Mô tả bước thực hiện | |
Trav #3: Duyệt cập nhật có sử dụng index | - Giống như kịch bản #2, nhưng hàm update sử dụng thuộc tính ngày của đối tượng nguyên tố và thuộc tính này được sử dụng index (cũng có 3 kết quả là #3a, #3b, #3c) - Hàm update sẽ tăng lên 1 nếu giá trị ngày là lẻ và giảm nếu là chẵn |
Trav #6: Duyệt gốc | - Giống như kịch bản #1 nhưng không thực hiện duyệt DFS toàn bộ đồ thị đối tượng nguyên tố mà chỉ duyệt đối tượng nguyên tố gốc |
Trav #8: Duyệt đối tượng manual | - Duyệt đối tượng lớn manual và đếm số lần xuất hiện 1 ký tự bất kỳ xuất hiện trong đối tượng này (kiểm tra việc duyệt từng ký tự trong xâu đối tượng) |
Trav #9: Duyệt đối tượng manual | - Kiểm tra xem ký tự đầu tiên và ký tự cuối cùng của đối tượng manual có giống nhau không (kiểm tra việc tìm kiếm tới ký tự cuối cùng) |
Có thể bạn quan tâm!
-

 Mô Hình Cơ Sở Dữ Liệu Hướng Đối Tượng Phân Tán
Mô Hình Cơ Sở Dữ Liệu Hướng Đối Tượng Phân Tán -
 Quản Lý Dữ Liệu Phân Tán Với Các Mức Trong Suốt Khác Nhau
Quản Lý Dữ Liệu Phân Tán Với Các Mức Trong Suốt Khác Nhau -
 Một Số Nghiên Cứu Khác Về Đánh Giá Hiệu Năng Csdl Hđt
Một Số Nghiên Cứu Khác Về Đánh Giá Hiệu Năng Csdl Hđt -
 Các Thông Tin Đầu Vào Của Bài Toán Phân Mảnh Dọc Và Cấp Phát Lớp
Các Thông Tin Đầu Vào Của Bài Toán Phân Mảnh Dọc Và Cấp Phát Lớp -
 Ma Trận Sqf Sau Biến Đổi (Chuyển Vị Của Ma Trận Qsf Sau Biến Đổi).
Ma Trận Sqf Sau Biến Đổi (Chuyển Vị Của Ma Trận Qsf Sau Biến Đổi). -
 Thuật Toán Attrfrag Phân Mảnh Dựa Trên Tương Quan Thuộc Tính
Thuật Toán Attrfrag Phân Mảnh Dựa Trên Tương Quan Thuộc Tính
Xem toàn bộ 136 trang tài liệu này.
1.3.4.2. Truy vấn đối tượng
Bảng 1.3 là các kịch bản cơ bản sử dụng ngôn ngữ truy vấn khai báo để truy vấn đối tượng của CSDL HĐT. Điểm chú ý là việc truy vấn đối tượng này có thể được cung cấp sẵn trong ngôn ngữ truy vấn, hoặc cũng có thể phải tùy biến và bổ sung thêm nhiều thủ tục mới hoàn thành công việc. Ví dụ, có những CSDL HĐT hỗ trợ tìm kiếm khoảng cho thuộc tính date, nhưng với CSDL HĐT mà chưa hỗ trợ thì phải liệt kê toàn bộ và sử dụng thêm một số hàm so sánh mức lập trình thủ tục để tìm kiếm ra đối tượng thỏa mãn.
