![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
[11] chỉ ra rằng nó có giá trị lớn nhất xấp xỉ ![]() và giá trị này bị giới hạn như sau:
và giá trị này bị giới hạn như sau:
Có thể bạn quan tâm!
-

 Giải pháp nâng cao hiệu quả của giản đồ lập lịch dựa trên độ tin cậy trong các hệ thống tính toán tình nguyện - 2
Giải pháp nâng cao hiệu quả của giản đồ lập lịch dựa trên độ tin cậy trong các hệ thống tính toán tình nguyện - 2 -
 So Sánh Với Tính Toán Lưới Và Tính Toán Ngang Hàng
So Sánh Với Tính Toán Lưới Và Tính Toán Ngang Hàng -
 Lý Thuyết Cơ Bản Về Lập Lịch Dựa Trên
Lý Thuyết Cơ Bản Về Lập Lịch Dựa Trên -
 Lập Lịch Round Robin Dựa Trên Sự Ưu Tiên Về Khả Năng Tính Toán
Lập Lịch Round Robin Dựa Trên Sự Ưu Tiên Về Khả Năng Tính Toán -
 Giản Đồ Lập Lịch Round Robin Dựa Trên Kiểm Thử Độ Tin Cậy
Giản Đồ Lập Lịch Round Robin Dựa Trên Kiểm Thử Độ Tin Cậy -
 Giải pháp nâng cao hiệu quả của giản đồ lập lịch dựa trên độ tin cậy trong các hệ thống tính toán tình nguyện - 8
Giải pháp nâng cao hiệu quả của giản đồ lập lịch dựa trên độ tin cậy trong các hệ thống tính toán tình nguyện - 8
Xem toàn bộ 83 trang tài liệu này.
Trực quan, điều này nghĩa rằng nếu một máy phá hoại biết n trước đó, thì nó thiết lập tỉ lệ lỗi phá hoại là ![]() , khi tỉ lệ lỗi cao hơn dẫn đến máy phá hoại đang được bắt cũng nhanh hơn, trong khi có một tỉ lệ lỗi thấp dẫn đến ít lỗi trong phần cuối của lô. Tuy nhiên thậm chí nếu các máy phá hoại tối ưu tỉ lệ phá hoại bằng cách này, phương trình (2) chỉ rằng tỉ lệ lỗi trung bình không thể lớn hơn
, khi tỉ lệ lỗi cao hơn dẫn đến máy phá hoại đang được bắt cũng nhanh hơn, trong khi có một tỉ lệ lỗi thấp dẫn đến ít lỗi trong phần cuối của lô. Tuy nhiên thậm chí nếu các máy phá hoại tối ưu tỉ lệ phá hoại bằng cách này, phương trình (2) chỉ rằng tỉ lệ lỗi trung bình không thể lớn hơn ![]() . Đó là, kiểm tra điểm giảm tuyến tính tỉ lệ lỗi trung bình trong trường hợp tồi nhất với n (cho f là hằng số). Vì vậy để giảm tỉ lệ lỗi, máy chủ phải làm các lô dài hơn để n lớn hơn.
. Đó là, kiểm tra điểm giảm tuyến tính tỉ lệ lỗi trung bình trong trường hợp tồi nhất với n (cho f là hằng số). Vì vậy để giảm tỉ lệ lỗi, máy chủ phải làm các lô dài hơn để n lớn hơn.
2.2.2.2Kiểm tra điểm không dùng danh sách đen
Không may mắn, danh sách đen không phải luôn luôn có thể có hiệu lực. Mặc dù chúng ta có thể có danh sách đen các máy phá hoại dựa trên địa chỉ thư, thì cũng không quá khó cho các máy phá hoại tạo một địa chỉ thư mới và máy tình nguyện đó sẽ trở thành máy tình nguyện mới. Danh sách đen theo địa chỉ IP cũng không làm việc được bởi nhiều người sử dụng các nhà cung cấp dịch vụ ISP mà cấp cho họ địa chỉ động sau mỗi lần họ quay số. Yêu cầu nhiều mẫu xác minh để thẩm định như là địa chỉ nhà và số điện thoại có thể cấm máy phá hoại, nhưng cũng có thể cấm nhiều máy tình nguyện có ý tốt.
