Việc quản lý các ràng buộc toàn vẹn trong CSDL phân tán chưa được nghiên cứu hoàn toàn, các kỹ thuật cần thiết cho một môi trường phân tán không khác nhiều so với các kỹ thuật trong một hệ thống tập trung, đặc biệt khi CSDL phân tán cung cấp tính trong suốt phân mảnh (và rất vô lý để cố gắng phát triển các ràng buộc toàn vẹn ở mức trong suốt thấp hơn). Vấn đề chính trong việc áp dụng kiểm tra ràng buộc cho các CSDL phân tán là toàn bộ hiệu quả của hệ thống. Bởi vì việc kiểm tra ràng buộc có thể làm tăng yêu cầu truy xuất các nơi từ xa (như trong ví dụ trên) nên cũng cần xét việc kiểm tra ràng buộc trong việc thiết kế phân tán của CSDL.
Chương 3
THIẾT KẾ CƠ SỞ DỮ LIỆU PHÂN TÁN
Thiết kế CSDL phân tán là một việc rất khó, bởi vì nhiều vấn đề về tổ chức và về kỹ thuật, mà chúng đóng vai trò chủ yếu trong việc thiết kế CSDL đơn nơi (single - site system), trở nên khó hơn trong mọt hệ thống đa nơi (multiple - site system).
Về quan điểm kỹ thuật, các vấn đề mới phát sinh, chẳng hạn như việc kết nối giữa các nơi nhờ vào một mạng máy tính và phân tán tối ưu về dữ liệu và các ứng dụng cho các nơi để thoả màn các yêu cầu của ứng dụng và để tối ưu hoá hiệu quả.
Về quan điểm tổ chức, vấn đề phi tập trung hoá là chủ yếu, bởi vì các hệ thống phân tán thay thế cho các hệ thống tập trung, lớn và trong trường hợp này, việc phân tán một ứng dụng có ảnh hưởng lớn đến tổ chức.
Mặc dù các kinh nghiệm thiết kế hệ thống phân tán còn hạn chế, vấn đề này đã được nghiên cứu một cách bao quát, phần lớn xuất phát từ quan điểm kỹ thuật, và nhiều đóng góp có thể được tìm thấy trong các tài liệu. Vấn đề về mặt toán học trong việc phân tán dữ liệu một cách tối ưu trên một mạng máy tính đã được phân tích nhiều trong ngữ cảnh của hệ thống tập tin phân tán và trong các CSDL phân tán. Các kết quả chủ yếu của phân tán này bao gồm hai phần:
Có thể bạn quan tâm!
-

 Truy Xuất Csdl Ql Kinh Doanh Khi Ddbms Với Trong Suốt Ánh Xạ Cục Bộ
Truy Xuất Csdl Ql Kinh Doanh Khi Ddbms Với Trong Suốt Ánh Xạ Cục Bộ -
 Truy Xuất Csdl Sau Khi Nhập Vào Tất Cả Các Giá Trị
Truy Xuất Csdl Sau Khi Nhập Vào Tất Cả Các Giá Trị -
 Truy Xuất Csdl Trước Khi Nhập Vào Các Giá Trị
Truy Xuất Csdl Trước Khi Nhập Vào Các Giá Trị -
 Thiết Kế Phân Mảnh Cơ Sở Dữ Liệu
Thiết Kế Phân Mảnh Cơ Sở Dữ Liệu -
 Cơ sơ dữ liệu phân tán - 17
Cơ sơ dữ liệu phân tán - 17 -
 Thiết Kế Phân Mảnh Ngang Dẫn Xuất
Thiết Kế Phân Mảnh Ngang Dẫn Xuất
Xem toàn bộ 312 trang tài liệu này.
- Nhiều tiêu chuẩn thiết kế đã được thiết lập về vấn đề dữ liệu có thể được phân tán một cách thuận lợi như thế nào.
- Cơ sở toán học dùng để trợ giúp thiết kế sẽ giúp cho người thiết kế trong việc xác định phân tán dữ liệu.
Chương này sẽ trình bày một số vấn đề sau:
- Các bước để thiết kế các CSDL phân tán bằng cách nhấn mạnh cái gì nên được thiết kế; các mục tiêu của thiết kế phân tán dữ liệu và giới thiệu cách tiếp cận từ trên xuống (top - down approach) và cách tiếp cận từ dưới lên (bottom - up approach). Trong đó sẽ tập trung vào cách tiếp cận từ trên xuống.
