Danh mục thuật toán
UThuật toán 1.1. Giả mã tìm node successor của ID nU 25
UThuật toán 1.2. Giả mã cho hoạt động join vào mạng của một nodeU 26
UThuật toán 1.3. Giả mã cho quá trình stabilizationU 27
UThuật toán 3.1. Thuật toán join tối ưu hóaU 73
UThuật toán 3.2. Thuật toán leave tối ưu hóaU 76
UThuật toán 3.3. Quá trình stabilization định kỳ để xử lý failureU 78
UThuật toán 3.4. Quá trình cachingU 81
UThuật toán 3.5. Đồng bộ hóa vòng proxy và vòng node Chord thông thườngU 85
Có thể bạn quan tâm!
-

 Đánh giá hiệu năng của một số thuật toán bảng băm phân tán DHT và đưa ra giải pháp cải tiến hiệu năng của thuật toán CHORD - 1
Đánh giá hiệu năng của một số thuật toán bảng băm phân tán DHT và đưa ra giải pháp cải tiến hiệu năng của thuật toán CHORD - 1 -
 (A) Một Mạng Chord Với 6 Node, 5 Item Và N=16. (B) Nguyên Tắc Chung Của Bảng Routing Table. (C) Bảng Routing Table Của Node 3 Và Node 11
(A) Một Mạng Chord Với 6 Node, 5 Item Và N=16. (B) Nguyên Tắc Chung Của Bảng Routing Table. (C) Bảng Routing Table Của Node 3 Và Node 11 -
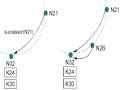 (A) Bảng Finger Và Vị Trí Của Key Sau Khi Node 6 Join. (B)Bảng Finger Và Vị Trí Của Key Sau Khi Node 3 Leave.
(A) Bảng Finger Và Vị Trí Của Key Sau Khi Node 6 Join. (B)Bảng Finger Và Vị Trí Của Key Sau Khi Node 3 Leave. -
 Minh Họa Cách Chọn Bảng Định Tuyến Của Một Node Tapestry
Minh Họa Cách Chọn Bảng Định Tuyến Của Một Node Tapestry
Xem toàn bộ 98 trang tài liệu này.
UThuật toán 3.6. Xử lý thay đổi trong vòng proxyU 86
UThuật toán 3.7. Quá trình tìm kiếm và chèn trong giải pháp nhân bản đối xứngU 89
UThuật toán 3.8. Join và leave trong trường hợp nhân bản đối xứngU 90
UThuật toán 3.9. Xử lý failure trong nhân bản đối xứngU 90
UThuật toán 3.10. Thuật toán bulk owner operationU 91
Danh mục bảng
UBảng 1.1. Trạng thái phát triển của các simulatorU 41
UBảng 1.2. Đặc điểm của các simulatorU 42
UBảng 2.1. Bảng tham số của KademliaU 49
UBảng 2.2. Bảng tham số của ChordU 50
UBảng 2.3. Bảng tham số của KelipsU 51
UBảng 2.4. Bảng tham số của TapestryU 52
UBảng 2.5. Giá trị churn rate để các DHT đạt được tỷ lệ tìm kiếm thành công 90% trong mạng 100 và 1000 nodeU 53
UBảng 2.6. Điều kiện mô phỏngU 54
UBảng 2.7. Giá trị tham số của ChordU 54
UBảng 2.8. Giá trị tham số của TapestryU 54
UBảng 2.9. Giá trị tham số của KelipsU 55
UBảng 2.10. So sánh giữa Chord, Kelips và TapestryU 56
UBảng 2.11. Giá trị tham số của ChordU 57
UBảng 2.12. Giá trị tham số của KelipsU 58
UBảng 2.13. Giá trị tham số của TapestryU 58
UBảng 2.14. Bảng tóm tắt kết quảU 63
UBảng 2.15. Giá trị tham số của ChordU 64
UBảng 2.16. Giá trị tham số của KelipsU 64
UBảng 2.17. Giá trị tham số của TapestryU 65
Lời mở đầu
Khoảng mười năm trở lại đây, thế giới đã chứng kiến sự bùng nổ của Internet băng thông rộng, cùng với nó là sự phát triển mạnh mẽ của các ứng dụng peer-to-peer. Với nhiều ưu điểm hứa hẹn như tính hiệu quả, linh hoạt và khả năng mở rộng cao, các mạng peer-to-peer overlay đã và đang thu hút được nhiều sự quan tâm từ cộng đồng nghiên cứu. Các mạng peer-to-peer overlay đã phát triển qua ba thế hệ, thế hệ hiện nay là mạng structured overlay dựa trên khả năng lưu trữ và tìm kiếm dữ liệu hiệu quả của cơ chế bảng băm phân tán (Distributed Hash Table hay DHT).
