trị Sig. nhỏ hơn 0.05 chứng tỏ các biến độc lập này có ý nghĩa thống kê trong mô hình, các biến độc lập “Tên thương hiệu” và “Quảng bá thương hiệu” trong mô hình có giá trị Sig. lớn hơn 0.05 chứng tỏ các biến độc lập này không có ý nghĩa thống kê nên bị loại. Ngoài ra hằng số trong mô hình có giá trị Sig. là 0.023< 0.05 nên không bị loại.
Như vậy, phương trình hồi quy được xác định như sau:
NHANBIETTHUONGHIEU = 0.735 + 0.198LOGO + 0.227SLOGAN + 0.194DONGPHUC
Nhìn vào mô hình hồi quy, ta có thể xác định rằng: các nhân tố “Hình ảnh Logo”, “Câu khẩu hiệu Slogan”, “Đồng phục nhân viên” ảnh hưởng đến “Mức độ nhận biết” của khách hàng về thương hiệu CodeGym.
Đề tài tiến hành giải thích ý nghĩa các hệ số Bê – ta như sau:
Hệ số β2 = 0.198 có ý nghĩa là khi biến “Hình ảnh Logo” thay đổi một đơn vị trong khi các biến khác không đổi thì “Mức độ nhận biết” biến động cùng chiều với 0.198 đơn vị.
Hệ số β3 = 0.227 có ý nghĩa là khi biến “Câu khẩu hiệu Slogan” thay đổi một đơn vị trong khi các biến khác không đổi thì “Mức độ nhận biết” biến động cùng chiều với 0.227 đơn vị.
Hệ số β5 = 0.194 có ý nghĩa là khi biến “Đồng phục nhân viên” thay đổi một đơn vị trong khi các biến khác không đổi thì “Mức độ nhận biết” biến động cùng chiều với 0.194 đơn vị.
Các biến độc lập ảnh hưởng cùng chiều đến biến phụ thuộc “Mức độ nhận biết”, mức độ nhận diện thương hiệu của khách hàng đối với thương hiệu “CodeGym – Hệ thống đào tạo lập trình hiện đại” tại thành phố Huế sẽ được nâng cao khi những yếu tố ảnh hưởng cùng chiều này sẽ tăng. Đối với 2 biến độc lập “Tên thương hiệu” và “Quảng bá thương hiệu” không có sự ảnh hường
nào đến biến phụ thuộc. Điều này cho thấy Công ty CP CodeGym cần phải có những động thái nhằm kiểm soát các yếu tố này một cách cẩn thận hơn.
2.3.5.4. Đánh giá độ phù hợp của mô hình
Bảng 2.19: Đánh giá độ phù hợp của mô hình
R | R Square | Adjusted R Square | Std. Error of the Estimate | Durbin - Watson | |
1 | 0.611 | 0.373 | 0.346 | 0.617 | 2.132 |
Có thể bạn quan tâm!
-

 Mức Độ Nhận Biết Của Khách Hàng Về Thương Hiệu Codegym Tại Thành Phố Huế
Mức Độ Nhận Biết Của Khách Hàng Về Thương Hiệu Codegym Tại Thành Phố Huế -
 Phương Tiện Giúp Khách Hàng Biết Đến Thương Hiệu Codegym
Phương Tiện Giúp Khách Hàng Biết Đến Thương Hiệu Codegym -
 Phân Tích Nhân Tố Khám Phá Exploratory Factor Analysic (Efa)
Phân Tích Nhân Tố Khám Phá Exploratory Factor Analysic (Efa) -
 Đánh Giá Của Khách Hàng Đối Với Nhóm Nhân Tố “Quảng Bá
Đánh Giá Của Khách Hàng Đối Với Nhóm Nhân Tố “Quảng Bá -
 Giải Pháp Dựa Trên Nhóm Yếu Tố Đồng Phục Nhân Viên
Giải Pháp Dựa Trên Nhóm Yếu Tố Đồng Phục Nhân Viên -
 Kết Quả Xử Lý, Phân Tích Spss
Kết Quả Xử Lý, Phân Tích Spss
Xem toàn bộ 147 trang tài liệu này.
(Nguồn: Kết quả xử lý SPSS 20)
Dựa vào bảng kết quả phân tích, mô hình 5 biến độc lập có giá trị R Square hiệu chỉnh là 0.376 tức là: độ phù hợp của mô hình là 37.6%. Hay nói cách khác, 37.6% độ biến thiên của biến phụ thuộc “Mức độ nhận biết” được giải thích bởi 5 nhân tố được đưa vào mô hình. Bên cạnh đó, ta nhận thấy giá trị R Square hiệu chỉnh là 0.376 khá là thấp (< 50%), nghĩa là mối quan hệ giữa biến độc lập và biến phụ thuộc không được chặt chẽ.
