nghiên cứu hơn nữa để đóng góp về mặt lý luận cho lĩnh vực phân lớp nói riêng và lĩnh vực khai thác dữ liệu và khám phá tri thức nói chung.
1.9 Bố cục luận văn
Luận văn bao gồm các phần sau:
Chương 1: Tổng quan
Giới thiệu về những vấn đề liên quan đến phân lớp dữ liệu trong khai thác dữ liệu, Cơ sở hình thành đề tài, Các nghiên cứu liên quan, Mục tiêu của luận văn, Đối tượng nghiên cứu, Các phương pháp nghiên cứu, Nội dung và phạm vi nghiên cứu, Ý nghĩa của luận văn và Bố cục luận văn.
Chương 2: Cơ sở lý thuyết
Có thể bạn quan tâm!
-

 Sử dụng cây quyết định phân lớp dữ liệu mất cân đối - 1
Sử dụng cây quyết định phân lớp dữ liệu mất cân đối - 1 -
 Sử dụng cây quyết định phân lớp dữ liệu mất cân đối - 2
Sử dụng cây quyết định phân lớp dữ liệu mất cân đối - 2 -
 Các Vấn Đề Trong Khai Thác Dữ Liệu Sử Dụng Cây Quyết Định
Các Vấn Đề Trong Khai Thác Dữ Liệu Sử Dụng Cây Quyết Định -
 Đánh Giá Độ Chính Xác Của Mô Hình Phân Lớp
Đánh Giá Độ Chính Xác Của Mô Hình Phân Lớp -
 Phân Lớp Dữ Liệu Mất Cân Đối Bằng Cây Quyết Định
Phân Lớp Dữ Liệu Mất Cân Đối Bằng Cây Quyết Định
Xem toàn bộ 81 trang tài liệu này.
Giới thiệu cách tiếp cận và giải quyết vấn đề của luận văn. Trình bày cơ sở toán học và áp dụng lý thuyết vào bài toán.
Chương 3: Thuật toán phân lớp dữ liệu mất cân đối bằng cây quyết định
Trong chương này trình bày cách tiếp cận mới trong phân lớp dữ liệu mất cân đối bằng cây quyết định bằng cách thay đổi và cải tiến thuật toán C4.5.
Chương 4: Thực nghiệm và đánh giá.
Thực nghiệm chương trình với tập dữ liệu huấn luyện. Kiểm nghiệm đánh giá chương trình với tập dữ liệu kiểm tra.
Chương 5: Kết luận và hướng phát triển
Ý nghĩa thực tiễn, những hạn chế và hướng phát triển của luận văn.
CHƯƠNG 2. CƠ SỞ LÝ THUYẾT
2.1 Tổng quan về khai thác dữ liệu
2.1.1 Khai thác dữ liệu là gì?
Khai thác dữ liệu là một khái niệm ra đời vào cuối những năm 1980. Nó là quá trình khám phá thông tin ẩn được tìm thấy trong các cơ sở dữ liệu (CSDL) và có thể xem như là một bước trong quá trình khám phá tri thức. KTDL là giai đoạn quan trọng nhất trong tiến trình khai thác tri thức từ CSDL, các tri thức này hỗ trợ trong việc ra quyết định trong các lĩnh vực như: khoa học, giáo dục, kinh doanh, …
Năm 1989 Fayyad, Smyth và Piatestsky-Shapiro đã dùng khái niệm Phát hiện tri thức từ CSDL trong đó KTDL là một giai đoạn rất đặc biệt trong toàn bộ quá trình, nó sử dụng các kỹ thuật để tìm ra các mẫu từ dữ liệu.
KTDL là quá trình phát hiện các mô hình, các tổng kết khác nhau và các giá trị được lấy từ tập dữ liệu cho trước. Hay, KTDL là sự thăm dò và phân tích lượng dữ liệu lớn để khám phá từ dữ liệu ra các mẫu hợp lệ, mới lạ, có ích và có thể hiểu được.