Kĩ thuật này thì rất hữu ích khi quan tâm đến hiệu quả của kiểm tra điểm khi danh sách đen không có hiệu lực. Không may mắn, trong trường hợp này, các máy phá hoại có thể tăng đáng kể tỉ lệ lỗi bằng việc dời đi sau khi chỉ làm một giới hạn số lượng công việc, l, và sau đó quay lại gia nhập với một nút mới. Chúng ta có thể chỉ [8] rằng điều này sẽ thay đổi cận trên trong trường hợp tỉ lệ lỗi trung bình trường hợp tồi nhất đến ![]() . Điều này kém hơn trước đó. Bởi vì không giống phương trình (2), tỉ lệ này không giảm nghịch đảo với n. Vì vậy không thể mong đợi giảm với chiều dài của lô. Điều tốt nhất máy chủ có thể làm trong trường hợp
. Điều này kém hơn trước đó. Bởi vì không giống phương trình (2), tỉ lệ này không giảm nghịch đảo với n. Vì vậy không thể mong đợi giảm với chiều dài của lô. Điều tốt nhất máy chủ có thể làm trong trường hợp
này là có gắng ép buộc các máy phá hoại ở lâu hơn (tăng l) bằng cách làm công việc
khó đối với chúng để chúng khó tiến tới một nhận dạng mới hoặc bằng cách đánh lừa chễ công việc.
Nếu các lô của chúng ta không quá dài thì chúng ta có thể đưa ra một quy tắc đó là người dùng mới không được phép gia nhập cho đến tận lô tiếp theo, để mà một máy trạm không thể lấy được bất cứ công gì khi dời đi sớm. Trong trường hợp này tỉ lệ lỗi là giống như trong phần 3.2.1.Tuy nhiên, giản đồ này không có ích nếu lô quá dài, khi đó nó sẽ lãng phí nguồn tài nguyên tiềm năng của các máy tình nguyện tốt vì bị ép buộc phải đợi lô kế tiếp.
2.3 Chịu lỗi dựa trên độ tin cậy
Trong phần này, chúng ta biểu diễn một ý tưởng mới được gọi là chịu lỗi dựa trên độ tin cậy, ý tưởng này không chỉ giải quyết lỗi của danh sách đen mà quan trọng hơn nó cung cấp một khung làm việc cho việc kết hợp lợi ích của biểu quyết, kiểm tra điểm và các kĩ thuật khác tốt có thể.
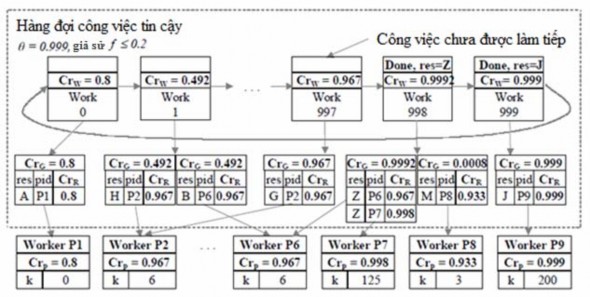
Hình 2-4. Hàng đợi công việc lập lịch tham lam nâng cao độ tin cậy [8]
2.3.1 Tổng quan
Ý tưởng chính trong chịu lỗi dựa trên độ tin cậy đó là nguyên lý ngưỡng tin cậy:
Nếu chúng ta chỉ đồng ý một kết quả cho một thực thể công việc khi xác suất điều
![]()
![]()
kiện của kết quả đang đúng đó là lớn hơn một vài ngưỡng ,thì xác suất đồng ý một kết quả đúng, trung bình của tất cả các thực thể công việc, phải lớn hơn .
Nguyên lý này ám chỉ rằng nếu chúng ta có thể tính toán bằng cách này hay cách khác xác suất điều kiện, cho đến tận thời điểm kết quả tốt nhất cuối cùng tốt nhất của thực thể công việc là chính xác, thì chúng ta có thể đảm bảo toán học rằng tỉ lệ lỗi (về trung bình) sẽ kém hơn một vài được mong đợi, bằng cách chuyển đổi
![]()
![]()
![]()
![]()
đơn giản cờ được làm không được thiết lập cho đến khi xác suất điều kiện của kết quả tốt nhất đạt đến ngưỡng .
