right2), rr2) ^
rhel_rel(name, n1, n2) ∈ rr1∩ rr2^ n1∈ p1 ^ n2∈ p2^ paratactic(name)]
S(l, h, Tree(Hạt nhân, name, p1 ∪ p2, Tree1(…), Tree2(…), rr1∩ rr2 {rhel_rel(name, l, n1, n2)}
Tiên đề này có nghĩa:
Nếu
- Đoạn văn bản kéo dài từ đơn vị l tới đơn vị b được biểu diễn bằng cây cấu trúc Tree1 với tập quan hệ diễn ngôn rr1
- Đoạn văn bản kéo dài từ đơn vị b+1 tới đơn vị h được biểu diễn bằng cây Tree2 có tập quan hệ diễn ngôn rr2.
- Tồn tại quan hệ diễn ngôn rhel_rel(name, n1, n2) giữa đoạn n1 là một trong các đoạn nổi bật của đoạn [l, b] với đoạn n2 là một trong các đoạn nổi bật của [b+1, h].
- Quan hệ diễn ngôn rhel_rel (name, n1, n2) có thể mở rộng trên cả đoạn [l, b] và đoạn
- [b+1, h]
- rhel_rel(name, n1, n2) ∈ rr1∩ rr2
- Quan hệ name nói trên là đẳng lập (paratactic).
Thì
- Có thể tổ hợp đoạn [l, b] và đoạn [b+1, h] thành đoạn lớn hơn [l, h] có trạng thái là hạt nhân, kiểu quan hệ name, tập nổi bật là p1 ∪ p2 (p1là tập nổi bật của[l, b], p2 là tập nổi bật của[b+1, h]), có 2 cây con là tree1 và tree2.
- Tập quan hệ hiện nay sẽ là rr1∩ rr2 {rhel_rel(name, l, n1, n2)
Lựa chọn cây diễn ngôn
Tương tự tiếng Anh, tiếng Việt là ngôn ngữ có cách viết từ trái sang phải, phát ngôn trong tiếng Việt có xu hướng để mệnh đề quan trọng trước. Do vậy, luận án đã theo cách đánh giá cây diễn ngôn của Marcu trong [89] thiên về cây lệch trái theo tiêu chuẩn sau:

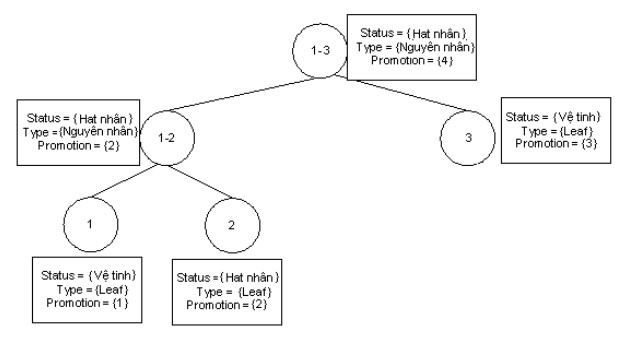
Trong hình 3.13 dưới đây là ví dụ về các loại cây diễn ngôn. Cây lệch trái có giá trị 1 là giá trị lớn nhất. Điều đó thể hiện sự ưu tiên cây lệch trái.
Cây cân bằng với w = 0.
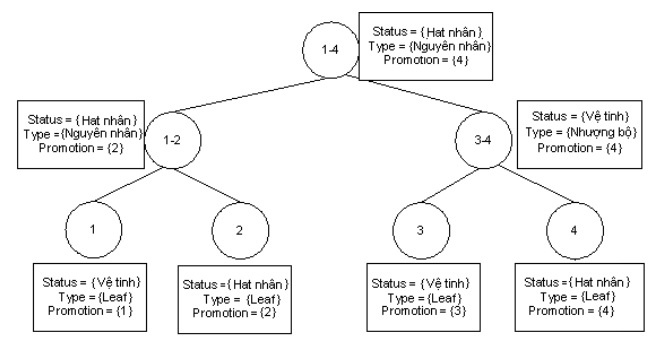
Cây lệch trái với w = 1
Cây lệch phải với w = -1
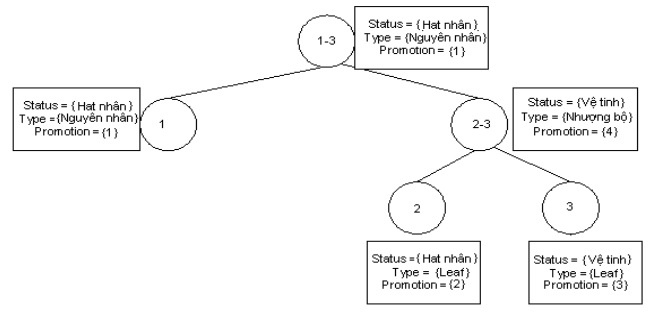
Hình 3.13. Các dạng cây cấu trúc diễn ngôn
3.2.2. Giải thuật phân tích cú pháp câu ghép
Luận án đã đề xuất giải thuật tổng thể để phân tích cú pháp cho câu ghép biểu diễn dưới dạng một dãy các từ như sau:
| Vào: Câu tiếng Việt s đã tách từ Ra: Kết quả phân tích câu bao gồm danh sách các kết nối Phương pháp: U [N] := Discourse_Segment(s);// U chứa các đơn vị diễn ngôn của câu s root := RS_Parse(); // Cây phân tích diễn ngôn của s có gốc là root for i:=1 to N if Is_Unit (U[i]) { Parse(U[i],LinkTemp); Lnk.Add LinkTemp; } Insert_Link_From_RST_Tree(root); After_Insert(); |
Có thể bạn quan tâm!