- Phương pháp thiết kế các mảnh ngang và các mảnh dọc; nêu ra các tiêu chuẩn có tính kinh nghiệm cho phép xác định chúng; khái niệm phép kết nối phân tán giữa các quan hệ được phân mảnh, và cho thấy việc chọn các tiêu chuẩn để phân mảnh có thể rất có ích cho việc đơn giản các phép kết nối phân tán.
- Phương pháp định vị các mảnh, vấn đề này tương ứng với việc xác định các ánh xạ giữa các mảnh và các hình ảnh vật lý: Các nguyên lý và các khái niệm trong định vị mảnh; các công thức đơn giản để đánh giá các chi phí và lợi ích của các định vị.
- Vấn đề kiểm soát dữ liệu ngữ nghĩa: Quản lý khung nhìn, an toàn dữ liệụ, kiểm soát tính toàn vẹn ngữ nghĩa.
3.1. Vấn đề thiết kế cơ sở dữ liệu phân tán
3.1.1. Các bước thiết kế phân tán dữ liệu
1) Các bước thiết kế một CSDL tập trung bao gồm: Bước 1: Thiết kế lược đồ khái niệm
Mô tả tất cả các CSDL được sử dụng bởi các ứng dụng CSDL Bước 2: Thiết kế cơ sở dữ liệu vật lý
- Ánh xạ lược đồ khái niệm vào các vùng lưu trữ
- Xác định các phương pháp truy vấn thích hợp
2) Các bước thiết kế một CSDL phân tán bao gồm:
Thuật ngữ thiết kế cơ sở dữ liệu phân tán có một ý nghĩa rất rộng và không chính xác. Hiện nay chưa có một kỹ thuật cụ thể nào nói một cách chi tiết việc thiết kế CSDL phân tán. Tuy nhiên một cách tổng quát chúng ta có thể thiết kế CSDL phân tán theo sơ đồ được chỉ ra trong hình 3.1:

Hình 3.1. Sơ đồ thiết kế tổng CSDL phân tán
Bước 1: Thiết kế lược đồ toàn cục
- Thiết kế các quan hệ toàn cục
- Mô tả toàn bộ dữ liệu sẽ được dùng trong hệ thống Bước 2: Thiết kế phân mảnh:
Phân chia quan hệ toàn cục thành các mảnh ngang, dọc hoặc hỗn hợp Bước 3: Thiết kế định vị mảnh
- Xác định các mảnh được ánh xạ vào các hình ảnh vật lý như thế nào
- Tạo các hình ảnh vật lý tại các trạm
- Xác định việc nhân bản các mảnh
- Các đoạn dữ liệu được đưa vào các vị trí lưu trữ thích hợp với yêu cầu hoạt động thực tế của hệ thống
Bước 4: Thiết kế các CSDL vật lý cục bộ tại mỗi nơi Thiết kế cơ sở dữ liệu vật lý cho các quan hệ tại các trạm
Sự khác biệt giữa hai giai đoạn thiết kế phân mảnh và thiết kế định vị mảnh là sự hợp lý về mặt khái niệm, bởi vì vấn đề đầu tiên giải quyết “các tiêu chuẩn luận lý” là cơ sở của việc phân mảnh một quan hệ toàn cục. Trong khi đó, vấn đề thứ hai giải quyết “sự sắp đặt vật lý” của dữ liệu đặt tại nhiều nơi khác nhau. Tuy nhiên, sự khác biệt này phải được nêu ra một cách thận trọng. Nói chung, không thể xác định sự phân mảnh và sự định vị tối ưu bằng cách giải quyết hai vấn đề này một cách độc lập, bởi vì chúng có liên quan với nhau.
Mặc dù thiết kế các chương trình ứng dụng được thực hiện sau việc thiết kế các lược đồ, nhưng các hiểu biết về các yêu cầu của ứng dụng ảnh hưởng đến thiết kế các lược đồ, bởi vì các lược đồ phải có khả năng hỗ trợ ứng dụng một cách hiệu quả. Do đó, trong thiết kế CSDL phân tán, cần phải hiểu biết thật chính xác các yêu cầu của ứng dụng. Rò ràng, sự hiểu biết này chỉ cần thiết đối với các ứng dụng “quan trọng” hơn, nghĩa là các ứng dụng được thực hiện một cách thường xuyên hoặc các ứng dụng cần phải được chạy một cách có hiệu quả.
Trong các yêu cầu của ứng dụng, chúng ta quan tâm đến:
- Nơi chạy ứng dụng (còn được gọi là nơi gốc của ứng dụng).