Để thực hiện ý tưởng này, chúng ta thêm các giá trị tin cậy đến các đối tượng khác nhau trong hệ thống, được chỉ trong hình 2-1. Ở đây độ tin cậy của một vài đối tượng X, được viết là ![]() , được định nghĩa là xác suất điều kiện để X cho một
, được định nghĩa là xác suất điều kiện để X cho một
kết quả tốt. Có bốn loại độ tin cậy: Độ tin cậy của một máy trạm, độ tin cậy của kết quả, độ tin cậy của một nhóm kết quả (một nhóm chứa đựng các kết quả giống nhau) và độ tin cậy của một thực thể công việc. Độ tin cậy của một máy trạm phụ thuộc vào các hành vi quan sát được của nó như là tính chính xác của kết quả, số lượng điểm kiểm tra mà nó đã vượt qua... Độ tin cậy của một kết quả thì bằng độ tin cậy của máy trạm trả về kết quả đó. Độ tin cậy của một nhóm các kết quả là xác suất có điều kiện để kết quả là chính xác. Cuối cùng độ tin cậy của một thực thể công việc là độ tin cậy của nhóm tốt nhất được xác minh qua quá trình xử lý biểu quyết.
Trong suốt quá trình chạy một lô song song, độ tin cậy của các đối tượng trong hệ thống thay đổi hoặc là: (1) các máy trạm qua được các kiểm tra điểm (vì vậy tăng độ tin cậy các kết quả của chúng và các nhóm chúng tham gia) (2) các kết quả ánh xạ được nhận cho thực thể công việc giống nhau (vì vậy hình thành kết quả nhóm),
(3) hoặc máy trạm có thể bị bắt (vì các kết quả chúng không hợp lệ, và giảm độ tin cậy của nhóm các kết quả liên quan đến chúng ). Giả sử có đủ các máy trạm tốt, độ tin cậy của mỗi thực thể công việc W thậm chí hướng đến ngưỡng như máy chủ thu thập đủ kết quả ánh xạ cho một thực thể công việc W, hoặc các máy phân giải các kết quả trong W đủ qua các kiểm tra điểm để làm cho các độ tin cậy cảu các kết quả
của chúng tăng lên hoặc đồng thời. Khi điều này xảy ra, thực thể công việc được đánh dấu được là và máy chủ dùng quay lại gán các công việc đến các máy trạm. Điều này tiếp tục xảy ra cho tất cả các thực thể công việc chưa được làm cho đến tận khi tất cả các thực thể công việc hướng đến ngưỡng được mong đợi
![]()
![]()
![]()
![]()
![]()
, tại điểm nào đó, cuối của lô. Tại điểm này, giả sử rằng các độ tin cậy của chúng ta là các ước lượng của các xác suất có điều kiện tốt, phân số của các kết quả cuối cùng, kết quả sẽ là chính xác, nên lớn hơn và vì vậy tỉ lệ lỗi hầu hết tại
![]()
.
Chú ý rằng giản đồ này tự động cân đối hiệu năng cho tính chính xác. Nó tương tự như biểu quyết ngoại trừ rằng ở đây, m không được xác minh trước, nhưng được xác minh động, bằng làm điều chỉnh lớn như là nó yêu cầu cho một thực thể công việc. Tuy nhiên không giống như biểu quyết truyền thống, chúng ta không phải quay lại làm một thực thể công việc nhiều lần (hoặc tất cả) nếu kết quả của nó được làm bởi một máy trạm đã được kiểm tra điểm nhiều lần và vì vậy có một độ tin cậy rất cao. Theo cách này, một thực thể công việc chỉ lặp lại một số lần để đạt được mức độ quan tâm mong đợi, nhưng không nhiều. Điều này làm cho chịu lỗi dựa trên độ tin cậy rất hiệu quả, và được chỉ trong phần 4.3, cho phép nó đạt được tỉ lệ lỗi rất thấp với độ dư thừa ít.
2.3.2 Tính toán độ tin cậy
Quyết định chính trong kĩ thuật này là tính toán các giá trị độ tin cậy là chính xác. Thông thường, có nhiều các giá trị độ tin cậy có thể, tương ứng đối với các cách quan sát trạng thái hiện thời của hệ thống khác nhau, thêm vào đó là các cách tính toán khác nhau hoặc ước lượng xác suất điều kiện của tính chính xác dựa trên các quan sát. Trong phần này chúng ta sẽ biểu diễn các giá trị đặc biệt mà chúng ta nhận thấy là hiệu quả.
