trả về, node lại chọn node ngẫu nhiên và lặp lại quá trình tương tự cho đến khi ID
được tìm thấy.
Khi một node muốn chèn một item mới nào đó, nó sẽ lưu item tại k node gần nhất với ID. Do sử dụng so khớp prefix nên một lookup sẽ được thực hiện trong O(log(N)) chặng.
Joins, leave and maintenance
Một node tìm thấy node gần nó nhất thông qua bất kỳ contact ban đầu nào và khởi tạo bảng định tuyến của nó bằng cách yêu cầu node đó tìm kiếm các node trong các cây con khác nhau.
Nếu một k-bucket được bổ xung quá nhiều node từ một cây con nào đó, quy tắc thay thế least-recently-used sẽ được áp dụng.
Tuy nhiên Kademlia sử dụng một thống kê từ các nghiên cứu về peer-to-peer cho rằng một node nếu đã kết nối trong một khoảng thời gian dài nhiều khả năng sẽ tiếp tục ở lại mạng trong một thời gian dài nữa. Do đó, Kademlia có thể bỏ qua thông tin về các node mới nếu nó đã biết nhiều node ổn định trong cây con đó.
Việc maintenance bảng định tuyến sau khi node join/leave được thực hiện nhờ sử dụng lưu lượng lookup, kỹ thuật này khác với kỹ thuật stabilization của Chord. XOR metric dẫn đến mọi node nhận được truy vấn từ node chứa trong bảng định tuyến của nó. Do đó, nhận được một thông điệp từ một node nào đó trong cây con chính là một cập nhật k-bucket của cây con đó. Cách tiếp cận này rõ ràng là tối thiểu hóa chi phí bảo trì.
Có thể bạn quan tâm!
-
 Đánh giá hiệu năng của một số thuật toán bảng băm phân tán DHT và đưa ra giải pháp cải tiến hiệu năng của thuật toán CHORD - 2
Đánh giá hiệu năng của một số thuật toán bảng băm phân tán DHT và đưa ra giải pháp cải tiến hiệu năng của thuật toán CHORD - 2 -
 (A) Một Mạng Chord Với 6 Node, 5 Item Và N=16. (B) Nguyên Tắc Chung Của Bảng Routing Table. (C) Bảng Routing Table Của Node 3 Và Node 11
(A) Một Mạng Chord Với 6 Node, 5 Item Và N=16. (B) Nguyên Tắc Chung Của Bảng Routing Table. (C) Bảng Routing Table Của Node 3 Và Node 11 -
 (A) Bảng Finger Và Vị Trí Của Key Sau Khi Node 6 Join. (B)Bảng Finger Và Vị Trí Của Key Sau Khi Node 3 Leave.
(A) Bảng Finger Và Vị Trí Của Key Sau Khi Node 6 Join. (B)Bảng Finger Và Vị Trí Của Key Sau Khi Node 3 Leave. -
 Quá Trình Thực Nghiệm Và Phương Pháp Đánh Giá Hiệu Năng
Quá Trình Thực Nghiệm Và Phương Pháp Đánh Giá Hiệu Năng -
 Đồ Thị Biểu Diễn Tỷ Lệ Tìm Kiếm Thành Công (Fration Of Successful Lookups) Theo Băng Thông Trung Bình Một Node Sử Dụng (Average Live Bandwidth) Trong Mạng
Đồ Thị Biểu Diễn Tỷ Lệ Tìm Kiếm Thành Công (Fration Of Successful Lookups) Theo Băng Thông Trung Bình Một Node Sử Dụng (Average Live Bandwidth) Trong Mạng -
 Đồ Thị Biểu Diễn Tỷ Lệ Tìm Kiếm Thành Công Theo Băng Thông Trung Bình Một Node Sử Dụng Của Kelisp Và Tapestry Với Rtt=1S, 10S Và Node Join/leave Với
Đồ Thị Biểu Diễn Tỷ Lệ Tìm Kiếm Thành Công Theo Băng Thông Trung Bình Một Node Sử Dụng Của Kelisp Và Tapestry Với Rtt=1S, 10S Và Node Join/leave Với
Xem toàn bộ 98 trang tài liệu này.
Một nhiệm vụ bảo trì khác là dựa vào việc nhận được nhiều truy vấn từ một cây con, Kademlia cập nhật latency của các node trong một k-bucket cụ thể. Việc này cải thiện sự lựa chọn node cho quá trình tìm kiếm và có thể nói rằng Kademlia cũng chú ý đến độ trễ và tính vị trí của các node.
Replication and Fault Tolerance
Khả năng chịu lỗi của Kademlia phụ thuộc chủ yếu vào liên kết bền vững trong k-bucket bởi vì Kademlia lưu k contact cho mỗi cây con, điều này giúp cho khả năng graph bị đứt liên kết thấp.