2.1.2 Quá trình khai thác dữ liệu

Hình 2-1: Quá trình khai thác dữ liệu
Bắt đầu của quá trình là kho dữ liệu thô và kết thúc với tri thức được chiết xuất ra. Về lý thuyết thì có vẽ rất đơn giản nhưng thực sự đây là một quá trình rất khó khăn gặp phải rất nhiều vướng mắc như: quản lý các tập dữ liệu, phải lặp đi lặp lại toàn bộ quá trình,…
Tập hợp dữ liệu
Đây là giai đoạn đầu tiên trong quá trình KTDL. Giai đoạn này lấy dữ liệu trong một CSDL, một kho dữ liệu và dữ liệu từ các nguồn Internet.
Trích lọc dữ liệu
Giai đoạn này dữ liệu được lựa chọn hoặc phân chia theo một số tiêu chuẩn nào đó.
Tiền xử lý và chuẩn bị dữ liệu
Giai đoạn này rất quan trọng trong quá trình KTDL. Một số lỗi thường mắc phải trong khi thu thập dữ liệu như thiếu thông tin, không logic... Vì vậy, dữ liệu thường chứa các giá trị vô nghĩa và không có khả năng kết nối dữ liệu.
Giai đoạn này tiến hành xử lý những dạng dữ liệu nói trên. Những dữ liệu dạng này được xem như thông tin dư thừa, không có giá trị. Vì vậy, đây là một giai đoạn rất quan trọng vì dữ liệu này nếu không được làm sạch - tiền xử lý - chuẩn bị trước thì sẽ gây nên những kết quả sai lệch nghiêm trọng trong KTDL.
Chuyển đổi dữ liệu
Giai đoạn chuyển đổi dữ liệu, dữ liệu đưa ra có thể sử dụng và điều khiển được bởi việc tổ chức lại nó. Dữ liệu đã được chuyển đổi phù hợp với mục đích khai thác.
Khai thác dữ liệu
Giai đoạn mang tính tư duy trong KTDL. Ở giai đoạn này nhiều thuật toán khác nhau đã được sử dụng để xuất ra các mẫu từ dữ liệu. Thuật toán thường dùng là thuật toán phân loại dữ liệu, kết hợp dữ liệu hoặc các mô hình hóa dữ liệu tuần tự.
Đánh giá kết quả mẫu
Giai đoạn cuối trong quá trình KTDL. Trong giai đoạn này, các mẫu dữ liệu được chiết xuất ra bởi phần mềm KTDL. Không phải bất cứ mẫu dữ liệu nào cũng đều hữu ích, đôi khi nó còn bị
sai lệch. Vì vậy, cần phải ưu tiên những tiêu chuẩn đánh giá để đưa ra các tri thức cần thiết và sử dụng được.
2.1.3 Khai thác dữ liệu sử dụng phân lớp
2.1.3.1 Phân lớp dữ liệu
Phân lớp dữ liệu là một quá trình gồm hai bước
Bước thứ nhất – bước học.
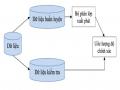
Quá trình học nhằm xây dựng một mô hình mô tả một tập các lớp dữ liệu hay các khái niệm định trước. Đầu vào của quá trình này là một tập dữ liệu có cấu trúc được mô tả bằng các thuộc tính và được tạo ra từ tập các bộ giá trị của các thuộc tính đó. Mỗi bộ giá trị được gọi chung là một phần tử dữ liệu, có thể là các mẫu. Trong tập dữ liệu này, mỗi phần tử dữ liệu được giả sử thuộc về một lớp định trước, lớp ở đây là giá trị của một thuộc tính được chọn làm thuộc tính gán nhãn lớp hay thuộc tính phân lớp. Đầu ra của bước này thường là các quy tắc phân lớp dưới dạng luật dạng if-then, cây quyết định,... Quá trình này được mô tả như trong hình 2-2.
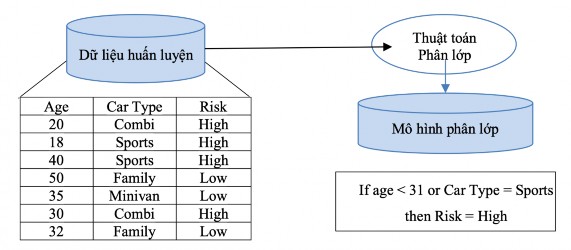
Hình 2-2: Quá trình phân lớp dữ liệu - Bước xây dựng mô hình phân lớp
Bước thứ hai – phân lớp.