Độ tin cậy của một máy trạm không có kiểm tra điểm là:
![]()
![]()
![]()
![]()
Độ tin cậy của một máy trạm có kiểm tra điểm và danh sách đen, giả sử nó đã qua k
lần kiểm tra là:
![]()
![]()
![]()
![]()
Độ tin cậy của một máy trạm có kiểm tra điểm và không có danh sách đen được ước lượng là:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Nếu một thực thể công việc có g nhóm, thì độ tin cậy của nhóm a, cho , là xác suất có điều kiện để mà tất cả các kết quả trong nhóm a là đúng, giả sử rằng kết quả các nhóm khác là sai. Xác suất này có thể được ước lượng là:
Tính độ tin cậy độ tin cậy của một vài đối tượng cho các trường hợp khác nhau
được tính toán
![]()
![]()
![]()
![]()
![]()
ở đây P(Gatốt) là xác suất để tất cả các kết quả của ![]()
![]() là tốt:
là tốt:
![]()
![]()
![]()
![]()
![]()
Và ở đây P(Gaxấu) là xác suất để tất cả các kết quả ![]()
![]() là xấu:
là xấu:
![]()
![]()
![]()
![]()
![]()
Cuối cùng, độ tin cậy của một thực thể công việc là độ tin cậy của nhóm có độ tin cậy cao nhất.
2.3.3 Ứng dụng sự tin cậy
2.3.3.1Kết hợp biểu quyết và kiểm tra điểm
Mặc dù chịu lỗi dựa trên độ tin cậy có thể được dùng với biểu quyết hoặc kiểm tra
điểm một mình, nhưng tốt nhất dùng tích hợp biểu quyết và kiểm tra điểm cùng
![]()
![]()
nhau. Trong trường hợp này, chúng ta bắt đầu với tất cả các máy trạm hiệu quả có một độ tin cậy và bắt đầu tập hợp các kết quả. Nếu ngưỡng độ tin cậy là đủ
![]()
![]()
thấp, và các lô là dài, thì bằng thời điểm chúng ta đi một vòng hàng đợi công việc quay tròn, các máy trạm có thể giành được đủ độ tin cậy bằng việc vượt qua các kiểm tra điểm để làm cho các kết quả của chúng được chấp nhận. Trong trường hợp này chúng ta không cần làm biểu quyết và chúng ta có thể hướng tới tỉ lệ lỗi mong đợi với chỉ ![]()
![]() độ dư thừa bởi các công việc giám sát. Nếu là cao, thì kiểm tra điểm không đủ, do đó chúng ta quay lại gán công việc, tâp hợp các kết quả dư thừa, và biểu quyết.
độ dư thừa bởi các công việc giám sát. Nếu là cao, thì kiểm tra điểm không đủ, do đó chúng ta quay lại gán công việc, tâp hợp các kết quả dư thừa, và biểu quyết.
Nếu chúng ta không dùng kiểm tra điểm, chúng ta thậm chí hướng đến ngưỡng sau
![]()
![]()
một sự chậm chễ tương ứng xấp xỉ là ![]() . Tuy nhiên kiểm tra
. Tuy nhiên kiểm tra
![]()
điểm giảm hiệu quả thuật toán này, ![]() , tuyến tính với thời gian, và vì vậy cho ta hướng tới ngưỡng mong đợi ít thời gian hơn nhiều so với biểu quết một mình.
, tuyến tính với thời gian, và vì vậy cho ta hướng tới ngưỡng mong đợi ít thời gian hơn nhiều so với biểu quết một mình.
Một thuận lợi khác của việc dùng độ tin cậy đó là nó vẫn làm việc tốt thậm chí chúng ta không dùng danh sách đen. Bằng việc dùng giá trị độ tin cậy từ phương trình 6, chúng ta đã làm mất tác dụng một cách hiệu quả ảnh hưởng của các máy phá hoại chỉ làm một ít công việc và rồi sau đó gia nhập nút mới.
