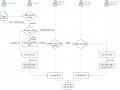
Phân tích
Xác định các yêu cầu
nghiệp vụ
Kiến trúc tổng thể
Thiết kế
Lập kế hoạch vĩ mô
cho dự án
Lập kế hoạch
Đặc tả chi tiết dự án
Có thể bạn quan tâm!
-

 Ứng dụng bi Business intelligence trong bài toán thẩm định tài sản bảo đảm của ngân hàng - 1
Ứng dụng bi Business intelligence trong bài toán thẩm định tài sản bảo đảm của ngân hàng - 1 -
 Ứng dụng bi Business intelligence trong bài toán thẩm định tài sản bảo đảm của ngân hàng - 2
Ứng dụng bi Business intelligence trong bài toán thẩm định tài sản bảo đảm của ngân hàng - 2 -
 Bài Toán Ứng Dụng Bi Trong Hỗ Trợ Thẩm Định Tài Sản Bảo Đảm Của Ngân Hàng
Bài Toán Ứng Dụng Bi Trong Hỗ Trợ Thẩm Định Tài Sản Bảo Đảm Của Ngân Hàng -
 Phương Pháp So Sánh Trực Tiếp Trong Bước Định Giá Giá Trị Của Tài Sản
Phương Pháp So Sánh Trực Tiếp Trong Bước Định Giá Giá Trị Của Tài Sản -
 Sử Dụng Thuật Toán K-Nearest Neighbors (Knn) Để Dự Đoán Giá Trị Tài Sản Thẩm Định
Sử Dụng Thuật Toán K-Nearest Neighbors (Knn) Để Dự Đoán Giá Trị Tài Sản Thẩm Định
Xem toàn bộ 103 trang tài liệu này.
Xác định các mô hình
toán học
Xác định nguồn dữ liệu định nghĩa kho dữ liệu,
khối dữ liệu
Xây dựng nguyên mẫu
Cài đặt và kiểm tra
Xây dựng kho dữ liệu,
khối dữ liệu chủ đề
Xây dựng metadata
Xây dựng module ETL
Xây dựng ứng dụng
Phát hành và kiểm thử
Hình 1- 3: Các pha phát triển một hệ thống BI [13]
Phân tích (Analysis): Xác định các nhu cầu liên quan đến việc phát triển một hệ thống BI của tổ chức. Thông qua một loạt các buổi phỏng vấn các nhân viên có các vai trò và hoạt động khác nhau trong tổ chức. Mô tả rõ ràng các mục tiêu chung và các ưu tiên của dự án, đưa ra các chi phí và trợ cấp phát sinh từ việc phát triển hệ thống BI.
Thiết kế (Design): Nhằm mục đích đưa ra một kế hoạch tạm thời về kiến trúc tổng thể, có tính đến bất kỳ sự phát triển nào trong tương lai gần và sự phát triển của hệ thống trong giai đoạn giữa. Bao gồm hai giai đoạn:
Đầu tiên là đánh giá các cơ sở hạ tầng thông tin đã có và phải kiểm tra các quy trình ra quyết định chính cần được hệ thống BI hỗ trợ để xác định đầy đủ các thông tin yêu cầu.
Sau đó, sử dụng các phương pháp quản lý dự án để đưa ra kế hoạch của dự án, xác định các giai đoạn phát triển, các ưu tiên, thời gian và chi phí dự kiến, các vai trò và nguồn lực cần thiết.
Lập kế hoạch (Planning): Xác định và mô tả chi tiết hơn các tính năng của hệ thống BI.
Đánh giá nguồn dữ liệu hiện có, dữ liệu được truy xuất từ bên ngoài. Điều này cho phép xây dựng cấu trúc thông tin của hệ thống BI, bao gồm một kho dữ liệu trung tâm và có thể có nhiều khối dữ liệu đi kèm.
Cần xác định các mô hình toán học được áp dụng, đảm bảo tính sẵn có của các dữ liệu cần thiết cho mỗi mô hình và xác định hiệu quả của các thuật toán có phù hợp với mức độ kết quả các vấn đề.