-

 Kết Quả Thử Nghiệm Phân Tích Câu Đơn Và Câu Ghép Đơn Giản
Kết Quả Thử Nghiệm Phân Tích Câu Đơn Và Câu Ghép Đơn Giản -
 Mô hình văn phạm liên kết tiếng Việt - 16
Mô hình văn phạm liên kết tiếng Việt - 16 -
 Mô hình văn phạm liên kết tiếng Việt - 17
Mô hình văn phạm liên kết tiếng Việt - 17 -
 Kết Quả Thử Nghiệm Phân Tích Câu Ghép
Kết Quả Thử Nghiệm Phân Tích Câu Ghép -
 Giải Thuật Kiểu Viterbi Để Tìm Phân Tích Tốt Nhất
Giải Thuật Kiểu Viterbi Để Tìm Phân Tích Tốt Nhất -
 Mô hình văn phạm liên kết tiếng Việt - 21
Mô hình văn phạm liên kết tiếng Việt - 21
Xem toàn bộ 305 trang tài liệu này.
Hình 3.14. Giải thuật phân tích cú pháp cho câu ghép
Trong giải thuật này,
- Biến Lnk chứa toàn bộ liên kết cho cả câu ghép. Biến LinkTemp chứa các liên kết cho từng mệnh đề.
- Hàm Discourse_Segment thực hiện phân đoạn diễn ngôn cho câu s.
- Hàm RS_Parse cho phép dựng cây phân tích diễn ngôn của câu .
- Hàm Is_Unit trả về giá trị true nếu đơn vị diễn ngôn được xem xét chứa từ hai từ trở lên.
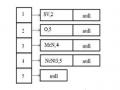
- Hàm Parse là hàm phân tích cú pháp, trả 1 nếu câu đúng cú pháp, 0 nếu ngược lại. Kết quả được lưu trong lnk. lnk có cấu trúc như hình 3.16. Mỗi danh sách ứng với mỗi từ là một linklist.
- Hàm After_Insert cho phép xử lý và tạo liên kết với các mệnh đề phụ trạng ngữ: “hôm qua”,”trong khi đó”…
- Hàm Insert_Link_From_RST_Tree thực hiện việc duyệt cây diễn ngôn của câu, thêm các liên kết ứng với từng quan hệ diễn ngôn.
Hình 3.15 dưới đây trình bày hàm Insert_Link_From_RST_Tree do luận án đề xuất.
Trong hàm này,
- Thuộc tính promotion cho biết phạm vi của quan hệ diễn ngôn liên quan đến mệnh đề nào trong câu.
- Biến FirstWord trả về thứ tự của từ đại diện cho mệnh đề thứ nhất, LastWord trả về thứ tự của từ đại diện cho mệnh đề thứ hai.
- Biến FirstMarker chứa dấu hiệu diễn ngôn ở đầu đoạn văn bản được mô tả bởi một cây con của cây cấu trúc diễn ngôn, MidMarker chứa dấu hiệu diễn ngôn nằm ở giữa đoạn văn bản của cây con của cây cấu trúc diễn ngôn. Hai từ đó cần được xác định bởi các hàm FindFirstMarker và FindMiddleMarker vì tùy từng xử lý, giải thuật phân tích diễn ngôn có thể để dấu hiệu diễn ngôn ở đầu hay cuối đơn vị diễn ngôn nguyên tố.
- Hàm Represent trả về từ đại diện cho mệnh đề được xét.
- Thuộc tính IndexOfRepWord trả về số thứ tự của từ đại diện tại nút trong của cây cấu trúc diễn ngôn.
- Hàm InsertLink cho phép thêm một mối liên hệ vào Linkage.
| Insert_Link_From_RST_Tree (node) { if(IsLeaft(node) ) return; InsertLinkFromRSTree(node.LeftChild); InsertLinkFromRSTree(node.RightChild); if (!IsLeaf(node)) if (IsLeaf(node.LeftChild) ) if(IsLeaf(node.RightChild) { FirstWord = Represent (node.LeftChild.promotion) LastWord = Represent (node.RightChild.promotion) } else { FirstWord = Represent (node.LeftChild.promotion); LastWord = node.RightChild. IndexOfRepWord; } else if (IsLeaf(node.RightChild)) {FirstWord = node.LeftChild.IndexOfRepWord; LastWord = Represent (node.RightChild.promotion); } else {FirstWord = node.LeftChild. IndexOfRepWord; LastWord = node.RightChild. IndexOfRepWord; } FirstMarker = FindFirstMarker (node); MidMarker = FindMiddleMarker (node); InsertLink(node, FirstWord, LastWord, FirstMarker, MidMarker, node.Action); } } |
Hình 3.15. Hàm Insert_Link_From_RST_Tree
3.2.3. Tìm từ để kết nối mệnh đề
Nếu trong mô hình văn phạm phụ thuộc, từ đại diện cho mệnh đề chính là từ trung tâm của mệnh đề thì trong mô hình văn phạm liên kết, cần phải chọn từ đại diện cho mệnh đề.
Bậc của kết nối Việc chọn từ đại diện cho mệnh đề phải đảm bảo cầu về tính phẳng của liên kết. Sau khi phân tích cú pháp cho các mệnh đề, các kết nối được lưu trữ lại dưới dạng danh sách liên kết.
Hình 3.16 dưới đây thể hiện cấu trúc lưu trữ phân tích liên kết của câu “Tôi mua một bông hoa”. 1, 2…5 là số thứ tự của từ. Mỗi từ có một danh sách liên kết các kết nối với các từ nằm bên phải nó. Thông tin về mỗi kết nối bao gồm (kiểu, đích, bậc). Ví dụ (SV, 2, 0 ) chỉ liên kết của từ đầu tiên (“tôi”) và từ thứ hai (“mua”).