Bảng 1.3: Kich bản truy vấn
Mô tả bước thực hiện | |
Query #1: tìm kiếm chính xác | - Tạo ngẫu nhiên giá trị OID - Tìm kiếm đối tượng nguyên tố theo giá trị OID được sinh ra - Lặp lại thao tác trên vài lần (theo tham số Query1RepeatCnt) |
Query #2: tìm kiếm theo khoảng | - Thiết lập khoảng giá trị ngày đảm bảo gồm X% đối tượng nguyên tố có giá trị ngày thuộc khoảng này (Query2Percent=1%) - Tìm kiếm các đối tượng nguyên tố có thuộc tính ngày thỏa mãn |
Mô tả bước thực hiện | |
Query #3: tìm kiếm theo khoảng | - Giống như kịch bản #2 với Query3Percent=10% |
Query #4: tìm kiếm đối tượng văn bản | - Tạo ngẫu nhiên giá trị Title - Tìm kiếm các assembly mà chứa đối tượng Composite có liên kết với Document sử dụng title được sinh ra - Lặp lại thao tác trên vài lần (theo tham số Query4RepeatCnt) |
Query #5: tìm kiếm theo khoảng | - Tìm kiếm các base assembly có 1 đối tượng Composite mà builtDate của nó lớn hơn buildDate của assembly |
Query #7: tìm kiếm liệt kê | - Liệt kê toàn bộ đối tượng nguyên tố |
Query #8: tìm kiếm liên kết | - Tìm kiếm các cặp Document và đối tượng nguyên tố có liên kết DocID |
1.3.5. Kết quả thực nghiệm
1.3.5.1.Môi trường thực nghiệm
Bảng 1.4: Môi trường thực nghiệm
- Máy để bàn Intel i3-4150 3.5GHz, 8GB RAM - Windows 64 bit | |
Phần mềm và thư viện | - CSDL Db4o version 8.0.249 - Java 1.8 |
CSDL HĐT được cấu hình theo một số tham số khác nhau nhằm kiểm tra kết quả từ nhiều góc độ, một số tham số của CSDL được thay đổi như sau:
- Sử dụng cấu hình CSDL dạng nhỏ (small) với cấu hình client/server và dạng tệp trực tiếp trên ổ đĩa (embedded file)
- Sử dụng index (index on) và không sử dụng index (index off)
- Tải dữ liệu dạng đầy đủ (eager load) và dạng không đầy đủ (lazy load)
- Chương trình bổ sung CSDL dạng vừa (medium) có thiết lập sẵn index và tải dữ liệu đầy đủ. Kết quả thực nghiệm cho thấy CSDL dạng vừa và lớn cần tới dòng máy chủ cao cấp để có thể chạy được thực nghiệm này, với cấu hình máy để bàn một số thao tác thực hiện trong khoảng từ 10 đến 30 ngày.
1.3.5.2. Kết quả duyệt
a. Biểu đồ thao tác duyệt dạng COLD
Biểu đồ thao tác duyệt dạng COLD Hình 1.7, một số nhận xét từ biểu đồ như sau:
- Khi sử dụng index kết quả có tốt hơn khoảng 5% thời gian xử lý, kết quả này không thực sự phản ánh tốt tính năng index do phần lớn các thao tác duyệt có xử lý update dữ liệu (index phù hợp cho việc đọc hơn là update dữ liệu).
- Với thao tác duyệt đầy đủ dữ liệu như Trav1/Trav2x/Trav3x thì kết quả tải dữ liệu không đầy đủ không tốt hơn so với dạng tải dữ liệu đầy đủ. Tuy nhiên với dạng duyệt không toàn bộ như Trav6 thì kết quả tải dữ liệu không đầy đủ tốt hơn nhiều so với dạng tải dữ liệu đầy đủ, đây chính là ưu điểm của việc sử dụng tính năng tải dữ liệu không đầy đủ khi duyệt dữ liệu rút gọn.
- Với CSDL dạng tệp trực tiếp trên ổ đĩa, kết quả tốt hơn nhiều. Với CSDL dạng vừa, thời gian tăng đột biến từ 8-10 lần do phải xử lý số lượng dữ liệu rất lớn.
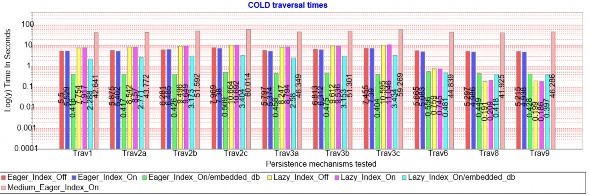
Hình 1.7: Biểu đồ thao tác duyệt dạng COLD
b. Biểu đồ thao tác duyệt dạng HOT
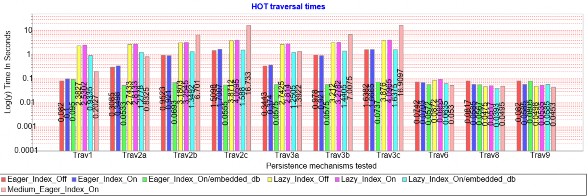
Hình 1.8: Biểu đồ thao tác duyệt dạng HOT
Biểu đồ thao tác duyệt dạng HOT trong Hình 1.8, một số nhận xét từ biểu đồ như sau:
- Duyệt dạng HOT cho kết quả tốt hơn rất nhiều so với dạng COLD do dữ liệu được tái sử dụng và cache trong bộ nhớ. Phần lớn các thao tác duyệt chỉ đọc không quá một giây và các thao tác duyệt có cập nhật dữ liệu cũng không quá một giây đối với CSDL dạng nhỏ.