Cuối cùng, tạo một hệ thống với chi phí thấp và khả năng giới hạn, để phát hiện ra bất kỳ sự khác biệt giữa nhu cầu thực tế và các dự án cụ thể.
Cài đặt và kiểm tra (Implementation and control): Gồm có 5 giai đoạn chính:
Đầu tiên là phát triển kho dữ liệu và khối dữ liệu cụ thể. Đây là những cơ sở hạ tầng thông tin sẽ cung cấp cho hệ thống BI.
Thứ hai là tạo ra một metadata để giải thích ý nghĩa của dữ liệu lưu trữ trong kho dữ liệu và áp dụng các phép biến đổi dữ liệu chính.
Thứ ba là thiết lập các thủ tục ETL để thu thập và chuẩn hóa dữ liệu đã tồn tại trong các nguồn tài nguyên chính, nạp chúng vào trong kho dữ liệu và các khối dữ liệu.
Bước tiếp theo là phát triển các ứng dụng core của BI để thực hiện các phân tích kế hoạch.
Cuối cùng, hệ thống được phát hành để thử nghiệm và sử dụng.
1.2.Giới thiệu về Data Warehouse
1.2.1. Khái niệm
Data Warehouse (DW) là nơi lưu trữ dữ liệu có giá trị cho việc xây dựng các kiến trúc BI và các hệ thống hỗ trợ quyết định. Một định nghĩa DW thể hiện toàn bộ các hoạt động liên quan đến nhau, tham gia vào việc thiết kế, phát triển và sử dụng một DW. [13]
Kho dữ liệu được xây dựng để tiện lợi cho việc truy cập theo nhiều nguồn, nhiều kiểu dữ liệu khác nhau sao cho có thể kết hợp được cả những ứng dụng của các công nghệ hiện đại và kế thừa được từ những hệ thống đã có sẵn từ trước.
Các đặc tính của kho dữ liệu:
- Hướng chủ đề: Kho dữ liệu được thiết kế để phục vụ cho một mục đích phân tích dữ liệu hướng tới một chủ đề nào đó. Có thể là: Khách hàng, sản phẩm, bán hàng… Giúp người dùng xác định được các thông tin cần thiết trong hoạt động của mình và loại bỏ những thông tin không cần thiết.
- Tích hợp: Dữ liệu được tập hợp từ nhiều nguồn khác nhau: cơ sở dữ liệu Oracle, SQLserver, files… cần phải thực hiện việc làm sạch, sắp xếp, rút gọn dữ liệu.
- Biến đổi theo thời gian: Mỗi dữ liệu trong kho dữ liệu đều được gắn với thời gian và có tính lịch sử.
- Ổn định: Được lấy từ nhiều nguồn dữ liệu của hệ thống tác nghiệp có sẵn. Nó tách rời vật lý với môi trường tác nghiệp,nên dữ liệu trong kho dữ liệu là dữ liệu chỉ đọc, không được sửa bởi người dùng cuối.
1.2.2.Kiến trúc của Data Warehouse
Các kiến trúc tham chiếu của một kho dữ liệu được thể hiện như sau [13]:
Metadata
Dữ liệu các hệ thống
Xuất nhập khẩu
Kho dữ liệu
Kinh doanh
Cube đa chiều
Phân tích thăm dò dữ liệu Phân tích chuỗi thời gian Khai giá dữ liệu
Tối ưu hóa
Dữ liệu ngoài
Đánh giá hiệu suất
Công cụ ETL
OLAP
Hình 1- 4: Kiến trúc và các tính năng của một kho dữ liệu [13]
- Kho dữ liệu kết hợp với các metadata chứa dữ liệu và các chức năng cho phép dữ liệu được truy cập, hình tượng hóa và cập nhật.
- Các ứng dụng thu thập dữ liệu từ hệ thống nghiệp vụ, chuẩn hóa dữ liệu về dạng dữ liệu đa chiều, nạp vào kho dữ liệu (ETL) hoặc các công cụ back-end cho phép dữ liệu được chiết xuất, chuyển đổi và tải vào kho dữ liệu.