Bước thứ hai dùng mô hình đã xây dựng ở bước trước để phân lớp dữ liệu mới. Trước tiên độ chính xác mang tính chất dự đoán của mô hình phân lớp vừa tạo ra được ước lượng. Holdout là một kỹ thuật đơn giản để ước lượng độ chính xác đó. Kỹ thuật này sử dụng một tập dữ liệu kiểm tra với các mẫu đã được gán nhãn lớp. Các mẫu này được chọn ngẫu nhiên và độc lập với các mẫu trong tập dữ liệu huấn luyện. Độ chính xác của mô hình trên tập dữ liệu kiểm tra đã đưa là tỉ lệ phần trăm các các mẫu trong tập dữ liệu kiểm tra được mô hình phân lớp đúng (so với thực tế). Nếu độ chính xác của mô hình được ước lượng dựa trên tập dữ liệu huấn luyện thì kết quả thu được là rất khả quan vì mô hình luôn có xu hướng quá khớp dữ liệu. Do vậy cần sử dụng một tập dữ liệu kiểm tra độc lập với tập dữ liệu huấn luyện. Nếu độ chính xác của mô hình là chấp nhận được, thì mô hình được sử dụng để phân lớp những dữ liệu tương lai, hoặc những dữ liệu mà giá trị của thuộc tính phân lớp là chưa biết.
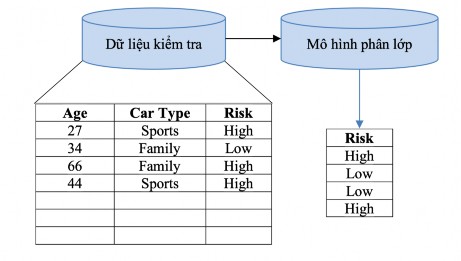
Hình 2-3: Quá trình phân lớp dữ liệu – Ước lượng độ chính xác mô hình
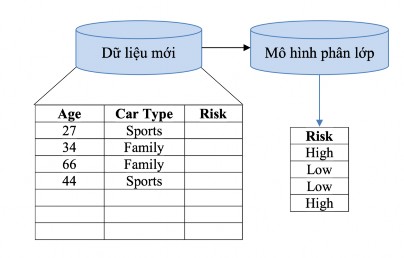
Hình 2-4: Quá trình phân lớp dữ liệu – Phân lớp dữ liệu mới
2.1.3.2 Phân lớp dữ liệu bằng thuật giải Inductive Learning Algorithm
Thuật giải Inductive Learning Algorithm (ILA) được dùng để xác định các luật phân loại cho tập hợp các mẫu học. Thuật giải này thực hiện theo cơ chế lặp, để tìm luật riêng đại diện cho tập mẫu của từng lớp. Sau khi xác định được luật, thuật giải sẽ loại bỏ các mẫu mà luật này bao hàm, đồng thời thêm luật mới này vào tập luật. Kết quả có được là một danh sách có thứ tự các luật.
Mô tả thuật giải ILA [23]
+ Bước 1: Chia bảng con có chứa m mẫu thành n bảng con. Một bảng con ứng với một giá trị của thuộc tính phân lớp (Lặp lại từ Bước 2 đến Bước 8 cho mỗi bảng con).
+ Bước 2: Khởi tạo số lượng thuộc tính kết hợp j với j = 1.
+ Bước 3: Với mỗi bảng con đang xét, phân chia các thuộc tính của nó thành một danh sách các thuộc tính kết hợp, mỗi thành phần của danh sách có j thuộc tính phân biệt.
+ Bước 4: Với mỗi kết hợp các thuộc tính trong danh sách trên, đếm số lần xuất hiện các giá trị cho các thuộc tính trong kết hợp đó ở các dòng chưa bị khóa của bảng đang xét nhưng nó không được xuất hiện cùng giá trị ở những bảng con khác. Chọn ra một kết hợp trong danh sách sao cho nó có giá trị tương ứng xuất hiện nhiều nhất và được gọi là Max_combination.
+ Bước 5: Nếu Max_combination = 0 thì j = j+1 quay lại Bước 3.
+ Bước 6: Khóa các dòng ở bảng con đang xét mà tại đó giá trị bằng với giá trị tạo ra Max_combination.