- Tần suất chạy ứng dụng (nghĩa là số lần chạy trong một đơn vị thời gian); trong trường hợp tổng quát mà các ứng dụng có thể được chạy tại nhiều nơi, chúng ta cần phải biết tần suất chạy của mỗi ứng dụng tại mỗi nơi.
- Số lượng, loại và sự phân tán của các truy xuất trong mỗi ứng dụng đến mỗi đối tượng dữ liệu cần thiết.
Xác định rò các đặc điểm này là điều quan trọng. Hơn nữa, cần phải xem xét các dữ liệu này được cho trước đối với các quan hệ toàn cục và phải được biến thành các điều kiện áp dụng cho các mảnh; bởi vì kết quả của thiết kế là tạo ra sự phân mảnh, các dữ liệu này phải được biết đến đối với tất cả các cách phân mảnh khác nhau mà chúng được xét trong khi thiết kế.
3.1.2. Các mục tiêu của thiết kế phân tán dữ liệu
Trong thiết kế phân tán dữ liệu, chúng ta nên quan tâm đến các mục tiêu sau đây:
1) Tính cục bộ xử lý
Việc phân tán dữ liệu để làm cực đại hoá tính cục bộ xử lý (processing locality) tương ứng với nguyên tắc cơ bản là đặt dữ liệu càng gần các ứng dụng sử dụng các dữ liệu này càng tốt. Trong chương 1, chúng ta đã chỉ ra rằng đạt được tính cục bộ xử lý là một trong các mục tiêu chủ yếu của CSDL phân tán.
Đối với phân mảnh, vấn đề quan trọng là đơn vị phân tán (unit of distribution) thích hợp. Một quan hệ không là một đơn vị phân tán thích hợp vì những lý do sau:
- Các khung hình ứng dụng thông thường là các tập con của các quan hệ. Do đó, tính cục bộ xử lý của các ứng dụng không được xác định trên các quan hệ mà trên các
tập con của các quan hệ này. Vì thế, chỉ có thể xem các tập con của các quan hệ này là các đơn vị phân tán.
- Nếu các ứng dụng có các khung nhìn được định nghĩa trên một quan hệ cho trước đặt tại các nơi khác nhau, thì có thể có hai cách khác nhau để xem lại toàn bộ quan hệ là một đơn vị phân tán. Quan hệ không được nhân bản và được lưu trữ chỉ tại một nơi, hoặc quan hệ được nhân bản tại tất cả hoặc một số nơi có chạy các ứng dụng. Cách thứ nhất dẫn đến một số lượng lớn không cần thiết các truy xuất dữ liệu từ xa. Mặt khác, cách thứ hai có sự nhân bản không cần thiết và gây ra các vấn đề không mong muốn trong việc thực hiện cập nhật khi vùng lưu trữ bị giới hạn.
- Cách đơn giản nhất để xác định tính cục bộ xử lý là xét hai loại tham chiếu dữ liệu: các tham chiếu cục bộ (local reference) và các tham chiếu từ xa (remote reference). Rò ràng, khi biết các nơi gốc của các ứng dụng, tính cục bộ (locality) và tính từ xa (remoteness) của các tham chiếu chỉ phụ thuộc vào sự phân tán dữ liệu.
Thiết kế phân tán dữ liệu để cực đại hoá tính cục bộ xử lý (tức là làm cực tiểu hoá các tham chiếu từ xa) có thể được thực hiện bằng cách xét các tham chiếu cục bộ và các tham chiếu từ xa tương ứng với mỗi cách phân mảnh dự kiến (candidate fragmentation) và chọn giải pháp tốt nhất giữa các phân mảnh này.
Mở rộng tiêu chuẩn tối ưu hoá đơn giản này cần được quan tâm đến khi một ứng dụng có tính cục bộ hoàn toàn (complete locality). Chúng ta sử dụng thuật ngữ này để nói đến các ứng dụng mà chúng có thể được thực hiện hoàn toàn tại nơi gốc của chúng. Ưu điểm của tính cục bộ hoàn toàn không chỉ là giảm bớt các truy xuất từ xa mà còn làm tăng tính đơn giản trong việc kiểm soát việc thực hiện các ứng dụng.
2) Tính sẵn sàng và độ tin cậy của dữ liệu phân tán
Trong chương 1, chúng ta đã thấy tính sẵn sàng và độ tin cậy được xem là ưu điểm của các hệ thống phân tán đối với các hệ thống không phân tán. Mức độ sẵn sàng cao đối với các ứng dụng chỉ đọc sẽ đạt được bằng cách lưu trữ nhiều bản nhân của cùng một thông tin, hệ thống phải có khả năng chuyển đổi qua một bản khác khi một bản được truy xuất dưới các điều kiện bình thường trở thành không hiệu lực.