- Các ứng dụng BI và hệ thống ra quyết định như là các front-end, cho phép các nhà tri thức thực hiện các phân tích và trực quan hóa các kết quả.
Một kho dữ liệu có thể được phát triển theo các kiểu thiết kế: top-down (từ trên xuống), bottom-up (từ dưới lên) và mixed (hỗn hợp hai phương pháp)
- Top - down: Phương pháp top-down dựa trên thiết kế tổng thể của kho dữ liệu. Thời gian phát triển dài hơn và rủi ro không hoàn thành theo lập lịch cao hơn, khi toàn bộ kho dữ liệu được phát triển trên thực tế.
- Bottom-up: Phương pháp này dựa trên việc sử dụng các nguyên mẫu và do đó phần mở rộng hệ thống được thực hiện theo từng bước của kế hoạch. Cách tiếp cận này thường nhanh hơn, cung cấp nhiều kết quả hữu hình hơn, nhưng lại thiếu một tầm nhìn tổng thể của toàn bộ hệ thống đang được phát triển.
- Mixed: Phương pháp này dựa trên thiết kế tổng thể của kho dữ liệu, nhưng sau đó tiến hành theo cách tiếp cận các nguyên mẫu, bằng cách thực hiện tuần tự các phần khác nhau của toàn bộ hệ thống. Cách tiếp cận này thực tiễn hơn và thích hợp hơn, vì nó cho phép các bước nhỏ đã được kiểm soát để được thực hiện trong khi luôn ghi nhớ tới toàn bộ hình ảnh.
Hai thành phần quan trọng tạo nên kho dữ liệu là:
- Các công cụ ETL: Là các công cụ phần mềm sử dụng để thực hiện tự động hóa ba tính năng chính sau: Khai thác, chuyển đổi và nạp dữ liệu vào trong kho dữ liệu.
o Khai thác: Dữ liệu được trích xuất từ các nguồn dữ liệu bên trong và mở rộng có sẵn. Việc lựa chọn dữ liệu để cập nhật vào dựa trên thiết kế kho dữ liệu, phụ thuộc vào thông tin được đưa ra bởi các hệ thống phân tích nghiệp vụ kinh doanh và hỗ trợ ra quyết định hoạt động trong một miền ứng dụng cụ thể.
o Chuyển đổi: Cải tiến chất lượng dữ liệu được chiết xuất từ các nguồn dữ liệu khác nhau, thông qua việc hiệu chỉnh tính không nhất quán, không chính xác và thiếu giá trị.
o Nạp dữ liệu: Dữ liệu được nạp vào trong các bảng của kho dữ liệu, tạo ra các dữ liệu có giá trị cho các ứng dụng phân tích và hỗ trợ quyết định.
- Metadata (Siêu dữ liệu): Ghi lại ý nghĩa của dữ liệu trong kho dữ liệu. Được chia làm hai nhóm là siêu dữ liệu nghiệp vụ và siêu dữ liệu kỹ thuật.
o Siêu dữ liệu nghiệp vụ mô tả ý nghĩa dữ liệu, các luật và ràng buộc tác động.
o Siêu dữ liệu kỹ thuật mô tả cách thức tổ chức, lưu trữ và điều khiển dữ liệu trong hệ thống máy tính.
1.2.3.Xây dựng Data warehouse
Việc thiết kế kho dữ liệu và dữ liệu mô tả dựa trên mô hình dữ liệu đa chiều. Về mặt chức năng mô hình có thể đảm bảo thời gian phản hồi nhanh, thậm chí đối với câu lệnh truy vấn phức tạp. Về mặt logic người dùng có thể nhìn dữ liệu theo nhiều khía cạnh khác nhau.
