1957 và 1958. George Rasch (1960) xuất bản cuốn sách của ông đề xuất một số mô hình cho ứng đáp câu hỏi. Trong những năm 1960, nhiều công việc trong lĩnh vực này đã được đóng góp bởi Baker (1961) về so sánh thực nghiệm giữa các tiêu chí của bài thi. Có thể kể ra và Novick (1968), và Wright (1968) đã làm việc trên các mô hình nhị phân. Samejima đề xuất mô hình đa phân trong năm 1969. Nhóm học giả này đã mang lại các kết quả đáng kể trong lĩnh vực này. Thông qua những năm 1970 và 1980, một nhóm học giả mới nổi lên bao gồm Aldrich (1978), Anderson (1977, 1980), Hambleton và Swaminathan (1986), Wright and Stone (1979), Swaminathan và Rogers (1981), và Harris (1989). Cũng có những đóng góp quan trọng cho lý thuyết khảo thí hiện đại. [B4]. Vào những năm 2000, lĩnh vực IRT đã được thúc đẩy bởi một làn sóng các nhà nghiên cứu mới, những người không chỉ mở rộng các khía cạnh lý thuyết (dự toán, xác định mô hình, và sự phù hợp), mà còn nâng cao các khía cạnh tính toán và ứng dụng của nó. Nghiên cứu sâu rộng về IRT trong 50 năm qua năm đã được thể hiện bằng sự gia tăng số lượng các gói phần mềm được thiết kế để phân tích câu hỏi dữ liệu phản hồi từ các khảo sát hoặc kiểm tra. Nhiều phần mềm thương mại khác của IRT cũng được tạo ra như BILOG, MULTILOG, WINSTEPS, IRTPRO, MPLUS, QUEST, CONQUEST và HLM, là các ví dụ. Quan trọng hơn nữa là một số gói IRT đã được phát triển trong phần mềm mã nguồn mở R để ước tính các mô hình IRT khác nhau cũng xuất hiện và đã được công nhận. Bao gồm các gói ltm cho IRT không giới hạn ((Rizopoulos, 2006), eRm cho các mô hình Rasch mở rộng (Mair & Hatzinger, 2007), mlirt cho đánh giá đa cấp và Bayesian của một số mô hình IRT (Fox, 2007), gpcm (Johnson, 2007) cho một dự toán Bayesian của mô hình tín dụng một phần tổng quát, MCMCpack cho Bayesian IRT (Martin, Quinn, & Park, 2011), và mirt cho IRT đa chiều (Chalmers, 2012). De Boeck (2008) và Wilson (2008) đã sử dụng gói thống kê chung lme4 và kết hợp các mô hình Rasch theo mô hình hỗn hợp tuyến tính tổng quát. Điều này làm cho có thể sử dụng SAS PROC NLMIXED (SAS Institute Inc.) cho IRT.
Bước ngoặt cho sự phát triển nở rộ là ý tưởng thay mô hình dạng vòm chuẩn mà Birnbaum và Lord đề xuất cho hàm đặc trưng câu hỏi bằng mô hình logistic mà George Rasch đề xuất. Từ đây các khó khăn về mô hình toán học trong IRT được tháo gỡ. Trên cơ sở IRT công nghệ trắc nghiệm thích ứng nhờ máy tính (Computer
Adaptive Test – CAT) ra đời. Ngoài ra, trên cơ sở những thành tựu của IRT, công nghệ E-RATE chấm tự động các bài tự luận tiếng Anh nhờ máy tính của ETS đã được triển khai nhờ mạng Internet trong nhiều năm qua. Hiện nay một số nước Nhật, Thái Lan, Trung Quốc ... bước đầu áp dụng lý thuyết IRT vào các kì thi diện rông của mình.