2.3.5.5. Kiểm định độ phù hợp của mô hình
Bảng 2.20: Kiểm định ANOVA
Model | Sum of Squares | Df | Mean Square | F | Sig. | |
1 | Regression | 25.888 | 5 | 5.178 | 13.854 | 0.000 |
Residual | 43.454 | 114 | 0.381 | |||
Total | 69.342 | 119 | ||||
(Nguồn: Kết quả xử lý SPSS 20)
Kết quả từ bảng ANOVA cho thấy giá trị Sig. = 0,000 rất nhỏ, cho phép nghiên cứu bác bỏ giả thiết rằng “Hệ số xác định R bình phương = 0” tức là mô hình hồi quy phù hợp. Như vậy mô hình hồi quy thu được rất tốt, các biến độc lập giải thích được khá lớn sự thay đổi của biến phụ thuộc “Mức độ nhận biết”.
2.3.5.6 Xem xét tự tương quan
Đại lượng Durbin – Watson được dùng để kiểm định tương quan của các sai số kề nhau. Dựa vào kết quả thực hiện phân tích hồi quy cho thấy, giá trị Durbin – Watson là 2.132 thuộc trong khoảng chấp nhận (1.6 đến 2.6). Vậy có thể kết luận là mô hình không xảy ra hiện tượng tự tương quan.
2.3.5.7. Xem xét đa cộng tuyến
Mô hình hồi quy vi phạm hiện tượng đa cộng tuyến khi có giá trị hệ số phóng đại phương sai (VIF – Variance Inflation Factor) lớn hơn hay bằng 10.
Từ kết quả phân tích hồi quy ở trên, ta có thể thấy rằng giá trị VIF của mô hình nhỏ nên nghiên cứu kết luận rằng mô hình hồi quy không vi phạm hiện tượng đa cộng tuyến.
2.3.5.8. Kiểm định phân phối chuẩn của phần dư
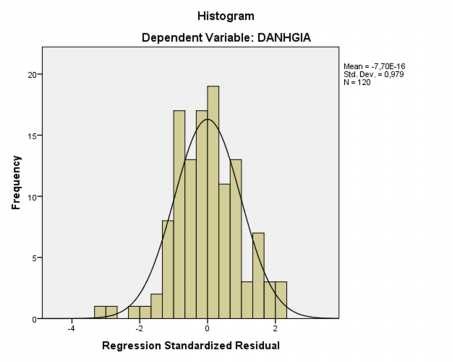
Biểu đồ 2.1: Biểu đồ tần số Histogram của phần dư chuẩn hóa
(Nguồn: Kết quả xử lý SPSS 20)
Phần dư có thể không tuân theo phân phối chuẩn vì những lý do như: sử dụng sai mô hình, phương sai không phải là hằng số, số lượng các phần dư không đủ nhiều để phân tích. Vì vậy chúng ta phải tiến hành kiểm định phân phối chuẩn của phần dư để xem xét sự phù hợp của mô hình đưa ra.
Từ biểu đồ trích từ kết quả phân tích hồi quy, ta có thể thấy rằng phần dư tuân theo phân phối chuẩn. Với giá trị Mean xấp xỉ -7.07E-16 và giá trị Std.Dev gần bằng 1 (0.979).
2.4. Kiểm định ONE SAMPLE T TEST (Kiểm định giá trị trung bình kết quả đánh giá của khách hàng với từng yếu tố ảnh hưởng đến mức độ nhận biết thương hiệu)
Sau khi xác định được các nhân tố thực sự có tác động đến mức độ nhận biết thương hiệu cũng như mức độ ảnh hưởng của nó, nghiên cứu tiến hành phân tích đánh giá của khách hàng đối với từng nhóm nhân tố này thông qua kết quả điều tra phỏng vấn mà nghiên cứu đã thu thập từ trước. Sau đó, tiến hành kiểm định One Sample T-Test để so sánh mức đánh giá trung bình của người tiêu dùng cho từng nhóm nhân tố đối với tổng thể với độ tin cậy 95%.
Cặp giả thuyết nghiên cứu:
- H0: Các đánh giá của khách hàng là giống nhau µ=4
- H1: Các đánh giá của khác hàng là không giống nhau µ≠4
Với µ là đánh giá của khách hàng đối với từng yếu tố ảnh hưởng đến mức
độ nhận biết thương hiệu.