2.3.3.2Kiểm tra điểm bằng biểu quyết
Mặc dù dùng độ tin cậy với biểu quyết và kiểm tra điểm thực sự làm việc khá tốt, chúng ta vẫn có thể thu được nhiều hiệu năng hơn bằng việc dùng biểu quyết cho kiểm tra điểm.
![]()
![]()
![]()
Từ giờ trở đi, chúng ta giả sử rằng một máy chủ kiểm tra điểm một máy trạm bằng cách cho nó một loại công việc mà kết quả chính xác đã thực sự biết. Bởi vậy điều này ám chỉ rằng hoặc máy chủ bản thân nó, hoặc một vài máy trạm có đầy đủ độ tin cậy, phải làm các công việc để xác minh kết quả chính xác, chúng ta thường giả sử rằng yêu cầu là nhỏ (nghĩa là kém hơn 10%). Bởi vì xấp xỉ là , điều này giới
hạn tỉ lệ tại đó độ tin cậy tăng vì vậy giới hạn hiệu năng.
May mắn, chúng ta có thể đạt tới hiệu năng tốt hơn nhiều bằng việc dùng biểu quyết dựa trên độ tin cậy như là một kĩ thuật kiểm tra điểm. Đó là, bất cứ khi nào các nhóm kết quả của một thực thể công việc hướng đến ngưỡng, chúng ta tăng giá trị k của các máy trạm đã thực hiện kết quả trong nhóm chiến thắng trong khi đó chúng ta đối xử với các máy trạm khác trong nhóm thất bại như là chúng bị trượt trong kiểm tra điểm (nghĩa là chúng ta sẽ gỡ bỏ chúng từ hệ thống và làm mất hiệu lực các kết quả khác của chúng).
![]()
![]()
![]()
Nếu chúng ta giả sử rằng chúng ta phải làm tất cả các công việc ít nhất hai lần, điều này ám chỉ rằng tất cả các kết quả trả về bởi một máy trạm sẽ phải tham gia vào quá trình biểu quyết, thì dùng những biểu quyết này để kiểm tra điểm một máy trạm ám chỉ rằng một máy trạm sẽ lấy kiểm tra điểm ít nhất lần – có nghĩa ![]() lần nhiều hơn trước. Điều này muốn chỉ ra rằng tỉ lệ lỗi tỉ lệ nghịch với độ tin cậy của các máy trạm tốt, máy được quay vòng để cho phép biểu quyết thực hiện nhanh hơn. Chú ý rằng kĩ thuật này chỉ có thể được làm bằng dùng độ tin cậy dựa trên biểu quyết để bắt đầu. Tin tưởng dùng biểu quyết theo số đông truyền thống để kiểm tra điểm các máy trạm là nguy hiểm bởi vì thay đổi của các máy phá hoại thắng phiếu các máy tốt và vì vậy chúng bị cho vào trong danh sách đen, điều này là đáng kể nếu f không nhỏ. Biểu quyết dựa trên độ tin cậy làm việc bởi vì nó đảm bảo rằng chúng ta không biểu quyết cho đến khi xác suất để biểu quyết đúng là đủ cao. Vì vậy, nó giới hạn xác suất của các máy trạm tốt đang thắng phiếu đến một giá trị rất nhỏ. Tuy nhiên chú ý rằng một vài “bootstraping” được yêu cầu ở đây. Đó là, chúng ta không thể bắt đầu dùng biểu quyết cho kiểm tra điểm cho đến khi các nhóm kết quả thực sự chi bắt đầu hướng đến ngưỡng và biểu quyết. Điều này ám chỉ rằng: (1) Kiểm tra điểm bằng biểu quyết chỉ có lợi khi sự dư thừa thực sự nhỏ hơn 2, và (2) chúng ta cần duy trì bình thường kiểm tra điểm (ít nhất cho một vài lô đầu tiên) để cho phép các máy trạm thu được đủ độ tin cậy để hướng đến ngưỡng đủ sớm.