1.1.5.2. Ứng dụng trắc nghiệm ở Việt Nam
Khoa học về đo lường và đánh giá trong giáo dục ở nước ta thực sự chưa được quan tâm đúng mức. Trước đây do chiến tranh, nên các chuyên gia về đo lường đánh giá ở miền Bắc gần như không có. Trước năm 1975, ở Miền Nam nước ta có một vài người được đào tạo bài bản về đo lường đánh giá như GS. Dương Thiệu Tống. Những năm 90 bộ giáo dục đã bước đầu có định hướng gửi đi đào tạo các nước phát triển các chuyên gia về đo lường đánh giá, nhưng số lượng còn quá ít. Hiện nay ngay trong một số trường sư phạm môn đo lường đánh giá vẫn chưa được giảng dạy như một môn học chính khóa. Các sách viết về khoa học đo lường cho đến nay chủ yếu của hai giáo sư GS. Dương Thiệu Tống và GS. Lâm Quang Thiệp. Các cuốn sách này tương đối hàn lâm với đa số người đọc và giáo viên. Tuy nhiên những năm gần đây các hội thảo, khóa học ngắn về đo lường đánh giá đã được các trường đại học, bộ giáo dục tổ chức thường xuyên nhằm từng bước “xóa mù”, phổ cập cho giáo viên và các nhà quản lý giáo dục. Các kì thi trung học phổ thông quốc gia chuyển dần sang hình thức thi trắc nghiệm và ứng dụng khoa học khảo thí vào công việc thiết kế, xây dựng, phân tích đề thi. Đây là một vấn đề khoa học tương đối mới nên đôi ngũ nghiên cứu, đào tạo làm chuyên môn về khỏa thí hiện đại chưa nhiều chủ yếu các nhóm nghiên cứu nằm trong trường hoặc liên quan đến ĐHQG HN.
1.2. Lý thuyết đánh giá cổ điển
Mặc dù IRT đã được nghiên cứu trong 50 năm qua, CTT vẫn được nghiên cứu và áp dụng liên tục. Nhiều chương trình thử nghiệm vẫn còn thực hiện CTT trong thiết kế và đánh giá kết quả kiểm tra. Điều này là do một số lợi thế CTT so với IRT. Ví dụ, CTT mô tả mối quan hệ giữa điểm số thực và điểm quan sát theo một cách tuyến tính làm cho mô hình CTT dễ hiểu và áp dụng nhiều nhà nghiên cứu. Nó dựa hoàn toàn vào tổng số điểm hoặc điểm số của chính các câu trả lời. Điểm quan sát của thí sinh là tổng số điểm đạt được của mỗi thí sinh và nó khác với điểm số thực sự của một điểm số lỗi thông thường. Phương pháp tính điểm này đã tạo ra một số lợi thế cũng như hạn chế. Lợi thế đầu tiên của CTT là các phân tích yêu cầu kích cỡ mẫu nhỏ hơn IRT. Thứ hai, CTT thủ tục toán học đơn giản hơn nhiều so với IRT, vì các mô hình trong CTT là tuyến tính trong khi các mô hình của IRT là phi tuyến. Thứ ba, mô hình tham số ước tính trong CTT là khái niệm đơn giản và đòi hỏi tối thiểu giả định, làm cho các mô hình hữu ích và áp dụng rộng rãi. Thứ tư, các phân tích không yêu cầu sự nghiêm chỉnh của các nghiên cứu phù hợp như trong IRT. Tuy nhiên, CTT có một vài nhược điểm lớn. Nền tảng của nhiều phân tích CTT là các đặc tính của các bài kiểm tra khó khăn và độ tin cậy. Các chỉ số này được đo bằng tỷ lệ của phần %, p, của người kiểm tra, người mà trả lời câu hỏi một cách chính xác và tổng số câu hỏi tương quan, r: Tuy nhiên, các chỉ số không liên tục vì chúng hoàn toàn phụ thuộc vào mẫu của thí sinh được lấy. Không thể sử dụng chúng để chỉ ra đặc trưng hoặc chất lượng của một bài kiểm tra. Một nhược điểm nữa đó là điểm thi của thí sinh được kiểm chứng. Nghĩa là, thí sinh có thể đạt được điểm cao hơn trên một bài kiểm tra dễ dàng hơn và điểm thấp hơn trên một khó kiểm tra, và do đó không có điểm số thực sự có thể được trích xuất. Điều này không cho phép một cơ sở để kết hợp bài kiểm tra và mức