nhà nhân viên (#FOUND) thì ứng dụng tiếp tục tìm tên dự án, vị trí của dự án trong mảnh DA1 đặt tại nơi 1; nếu không tìm thấy mã nhân viên tại nơi 1 thì cùng những thao tác này được thực hiện trên mảnh HS2 tại nơi 2 hoặc 3 và trên mảnh NV2 tại nơi 2 hoặc 3.
Ví dụ 2.19: Xét hệ thống quản lý kinh doanh trong ví dụ 2.13
Hình 2.8 cho thấy cách thức mà ứng dụng truy xuất CSDL quản lý kinh doanh khi DDBMS cung cấp trong suốt ánh xạ cục bộ.
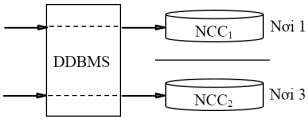
Hình 2.8. Truy xuất CSDL QL kinh doanh khi DDBMS với trong suốt ánh xạ cục bộ
a) Với ứng dụng 1:
Read(terminal, $MANCC); Select TENNCC Into $TENNCC From NCC1 at site 1
Where MANCC = $ MANCC;
If not #FOUND then
Select TENNCC Into $TENNCC From NCC2 at site 2
Where MANCC = $ MANCC;
If #FOUND then
Write (terminal, $TENNCC);
Else write (terminal, “Không tìm thấy”);
Chương trình này nhập một mã nhà cung cấp và tìm tên nhà cung cấp có mã được nhập trong mảnh NCC1 ở nơi 1. Nếu không tìm thấy nhân viên tại nơi 1 thì cùng những thao tác này được thực hiện trên mảnh NCC2 tại nơi 2.
b) Với ứng dụng 2:
Read(terminal, $DC);
Select DC, COUNT(MANCC) Into $SONCC
From NCC1 at site 1 Where DC = $DC; Group by DC
If not #FOUND then
Select DC, COUNT(MANCC) Into $SONCC
From NCC2 at site 2 Where DC = $DC; Group by DC
If #FOUND then
Write (terminal, $SONCC);
Else write (terminal, “Không tìm thấy”);
Chương trình này nhập một địa chỉ và tìm số nhân viên có địa chỉ được nhập trong mảnh NCC1 ở nơi 1. Nếu không tìm thấy địa chỉ tại nơi 1 thì cùng những thao tác này được thực hiện trên mảnh NCC2 tại nơi 2.
c) Với ứng dụng 3:
Read(terminal, $MAMH); Select MANCC Into $MANCC From KD1 at site 3
Where MAMH = $MAMH
If #FOUND then
Send $MANCC from site 3 to site 1; Select TENNCC Into $TENNCC From NCC2
Where MANCC = $MANCC;
If NOT #FOUND then Begin
Select MANCC Into $MANCC From KD1 at site 4
Where MAMH = $MAMH
If #FOUND then
Send $MANCC from site 4 to site 2; Select TENNCC Into $TENNCC From NCC2
Where MANCC = $MANCC;
End
If #FOUND then
Write (terminal, $TENNCC);
Else write (terminal, “Không tìm thấy”);
Chương trình này nhập một mã nhà cung cấp và tìm nhà cung cấp của mặt hàng này trong mảnh KD1 ở nơi 3. Nếu tìm thấy mã nhà cung cấp (#FOUND) thì ứng dụng gửi mã nhà cung cấp đến nơi 1 (lệnh send) để tìm tên nhà cung cấp trong mảnh NCC1
đặt tại nơi 1; nếu không tìm thấy mã nhà cung cấp tại nơi 3 thì cùng những thao tác này được thực hiện trên mảnh KD2 tại nơi 4 và trên mảnh NCC2 tại nơi 2.
Lưu ý rằng các truy vấn SQL đã được sử dụng trong ứng dụng của ví dụ trước, để
thực hiện một phép kết nối giữa hai mảnh có thể được đặt tại các nơi khác nhau, đã được tách ra trong ví dụ này. Trên thực tế, trong ví dụ này, chúng ta giả sử DDBMS yêu cầu mỗi thao tác cơ bản được thực hiện chỉ tại một nơi, và do đó nó không thể thực hiện một phép kết nối giữa hai mảnh đặt tại các nơi khác nhau; điều này là một giả sử có lý đối với DDBMS không cung cấp tính trong suốt vị trí.
