thể tạm thời trong một thời gian nhất định hoặc lâu dài được lưu trữ bền vững trong CSDL, do hệ thống hoặc do người dùng tạo ra.
Cài đặt OID cho các đối tượng bền vững dựa trên định danh logic hoặc định danh vật lý. Định danh vật lý POID (physical OID) cung cấp giá trị OID đồng nhất vớiđịa chỉ vật lý của đối tượng. Ưu điểm là có thể nhận đối tượng trực tiếp qua OID của nó, nhược điểm là tất cả các đối tượng cha và các chỉ mục đều phải được cập nhật mỗi khi một đối tượng được di chuyển đến một trang khác. Phương pháp dùng định danh logic LOID (logical OID) cấp phát một OID duy nhất cho mỗi đối tượng trên toàn bộ hệ thống. LOID có thể được sinh ra bằng cách sử dụng một bộ đếm duy nhất trên toàn bộ hệ thống hoặc bằng cách gộp định danh của server với một bộ đếm ở mỗi server. Vì OID là bất biến nên không phải trả chi phí nào khi di chuyển đối tượng. Điều này có được qua một bảng OID liên kết mỗi OID với địa chỉ đối tượng vật lý, bù lại phải tốn chi phí tìm kiếm trên bảng OID cho mỗi lần truy xuất đối tượng. Để tăng tốc độ tìm kiếm, bảng OID thường được tổ chức dạng bảng băm hoặc cây B+.
Cài đặt định danh cho đối tượng tạm thời thường sử dụng các kỹ thuật được dùng trong các ngôn ngữ lập trình, và cũng có thể thuộc loại logic hoặc vật lý.
Trong các hệ quản trị CSDL phân tán, dùng LOID có thể thích hợp hơn vì các thao tác như làm tái tụ dữ liệu, nhân bản và phân mảnh xảy ra thường xuyên.
1.2.5.2. Ánh xạ con trỏ
Trong các hệ CSDL đối tượng, người ta có thể duyệt từ một đối tượng đến một đối tượng khác bằng cách dùng biểu thức đường dẫn (path expression) có chứa các thuộc tính với giá trị của chúng dựa trên đối tượng. Về cơ bản biểu thức đường dẫn đều là con trỏ. Thông thường trên đĩa, định danh đối tượng được dùng để biểu diễn những con trỏ này. Tuy nhiên trong bộ nhớ, người ta muốn dùng các con trỏ trên bộ nhớ trong để duyệt từ đối tượng này sang đối tượng khác. Quá trình chuyển phiên bản từ con trỏ trên bộ nhớ ngoài thành phiên bản con trỏ trên bộ nhớ trong gọi là ánh xạ con trỏ (pointer swizzling). Các lược đồ dựa trên phần cứng và dựa trên phần mềm là hai loại ánh xạ con trỏ.
1.2.5.3. Di trú đối tượng
Trong các hệ phân tán, theo thời gian, các đối tượng cần được di chuyển giữa các vị trí. Điều này làm phát sinh một số vấn đề. Trước hết là đơn vị di trú. Ba khả năng có thể được xem xét khi di trú các lớp:
Mã nguồn phải được di chuyển và biên dịch lại tại vị trí đích.
Phiên bản đã được biên dịch của một lớp được di trú giống như mọi đối tượng khác.
Mã nguồn được di chuyển nhưng không di chuyển các thao tác của nó đã được biên dịch, mà sẽ dùng đến chiến lược di chuyển muộn.