độ khả năng. Theo nghĩa này, IRT có nhiều lợi ích hơn CTT. Trong khung IRT, các đặc điểm của mục là độc lập mẫu và điểm tiềm ẩn của một cá nhân được kiểm tra độc lập với điều kiện là các mô hình được lựa chọn phù hợp với dữ liệu. Vì vậy, điểm số mô tả trình độ thí sinh không phụ thuộc vào số lượng cũng như năng lực của mẫu thử nghiệm. Điểm số của họ có thể thấp hơn khi các bài kiểm tra khó hơn và cao hơn các bài kiểm tra dễ dàng hơn nhưng điểm số về khả năng của chúng vẫn không đổi so với bất kỳ bài kiểm tra nào tại thời điểm thử nghiệm hoặc khảo sát. IRT cũng cho phép tính toán xác suất
của một người trả lời cụ thể chọn một trên một câu hỏi kiểm tra. Các bài kiểm tra mẫu độc lập tạo điều kiện thuận lợi cho việc thiết kế bài kiểm tra thích nghi trên máy tính, cho phép so sánh chính xác hơn hoặc xác định rõ năng lực người kiểm tra. Hơn nữa, IRT có thể được sử dụng để sàng lọc quy mô lớn hoặc rời rạc, vì nó có khả năng tính toán tiêu chuẩn lỗi và do đó cung cấp thông tin về chất lượng của mỗi câu hỏi thi. Hỗ trợ này với việc làm quyết định lựa chọn các câu hỏi để loại trừ hoặc đưa vào một câu hỏi kiểm tra trong bài thi. Ngoài ra, các câu hỏi cũng được lựa chọn dựa trên các chỉ số độ khó, độ phân biệt của câu hỏi, nghĩa là khả năng của họ phân biệt các nhóm có đặc điểm tiềm ẩn thấp và cao. Mặc dù có những ưu điểm, các mô hình IRT cũng có những thiếu sót hạn chế của nó. Về mặt kỹ thuật, các mô hình thường quá phức tạp hơn và các phương pháp ước lượng tham số thường liên quan đến phương pháp số, các công thức toán học. Các đặc điểm tiềm ẩn cũng như các thông số của câu hỏi thi cũng có thể khó giải thích cả bằng đồ họa và số. Do vậy mà mô hình CTT vẫn được nghiên và dùng phổ biến hiện nay. Để nắm chắc về lý thuyết khảo thí cổ điển chúng ta cần biết rõ về các khái niệm thống kê, các đặc trưng của câu hỏi trắc nghiệm,…
1.2.1. Các tham số đặc trưng của cầu hỏi trắc nghiệm và phân tích đề trắc nghiệm
1.2.1.1. Công thức tính độ khó của câu trắc nghiệm.
Đề thi được cho là dễ khi tỉ lệ học sinh làm đúng trên tổng số thí sinh dự thi là một số gần bằng 1, ngược lại, khi tỉ lệ này gần bằng 0. Từ ý tưởng đó, người ta đi đến công thức tính độ khó của câu trắc nghiệm như sau:
Độ khó của câu i = |
Tổng sổ người làm bài trắc nghiệm |
Có thể bạn quan tâm!
-

 Triển khai đánh giá kết quả học tập môn Toán lớp 12 bằng một đề tổng hợp với các câu hỏi nhị phân, đa phân và đa chiều - 1
Triển khai đánh giá kết quả học tập môn Toán lớp 12 bằng một đề tổng hợp với các câu hỏi nhị phân, đa phân và đa chiều - 1 -
 Triển khai đánh giá kết quả học tập môn Toán lớp 12 bằng một đề tổng hợp với các câu hỏi nhị phân, đa phân và đa chiều - 2
Triển khai đánh giá kết quả học tập môn Toán lớp 12 bằng một đề tổng hợp với các câu hỏi nhị phân, đa phân và đa chiều - 2 -
 So Sánh Ưu Nhược Điểm Của Đề Thi Tnkq Và Tự Luận
So Sánh Ưu Nhược Điểm Của Đề Thi Tnkq Và Tự Luận -
 Thứ Hạng Bách Phân (Percentile Ranks, Thường Viết Là Pr)
Thứ Hạng Bách Phân (Percentile Ranks, Thường Viết Là Pr) -
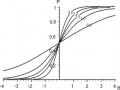 Các Đường Cong Đtch Hai Tham Số Với Các Giá Trị A Khác Nhau (B= 0)
Các Đường Cong Đtch Hai Tham Số Với Các Giá Trị A Khác Nhau (B= 0) -
 Về Trắc Nghiệm Đa Phân Và Trắc Nghiệm Đa Chiều
Về Trắc Nghiệm Đa Phân Và Trắc Nghiệm Đa Chiều
Xem toàn bộ 137 trang tài liệu này.