Độ tin cậy cũng đạt được bằng cách lưu trữ nhiều bản nhân của cùng một thông tin, bởi vì có thể được phục hồi khi máy tính bị ngừng hoặc có hư hỏng vật lý của một trong các bản nhân bằng cách sử dụng các bản nhân khác vẫn còn hiệu lực. Vì hư hỏng vật lý có thể xảy ra bởi các biến cố (chẳng hạn như lửa, động đất, phá hoại…), do đó việc lưu trữ các bản nhân tại các vị trí địa lý phân tán là thích hợp.
3) Điều phối tải làm việc
Điều phối tải làm việc tại các nơi là một đặc điểm quan trọng của các hệ thống máy tính phân tán. Thực hiện điều phối tải làm việc để tận dụng ưu điểm của các nguồn lực khác nhau hoặc tính năng của các máy tính tại mỗi nơi, và cực đại hoá mức độ thực
hiện song song các ứng dụng. Vì điều phối tải làm việc có thể ảnh hưởng ngược lại với tính cục bộ xử lý, do đó cần phải cân nhắc giữa chúng trong thiết kế phân tán dữ liệu. Phân rã một quan hệ thành các mảnh, mỗi mảnh được xử lý như là một đơn vị, cho phép nhiều giao dịch được thực hiện đồng thời. Hơn nữa, phân mảnh các quan hệ dẫn đến việc thực hiện đồng thời một truy vấn đơn bằng cách chia truy vấn này thành các truy vấn con để thực hiện trên các mảnh, đặc tính này được gọi là tính đồng thời nội truy vấn (intraquery concurrency). Do đó, sự phân mảnh làm tăng mức độ đồng thời và từ đó làm tăng thông lượng của hệ thống (system throughput).
4) Các chi phí lưu trữ và khả năng lưu trữ có sẵn
Sự phân tán CSDL nên phản ánh chi phí và khả năng lưu trữ tại các nơi khác nhau. Có thể có các nơi chuyên dụng trong mạng để lưu trữ dữ liệu, hoặc ngược lại có các nơi không hỗ trợ vùng lưu trữ lớn. Chi phí lưu trữ dữ liệu là không thích đáng so với các chi phí CPU, nhập/xuất và truyền thống của các ứng dụng, nhưng phải xét giới hạn lưu trữ có sẵn tại mỗi nơi.
Sử dụng cùng lúc tất cả các tiêu chuẩn ở trên là điều vô cùng khó khăn, bởi vì điều này dẫn đến các mô hình tối ưu hoá phức tạp. Có thể xem một số đặc điểm ở trên như là các ràng buộc, hơn là các mục tiêu (chẳng hạn, có thể nêu ra các ràng buộc về số lượng tải làm việc tối đa hoặc vùng lưu trữ tối đa có sẵn ở mỗi nơi). Mặt khác, có thể xét tiêu chuẩn quan trọng nhất trong thiết kế ban đầu và đưa ra các tiêu chuẩn khác trong hậu tối ưu hoá.
Lưu ý rằng, sự phân mảnh vẫn có các nhược điểm. Nếu các ứng dụng có các yêu cầu mâu thuẫn nhau không cho phép phân rã các quan hệ thành các mảnh riêng biệt nhau, các ứng dụng này có các khung nhìn được định nghĩa trên nhiều mảnh, có thể làm giảm hiệu quả. Chẳng hạn, cần phải lấy dữ liệu từ hai mảnh và sau đó thực hiện phép hợp hoặc phép kết nối của chúng mà điều này làm tốn chi phí. Tránh điều này là một vấn đề cơ bản của phân nhánh. Vấn đề thứ hai liên quan đến việc kiểm tra dữ liệu ngữ nghĩa (semantic data control), đặc biệt là việc kiểm tra tính toàn vẹn (integrity checking). Do kết quả của sự phân nhánh, các thuộc tính tham gia vào một phụ thuộc có thể bị phân rã trong các mảnh khác nhau và có thể được định vị tại các nơi khác nhau. Trong trường hợp này, ngay cả công việc đơn giản như kiểm tra các phụ thuộc sẽ dẫn đến sự kết nối dữ liệu tại nhiều nơi.
Sau đây, chúng ta sẽ sử dụng cách tiếp cận đơn giản để cực đại hoá tính cục bộ xử lý, mục tiêu này là thích đáng để đưa ra các tiêu chuẩn thiết kế thường dùng và thực tế.