Kademlia lưu k phiên bản của một item trên k node gần id của item nhất, các node này được republish định kỳ. Chính sách cho việc republish này là bất kỳ node nào thấy nó gần với item ID hơn các node khác mà nó biết sẽ báo cho k-1 node còn lại biết.
Applications and Implementation
Kademlia được chấp nhận rộng rãi thông qua hai ứng dụng chia sẻ file là Overnet và Emule.
1.3.3. Tapestry
Overlay graph
Tapestry cũng tổ chức các ID trong không gian vòng tròn N. Các ID được biểu diễn theo base .
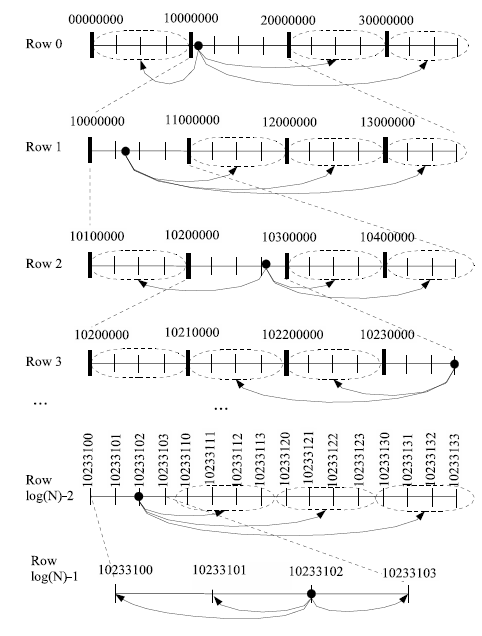
Hình 1.8. Minh họa cách chọn bảng định tuyến của một node Tapestry
Hàng thứ nhất trong bảng định tuyến của một node chứa các node có ID khác với ID của node đó ở chữ số thứ nhất. Tương tự như vậy, hàng thứ hai trong bảng định
tuyến chứa các node có ID giống với ID của node đó ở chữ số thứ nhất nhưng khác ở
chữ số thứ hai. Các hàng còn lại của bảng định tuyến được tổ chức tương tự như vậy.
XHình 1.8X minh họa cách chia không gian ID của Tapestry .
Để tăng tính dự phòng, ở mỗi mức, mỗi contact lại được dự phòng bởi c contact
cùng nhóm. Một node Tapestry có bảng định tuyến với logN mức, mỗi mức có c
contact. Như vậy bảng định tuyến của Tapestry có kích thước c logN.
Mapping items onto nodes
Tapestry ánh xạ ID của item tới một node duy nhất gọi là root của ID. Nếu tồn tại node N có ID bằng với ID của item thì node được gọi là root của item đó. Nếu không tồn tại node có ID bằng với ID của item thì item được ánh xạ vào node có ID gần ID của nó nhất. Tapestry không chuyển item đến node nào đó trên mạng mà chỉ thiết lập con trỏ trên các node nằm trên đường đi từ node chứa item tới node root của item trỏ tới item.
Lookup process
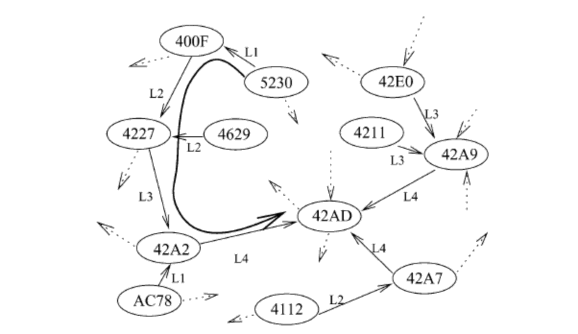
Quá trình định tuyến của Tapestry diễn ra như sau. Để tìm một node gần với một ID x nhất, node sẽ dùng bảng định tuyến kiểm tra từ trên xuống dưới xem x rơi vào khoảng ID nào. Nếu x rơi vào khoảng ID khác với khoảng ID của node, node sẽ chuyển tiếp truy vấn tới contact của nó nằm trong khoảng ID đó. Quá trình cứ diễn ra như vậy cho đến khi đến node root của x. Nếu trong bảng định tuyến của node không tồn tại contact như vậy, node sẽ chuyển tiếp truy vấn tới node có ID gần với x nhất.
Quá trình định tuyến được minh họa trong XHình 1.9
Hình 1.9. Đường đi của thông điệp từ node 5230 tới node 42AD
Để thông báo về sự tồn tại của một item I, node n lưu item định kỳ gửi thông điệp đến root của item đó. Mỗi node dọc đường đi của thông điệp sẽ lưu một con trỏ ánh xạ (I,n) thay vì lưu lại bản thân item. Khi có vài bản sao của một item trên một số node, mỗi node sẽ thông báo về bản sao nó lưu. Một node nhận được nhiều thông báo về một item, nó sẽ lưu ánh xạ theo thứ tự latency.
