CHƯƠNG 4
HỆ THỐNG DỊCH MÁY
SỬ DỤNG DẠNG TUYỂN CÓ CHÚ GIẢI
4.1. Tổng quan về dịch máy
4.1.1.Tình hình phát triển dịch máy ở Việt Nam

Dịch máy là lĩnh vực đang rất được quan tâm của CNTT do nhu cầu chuyển ngữ một số lượng lớn văn bản trong thời gian nhanh nhất. Theo Đinh Điền [3], các hướng tiếp cận chính của dịch máy như sau:
- Tiếp cận dựa trên luật: là hướng tiếp cận của nhiều hệ dịch liên quan đến tiếng Việt. Hướng này đạt hiệu quả khi dịch trong quy mô nhỏ, tuy nhiên, công sức xây dựng các hệ chuyển đổi rất lớn.
- Tiếp cận thống kê: Khó đạt chất lượng cao đặc biệt khi bộ ngữ liệu có hạn. Khó theo dõi kết quả trung gian để can thiệp.
- Tiếp cận trên cơ sở tri thức: đòi hỏi “hiểu” toàn bộ văn bản, rất khó đạt được điều đó.
- Tiếp cận trên ví dụ: đơn giản về mặt lý thuyết, có thể cho chất lượng cao nếu văn bản đơn giản, cấu trúc lặp đi lặp lại.
- Tiếp cận dựa trên ngữ liệu: khi có bộ ngữ liệu lớn, dùng phương pháp học máy rút ra quy luật ngôn ngữ. Dễ cập nhật những thay đổi, mở rộng của ngôn ngữ.
- Ngoài ra, một phương pháp lai giữa các phương pháp kể trên là lựa chọn của nhiều hệ thống dịch.
Hiện nay ở Việt nam đã xuất hiện một số hệ thống dịch máy như:
- Hệ thống EVtran-Vetran của Nacentech do TS Lê Khánh Hùng chủ trì [10].
- Hệ thống Vietgle của Lạc Việt.
- Hệ thống dịch Việt – Anh do PGS Phan Thị Tươi chủ trì [124].
- Hệ thống dịch Anh – Việt EVTS do PGS Hồ Sĩ Đàm chủ trì [93].
- Hệ thống dịch các tài liệu tin học của Đại học Khoa học Tự nhiên – ĐHQG TP Hồ Chí Minh [3].
- Một số hệ thống dịch do các nhà nghiên cứu Việt Nam tại JAIST [115].
- Hệ thống Google Translation.
- Hệ thống dịch Anh – Việt dựa trên việc học luật chuyển đôi từ ngữ liệu song ngữ của PGS Đinh Điền [3].
Các hệ thống kể trên chủ yếu là hệ thống dịch Anh – Việt để tận dụng nguồn tài nguyên ngôn ngữ phong phú của tiếng Anh. Số lượng hệ thống dịch Việt – Anh là rất nhỏ: hệ thống VEtran, Google Translation, một số hệ thống thử nghiệm của Đại học Bách khoa thành phố Hồ Chí Minh, JAIST…Trong số đó, hai hệ thống được phổ biến rộng rãi là hệ thống dịch của Google theo cách tiếp cận thống kê, hệ thống VEtran theo cách tiếp cận dựa trên luật.
Sự khác biệt giữa tiếng Việt và tiếng Anh là sự khác biệt giữa một ngôn ngữ phương đông và một ngôn ngữ phương Tây, tập trung ở một số lĩnh vực chính: hình thái, trật tự từ, quan hệ phụ thuộc không liền kề (long distance dependency). Văn phạm liên kết, do tính từ vựng hóa hoàn toàn, có khả năng thể hiện tốt sự phụ thuộc về hình thái (theo Schneider [109]). Trật tự từ cũng có thể được phát hiện từ liên kết giữa các từ. Một số quan hệ giữa các từ không liền kề có thể được biểu diễn bởi các liên kết, một số ít khác không thể biểu diễn do vi phạm điều kiện về tính phẳng.
Có thể bạn quan tâm!
-

 Giải Thuật Kiểu Viterbi Để Tìm Phân Tích Tốt Nhất
Giải Thuật Kiểu Viterbi Để Tìm Phân Tích Tốt Nhất -
 Mô hình văn phạm liên kết tiếng Việt - 21
Mô hình văn phạm liên kết tiếng Việt - 21 -
 Mô hình văn phạm liên kết tiếng Việt - 22
Mô hình văn phạm liên kết tiếng Việt - 22 -
 Mô hình văn phạm liên kết tiếng Việt - 24
Mô hình văn phạm liên kết tiếng Việt - 24 -
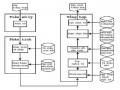 Hệ Thống Dịch Máy Sử Dụng Dạng Tuyển Có Chú Giải
Hệ Thống Dịch Máy Sử Dụng Dạng Tuyển Có Chú Giải -
 Mô hình văn phạm liên kết tiếng Việt - 26
Mô hình văn phạm liên kết tiếng Việt - 26
Xem toàn bộ 305 trang tài liệu này.
Sau khi xây dựng mô hình văn phạm liên kết tiếng Việt, luận án thử nghiệm mô hình dịch máy như một minh chứng về khả năng biểu diễn các đặc trưng tiếng Việt của mô hình.