+ Bước 7: Thêm vào R luật mới với giả thuyết là các giá trị tạo ra Max_combination kết nối các bộ này bằng phép AND, kết luận là giá trị của thuộc tính quyết định trong bảng con đang xét.
+ Bước 8: Nếu tất cả các dòng đều khóa:
Nếu còn bảng con thì qua bảng con tiếp theo và quay lại Bước 2.
Ngược lại chấm dứt thuật toán.
Ngược lại quay lại B ước 4.
2.1.3.3 Phân lớp dữ liệu bằng mạng Naïve Bayes
Các mô hình phân lớp dựa theo Naïve Bayes [2] là loại mô hình phân lớp theo lý thuyết thống kê. Chúng có thể dự đoán xác suất của các thành viên lớp, chẳng hạn xác suất để một bản ghi nhất định thuộc về một lớp cụ thể nào đó. Phân lớp dựa theo Bayes căn cứ vào nền tảng lý thuyết là định lý Bayes (được đặt theo tên của Thomas Bayes, nhà toán học Anh vào thế kỷ 18).
Thuật toán phân lớp Naïve Bayes (NB) giả định rằng ảnh hưởng của một giá trị thuộc tính nào đó trên một lớp nhất định là độc lập với các giá trị của các thuộc tính khác. Giả định này được gọi là sự độc lập theo điều kiện lớp. Người ta giả định như vậy để đơn giản hóa khối lượng tính toán cần thiết, và vì lý do này, nó được gọi là “ngây thơ” (naïve).
Chi tiết của việc phân lớp dữ liệu bằng mạng NB có thể được tham khảo ở [2]
Ưu điểm
+ Về thời gian học (tức thời gian xây dựng mô hình): ít hơn so với phương pháp quy nạp cây quyết định, và ít hơn rất nhiều so với mạng nơ ron, nhất là đối với dữ liệu rời rạc.
+ Hiệu năng phân lớp (độ chính xác và tốc độ) cao khi dùng với CSDL lớn.
+ Thuật toán dễ hiểu và dễ hiện thực.
Nhược điểm
+ Do NB giả định là các thuộc tính độc lập với nhau, nên khi các thuộc tính có sự phụ thuộc lẫn nhau (ví dụ, trong giáo dục có một số môn học có ý nghĩa tiên quyết đối với một số môn học khác) thì phương pháp NB trở nên thiếu chính xác.
+ NB không sinh ra được những mô hình phân lớp dễ hiểu đối với người dùng không chuyên về KTDL.
2.1.3.4 Phân lớp dữ liệu bằng mạng nơ ron
Lĩnh vực học bằng các mạng nơ ron nhân tạo, lúc đầu được khởi xướng bởi các nhà tâm lý học và các nhà sinh học thần kinh muốn tìm cách xây dựng và kiểm tra những mô hình tính toán tương tự với mạng lưới các tế bào thần kinh của con người. Một mạng nơ ron nhân tạo, hay chỉ vắn tắt là mạng nơ ron, đôi khi còn được gọi là multilayer perceptron, là một tập hợp các nút xuất/nhập nối kết với nhau, trong đó mỗi đường nối kết có một trọng số liên kết với nó. Trong giai đoạn học, mạng này học bằng cách điều chỉnh các trọng số để dự đoán được nhãn lớp đúng đắn của các bản ghi nhập vào.
Ưu điểm
+ Các mô hình học được từ mạng nơ ron có khả năng chịu đựng đối với dữ liệu nhiễu cao cũng như khả năng phân lớp được những mẫu hình mà chúng chưa từng được huấn luyện.
+ Chúng rất thích hợp đối với dữ liệu nhập và xuất có trị liên tục.
+ Các thuật toán mạng nơ ron vốn có sẵn tính song song; có thể dùng các kỹ thuật song song hóa để tăng tốc quá trình tính toán.
+ Ngoài ra, gần đây đã có nhiều kỹ thuật được xây dựng để rút trích ra các luật phân lớp dễ hiểu từ các mạng nơ ron học được.
Chi tiết của việc phân lớp dữ liệu bằng các mạng nơ ron được tham khảo ở [2][3].
Nhược điểm
+ Học bằng mạng nơ ron đòi hỏi thời gian huấn luyện phải dài, vì thế thích hợp hơn với các ứng dụng nào chấp nhận điều này.