Quá trình publishing được minh họa trong XHình 1.10
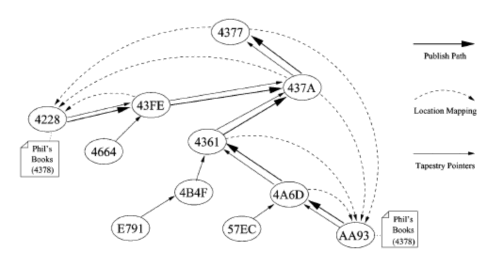
Hình 1.10. Ví dụ về Tapestry node publish item
Một node muốn truy vấn một item nào đó, nó sẽ gửi truy vấn đến root của item. Mỗi node trên đường đi sẽ kiểm tra xem nó có ánh xạ vị trí của item đó không, nếu có nó sẽ chuyển truy vấn theo hướng đến node lưu item, nếu không có nó sẽ chuyển tiếp truy vấn theo hướng đến root của item.
Quá trình truy vấn item được minh họa trong HX ình 1.11X dưới đây
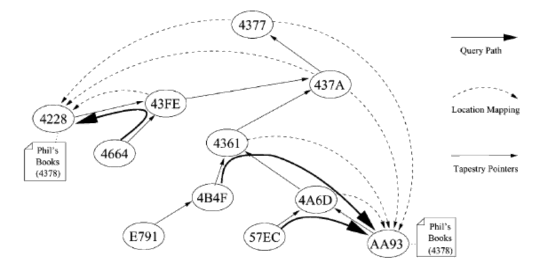
Hình 1.11. Ví dụ về Tapestry node tìm kiếm item
Join/leave and maintenance
Chèn một node N vào mạng bắt đầu bằng việc tìm kiếm node gốc S (có chung prefix độ dài p) của N. Node S sau đó gửi thông điệp tới các node cùng chung prefix, các node này sau khi nhận được thông điệp sẽ chèn N vào trong bảng định tuyến của chúng và chuyển các ánh xạ tham chiếu vị trí nếu cần thiết.
Quá trình khởi tạo bảng định tuyến của N diễn ra như sau. N tìm kiếm các neighbour gần nhất bắt đầu với mức định tuyến p, điền các neighbour này vào bảng định tuyến ở mức p dùng k node gần nhất. Sau đó N giảm p và tiếp tục quá trình như vậy cho đến khi các mức trong bảng định tuyến được điền đầy.
1.3.4. Kelips
Overlay graph
Kelisp băm không gian ID vào k nhóm sử dụng consistent hashing, đánh số từ 0 đến k-1. Do sử dụng thuật toán consistent hashing nên Kelips đảm bảo rằng số node trong mỗi nhóm là n/k với xác xuất cao.
Bảng định tuyến của một Kelips node bao gồm ba phần:
Affinity group view: thông tin về một tập các node nằm trong cùng nhóm.
Contact: đối với mỗi nhóm, Kelips lưu thông tin về một tập nhỏ các node trong nhóm đó.
Filetuples: một tập các bộ, mỗi bộ lưu thông tin về một file và node chứa file đó. Một node chỉ lưu thông tin về các file chứa trong các node nằm cùng nhóm với node đó.
XHình 1.12X minh họa bảng định tuyến của một node trong hệ thống có 10 nhóm:
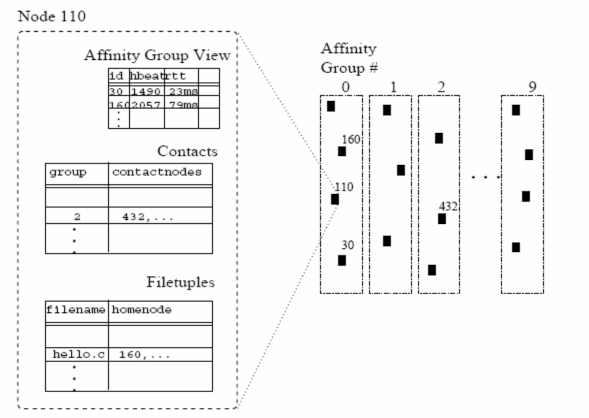
Hình 1.12. Mạng Kelips trong đó các node phân tán trong 10 nhóm affinity và trạng thái tại một node cụ thể
Mapping items onto nodes
Một item được băm vào một trong các nhóm của hệ thống sử dụng cùng thuật toán consistent hashing được dùng để băm các node và được lưu trên một node bất kỳ trong nhóm này.
Lookup process
Khi một node muốn truy vấn một item, nó sẽ dùng consistent hashing xem item được ánh xạ vào nhóm nào và gửi truy vấn đến contact gần nhất trong nhóm đó. Nếu trong các bộ của node contact có item cần tìm, node sẽ trả kết quả về cho node truy vấn, nếu node contact không có thông tin về item cần tìm, node truy vấn có thể gửi yêu cầu