Vấn đề tiếp theo là việc di chuyển đối tượng phải được theo vết để có thể tìm ra vị trí mới của chúng. Một cách thường dùng theo vết các đối tượng là để lại các đại diện hoặc các đối tượng ủy nhiệm. Di trú đối tượng có thể được thực hiện dựa trên trạng thái hiện hành của chúng. Đối tượng có thể ở một trong bốn trạng thái:
Sẵn sàng (ready): Không cần kích hoạt, sẵn sàng nhận thông báo
Hoạt động (Active): Hiện có mặt trong một hoạt động
Chờ (waiting): Đã kích hoạt một đối tượng khác và đang chờ trả lời
Treo (suspended): Hiện tạm thời không sẵn sàng đối với kích hoạt Các đối tượng đang trong trạng thái hoạt động hoặc chờ không được phép di trú
vì hoạt động mà chúng đang tham gia có thể bị phá vỡ. Việc di trú gồm các bước:
Chuyển tải đối tượng từ nguồn đến đích, và
Tạo ra một ủy nhiệm tại nguồn để thay thế đối tượng ban đầu
Một vấn đề khác nảy sinh là khi di chuyển các đối tượng hợp phần, chuyển tải một đối tượng hợp phần có thể phải chuyển tải cả những đối tượng được đối tượng hợp phần tham chiếu đến. Điều này được đề cập trong phần xử lý truy vấn.
1.2.5.4. Lưu trữ đối tượng phân tán
Trong lưu trữ đối tượng phân tán cần quan tâm đến việc phân nhóm đối tượng (object clustering) và dọn rác phân tán (distributed garbage collection).
Mô hình đối tượng về cơ bản mang tính khái niệm và ánh xạ mô hình khái niệm thành mô hình lưu trữ vật lý là bài toán kinh điển của CSDL. Trong các hệ CSDL đối tượng chúng ta có hai mối quan hệ giữa các kiểu: sinh kiểu con và hợp phần. Các mối quan hệ này có vai trò quan trọng trong quá trình phân nhóm đối tượng. Phân nhóm đối tượng đề cập đến nhóm các đối tượng ở mức vật lý theo những tính chất chung nhằm tăng tốc độ truy xuất đối tượng.
Một ưu điểm của các hệ đối tượng là các đối tượng có thể tham chiếu đến các đối tượng khác bằng định danh đối tượng. Trong một hệ đếm tham chiếu, mỗi đối tượng có một bộ đếm ghi số lượng các tham chiếu đến nó. Bộ nhớ dành cho một đối tượng được tái sử dụng khi giá trị bộ đếm bằng 0.
1.2.6. Quản lý giao dịch
Các yêu cầu quan trọng trong quản lý giao dịch trong các hệ CSDL HĐT:
Ngoài việc đảm bảo đồng bộ hóa các thao tác Read và Write, bộ quản lý giao dịch phải có khả năng giải quyết được các thao tác trừu tượng (abstract operation).
Đáp ứng được sự đồng bộ hóa việc truy xuất đến các đối tượng hợp phần và đối tượng phức hợp. Đồng bộ hóa những đối tượng này đòi hỏi phải đồng bộ hóa truy xuất đến các đối tượng thành phần.
Nhiều ứng dụng đòi hỏi phải hỗ trợ các hoạt động trong thời gian dài trải qua nhiều giờ, nhiều ngày hoặc thậm chí là nhiều tuần lễ. Vì thế cơ chế giao dịch phải hỗ trợ việc chia sẻ kết quả từng thành phần.
Có khả năng theo dòi các biến cố và việc thực thi của các hoạt động được hệ thống kích hoạt.
1.3. Đánh giá hiệu năng CSDL HĐT với thư viện OO7
1.3.1. Giới thiệu
Ngoài vấn đề về chức năng và độ phù hợp của loại CSDL HĐT trong các bài toán hướng đối tượng thì vấn đề hiệu năng của chúng cũng luôn được cân nhắc nhằm đánh giá xem liệu CSDL HĐT đã thực sự hiệu quả trong quá trình triển khai
dự án. Một số tiêu chuẩn đánh giá hiệu năng CSDL HĐT đã được đưa ra, trong đó OO7 (The OO7 benchmark) [17] được coi là tiêu chuẩn và thư viện khá phổ biến do nó cung cấp khá đầy đủ các kịch bản kiểm thử nhằm đánh giá các loại CSDL HĐT từ nhiều góc độ khác nhau. Trong phần này sẽ trình bày về thư viện OO7 và kết quả đánh giá hiệu năng với CSDL HĐT Versant. OO7 đánh giá CSDL HĐT các tiêu chí chính sau:
- Tốc độ xử lý trong việc duyệt (traversal) các đối tượng, kể cả sử dụng bộ nhớ đệm hay duyệt trực tiếp trên ổ đĩa.