Các DHT được thiết kế để làm trong môi trường tương đối ổn định với các peer là máy tính. Tuy nhiên, vài năm gần đây, các thiết bị nối mạng ngày càng phong phú, đa dạng như tivi hay các thiết bị wireless như điện thoại, PDA, …. Các thiết bị này kết nối và rời khỏi mạng sau một thời gian ngắn (churn rate cao) khiến cho thông tin về các peer trên mạng liên tục thay đổi dẫn đến hiệu năng của các DHT giảm sút rõ rệt. Đánh giá và cải thiện hiệu năng của các DHT trong điều kiện mạng churn rate cao là bài toán đang rất được quan tâm hiện nay.
Luận văn bao gồm ba phần. Phần thứ nhất tóm tắt lý thuyết chung về mạng peer-to-peer. Phần thứ hai, luận văn phân tích, đánh giá hiệu năng của một số DHT nổi tiếng như Chord, Kademlia, Tapestry, Kelips trong điều kiện mạng churn rate cao. Dựa trên kết quả đạt được, luận văn phân tích hạn chế của giao thức Chord và đưa ra giải pháp cải tiến hiệu năng của giao thức này trong điều kiện churn rate cao.
Các kết quả nghiên cứu trong luận văn đã được công bố trên một số bài báo quốc tế và trong nước [15, 16, 17, 18].
Chương 1.
L0B
ý thuyết tổng quan
1.1. Lý thuyết chung về về mạng P2P
1.1.1. Khái niệm mạng P2P
Trong khoảng 10 năm trở lại đây, lĩnh vực P2P nhận được sự quan tâm của rất nhiều nhóm nghiên cứu, của các công ty, trường đại học và đã có những bước phát triển mạnh mẽ. Ngày nay các ứng dụng peer-to-peer được sử dụng rộng rãi cho nhiều mục đích khác nhau như chia sẻ tài nguyên và nội dung, chat, chơi game, …
Cũng giống như các xu hướng đang trong quá trình phát triển khác, hiện nay chưa có một định nghĩa chính xác về mạng P2P. Dưới đây là một số định nghĩa về P2P: Theo Oram, P2P là một lớp các ứng dụng tận dụng các tài nguyên như bộ nhớ,
năng lực xử lý, nội dung, … tại các điểm cuối trong mạng Internet. Bởi vì truy cập vào các tài nguyên phân tán này cũng có nghĩa là hoạt động trong một môi trường liên kết không ổn định và với địa chỉ IP có thể thay đổi, các node P2P phải hoạt động ngoài hệ thống DNS và có quyền tự trị cao hoặc hoàn toàn tự trị.
Theo Miller, P2P là một kiến trúc trong đó các máy tính có vai trò và trách nhiệm như nhau. Mô hình này đối lập với mô hình client/server truyền thống, trong đó một số máy tính được dành riêng để phục vụ các máy tính khác. P2P có năm đặc điểm:
− Việc truyền dữ liệu và thông tin giữa các peer trong mạng dễ dàng
− Các peer vừa có thể hoạt động như client vừa có thể hoạt động như server
− Nội dung chính trong mạng được cung cấp bởi các peer
− Mạng trao quyền điều khiển và tự trị cho các peer
− Mạng hỗ trợ các peer không kết nối thường xuyên và các peer không có địa chỉ IP cố định
Theo P2P Working Group: P2P computing là sự chia sẻ tài nguyên và dịch vụ bằng cách trao đổi trực tiếp giữa các hệ thống. Tài nguyên và dịch vụ ở đây bao gồm
thông tin, chu kỳ xử lý, không gian lưu trữ. Peer-to-peer computing tận dụng sức mạnh tính toán của các máy tính cá nhân và kết nối mạng, cho phép doanh nghiệp tận dụng sức mạnh tổng hợp của các client.