Các lệnh send thực sự không cần thiết; nếu các thao tác cơ bản send không được định nghĩa tường minh thì chúng ta giả sử các biến $MANCC được tạo ra bởi truy vấn thứ nhất, được trả về ngầm định cho ứng dụng và sau đó nó được gửi cho các nơi thực hiện truy vấn thứ hai. Lệnh send cho phép liên lạc trực tiếp giữa các nơi mà hai truy vấn được thực hiện. Điều này có thể rất quan trọng nếu kết quả trung gian (trong trường hợp này là $MANCC) không là biến đơn mà là cả tập tin.
Ứng dụng sau cùng này rò ràng phụ thuộc nhiều vào nội dung của các lược đồ; mọi thay đổi trong phân mảnh dữ liệu và định vị dữ liệu đều dẫn đến sự thay đổi của ứng dụng.
4) Không trong suốt (no transparency)
Tính trong suốt ánh xạ cục bộ là đặc biệt quan trọng nhưng khó có được trong một hệ thống không đồng nhất. Do đó, các ứng dụng có thể được viết như thế nào trên CSDL phân tán với SQL Server tại nơi 1 và Oracle tại nơi 3 nếu DDBMS không hỗ trợ bất kỳ tính trong suốt phân tán nào. Người lập trình ứng dụng phải viết các chương trình SQL Server và Oracle để thực hiện các chức năng cần thiết và cài đặt các chương trình phụ trợ này tại các nơi mà chúng được yêu cầu; ứng dụng gửi một yêu cầu chạy các chương trình phụ trợ từ xa này thay vì các lệnh SQL.
Giả sử DDBMS chấp nhận một thao tác cơ bản execute để xác định chương trình phải được chạy tại nơi nào và các tham số nào được truyền đi. Chi tiết của các chương trình SQL Server và Oracle không được nêu ra bởi vì điều này đòi hỏi phải định nghĩa các lược đồ ánh xạ cục bộ và đưa vào nhiều chi tiết không cần thiết của các hệ thống SQL Server và Oracle.
Dùng tham số $FOUND để thay cho biến #FOUND mà nó là mã điều kiện. Trong trường hợp này, thay đổi này là do DDBMS không đủ thông tin về ngữ nghĩa của các thao tác cơ bản để trả về kiểu của mã điều kiện này; các chương trình ứng dụng phụ trợ sẽ phải xác định các điều kiện này và trả chúng về một cách tường minh. Một lần nữa, không phụ thuộc vào các chi tiết của ngôn ngữ lập trình. Điều này cho thấy một ưu điểm tiêu biểu khác của tính trong suốt phân tán: DDBMS có thể xác định và quản lý nhiều điều kiện hơn một cách độc lập ở các mức trong suốt cao hơn.
Ví dụ 2.20: Xét hệ thống quản lý kinh doanh trong ví dụ 2.13
Hình 2.9 cho thấy cách thức mà ứng dụng truy xuất CSDL quản lý kinh doanh với ứng dụng khi DDBMS phân tán không đồng nhất không có trong suốt.
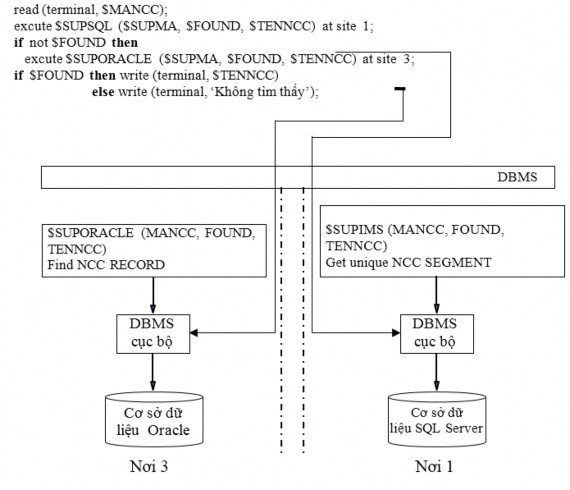
Hình 2.9. Một số ứng dụng trên một CSDL phân tán không đồng nhất không có trong suốt
Khi đó, DDBMS có một công việc không hoàn thành hiển nhiên, đó là chạy các chương trình từ xa và truyền các tham số giữa các chương trình chạy trên các DBMS cục bộ khác nhau. Lưu ý rằng DDBMS có thể rất có ích trong việc phát triển các ứng dụng CSDL phân tán, ngay cả khi nó không cung cấp bất kỳ một mức trong suốt nào.
2.3. Tính trong suốt phân mảnh dùng cho các ứng dụng cập nhật
2.3.1. Cây cập nhật
Trong phần trước chúng ta chỉ xét các ứng dụng thực hiện việc lấy dữ liệu từ CSDL. Trong phần này chúng ta xét các ứng dụng thực hiện việc cập nhật CSDL phân tán. Ở đây, vấn đề cập nhật chỉ được xét trên quan điểm của tính trong suốt phân tán đối với người lập trình ứng dụng, trong khi đó chúng ta không đề cập đến các vấn đề trong việc bảo đảm tính nguyên tố của các giao dịch cập nhật.