Mô hình văn phạm liên kết đã được ứng dụng để xây dựng các hệ thống dịch từ tiếng Anh sang các ngôn ngữ châu Âu như: tiếng Đức [135], Nga [134], Thổ Nhĩ Kỳ [133] hay Sanskrit – một ngôn ngữ của Ấn độ [71] dựa trên việc chuyển đổi tương ứng các liên kết giữa hai ngôn ngữ (riêng hệ thống dịch Anh-Nga có kết hợp thống kê). Các hệ thống đó đã đáp ứng khá tốt những biến đổi về hình thái như thì, thể, giống, số, cách. Tuy nhiên, khi ngôn ngữ nguồn và ngôn ngữ đích có sự khác biệt lớn về cú pháp và từ pháp, khó có thể đưa ra những bản dịch có chất lượng. Đó cũng là lý do các hệ thống nói trên chỉ dừng ở mức thử nghiệm cho một tập câu nhỏ. Một hệ thống dịch khác dựa trên văn phạm liên kết là hệ thống dịch của đại học Petronas, Malaysia [29], [30], [129] dịch từ tiếng Anh sang tiếng Indonesia. Hệ thống cho phép tra nghĩa từ, biến đổi cú pháp thông qua dạng tuyển có chú giải (Annotated Disjunct – ADJ). Hệ thống đã cho kết quả dịch khá tốt sang tiếng Indonesia – một ngôn ngữ Đông Nam Á cũng chưa có được nguồn tài nguyên phong phú để xử lý tự động như tiếng Việt.
Hệ thống dịch của luận án đã chọn công cụ ADJ. Mỗi ADJ thực chất chứa: một từ của ngôn ngữ nguồn, dạng tuyển của nó và nghĩa tương ứng của từ trong ngôn ngữ đích khi đi với dạng tuyển đã cho. Từ điển ADJ cho phép xác định nghĩa chính xác của từ theo cấu trúc liên kết trong câu.
Xây dựng bộ luật chuyển đổi cú pháp là công việc bắt buộc cho mỗi hệ thống dịch dựa trên luật. Với hai vấn đề chính được nhóm Nguyễn Phương Thái [115] đề cập là khác biệt về hình thái và trật tự từ, mô hình văn phạm liên kết tỏ ra rất có ưu thế để biến đổi hình thái từ, trong khi biến đổi trật tự từ cũng khá dễ dàng do cấu trúc của phân tích liên kết khá đơn giản.
4.1.2. Phương pháp đánh giá chất lượng dịch máy
Đánh giá chất lượng dịch máy là vấn đề khó. Ngay cả khi bản dịch được con người đánh giá cũng còn có nhiều ý kiến khác nhau về chất lượng. Đối với dịch máy tự động, cần đưa ra những tiêu chí để lượng hóa độ chính xác của bản dịch. Hai tiêu chí sau đây được hầu hết các phương pháp đánh giá tự động quan tâm:
- Độ tương ứng (adequacy): Lượng thông tin của bản dịch tham chiếu có trong bản dịch được đánh giá.
- Độ trôi chảy (fluency): Bản dịch có thể hiện đúng những cấu trúc thường dùng trong tự nhiên của ngôn ngứ đích không.
Các hướng tiếp cận chính dể tự động đánh giá chất lượng bản dịch, đó là: dựa trên độ chính xác (BLEU, NIST) [51], dựa trên độ phủ (METEOR), dựa trên đánh giá khoảng cách Levenshtein, dựa trên tỷ lệ lỗi…
Phương pháp BLEU (BiLingual Evaluation Understudy) do Papineni [100] đề xuất. Đây là phương pháp sử dụng trung bình có trọng số của các phép so sánh cụm từ có chiều dài thay đổi của bản dịch đang xét với bản dịch tham khảo, kết hợp với việc đánh giá độ dài bản dịch. BLEU được sử dụng phổ biến nhất để đánh giá chất lượng dịch máy ở trong và ngoài nước. Luận án đã chọn độ đo BLEU để đánh giá chất lượng bản dịch. Điểm BLEU được tính theo công thức:
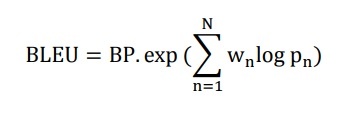
hay theo thang loga:
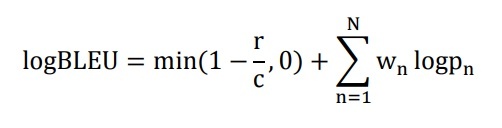
Trong đó, BP là điểm phạt dịch ngắn (brevity penalty) được tính theo công thức:
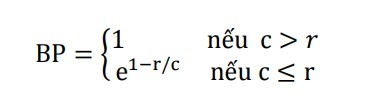
c là độ dài bản dịch đang xét, r là độ dài bản dịch tham chiếu.
pn là tỷ lệ n-gram phù hợp giữa bản dịch đang xét và bản dịch tham chiếu, được tính theo công thức sau:
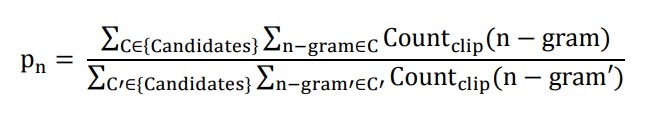
Ở đây n-gram liên quan đến bản dịch đang xét, còn n-gram’ liên quan đến bản dịch tham chiếu.