3.1.3. Chiến lược thiết kế phân tán dữ liệu
Có hai cách tiếp cận khác nhau để thiết kế phân tán dữ liệu: cách tiếp cận từ trên xuống và cách tiếp cận từ dưới lên.
1) Chiến lược thiết kế từ trên xuống (Top-down)
Trong cách tiếp cận từ trên xuống (Top - down approach), chúng ta bắt đầu bằng cách thiết kế lược đồ toàn cục, thiết kế phân mảnh của CSDL, định vị các mảnh tại các nơi, tạo ra các hình ảnh vật lý. Kết thúc cách tiếp cận này là việc thực hiện thiết kế dữ liệu vật lý đặt tại mỗi mơi.
Quá trình thiết kế từ trên xuống được chỉ ra trong hình 3.2.
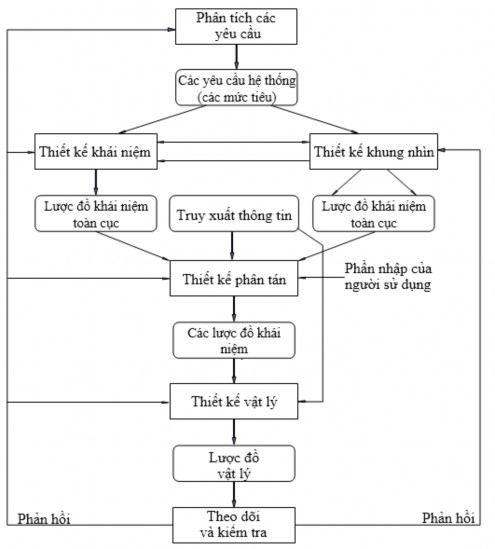
Hình 3.2. Chiến lược thiết kế từ trên xuống
a) Giai đoạn phân tích yêu cầu
- Đầu ra: Các yêu cầu hệ thống bao gồm
+ Môi trường của hệ thống
+ Các nhu cầu về dữ liệu
+ Các nhu cầu xử lý của người sử dụng CSDL
- Các mục tiêu của một DBMS mà thống cuối cùng sẽ thoả mãn như: hiệu suất, độ tin cậy, tính sẵn sàng, tính kinh tế, tính mở rộng (tính linh hoạt).
- Các bước thực hiện:
+ Xác định các yêu cầu của hệ thống
+ Xác định các mục tiêu
b) Giai đoạn thiết kế khung nhìn (view design):
- Đầu vào:
+ Các yêu cầu của hệ thống
+ Các mục tiêu của một DBMS
- Đầu ra:
+ Thông tin truy xuất
+ Các định nghĩa lược đồ ngoài (định nghĩa các giao diện cho những người sử dụng cuối cùng)
- Các bước thực hiện:
+ Xác định các thông tin truy xuất
+ Định nghĩa các giao diện cho những người sử dụng cuối cùng
c) Giai đoạn thiết kế khái niệm (conceptual design):
- Đầu vào:
+ Các yêu cầu của hệ thống
+ Các mục tiêu của một DBMS
- Đầu ra: Lược đồ khái niệm toàn cục (GCS: Global- Conceptual-Schema)
- Các bước thực hiện:
+ Xem xét tổng thể cơ quan, tổ chức đang xét
+ Phân tích thực thể (entity analysis): Xác định các thực thể, xác định các thuộc tính của các tập thực thể, xác định các mối liên hệ giữa các tập thực thể.
+ Phân tích chức năng (functional analysis ): Xác định các chức năng cơ bản trong hệ thống cần mô hình hóa
- Mối quan hệ giữa thiết kế khái niệm và thiết kế khung nhìn.
+ Thiết kế khái niệm là sự tích hợp các khung hình của người sử dụng
+ Tích hợp khung nhìn nên được sử dụng để bảo đảm rằng các yêu cầu thực thể và mối liên hệ cho tất cả các khung nhìn đã được đưa vào trong lược đồ khái niệm
+ Người sử dụng cần phải chỉ rò các thực thể dữ liệu, phải xác định các ứng dụng sẽ chạy trên CSDL, phải xác định thông tin thống kê về các ứng dụng như tần suất ứng dụng, khối lượng của các thông tin khác nhau, các số liệu khác.
d) Giai đoạn thiết kế phân tán (distribution design):
- Đầu vào:
+ Lược đồ khái niệm toàn cục
+ Thông tin truy xuất
+ Các lược đồ ngoài
+ Các yêu cầu từ người dùng
- Đầu ra: Lược đồ khái niệm cục bộ (LCS: Local-Conceptual-Schema)