Các định nghĩa về P2P thống nhất ở một số khái niệm: chia sẻ tài nguyên, tự trị/phân tán, địa chỉ IP động, vai trò vừa là client vừa là server.
1.1.2. Quá trình phát triển của các hệ thống P2P
Peer-to-Peer là thuật ngữ tương đối mới trong lĩnh vực mạng và các hệ thống phân tán. Theo Oram, P2P computing bắt đầu trở thành đề tài được nhiều người quan tâm từ giữa những năm 2000. Trong khoảng thời gian từ đó đến nay, P2P trải qua vài thế hệ, mỗi thế hệ được phát triển với những động cơ, mục đích của mình.
Thế hệ thứ nhất
Thế hệ P2P đầu tiên bắt đầu với sự xuất hiện của ứng dụng chia sẻ file Napster. Napster và các ứng dụng khác trong thế hệ thứ nhất sử dụng mô hình centralized directory. Đây là mô hình hybrid P2P trong đó hầu hết các peer trong hệ thống có vai trò như nhau, một số peer có vai trò lớn hơn và được gọi là các server.
XHình 1.1X cho thấy một ví dụ về mô hình centralized directory. Trong mô hình này, các peer muốn chia sẻ file với các peer khác sẽ thông báo với server về các file này. Khi một peer muốn tìm một file nào đó, nó sẽ gửi yêu cầu đến server, dựa trên các thông tin đã thu thập được, server sẽ tìm ra các peer chứa file đó và trả kết quả tìm kiếm cho peer yêu cầu. Kết quả trả về là peer phù hợp dựa trên một số thông số như tốc độ kết nối, kích thước file, …. Sau khi nhận được kết quả, peer tìm kiếm sẽ trao đổi file trực tiếp với peer chứa file mà không thông qua server nữa.
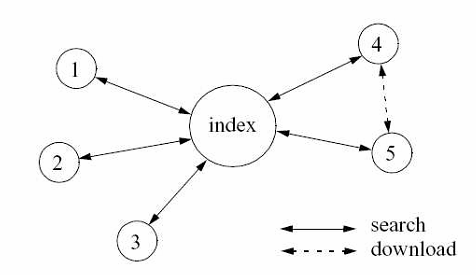
Hình 1.1. Mô hình centralized directory
Đóng góp chính của thế hệ thứ nhất là đã đưa ra kiến trúc mạng không xem các máy tính như client và server mà xem chúng như các máy cung cấp và sử dụng tài nguyên với vai trò tương đương nhau. Mô hình centralized directory cho phép tìm kiếm thông tin trong không gian lưu trữ một cách nhanh chóng, tuy nhiên, điểm yếu của của mô hình này là tính khả mở vì tải trên index server sẽ tăng tuyến tính với số lượng peer. Đồng thời các hệ thống sử dụng mô hình này, điển hình là Napster còn gặp vấn đề về bản quyền các tài nguyên.
Thế hệ thứ hai
Thế hệ thứ hai bắt đầu với các ứng dụng như Gnutella, Freenet làm việc mô hình flooded requests. Mô hình này không có bất kỳ server nào, các peer bình đẳng như nhau. Các hệ thống peer to peer thế hệ thứ hai là các hệ thống peer to peer thuần túy. Không giống thế hệ thứ nhất, các peer không thông báo về các nội dung chúng chia sẻ, khi một peer muốn tìm kiếm một file, nó gửi yêu cầu tới các peer kết nối trực tiếp với nó, nếu các peer đó không tìm thấy file, mỗi peer sẽ gửi yêu cầu tìm kiếm đến
các peer kết nối trực tiếp với nó, quá trình cứ diễn ra như vậy cho đến khi request bị timeout. Quá trình gửi yêu cầu tìm kiếm đi như vậy gọi là flooding. XHình 1.2X biểu diễn một mô hình flooding request.