Nếu: Sig. <0.05 ta bác bỏ giả thuyết H0, chấp nhận giả thuyết H1
Sig. ≥0.05 chưa có cơ sở bác bỏ H0
Bảng hỏi nghiên cứu sử dụng thang đo Likert với 5 mức độ, được chú thích với khách hàng như sau:
2 | 3 | 4 | 5 | |
Rất không đồng ý | Không đồng ý | Trung lập | Đồng ý | Rất đồng ý |
Đánh giá của khách hàng đối với nhân tố “Tên thương hiệu”
Khi được hỏi về tên thương hiệu của đồng phục BiCi đối với mức độ nhận diện thương hiệu, khách hàng đã trả lời và có những đánh giá:
Bảng 2.21: Đánh giá của khách hàng đối với nhân tố “Tên thương hiệu”
Mức độ đồng ý | Giá trị trung bình (T=4) | Mức ý nghĩa (Sig. T=4) | |||||
Rất không đồng ý | Không đồng ý | Trung lập | Đồng ý | Rất đồng ý | |||
% | % | % | % | % | |||
TH1 | 2.9 | 12.2 | 20.9 | 34.5 | 15.8 | 3.56 | 0.000 |
TH2 | 4.3 | 5.0 | 26.6 | 39.6 | 10.8 | 3.55 | 0.000 |
TH3 | 5.0 | 7.2 | 27.3 | 38.1 | 8.6 | 3.44 | 0.000 |
TH4 | 1.4 | 15.1 | 23.7 | 30.9 | 15.1 | 3.50 | 0.000 |
(Nguồn: Kết quả xử lý SPSS 20)
Giả thiết:
- H0: µ = 4 (Sig. > 0.05)
- H1: µ ≠ 4 (Sig. < 0.05)
Kết quả ở bảng trên cho thấy mức độ nhân biết thương hiệu của khách hàng đối với “Tên thương hiệu” đều ở mức lớn hơn 3 và hệ số Sig. <0.05. Do đó, ta bác bỏ giả thuyết H0 và chấp nhận H1. Từ kết quả kiểm định cho thấy giá trị trung bình giao động từ 3.44 đến 3.56 tất cả đều lớn hơn 3. Hay nói cách khác, mức độ nhận biết của khách hàng đối với nhóm nhân tố “tên thương hiệu” đều
nằm trên mức trung lập. Đánh giá của khách hàng đối với nhóm nhân tố “tên thương hiệu” đang ở mức trung bình không quá cao cũng không quá thấp. Các câu trả lời ở mức đồng ý chiếm tỷ lệ cao nhất đối với hầu hết các tiêu chí được đưa ra. Cụ thể:
Biến TH1: “Tên thương hiệu dễ đọc, dễ nhớ” và biến TH2 “Tên thương hiệu có ý nghĩa” được đánh giá tương đối bằng nhau (3.56 và 3.55) được khách hàng đánh giá ở mức cao nhất với giá trị trên mức trung lập và dưới mức đồng ý. Sở dĩ có sự đánh giá này là bởi thực tế, tên thương hiệu của một sản phẩm, một doanh nghiệp thường gắn gọn, có ý nghĩa giúp khách hàng dễ dàng ghi nhớ hơn.
Biến TH4: “Tên thương hiệu gây ấn tượng” và biến TH3 “Tên thương hiệu tạo khả năng liên tưởng” được đánh giá sát nhau (3.50 và 3.44) bởi lẽ hai yếu tố này có mối liên hệ đồng nhất với nhau, một thương hiệu gây ấn tượng sẽ gia tăng mức độ liên tưởng của khách hàng. Tuy nhiên, chỉ ở mức tương đối, không quá cao. Chính vì thế, để tăng khả năng liên tưởng thương hiệu, doanh nghiệp nên có những giải pháp để khách hàng có thể hiểu hơn về loại hình kinh doanh mà doang nghiệp đang tham gia.
