Mapping Items Onto Nodes.
Như chúng ta thấy trên XHình 1.4X, một item được lưu trên node đầu tiên mà theo sau nó theo chiều kim đồng hồ trong không gian ID. Các item với ID tương ứng 2, 3, 6, 10,13 được lưu trong các node trên mạng như sau: {2,3} được lưu tại node 3; {6} được lưu tại node 9; {10} được lưu tại node 11; và {13} được lưu tại node 0
Lookup Process
Quá trình tìm kiếm là kết quả tự nhiên của cách chia không gian ID. Cả việc chèn và tìm kiếm dữ liệu đều dựa trên việc tìm ID successor của một ID.
Ví dụ, khi node 11 muốn chèn một item mới với ID là 8, lookup được chuyển tiếp tới node 3 là node đứng trước gần node 8 nhất trong bảng finger của node 11. Node lại thực hiện quá trình tương tự, nó chuyển tiếp yêu cầu tới node 5 là node đứng trước gần 8 nhất trong bảng finger của nó. Node 5 thấy rằng 8 nằm giữa nó và successor của nó (node 9), do đó nó trả về kết quả 9 theo đường đi ngược lại. Sau khi nhận được câu trả lời, tầng ứng dụng trên node 11 sẽ liên lạc với tầng ứng dụng trên node 9 và yêu cầu lưu một số giá trị với key là 8. Bất kỳ node nào muốn tìm kiếm key 8 đều thực hiện quá trình tương tự và trong không quá M chặng, một node sẽ tìm ra node lưu các dữ liệu ứng với key 8. Nói chung, trong điều kiện thông thường, một tìm kiếm sẽ hoàn thành trong O(log2(N)) chặng.
Joins, Leaves and Maintenance
Khi node n muốn join vào mạng, nó phải tìm ID của mình thông qua một số contact trong mạng và chèn bản thân nó vào vòng giữa successor s của nó và predecessor của s sử dụng một thuật toán stabilization chạy định kỳ. Bảng định tuyến của n được khởi tạo bằng cách copy bảng định tuyến của s hoặc yêu cầu s tìm các finger của n. Tập các node cần điều chỉnh bảng định tuyến sau khi n join vào mạng nhờ các node này đều chạy thuật toán stabilization định kỳ. Nhiệm vụ cuối cùng là chuyển
Có thể bạn quan tâm!
-

 Đánh giá hiệu năng của một số thuật toán bảng băm phân tán DHT và đưa ra giải pháp cải tiến hiệu năng của thuật toán CHORD - 1
Đánh giá hiệu năng của một số thuật toán bảng băm phân tán DHT và đưa ra giải pháp cải tiến hiệu năng của thuật toán CHORD - 1 -
 Đánh giá hiệu năng của một số thuật toán bảng băm phân tán DHT và đưa ra giải pháp cải tiến hiệu năng của thuật toán CHORD - 2
Đánh giá hiệu năng của một số thuật toán bảng băm phân tán DHT và đưa ra giải pháp cải tiến hiệu năng của thuật toán CHORD - 2 -
 (A) Một Mạng Chord Với 6 Node, 5 Item Và N=16. (B) Nguyên Tắc Chung Của Bảng Routing Table. (C) Bảng Routing Table Của Node 3 Và Node 11
(A) Một Mạng Chord Với 6 Node, 5 Item Và N=16. (B) Nguyên Tắc Chung Của Bảng Routing Table. (C) Bảng Routing Table Của Node 3 Và Node 11 -
 Minh Họa Cách Chọn Bảng Định Tuyến Của Một Node Tapestry
Minh Họa Cách Chọn Bảng Định Tuyến Của Một Node Tapestry -
 Quá Trình Thực Nghiệm Và Phương Pháp Đánh Giá Hiệu Năng
Quá Trình Thực Nghiệm Và Phương Pháp Đánh Giá Hiệu Năng -
 Đồ Thị Biểu Diễn Tỷ Lệ Tìm Kiếm Thành Công (Fration Of Successful Lookups) Theo Băng Thông Trung Bình Một Node Sử Dụng (Average Live Bandwidth) Trong Mạng
Đồ Thị Biểu Diễn Tỷ Lệ Tìm Kiếm Thành Công (Fration Of Successful Lookups) Theo Băng Thông Trung Bình Một Node Sử Dụng (Average Live Bandwidth) Trong Mạng
Xem toàn bộ 98 trang tài liệu này.
một phần các item đang lưu trên node s có ID nhỏ hơn hoặc bằng n sao node n. Việc di chuyển dữ liệu này được thực hiện bởi tầng ứng dụng của n và s.