Biểu diễn data cube dựa trên lược đồ sao được xác định bởi hai loại bảng dữ liệu: bảng cắt lớp (dimenson tables) và bảng sự kiện (fact tables).[13]
- Bảng cắt lớp: Cung cấp các thông tin, quan điểm được dùng để phân tích dữ liệu. Bảng cắt lớp tương ứng với các thực thể chính chứa trong kho dữ liệu, chúng thường thu được từ các bảng chính được lưu trữ trên các hệ thống xử lý giao dịch thời gian thực (OLTP) như: bảng khách hàng, sản phẩm, kinh doanh, vị trí và thời gian. Mỗi bảng cắt lớp thường được xây dựng theo mối quan hệ có tính phân cấp. Bảng cắt lớp bao gồm 3 thành phần chính:
o Khóa thay thế: Là khóa chính chứa giá trị duy nhất, tự sinh và không có nghĩa.
o Khóa tự nhiên: Là khóa chính của dữ liệu trong hệ thống nghiệp vụ. Có ý nghĩa trong giá trị.
o Tập các thuộc tính mô tả: Có thể ở nhiều kiểu dữ liệu khác nhau.
- Bảng sự kiện: Lưu các tiêu chí, chi tiêu về hoạt động kinh doanh của doanh nghiệp. Mỗi môt tiêu chí được định nghĩa là một lượng quan sát được theo một đơn vị đo lường thống nhất. Bảng sự kiện gồm có hai thành phần:
o Một tập khóa ngoại: Để kết nối tới các bảng cắt lớp. Cung cấp ngữ cảnh cho các thông tin trong bảng sự kiện.
o Các tiêu chí đo lường: thuộc tính là các giá trị số, mô tả các giao dịch tương ứng và thể hiện mục tiêu của các phân tích OLAP tiếp theo.
Một bảng sự kiện được kết nối với n bảng cắt lớp có thể được biểu diễn bằng một data cube n cắt lớp, trong đó mỗi trục tương ứng với một cắt lớp. Nhìn chung, từ một bảng sự kiện liên kết với n bảng cắt lớp, có thể tạo ra một lưới các cuboid. Một cuboid tương ứng với các mức độ hợp nhất với một hoặc nhiều cắt lớp. Kiểu kết hợp này tương đương với ngôn ngữ truy vấn cấu trúc (SQL) tới câu lệnh truy vấn sum bắt nguồn từ điều kiện group by.
Trong nhiều trường hợp, phân tích OLAP dựa trên sự phân cấp các khái niệm để hợp nhất dữ liệu và tạo ra các quan điểm logic dọc theo các cắt lớp của một kho dữ liệu. Tính chất cây phân cấp định nghĩa ra một cấu trúc hình cây với các mức độ chi tiết khác nhau của một cắt lớp. Với hai mức độ liền nhau trong một cây, mức thấp hơn gọi là mức con, mức cao hơn gọi là mức cha. Các phân cấp khái niệm được sử dụng để thực hiện trực quan hóa khối dữ liệu trong một kho dữ liệu. Một số tính năng cho phép thực hiện điều đó là [5]:
- Nhìn xa (Roll-up): Hay còn gọi là drill-up. Biến tiêu chí từ mức chi tiết sang mức tổng hợp để hiển thị cho người dùng. Tập hợp dữ liệu trong cube được tạo ra từ việc thay thế theo hai cách: Đi từ mức thấp lên mức cao trong cây phân cấp hoặc làm giảm số cắt lớp.
- Đào sâu (Roll-down): Hay còn gọi là drill-down. Là một hoạt động ngược lại với roll-up. Nó cho phép đi từ mức tổng hợp cao đến mức chi tiết hơn. Mục đích là để đảo ngược kết quả từ hoạt động roll-up. Vì vậy, hoạt động drill-down có thể được thực hiện theo hai cách: Di chuyển xuống bậc thấp hơn dọc theo một cắt lớp của cây phân cấp hoặc thêm một cắt lớp.
- Cắt lát mỏng và cắt khối (Slice and dice): Hoạt động cắt lấy dữ liệu một lớp cắt cụ thể trong một cắt lớp hoặc lựa chọn giá trị cho ít nhất hai cắt lớp. Hoạt động "cắt" có được một khối lập phương trong một không gian con bằng việc lựa chọn một vài cắt lớp cùng một lúc.
- Đảo chiều (Pivot): Họat động pivot được xem như là việc luân chuyển, tạo ra một vòng xoay giữa các trục: biến cột thành hàng, hàng thành cột. Đảo chiều để có được một cách nhìn khác về khối dữ liệu.