- Khác với dạng COLD, kết quả của tải dữ liệu không đầy đủ với các thao tác duyệt đầy đủ có cập nhật Trav1/Trav2x/Trav3x kém hơn nhiều so với dạng tải dữ liệu đầy đủ (thời gian cao gấp khoảng 3 lần). Với các thao tác duyệt không đầy đủ Trav6/Trav8/Trav9 thì kết quả là tương đương giữa tải đữ liệu không đầy đủ và tải dữ liệu đầy đủ.
1.3.5.3. Kết quả truy vấn
a. Biểu đồ truy vấn dạng COLD
Biểu đồ truy vấn dạng COLD trong Hình 1.9, một số nhận xét từ biểu đồ như sau:
- Kết quả nạp dữ liệu không đầy đủ thể hiện ưu điểm với các thao tác truy vấn dữ liệu, kết quả tốt hơn nhiều so với nạp dữ liệu đầy đủ. Ví dụ với Query1, nạp dữ liệu không đầy đủ chỉ mất dưới một giây, còn nạp dữ liệu đầy đủ cần tới hơn 7 giây.
- Với truy vấn liệt kê toàn bộ đối tượng Query7 và truy vấn tìm kiếm có quan hệ liên kết Query8, kết quả sử dụng tải dữ liệu không đầy đủ còn tốt hơn rất nhiều. Với CSDL dạng vừa thì Query7 mất tới vài ngày và Query8 mất tới cả tháng.
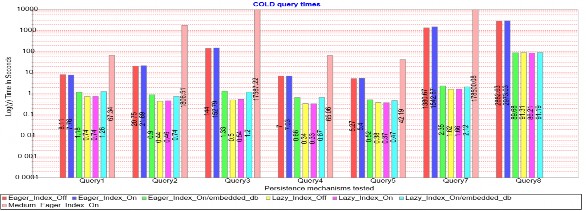
Hình 1.9: Biểu đồ truy vấn dạng COLD
b. Biểu đồ truy vấn dạng HOT
Biểu đồ truy vấn dạng HOT trong Hình 1.10, một số nhận xét từ biểu đồ như sau:
- Truy vấn dạng HOT cho kết quả rất tốt so với dạng COLD với các dạng tìm kiếm theo giá trị như các truy vấn từ Query1 đến Query5.
- Còn với dạng truy vấn liệt kê toàn bộ Query7 và truy vấn tìm kiếm quan hệ liên kết như Query8 thì kết quả không khác nhiều so với dạng HOT.
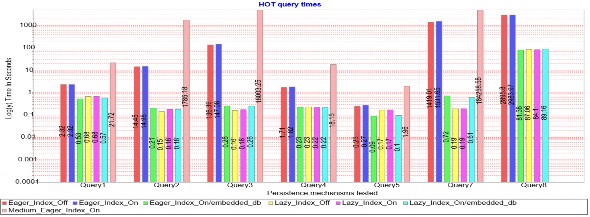
Hình 1.10: Biểu đồ truy vấn dạng HOT
1.4. Kết luận chương 1
CSDL quan hệ có những hạn chế khi áp dụng với các hệ thống lớn, phức tạp. Mô hình CSDL HĐT được đề xuất để giải quyết các vấn đề phức tạp trong các hệ thống ứng dụng. Đặc trưng chính của CSDL HĐT là cung cấp khả năng đặc tả cấu trúc của các đối tượng phức và quản lý hoạt động của các đối tượng.
CSDL HĐT phát triển trong môi trường mạng hình thành mô hình CSDL hướng đối tượng phân tán. Kiến trúc của hệ CSDL HĐT PT chủ yếu là kiến trúc clien/server. Trong các vấn đề của CSDL HĐT PT, xử lý truy vấn là một hướng nghiên cứu quan trọng. Xử lý truy vấn phân tán liên quan đến việc đánh giá hiệu năng, phân mảnh và cấp phát lớp các đối tượng, tối ưu hóa truy vấn.
Chương một của luận án đã trình bày các khái niệm và các vấn đề trong CSDL HĐT và CSDL HĐT PT, đồng thời chương này cũng đã đề cập đến việc đánh giá hiệu năng các CSDL HĐT bằng thư viện OO7.
Trong chương tiếp theo luận án sẽ trình bày những kiến thức và đề xuất các thuật toán để thực hiện việc phân mảnh và cấp phát lớp các đối tượng.