- Mức độ hiệu quả trong việc thay đổi đối tượng (tạo, xóa và cập nhật), kể cả đối tượng sử dụng index và không sử dụng index, dữ liệu lặp và dữ liệu dư thừa.
- Hiệu năng của việc xử lý các loại câu truy vấn đối tượng.
1.3.2. Một số nghiên cứu khác về đánh giá hiệu năng CSDL HĐT
Tiêu chuẩn OO1 (Object Operations Benchmark) [18], còn được gọi là tiêu chuẩn Sun Benchmark, lần đầu tiên được đưa ra để đánh giá hiệu năng các hệ thống CSDL cho các ứng dụng thiết kế công nghệ. Mặc dù phiên bản đầu tiên còn khá đơn giản nhưng được coi là tiền thân của tiêu chuẩn đánh giá CSDL HĐT sau này. Một chuẩn nữa là HyperModel [11] được phát triển bởi Tektronix. So với OO1 thì HyperModel có lược đồ dữ liệu đầy đủ hơn (bao gồm nhiều dạng quan hệ khác nhau và xử lý các tập dữ liệu nguyên thủy lớn hơn) và đưa ra nhiều thao tác đánh giá hơn (bao gồm đầy đủ các hàm như tìm kiếm, duyệt và cập nhật).
Mặc dù OO1 và HyperModel cũng đưa ra được những kết quả nhất định trong lĩnh vực đánh giá hiệu năng CSDL HĐT nhưng chưa đầy đủ, ví dụ như chúng chưa bao gồm mô phỏng các đối tượng phức hợp, đây là yêu cầu thực tế cho các dạng CSDL HĐT trong thực tế, ngoài ra hai bộ thư viện này không bao gồm đầy đủ các bộ kiểm tra cho nhiều dạng duyệt hoặc cập nhất đối tượng như có index hoặc không có index. Do đó các nhà nghiêu cứu tìm cách đưa ra một bộ tiêu chuẩn khác đầy đủ hơn nhằm đánh giá các vấn đề về hiệu năng và tính năng của các CSDL HĐT, và OO7 là một thư viện được sử dụng rộng rãi hơn trong việc đánh giá hiệu năng CSDL HĐT.
1.3.3. Thiết kế CSDL của OO7
Mục tiêu của thiết kế OO7 là kiểm tra nhiều khía cạnh khác nhau của hiệu năng hệ thống đặc biệt là cấu trúc CSDL và các thao tác xử lý đối tượng. Các đặc tả kỹ thuật của OO7 bao gồm lược đồ dữ liệu được mô tả ở chi tiết cho các nhà phát triển nếu muốn tự cài đặt thư viện. Những thông tin đặc tả cơ bản nhất của OO7 đưa ra ở phần này dựa trên bản cài đặt Java, bao gồm cả CSDL mẫu và kết quả chạy thử trên một số hệ thống CSDL HĐT như Db4o hay Versant. Theo trang web xếp hạng các hệ thống CSDL HĐT 2016 [55] thì Cáche, Db4o và Versant là ba hệ thống dẫn đầu trong các hệ thống CSDL HĐT.
Chú ý là bản thiết kế CSDL chạy thử được đưa ra ở mức độ tổng quát, mục tiêu là nhằm tìm hiểu và đánh giá các hệ thống CSDL HĐT. CSDL được thiết kế với ba cấp độ: nhỏ, trung bình và lớn. Bảng 1.1 mô tả các tham số CSDL chính của OO7. Hai thành phần chính của bản thiết kế dữ liệu OO7 tập “Đối tượng nguyên tố” (atomic object) và “Đối tượng phức hợp” (composite object). Tập hợp các đối tượng nguyên tố với các kết nối theo mô hình đồ thị sẽ cấu thành một đối tượng phức hợp, mỗi thành phần phức hợp tương ứng với một thiết kế cơ bản nào đó của ứng dụng thực tế. Tập các thành phần phức hợp này được gọi là thư viện thiết kế của OO7.