Trong các ứng dụng cập nhật, ta cũng xét tính:
- Trong suốt phân mảnh
- Trong suốt vị trí
- Trong suốt ánh xạ cục bộ
Tuy nhiên, một cập nhật phải được thực hiện trên tất cả các bản sao của một mục dữ liệu (data item), trong khi đó việc lấy dữ liệu có thể được thực hiện trên bất kỳ một bản sao nào (read- one write – all). Điều này có nghĩa là một DDBMS không cung cấp tính trong suốt vị trí và tính trong suốt nhân bản thì người lập trình ứng dụng phải có nhiệm vụ thực hiện tất cả các cập nhật cần thiết. Do đó, tính trong suốt vị trí và tính trong suốt nhân bản là quan trọng hơn đối với các ứng dụng cập nhật so với các ứng dụng chỉ đọc.
Trong việc cung cấp tính trong suốt phân tán cho ứng dụng cập nhật, có một vấn đề khác phức tạp hơn so với việc thực hiện các cập nhật trên tất cả các bản sao của một mục dữ liệu.
Ví dụ 2.21. Xét ví dụ 2.12, nếu thuộc tính VT của một dự án bị thay đổi. Rò ràng, một bộ (tuple) của dự án này phải di chuyển từ một mảnh này qua một mảnh khác. Hơn nữa, trong CSDL của ví dụ, các bộ của quan hệ HS có mã dự án này cũng phải thay đổi mảnh, bởi vì quan hệ HS được phân mảnh dẫn xuất theo quan hệ DA.
Việc thay đổi giá trị của một thuộc tính được sử dụng trong định nghĩa lược đồ phân mảnh (được gọi là thuộc tính phân mảnh) có thể có nhiều ảnh hưởng tương đối phức tạp và các ảnh hưởng này được quản lý bởi DDBMS. Mức độ của các ảnh hưởng này là điểm đặc trưng của mức trong suốt phân tán dùng cho các cập nhật.
Để hiểu cần phải có các thao tác di chuyển dữ liệu nào khi cập nhật một thuộc tính phân mảnh (fragmentation attribute) thì chúng ta cần nhìn vào cây phân mảnh (fragmentation tree).
Cây cập nhật (update tree):
Dựa vào cây phân mảnh để xác định các thao tác di chuyển dữ liệu nào khi cập nhật một thuộc tính phân mảnh.
Cây cập nhật của thuộc tính A được sử dụng trong vị từ chọn của phân mảnh ngang là cây con có nút gốc là nút biểu diễn phân mảnh ngang ở trên.
Việc thay đổi thuộc tính phân mảnh sẽ ảnh hưởng tới các mảnh là các nút lá của cây con cập nhật của thuộc tính phân mảnh:
- Dữ liệu bị di chuyển giữa các mảnh
- Một bộ bị sắp đặt lại theo một cách khác.
Ví dụ 2.22: Xét ví dụ 2.13 với ứng dụng cập nhật mã phòng.
Hình 2.10 cho thấy việc thay đổi thuộc tính MAP chỉ ảnh hưởng đến NV1, NV2 và NV3 chứ không ảnh hưởng đến NV4. Một bộ có thể di chuyển (thay đổi các mảnh) giữa hai trong ba mảnh do hệ quả của việc cập nhật.
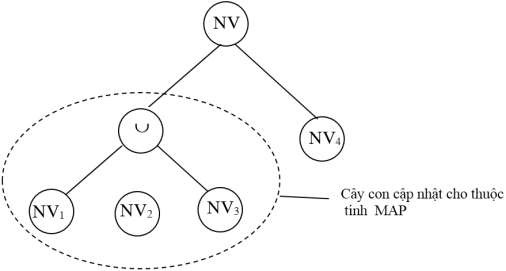
Hình 2.10. Cây con cập nhật cho thuộc tính MAP trong cây phân mảnh của quan hệ NV
Ví dụ 2.23: Xét ví dụ 2.13 với ứng dụng cập nhật mã phòng có quan hệ NV như sau:
NV
HOTEN | LUONG | THUE | MAQL | MAP | |
NV1 | Nguyễn Minh Anh | 100 | 10 | QL1 | 10 |
NV2 | Hà Tấn Đạt | 200 | 20 | QL2 | 12 |
NV3 | Trung Khang | 150 | 15 | QL3 | 15 |
NV4 | Nguyễn Kiên Nam | 200 | 8 | QL3 | 15 |
NV5 | Lê Diệu Huyền | 130 | 14 | QL4 | 5 |
Có thể bạn quan tâm!