CHƯƠNG 2 - PHÂN MẢNH VÀ CẤP PHÁT LỚP CÁC ĐỐI TƯỢNG PHÂN TÁN
Trong một hệ quản trị CSDL phân tán, dữ liệu sẽ được lưu trữ ở đâu là một câu hỏi quan trọng. Dữ liệu có thể được lưu trữ tập trung tại một trạm, hay được chia ra và phân tán trên các trạm, hoặc nhân bản dữ liệu trên toàn bộ các trạm. Có rất nhiều lựa chọn, cách cấu hình tốt nhất về vị trí dữ liệu cho một hệ thống phân tán cho trước là một bài toán khó.
Để cải tiến hiệu năng của xử lý truy vấn, phương pháp thiết kế dữ liệu phân tán với mục tiêu là đặt dữ liệu tại nơi mà các truy vấn có thể truy cập hiệu quả nhất. Nếu dữ liệu được lưu trữ tại một trạm khác với trạm thực hiện truy vấn, dữ liệu phải được truy cập từ xa. Thông thường, truy cập từ xa chậm hơn so truy cập cục bộ vì dữ liệu phải được truyền qua mạng. Tối ưu nhất là dữ liệu và truy vấn lưu trữ cục bộ cùng một trạm, tuy nhiên điều này không phải lúc nào cũng có thể xảy ra. Nếu nhân bản toàn bộ dữ liệu ở tất cả các trạm sẽ gặp phải vấn đề hạn chế về lưu trữ và xử lý của từng trạm cũng như chi phí cho việc đồng bộ hóa dữ liệu khi có các cập nhật mới tới các trạm.
Bài toán thiết kế dữ liệu phân tán chia thành hai bài toán chính: phân mảnh và cấp phát. Phân mảnh là chia nhỏ dữ liệu thành các phần nhỏ hơn. Cấp phát là định vị các mảnh vào các trạm. Với mô hình đối tượng việc phân mảnh nảy sinh các vấn đề phức tạp mới do các đặc tính của hướng đối tượng, đó là tính đóng gói, kế thừa, phân cấp lớp. Chương 2 của luận án trình bày mô hình phân mảnh và cấp phát trong CSDL HĐT PT và đề xuất hai thuật toán: Thuật toán AttrFrag thực hiện phân mảnh dựa trên tương quan thuộc tính. Thuật toán FragAlloS thực hiện phân mảnh và cấp phát đồng thời trong CSDL HĐT PT. Các kết quả đã được đăng ở các bài báo (1), (3), và (4).
2.1. Phân mảnh và cấp phát lớp các đối tượng
2.1.1. Mục tiêu của phân mảnh và cấp phát
Mục tiêu tổng quát của phân mảnh và cấp phát CSDL phân tán là nâng cao hiệu năng của hệ thống, mục tiêu tổng quát này được chia thành các mục tiêu cụ thể như sau [4]:
Tăng tính cục bộ xử lý, tăng hiệu quả xử lý truy vấn: Phân tán dữ liệu để làm cực đại hóa tính xử lý nghĩa là đặt dữ liệu ở càng gần nơi các ứng dụng xử lý chúng càng tốt.
Tăng tính sẵn sàng và độ tin cậy của dữ liệu.
Điều phối tải làm việc hợp lý: Cực đại hóa mức độ thực hiện song song của các ứng dụng.
Giảm chi phí: Chi phí này bao gồm chi phí lưu trữ dữ liệu, chi phí truyền dữ liệu, chi phí đọc dữ liệu.
Hoạt động thiết kế phân tán gồm hai bước chính: phân mảnh (fragmentation) và cấp phát (allocation). Phân mảnh là chia CSDL thành các phần nhỏ hơn gọi là các mảnh (fragment). Cấp phát là đặt các mảnh tại các trạm thích hợp trong mạng máy tính.
Thiết kế phân tán tối ưu là bài toán hết sức phức tạp vì có quá nhiều yếu tố ảnh hưởng đến thiết kế. Các thông tin cần thiết cho thiết kế phân tán có thể phân chia thành bốn loại: thông tin CSDL, thông tin ứng dụng, thông tin về mạng và thông tin về hệ thống máy tính. Thông thường thông tin CSDL và thông tin ứng dụng được sử dụng trong các thuật toán phân mảnh. Thông tin về mạng và thông tin về hệ thống máy tính có bản chất hoàn toàn định lượng và được sử dụng trong các mô hình cấp phát.
2.1.2. Phân mảnh lớp các đối tượng
2.1.2.1. Các vấn đề trong phân mảnh lớp các đối tượng
Phân mảnh trong CSDL HĐT PT dẫn đến nhiều vấn đề phức tạp mới do việc đóng gói các phương thức cùng với trạng thái các đối tượng. Một đối tượng được