1.3. Giới thiệu về Khai phá dữ liệu (Data mining)
1.3.1. Khái niệm
Các hoạt động khai phá dữ liệu là một quá trình lặp đi lặp lại nhằm phân tích các cơ sở dữ liệu lớn, với mục đích khai thác thông tin và tri thức một cách chính xác và hữu ích cho việc hỗ trợ ra quyết định và xử lý vấn đề. [13]
Thuật ngữ khai phá dữ liệu đề cập đến một quá trình tổng thể bao gồm: thu thập và phân tích dữ liệu, phát triển các mô hình học thức quy nạp thông qua các quyết định thực tiễn và các hành động diễn ra sau đó dựa trên kiến thức thu được.
Các hoạt động khai phá dữ liệu có thể được chia ra thành hai luồng phân tích chính, theo mục đích phân tích là: thông dịch (Interpretation) và dự đoán (Prediction).
- Thông dịch (Interpretation): Xác định các mẫu có quy tắc trong dữ liệu và mô tả chúng thông qua các luật và các tiêu chí mà các chuyên gia trong lĩnh vực ứng dụng có thể dễ dàng hiểu được. Các quy tắc tạo ra phải là nguyên thủy và không tầm thường để làm tăng thực sự mức độ tri thức và hiểu biết về hệ thống cần quan tâm.
- Dự đoán (Prediction): Mục đích của hoạt động này là dự đoán giá trị mà một biến ngẫu nhiên sẽ có trong tương lai hoặc để đánh giá khả năng xảy ra của các sự kiện trong tương lai. Thực tế thì hầu hết các kỹ thuật khai phá dữ liệu thu được được tiên đoán từ giá trị của một bộ biến liên quan đến các thực thể trong cơ sở dữ liệu.
1.3.2.Quy trình khai phá dữ liệu
Khai phá dữ liệu được thực hiện theo quy trình sau [13]:
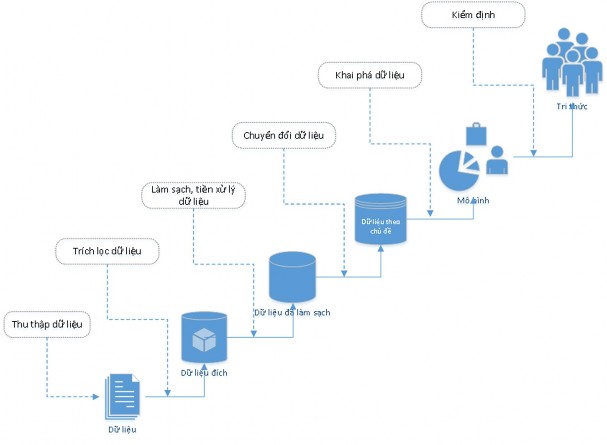
Hình 1- 5: Quy trình khai phá dữ liệu[13]
- Định nghĩa các mục tiêu (Objectives definition): Các phân tích khai phá dữ liệu được thực hiện trong những lĩnh vực ứng dụng nhất định và được mong đợi để cung cấp những tri thức cần thiết cho người ra quyết định.
- Thu thập và tích hợp dữ liệu (Data gathering and integration): Dữ liệu có thể đến từ nhiều nguồn khác nhau, có thể là trong một cơ sở dữ liệu, một kho dữ liệu, thậm chí các dữ liệu từ các nguồn ứng dụng web.
- Phân tích thăm dò (Exploratory analysis): Trong giai đoạn thứ ba của quá trình khai thác dữ liệu, một phân tích thăm dò sẽ được thực hiện với mục đích làm quen với các thông tin hiện có và thực hiện công việc làm sạch dữ liệu. Thông thường, dữ liệu được lưu trữ trong một kho dữ liệu đã được xử lý ở giai đoạn tải dữ liệu theo cách loại bỏ bất kỳ dữ liệu không nhất quán về cú pháp. Trong quá trình khai thác dữ liệu, làm sạch dữ liệu xảy ra ở mức độ ngữ nghĩa. Trước hết các giá trị phân bố của mỗi thuộc tính sẽ được nghiên cứu, sử dụng biểu đồ danh mục thuộc tính và các thống kê tổng hợp cơ bản cho các biến số. Bằng cách này, bất kỳ một giá trị bất thường nào hoặc thiếu giá trị cũng sẽ bị đánh dấu.