Khi nào độ khó của câu trắc nghiệm (TN) bằng 0? Khi nào độ khó của câu TN bằng 1? Như vậy độ khó của câu TN có thể có những giá trị từ bao nhiêu đến bao nhiêu? Độ khó càng gần 0 thì câu TN càng khó. Độ khó càng gần 1 thì câu TN càng dễ. Thực ra độ khó ở đây được hiểu là năng lực thực hiện câu hỏi của TS.
1.2.1.2. Xác định độ khó vừa phải của câu trắc nghiệm
Để có thể kết luận được rằng một câu TN là dễ, khó hay vừa sức học sinh (HS), trước hết ta phải tính độ khó của câu TN ấy rồi so sánh với độ khó vừa phải (ĐKVP) của loại câu TN ấy.
- Nếu độ khó của câu TN > ĐKVP thì ta kết luận rằng câu TN ây là dễ so với trình độ HS lớp làm trắc nghiệm.
- Nếu độ khó của câu TN < ĐKVP, thì ta kết luận rằng câu TN ấy là khó so với trình độ HS của lớp làm trắc nghiệm.
- Nếu độ khó của câu TN xấp xỉ với ĐKVP, thì ta kết luận rằng câu TN vừa sức với trình độ HS của lớp làm trắc nghiệm.
Ta có thể biểu diễn điều ấy trên một trục hoành như sau:
ĐKVP | ||
Câu TN khó | Câu TN vừa | Câu TN dễ |
Nhưng làm cách nào để tính được ĐKVP của câu TN? Công thức tính ĐKVP:
Độ khó vừa phải câu i = |
2 |
Mỗi loại câu TN có tỉ lệ % may rủi khác nhau. Loại câu đúng- sai có tỉ lệ % may rủi là 50%, loại câu có 4 lựa chọn có tỉ lệ % may rủi là 25%, loại câu có 5 lựa chọn có tỉ lệ % may rủi là 20%. Từ đó bạn hãy tính độ khó vừa phải của từng loại câu TN và nếu bạn có được độ khó của một câu TN, thì bạn có thể kết luận được rằng câu TN ấy là khó hay dễ so với trình độ HS lớp làm trắc nghiệm.
1.2.1.3. Độ phân biệt của câu hỏi
Độ phân biệt của một câu TN là một chỉ số giúp ta phân biệt được HS giỏi với HS kém. Cho nên, một bài TN gồm toàn những câu TN có độ phân cách tốt trở lên sẽ là một công cụ đo lường có tính tin cậy cao. Nhưng làm cách nào để tính được độ phân
cách của câu TN? Sau khi đã chấm và cộng tổng điểm của từng bài TN, ta có thể thực hiện các bước sau để biết được độ phân cách của một câu TN:
Bước 1: Xếp đặt các bài làm của học sinh (đã chấm, cộng điểm) theo thứ tự tổng điểm từ cao đến thấp.
Bước 2: Căn cứ trên tổng số bài TN, lấy 27% của tổng số bài làm có điểm từ bài cao nhất trở xuống xếp vào nhóm CAO và 27% tổng số bài làm có điểm từ bài thấp nhất trở lên xếp vào nhóm THẤP.
Bước 3: Tính tỉ lệ phần trăm học sinh làm đúng câu TN riêng cho từng nhóm (CAO, THẤP) bằng cách đếm số người làm đúng trong mỗi nhóm và chia cho số người của nhóm (lưu ý: số người mỗi nhóm = 27% tổng số bài làm học sinh).