lần nhiều hơn trước. Điều này muốn chỉ ra rằng tỉ lệ lỗi tỉ lệ nghịch với độ tin cậy của các máy trạm tốt, máy được quay vòng để cho phép biểu quyết thực hiện nhanh hơn. Chú ý rằng kĩ thuật này chỉ có thể được làm bằng dùng độ tin cậy dựa trên biểu quyết để bắt đầu. Tin tưởng dùng biểu quyết theo số đông truyền thống để kiểm tra điểm các máy trạm là nguy hiểm bởi vì thay đổi của các máy phá hoại thắng phiếu các máy tốt và vì vậy chúng bị cho vào trong danh sách đen, điều này là đáng kể nếu f không nhỏ. Biểu quyết dựa trên độ tin cậy làm việc bởi vì nó đảm bảo rằng chúng ta không biểu quyết cho đến khi xác suất để biểu quyết đúng là đủ cao. Vì vậy, nó giới hạn xác suất của các máy trạm tốt đang thắng phiếu đến một giá trị rất nhỏ. Tuy nhiên chú ý rằng một vài “bootstraping” được yêu cầu ở đây. Đó là, chúng ta không thể bắt đầu dùng biểu quyết cho kiểm tra điểm cho đến khi các nhóm kết quả thực sự chi bắt đầu hướng đến ngưỡng và biểu quyết. Điều này ám chỉ rằng: (1) Kiểm tra điểm bằng biểu quyết chỉ có lợi khi sự dư thừa thực sự nhỏ hơn 2, và (2) chúng ta cần duy trì bình thường kiểm tra điểm (ít nhất cho một vài lô đầu tiên) để cho phép các máy trạm thu được đủ độ tin cậy để hướng đến ngưỡng đủ sớm.
2.4 Khảo sát một số giản đồ lập lịch.
Trong phần này, tôi sẽ khảo sát một số giản đồ lập lịch sử dụng trong các hệ thống tính toán tình nguyện sử dụng kĩ thuật chịu lỗi. Trước tiên tôi sẽ khảo sát giản đồ
Round Robin thông thường dùng bởi hàng đợi công việc lập lịch tham lam[8]. Tiếp đó tôi sẽ thảo luận giản đổ Round Robin dựa trên sự ưu tiên về khả năng thực hiện công việc.
2.4.1 Lập lịch Round Robin
Trong công việc trước, Sarmenta đã đề xuất hàng đợi công việc lập lịch tham lam cái mà làm việc theo cách thức Round Robin (RR). Trong giản đồ này, các nhiệm vụ được đặt vào một hang đợi công việc. Với mỗi máy trạm, máy chủ sẽ tiếp tục cho một điểm kiểm tra với tỉ lệ s. Tại thời điểm bắt đầu, mọi máy trạm có độ tin cậy là 1− f (phương trình. 4.1). Ngay khi máy chủ nhận một kết quả, nó sẽ tính toán độ tin cậy của kết quả đó. Nếu độ tin cậy không lớn hơn ngưỡng được định nghĩa trước thì nhiệm vụ sau đó sẽ được gửi quay trở lại hàng đợi để thực hiện lại. Ngược lại, nhiệm vụ được hoàn thành. Xử lý sẽ tiếp tục cho đến khi không còn nhiệm vụ nào trong hàng đợi công việc. Nhận thấy rằng độ tin cậy của các nhiệm vụ tăng lên theo thời gian bởi vì nhiệm vụ (1) được thực hiện bởi một vài máy trạm đã thực sự vượt qua được một vài điểm kiểm tra hoặc (2) nhiệm vụ được thực hiện nhiều lần trên một máy trạm tốt, vì vậy độ tin cậy của thực thể kết quả có thể được tăng lên bằng cách dùng của kĩ thuật biểu quyết (3) thậm chí các nhiệm vụ được thực thi trên một vài máy trạm không tốt, nhưng phân số phá hoại f thì rất nhó, vì vậy độ tin cây của máy đó vẫn tăng bởi kĩ thuật biểu quyết cơ bản. Theo thời gian, tất cả các nhiệm vụ sẽ có kết quả vượt qua ngưỡng và quá trình tính toán được kết thúc.
Tôi có thể tóm tắt giản đồ lập lịch Round Robin được dùng bởi hàng đợi công việc tham lam dựa trên độ tin cậy như sau.
Mã giả lập của giản đồ Round Robin
Đẩy các nhiệm vụ vào trong hàng đợi nhiệm vụ; Đẩy các máy trạm vào trong hàng đợi máy trạm; Làm song song (Kiểm tra điểm):
While (Không dừng) do
Kiểm tra điểm mỗi máy trạm với tỉ lệ s;
If (Máy trạm vượt qua được kiểm tra điểm)