- Lựa chọn các thuộc tính (Attribute Selection): Trong giai đoạn này, sự liên quan của các thuộc tính khác nhau được đánh giá trên mối quan hệ giữa các mục
tiêu của phép phân tích. Các thuộc tính được chứng minh là ít được sử dụng sẽ bị loại bỏ, để làm sạch thông tin không liên quan từ bộ dữ liệu. Hơn nữa, các thuộc tính mới thu được từ các biến ban đầu thông qua các phép biến đổi thích hợp được đưa vào bộ dữ liệu. Phân tích thăm dò và lựa chọn thuộc tính là những giai đoạn quan trọng và có thể ảnh hưởng đến mức độ thành công của các giai đoạn tiếp theo.
- Phát triển mô hình và xác nhận (Model development and validation): Một khi bộ dữ liệu có chất lượng tốt được nhúng và có khả năng được làm giàu với các thuộc định mới đã được xác định, chúng ta có thể phát triển các mô hình nhận diện và dự báo. Thông thường việc đào tạo của các mô hình được thực hiện bằng cách sử dụng một mẫu của các bản nghi đã được chiết xuất từ tập dữ liệu ban đầu. Sau đó, độ chính xác dự đoán của mỗi mô hình đã được tạo ra có thể được đánh giá bằng phần còn lại của dữ liệu.
- Dự đoán và thông dịch dữ liệu (Prediction and interpretation): Sau khi kết thúc quá trình khai thác dữ liệu, mô hình đã được chọn trong số các mô hình được tạo ra trong suốt giai đoạn phát triển sẽ được cài đặt và sử dụng để đạt được các mục tiêu xác định ban đầu. Hơn nữa, nó cần được kết hợp chặt chẽ vào các thủ tục của quá trình hỗ trợ ra quyết định để để dự đoán và thu thập kến thức sâu hơn về các hiện tượng đang được quan tâm.
1.3.3. Các phương pháp khai phá dữ liệu
Có một số phương pháp khai phá dữ liệu điển hình là [13]:
- Phân lớp dữ liệu: Từ một cơ sở dữ liệu với nhiều thông tin ẩn, con người có thể trích rút ra các quyết định nghiệp vụ thông minh. Phân lớp và dự đoán là hai dạng của phân tích dữ liệu nhằm trích rút ra một mô hình mô tả các lớp dữ liệu quan trọng hay dự đoán các xu hướng dữ liệu tương lai. Phân lớp dự đoán giá trị của những nhãn xác định hay những giá trị rời rạc đã biết trước. Trong khi đó, dự đoán lại xây dựng mô hình với các hàm nhận giá trị liên tục. Một số thuật toán tiêu biểu như:Phân lớp cây quyết định (Decision tree classification), bộ phân lớp Bayesian (Bayesian classifier), mô hình phân lớp K hàng xóm gần nhất (K-nearest neighbor classifier), mạng nơ ron …
- Phân cụm dữ liệu: Phân cụm dữ liệu là một kỹ thuật nhằm tìm kiếm, phát hiện các cụm, các mẫu dữ liệu tự nhiên tiềm ẩn và quan trọng trong tập dữ liệu lớn, để từ đó cung cấp thông tin, tri thức cho việc ra quyết định. Có thể coi phân cụm dữ liệu là một cách học bằng quan sát, còn phân lớp dữ liệu là học bằng ví dụ. Các thuật toán thường được sử dụng như: K_means, K_medoids, CLARA (Clustering Large Application), CLARANS, AGNES, DIANA (Divisive Analysis), BIRCH …
- Khai phá luật kết hợp: Mục đích của luật kết hợp là rút ra những mối liên quan, những tập mẫu phổ biến, những cấu trúc kết hợp hay cấu trúc ngẫu nhiên giữa những tập hợp các item trong các CSDL giao tác hoặc trong các kho dữ liệu.