Bảng 1.1: Các tham số CSDL chính của OO7
Mô tả | Small | Medium | Large | |
NumModule | Số lượng module | 1 | 1 | 10 |
NumCompPerModule | Số lượng đối tượng phức hợp của một module | 500 | 500 | 500 |
NumAtomicPerComp | Số lượng đối tượng nguyên tố trong một đối tượng phức hợp | 200 | 200 | 200 |
NumConnPerAtomic | Số lượng kết nối của một đối tượng nguyên tố | 3, 6, 9 | 3, 6, 9 | 3, 6, 9 |
DocumentSize (bytes) | Kích cỡ văn bản | 2K | 20K | 20K |
Có thể bạn quan tâm!
-

 Xử lý và tối ưu hóa truy vấn trong cơ sở dữ liệu hướng đối tượng phân tán - 2
Xử lý và tối ưu hóa truy vấn trong cơ sở dữ liệu hướng đối tượng phân tán - 2 -
 Mô Hình Cơ Sở Dữ Liệu Hướng Đối Tượng Phân Tán
Mô Hình Cơ Sở Dữ Liệu Hướng Đối Tượng Phân Tán -
 Quản Lý Dữ Liệu Phân Tán Với Các Mức Trong Suốt Khác Nhau
Quản Lý Dữ Liệu Phân Tán Với Các Mức Trong Suốt Khác Nhau -
 Phân Mảnh Và Cấp Phát Lớp Các Đối Tượng Phân Tán
Phân Mảnh Và Cấp Phát Lớp Các Đối Tượng Phân Tán -
 Các Thông Tin Đầu Vào Của Bài Toán Phân Mảnh Dọc Và Cấp Phát Lớp
Các Thông Tin Đầu Vào Của Bài Toán Phân Mảnh Dọc Và Cấp Phát Lớp -
 Ma Trận Sqf Sau Biến Đổi (Chuyển Vị Của Ma Trận Qsf Sau Biến Đổi).
Ma Trận Sqf Sau Biến Đổi (Chuyển Vị Của Ma Trận Qsf Sau Biến Đổi).
Xem toàn bộ 136 trang tài liệu này.
100K | 1M | 1M | ||
NumAssmPerAssm | Số lượng Assembly con trong một Assembly lớn hơn | 3 | 3 | 3 |
NumAssmLevels | Số cấp độ Assembly | 7 | 7 | 7 |
NumCompPerAssm | Số lượng đối tượng phức hợp đóng trong một gói Assembly | 3 | 3 | 3 |
Để mô phỏng đối tượng gần với thực tế nhất, mỗi đối tượng phức hợp và đối tượng nguyên tố bao gồm một số thuộc tính cơ bản như ID kiểu int, BuildDate, một mảng dữ liệu, một vài thuộc tính cơ bản khác và kèm theo một văn bản. Văn bản cũng được mô tả bởi các tham số cơ bản như DocID, DocTitle, Text và độ lớn của văn bản được thiết lập bởi tham số DocumentSize. Các kịch bản đánh giá hiệu năng sẽ sử dụng các thuộc tính trên ví dụ như kiểm tra, duyệt hay cập nhật để đo thời gian xử lý trong quá trình thực thi.
Các đối tượng nguyên tố kết nối với nhau để tạo thành thành phần phức hợp, được biểu diễn bởi tham số NumAtomicPerComp, và sự liên kết giữa các đối tượng nguyên tố thông qua tham số NumConnPerAtomic hình thành nên một đồ thị kết nối giữa các đối tượng nguyên tố trong một đối tượng phức hợp như Hình 1.5.