Giả mã của các quá trình tìm kiếm successor của node n, khởi tạo bảng định tuyến của n, cập nhật bảng finger của các node liên quan và quá trình stabilization như sau:
//yêu cầu node n tìm successor của id n.find_successor(id);
n’=find_predecessor(id);
return n’.successor;
// yêu cầu node n tìm predecessor của id n.find_predecessor(id);
n’=n;
while (id (n’, n’.successor]) n’=n’.closest_preceding_finger(id);
return n’;
// trả về finger gần nhất đứng trước id n.closest_preceding_finger(id);
for i = m downto 1
if (finger[i].node (n; id))
return finger[i].node;
return n;
Thuật toán 1.1. Giả mã tìm node successor của ID n
#define successor finger[1].node
// node n join vào mạng;
// n’ là một node tùy ý trong mạng n.join(n’)
if (n’)
init_finger_table(n’); update_others();
// chuyển key trong khoảng (predecessor,n] từ successor
else // n là node duy nhất trên mạng
for i = 1 to m
finger[i].node = n;
predecessor = n ;
// khởi tạo bảng finger table của node
// n’ là một node bất kỳ trên mạng n.init_finger_table(n’)
finger[1].node = n’.fin_successor(finger[1].start); predecessor = successor.predecessor; successor.predecessor = n;
for i = 1 to m-1
if (finger[i+1].start [n, finger[i].node)) finger[i+1].node = finger[i].node;
else
finger[i+1].node =
n’.find_successor(finger[i+1].start);
// cập nhật n vào các node có finger table that đổi n.update_others()
for i = 1 to m
//tìm node p cuối cùng có finger thứ i là n p = find_predecessor(n-2i-1); p.update_finger_table(n.,i);
//nếu s là finger thứ i của n, cập nhật s vào bảng finger của n n.update_finger_table(s,i)
if (s [n, finger[i].node)) finger[i].node = s;
p = predecessor; // lấy node đầu tiên đứng trước n p.update_finger_table(s,i);
Thuật toán 1.2. Giả mã cho hoạt động join vào mạng của một node
n.join(n’)
predecessor = nil;
successor = n’.find_successor(n);
// định kỳ kiểm tra successor đứng ngay n và báo cho successor
//biết về n
n.stabilize()
x = successor.predecessor;
if ( x (n, successor)) successor = x;
successor.notify(n);
// n’ nghĩ n’ là predecessor của n
n.notify(n’)
if (predecessor is nil or n’ (predecessor,n)) predecessor = n’ ;
// định kỳ cập nhật các finger trong bảng finger table
n.fix_finger()
i = random index > 1 into finger [] finger[i].node = find_successor(finger[i].start);
Thuật toán 1.3. Giả mã cho quá trình stabilization
XHình 1.5X cho chúng ta thấy một ví dụ về quá trình join vào mạng của một node.
Giả sử node 21 có successor là node 32, trên node 32 đang lưu các key 24 và 30. Node 26 join vào mạng, sau quá trình tìm kiếm, node 26 biết node 32 là successor của mình, nó trỏ con trỏ successor của mình vào node 32 và báo cho node 32 biết. Node 32 sau khi được báo thì trỏ con trỏ predecessor vào node 26. Node 26 copy các key tương ứng với nó (key 24) từ node 32. Đến định kỳ, N21 chạy quá trình stabilize, lúc này con trỏ successor vẫn trỏ vào node 32. Node 21 hỏi node 32 về predecessor của node 32, lúc này predecessor của 32 là 26. Sau khi nhận được câu trả lời, N21 trỏ con trỏ successor vào node 26 và báo cho node 26 biết nó là predecessor của node 26. Node 26 trỏ con trỏ predecessor vào node 21
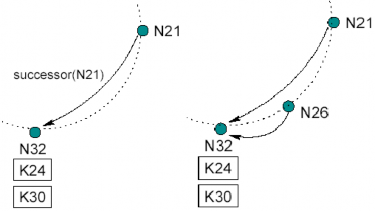
Hình 1.5. Quá trình một node join vào mạng
Quá trình rời khỏi mạng có báo trược được thực hiện như sau: node sắp rời khỏi mạng chuyển các key nó đang lưu sang successor của nó rồi báo cho các node predecessor và successor. Bảng định tuyến của các node liên quan sẽ được cập nhật khi các node này chạy thuật toán stabilization.
XHình 1.6X dưới đây cho chúng ta một ví dụ về bảng định tuyến của các node khi có sự join/leave. Ban đầu mạng có 3 node với ID là 0, 1, 3, bảng định tuyến của chúng được cho thấy trên hình vẽ.