Đánh giá của khách hàng đối với nhóm nhân tố “Logo”
Sau khi phỏng vấn khách hàng về yếu tố logo của thương hiệu CodeGym
đề tài thu được kết quả đánh giá như sau:
Bảng 2.22: Đánh giá của khách hàng đối với nhóm nhân tố “Logo”
Mức độ đồng ý | Giá trị trung bình (T=4) | Mức ý nghĩa (Sig. T=4) | |||||
Rất không đồng ý | Không đồng ý | Trung lập | Đồng ý | Rất đồng ý | |||
% | % | % | % | % | |||
LG1 | 4.3 | 12.9 | 27.3 | 36.0 | 5.8 | 3.30 | 0.000 |
LG2 | 3.6 | 13.7 | 25.2 | 33.8 | 10.1 | 3.38 | 0.000 |
LG3 | 3.6 | 12.2 | 32.4 | 28.1 | 10.1 | 3.33 | 0.000 |
LG4 | 4.3 | 13.7 | 30.2 | 30.2 | 7.9 | 3.28 | 0.000 |
(Nguồn: Kết quả xử lý SPSS 20)
Kết quả ở bảng trên cho thấy mức độ nhân biết thương hiệu của khách hàng đối với “Logo” đều ở mức lớn hơn 3 và hệ số Sig. <0.05. Do đó, ta bác bỏ giả thuyết H0 và chấp nhận H1. Nghĩa là mức độ nhận biết của khách hàng đối với nhóm nhân tố “Logo” đều khác mức trung lập, cụ thể là trên mức trung lập. Từ kết quả kiểm định cho thấy giá trị trung bình giao động từ 3.30 đến 3.38 tất cả đều lớn hơn 3. Đồng nghĩa với việc nhóm nhân tố “Logo” được khách hàng đánh giá không quá cao nhưng cũng không quá thấp. Tuy nhiên mức độ chênh lệch giữa các yếu tố không cao hay có thể nói là thấp (chênh lệch 0.1) điều nay chứng minh có sự liên kết giữa các yếu tố với nhau.
Trong đó “LG2 – Logo có ý nghĩa” (3.38), “LG3 – Logo có sự khác biệt” (3.33), “LG1- Logo dễ nhận biết” (3.30), “LG4 - Logo có tính mỹ thuật cao” (3.28). Nhìn chung, các tiêu chí đều có mức độ đánh giá gần sát nhau nhưng mức độ đánh giá đạt kết quả thu được là trên mức giá trị trung bình cao. Đây là điều đáng mừng cho công ty trong việc phát triển thương hiệu trên thị trường và
được xem là điểm mạnh trong các yếu tố tác động đến mức độ nhận biết thương hiệu của khách hàng. Logo thương hiệu với hai từ kết nối lại (Code-Gym) chồ thể hiện sự đồng hành, gắn bó cùng nhau phát triển nâng cao giá trị bản thân khách hàng nói chung và Công ty nói chung.
Đánh giá của khách hàng về nhóm nhân tố “Câu khẩu hiệu - Slogan”
Sau khi phỏng vấn khách hàng về yếu tố Slogan của thương hiệu CodeGym
đề tài thu được kết quả đánh giá như sau:
Bảng 2.23: Đánh giá của khách hàng đối với nhóm nhân tố “Slogan”
Mức độ đồng ý | Giá trị trung bình (T=4) | Mức ý nghĩa (Sig. T=4) | |||||
Rất không đồng ý | Không đồng ý | Trung lập | Đồng ý | Rất đồng ý | |||
% | % | % | % | % | |||
SLG1 | 4.3 | 10.1 | 37.4 | 30.8 | 9.2 | 3.28 | 0.000 |
SLG2 | 2.2 | 12.2 | 36.0 | 30.9 | 5.0 | 3.28 | 0.000 |
SLG3 | 3.6 | 12.2 | 25.2 | 33.1 | 12.2 | 3.44 | 0.000 |
SLG44.3 | 1.4 | 11.5 | 35.3 | 24.5 | 13.7 | 3.43 | 0.000 |
(Nguồn: Kết quả xử lý SPSS 20)
Kết quả kiểm định ở bảng trên cho thấy, giá trị Sig. của các tiêu chí “Câu khẩu hiệu dễ hiểu, dễ nhớ; Câu khẩu hiệu ngắn gọn; Câu khẩu hiệu có tính thu hút; Câu khẩu hiệu mang thông điệp ý nghĩa” thuộc nhân tố “slogan” đều nhỏ hơn 0,05 nên ta bác bỏ giả thuyết H0, chấp nhận giả thuyết H1, tức là đánh giá của khách hàng đối với các tiêu chí trong nhóm nhân tố slogan là khác 3, và căn cứ vào cột giá trị trung bình ta thấy mức đánh giá của khách hàng đều lớn hơn 3 nhưng các giá trị khách hàng đánh giá không quá cao so với giá trị 3, tương ứng chỉ từ 3,28 đến 3,44.