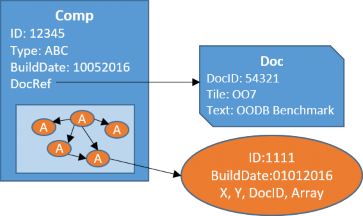
Hình 1.5: Đồ thị kết nối đối tượng của OO7
Mỗi thiết kế CSDL gồm nhiều module và mỗi module bao gồm nhiều
assembly mà ở đó một assembly là sự đóng gói của nhiều đối tượng phức hợp và
nguyên tố với nhau và có thể đóng gói ngay cả các assembly. Ở cấp độ cơ sở, được gọi là base assembly, gồm sự đóng gói các đối tượng phức hợp và cơ sở, các đối tượng này có thể được thiết kế ở cấp độ dùng chung hoặc dùng riêng (shared và unshared), số lượng đối tượng trên một assembly được đặt bởi tham số NumCompPerAssm. Các assembly lại có thể được đóng gói để hình thành các assemply phức hợp và các assembly này được liên kết theo hình cây với một số cấp độ nhất định được mô tả qua tham số NumAssmLevels. Số lượng đối tượng phức hợp trong một module rải rác ở các assembly cũng được giới hạn bởi tham số NumCompPerModule.
Mỗi module được thiết kế gồm một đối tượng dữ liệu kích thước lớn để mô phỏng trong việc đánh giá hiệu năng với các đối tượng rất lớn, đối tượng này được thiết lập qua tham số ManualSize. Với thiết kế như vậy, mô hình hóa bản thiết kế CSDL của OO7 được minh họa như Hình 1.6.

Hình 1.6: Mô hình hóa thiết kế CSDL của OO7
Mọi đối tượng và các thuộc tính của bản thiết kế OO7 đưa ra đều nhằm mục đích mô phỏng tốt nhất các bài toán hướng đối tượng trong thực tế. Kể cả với dạng
hướng đối tượng phân tán thiết kế trên cũng có thể mô phỏng được các đối tượng các địa điểm cục bộ hoặc phân tán khác nhau mà ở đó mỗi module được minh họa như một trạm xử lý của hệ phân tán.
1.3.4. Kịch bản đánh giá hiệu năng
1.3.4.1. Duyệt đối tượng
Duyệt đối tượng dữ liệu là kịch bản chính trong việc đánh giá hiệu năng của CSDL HĐT, khác với truy vấn đơn thuần, thao tác này duyệt từ đối tượng này tới đối tượng có liên kết khác, với từng đối tượng được duyệt kịch bản sẽ gọi một hàm nào đó của đối tượng này. Các kịch bản duyệt như trong Bảng 1.2.
Bảng 1.2: Các kịch bản duyệt đối tượng
Mô tả bước thực hiện | |
Trav #1: Duyệt cơ bản | - Duyệt cây assembly từ mức cao tới mức cơ sở - Tại mỗi assembly cơ sở sẽ duyệt các đối tượng Composite của riêng nó (unshared) - Tại mỗi đối tượng Composite sẽ thực hiện thuật toán tìm kiếm theo chiều sâu (DFS) các đối tượng nguyên tố trong cây đồ thị - Trả về số lượng đối tượng nguyên tố được thăm |
Trav #2: Duyệt cập nhật | - Giống như kịch bản #1, nhưng sẽ cập nhật đối tượng nguyên tố trong quá trình duyệt DFS tại từng đối tượng Composite - Có 3 kịch bản update như sau o Update một đối tượng nguyên tố (#2a) o Update tất cả đối tượng nguyên tố (#2b) o Update N lần giống nhau cho tất cả các đối tượng nguyên tố (#2c) - Hàm update là chuyển đổi giá trị thuộc tính của đối tượng nguyên tố - Trả về tổng số lần cập nhật được thực hiện - Giá trị N được thiết lập bởi tham số UpdateRepeatCnt |