Sau đó node 6 join vào mạng rồi node 3 rời khỏi mạng, bảng định tuyến của các node và sự thây đổi bảng định tuyến được thể hiện trong hình vẽ với những phần thay đổi có màu đen, những phần không đổi có màu xám.

Hình 1.6. (a) Bảng finger và vị trí của key sau khi node 6 join. (b)Bảng finger và vị trí của key sau khi node 3 leave.
Replication and Fault Tolerance
Các node rời khỏi mạng đột ngột có hai tác động tiêu cực. Thứ nhất là dẫn đến mất dữ liệu lưu trên các node này, thứ hai một phần của vòng bị mấtl liên kết dẫn đến một số ID sẽ không được tìm thấy. Có thể xảy ra tình huống một dãy các node liền nhau cùng rời khỏi mạng đột ngột. Chord giải quyết vấn đề này bằng cách cho mỗi node lưu một danh sách log2(N) node theo sau nó trong không gian ID. Danh sách này có hai mục đích, thứ nhất là nếu một node phát hiện successor của nó không hoạt động, nó sẽ thay thế bằng node ngay cạnh trong successor list, thứ hai, mọi dữ liệu được lưu trên một node nào đó cũng được lưu trên các node trong successor list. Dữ liệu chỉ bị mất hay vòng chỉ bị đứt khi có log2(N) + 1 node liên tiếp fail đồng thời.
Upper Services and Applications
Một số ứng dụng như cooperative file-system [14], một ứng dụng đọc/ghi hệ thống file và một DNS đã được xây dựng dựa trên Chord. Đồng thời, một thuật toán broadcast cũng được phát triển cho Chord
Implementation
Cài đặt chính của Chord được thực hiện bằng nghôn ngữ C++. Thêm nữa, một C++ discrete-event simulator cũng đã được xây dựng. Naanou là một cài đặt C# của Chord với một ứng dụng chia sẻ file được xây dựng dựa trên nó.
1.3.2. Kademlia
Overlay graph
Kademlia graph tổ chức các ID trong không gian vòng tròn trong đó ID của các node là lá của cây nhị phân, vị trí của các node được xác định bằng prefix của ID. Các ID trong Kademlia được biểu diễn theo cơ sở nhị phân. Mỗi node chia cây nhị phân thành các cây nhị phân con liên tiếp mà không chứa ID của node và lưu ít nhất một contact trong mỗi cây con này. Ví dụ, một node với ID là 3 có biểu diễn nhị phân 0011 trong không gian ID N=16. Do prefix với độ dài 1 là 0 nên nó cần biết một node với chữ số đầu tiên là 1. Tương tự như vậy, do prefix với độ dài 2 là 00 nên node cần biết một node với prefix là 01. Prefix với độ dài 3 là 001, node cần biết một node khác với prefix 000. Cuối cùng, do prefix với độ dài bằng 4 là 0011 nên nó cần biết node có prefix là 0010. Quy tắc này được minh họa trong XHình 1.7X dưới đây:
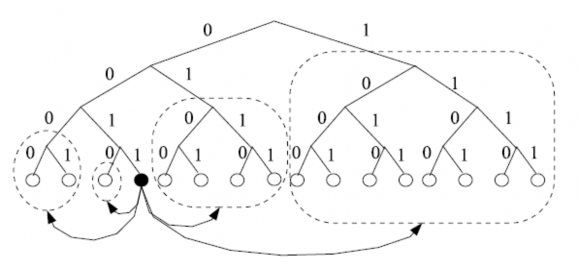
Hình 1.7.Con trỏ của node 3 (0011) trong Kademlia
Kademlia không lưu một danh sách các node gần với nó trong không gian ID như successor list của Chord. Tuy nhiên với mỗi cây con trong không gian ID, node lưu tới k contact thay vì một contact nếu có thể và gọi một nhóm không nhiều hơn k contact trong một cây con là subtree.
Mapping items onto nodes
Kademlia định nghĩa khái niệm khoảng cách giữa hai ID là kết quả XOR của hai ID. Một item được lưu trên node mà khoảng cách giữa hai ID là nhỏ nhất.
Lookup process
Để tăng cường khả năng tìm kiếm và giảm thời gian phản hồi, Kademlia thực hiện các lookup đồng thời và theo phương pháp lặp.
Khi một node tìm kiếm một ID, nó sẽ kiểm tra cây con nào chứa ID và chuyển yêu cầu lookup đến node ngẫu nhiên từ được lựa chọn từ k-bucket của cây con đó. Mỗi node lại trả về một k-bucket của cây con nhỏ hơn gần hơn với ID. Từ bucket được