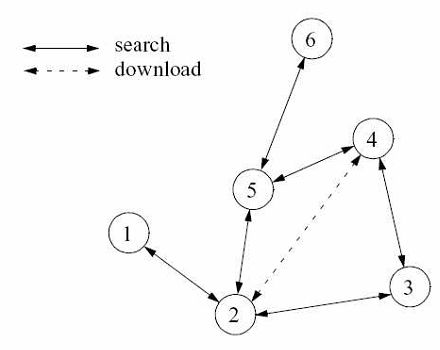
Hình 1.2. Mô hình flooding request
Thế hệ thứ hai xóa bỏ được một số điểm xử lý tập trung trong mạng nhưng tính khả mở còn kém hơn do mạng sử dụng thuật toán flooding sinh ra quá nhiều traffic. Thêm nữa, các mạng làm việc theo mô hình này không đảm bảo sẽ tìm được dữ liệu có trên mạng do phạm vi tìm kiếm bị giới hạn. Một số mạng trong thế hệ thứ hai đưa ra một số cải tiến. Freenet đưa ra mô hình document routing, trong đó dữ liệu được lưu trên trên node có id tương tự với id của dữ liệu và các query được chuyển tiếp dựa trên id của dữ liệu tìm kiếm. Kazza, Gnutella sử dụng khái niệm super peer trong đó một số node hoạt động như directory service, giảm lượng flooding trong mạng.
Thế hệ thứ ba
Sự đơn giản trong giải pháp và khả năng xóa bỏ điểm tập trung, chuyển trách nhiệm pháp lý về phía người sử dụng cũng như hạn chế về tính khả mở do lưu lượng quá lớn đã thu hút cộng đồng nghiên cứu về mạng và các hệ thống mở. Bài toán đặt ra cho cộng đồng nghiên cứu là xây dựng một mạng P2P overlay khả mở không có điểm điều khiển tập trung. Nỗ lực giải quyết bài toán này là sự xuất hiện của “structured P2P overlay networks”.
Thế hệ thứ ba được khởi đầu với các dự án nghiên cứu như Chord, CAN, Pastry, Tapestry và P-Grid. Các dự án này đưa ra khái niệm Distributed Hash
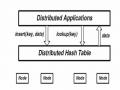
Table (DHT). Mỗi peer trong hệ thống có một ID thu được từ việc băm các đặc thuộc tính đặc trưng của peer đó như địa chỉ IP hay public key. Mỗi data item cũng có một ID thu được theo cách tương tự với các peer. Hash table lưu data dưới dạng cặp key-value. Như vậy, node ID và cặp key-value được băm vào cùng một không gian ID. Các node sau đó được nối với nhau theo một topology nào đó. Quá trình tìm kiếm dữ liệu trở thành quá trình định tuyến với kích thước bảng định tuyến nhỏ và chiều dài đường đi cực đại. Thế hệ thứ ba đảm bảo xác xuất tìm thấy thông tin cao.
Các DHT được xây dựng nhằm mục đích cho phép các peer hoạt động như một cấu trúc dữ liệu phân tán với hai hàm chính Put(key,value) và Get(Key). Hàm Put lưu dữ liệu tại một peer nào đó sao cho bất kỳ peer nào cũng có thể tìm được bằng hàm Get. Các hàm này hoàn thành sau khi đi qua một số nhỏ các chặng. Giải pháp DHT đảm bảo cho mạng có tính khả mở và khả năng tìm thấy thông tin cao trong khi vẫn hoàn toàn phân tán. DHT đang được xem như là cách tiếp cận hợp lý cho vấn đề định vị và định tuyến trong các hệ thống P2P. Cộng đồng nghiên cứu đã đưa ra nhiều DHT khác nhau. Mỗi DHT hoạt động theo nguyên lý chung và có ưu điểm riêng, Chord với thiết kế đơn giản, Tapestry và Pastry giải quyết được vấn đề proximity routing, …