Bước 4: Tính độ phân cách câu (D) theo công thức: D = Tỉ lệ % nhóm cao làm đúng câu TN - Tỉ lệ % nhóm thấp làm đúng câu TN
Lặp lại các bước 3 và 4 cho mỗi câu trắc nghiệm khác.
Chú thích: Có thể tính độ phân cách của một câu trắc nghiệm theo cách tương đương: Thực hiện bước 1 và 2 như mô tả trên. Trong bước 3 đếm số người làm đúng trong mỗi nhóm, gọi là Đúng (CAO) và Đúng (THẤP). Sau đó thay vào công thức (bước 4):
Độ phân cách câu i = | x 100% |
Sỗ người trong 1 nhom | |
Theo công thức tính độ phân cách ở phần 2, độ phân cách của một câu TN nằm trong giới hạn từ -1.00 đến +1.00. Để có thể đưa ra kết luận sau khi tính được độ phân cách của một câu TN, ta căn cứ vào quy định sau:
* D ≥ 0.40. Câu TN có độ phân cách rất tốt.
*0.30 ≤ D ≤0.39. Câu TN có độ phân cách khá tốt nhưng có thể làm cho tốt hơn.
*0.20 ≤ D ≤0.29. Câu TN có độ phân cách tạm được, cần phải điều chỉnh.
* D ≤0.19. Câu TN có độ phân cách kém cần phải loại bỏ hay phải sửa chữa nhiều.
1.2.1.4. Phân tích đề thi
a) Phân tích đáp án: Đáp án là lựa chọn được xác định là ĐÚNG NHẤT trong số các lựa chọn của phần trả lời câu MCQ (hoặc là giá trị ĐÚNG của mệnh đề trong câu Đúng - Sai). Một câu hỏi tốt nếu số người trả lời đúng ở nhóm cao hơn số người trả lời đúng ở nhóm thấp. Một câu hỏi có độ phân biệt tốt là tỉ lệ % số người ở nhóm cao chọn đáp án phải nhiều hơn số người ở nhóm thấp chọn đáp án từ 40% trở lên.
b) Phân tích mồi nhử: Khác với đáp án, mồi nhử là những lựa chọn được xác định là SAI trong phần trả lời. Chúng được tập hợp từ những câu trả lời sai trong bài làm của nhiều HS khi làm những câu hỏi dạng luận đề giáo viên đặt.
Vì vậy, một mồi nhử được gọi là tốt khi HS thuộc nhóm CAO ít chọn nó, còn HS thuộc nhóm THẤP chọn nó nhiều hơn, nghĩa là sự chênh lệch số người chọn (hoặc tỉ lệ%) của hai nhóm là lớn. Để làm rõ hơn ý vừa nói, ta hãy phân tích đáp án và mồi nhử của câu 1.
Bảng 1.3 Mô tả câu nhóm các câu hỏi trắc nghiệm
A | B* | C | D | Không trả lời | TC | |
Nhóm cao | 0 | 10 | 1 | 0 | 0 | 11 |
Nhóm thấp | 1 | 7 | 2 | 1 | 0 | 11 |
Ghi chú: B* là đáp án.
Nhân xét các lựa chọn câu 1: Quan sát các mồi nhử A, C, D ta thấy số người ở nhóm thấp chọn nhiều hơn số người ở nhóm cao nhưng mức độ chênh lệch không nhiều, cho nên ta có thể nhận định đầy là những mồi nhử chưa tốt lắm. Thêm vào đó, tỉ lệ % số người ở nhóm cao chọn đáp án B hơn tỉ lệ % số người ở nhóm thấp chọn đáp án B chỉ có 27% nên độ phân cách của câu này không cao. Ta hãy xem lại nội dung cụ thể của câu trắc nghiệm số 1 này (đáp án = B):
1.2.1.5. Một số tiêu chuẩn để chọn câu trắc nghiệm
Khi chọn câu TN được chọn (lưu vào ngân hàng đề) ta cần chú ý:
(1). Những câu TN có độ khó quá thấp hay quá cao, đồng thời có độ phân cách âm hoặc quá thấp là những câu kém cần phải xem lại để loại đi hay sửa chữa lại.