-
 Cơ sơ dữ liệu phân tán - 9
Cơ sơ dữ liệu phân tán - 9 -
 Tính Trong Suốt Phân Mảnh Dùng Cho Các Ứng Dụng Chỉ Đọc
Tính Trong Suốt Phân Mảnh Dùng Cho Các Ứng Dụng Chỉ Đọc -
 Truy Xuất Csdl Ql Dự Án Khi Ddbms Với Trong Suốt Vị Trí
Truy Xuất Csdl Ql Dự Án Khi Ddbms Với Trong Suốt Vị Trí -
 Truy Xuất Csdl Sau Khi Nhập Vào Tất Cả Các Giá Trị
Truy Xuất Csdl Sau Khi Nhập Vào Tất Cả Các Giá Trị -
 Truy Xuất Csdl Trước Khi Nhập Vào Các Giá Trị
Truy Xuất Csdl Trước Khi Nhập Vào Các Giá Trị -
 Vấn Đề Thiết Kế Cơ Sở Dữ Liệu Phân Tán
Vấn Đề Thiết Kế Cơ Sở Dữ Liệu Phân Tán
Xem toàn bộ 312 trang tài liệu này.
Nhưng quan hệ toàn cục NV được phân mảnh như sau: NV1 = MANV, HOTEN, LUONG, THUE (MAP ≤10 (NV)) NV2 = MANV, MAQL, MAP (MAP ≤10 (NV))
NV3 = MANV, HOTEN, MAP (MAP > 10 (NV))
NV4 = MANV, LUONG, THUE, MAQL (MAP > 10 (NV))
Các mảnh có kết quả như sau:
NV1
HOTEN | LUONG | THUE | |
NV1 | Nguyễn Minh Anh | 100 | 10 |
NV5 | Lê Diệu Huyền | 130 | 14 |
NV2
MAQL | MAP | |
NV1 | QL1 | 10 |
NV5 | QL4 | 5 |
NV3
HOTEN | MAP | |
NV2 | Hà Tấn Đạt | 12 |
NV3 | Trung Khang | 15 |
NV4 | Nguyễn Kiên Nam | 15 |
NV4
HOTEN | LUONG | THUE | MAP | |
NV2 | Hà Tấn Đạt | 200 | 20 | 12 |
NV3 | Trung Khang | 150 | 15 | 15 |
NV4 | Nguyễn Kiên Nam | 200 | 8 | 15 |
Khi đó hình 2.11 cho thấy cây con cập nhật cho thuộc tính MAP là toàn bộ cây phân mảnh.
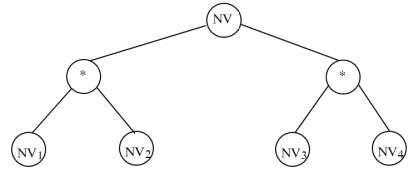
Hình 2.11. Cây con cập nhật khác cho thuộc tính MaP trong cây phân mảnh của quan hệ NV
Giả sử thay đổi giá trị của MAP từ 5 thành 12 của một bộ có MANV=NV5
Ảnh hưởng của việc thay đổi giá trị MAP được chỉ ra sau đây: Ban đầu một bộ thuộc về các mảnh NV1, NV2 của cây con bên trái, sau đó nó thuộc về cây con bên phải NV3, NV4.
Kết quả các mảnh sau khi cập nhật:
NV1
HOTEN | LUONG | THUE | |
NV1 | Nguyễn Minh Anh | 100 | 10 |
NV2
MAQL | MAP | |
NV1 | QL1 | 10 |
NV3
HOTEN | MAP | |
NV2 | Hà Tấn Đạt | 12 |
NV3 | Trung Khang | 15 |
HOTEN | MAP | |
NV4 | Nguyễn Kiên Nam | 15 |
NV5 | Lê Diệu Huyền | 12 |
MANV | HOTEN | LUONG | THUE | MAP |
NV2 | Hà Tấn Đạt | 200 | 20 | 12 |
NV3 | Trung Khang | 150 | 15 | 15 |
NV4 | Nguyễn Kiên Nam | 200 | 8 | 15 |
NV5 | Lê Diệu Huyền | 130 | 14 | 12 |
NV4
2.3.2. Chương trình ứng dụng cho các ứng dụng cập nhật
1) Trong suốt phân mảnh
Người lập trình ứng dụng thực hiện cập nhật giống như khi CSDL không phân tán, không cần biết một thuộc tính nào được sử dụng trong định nghĩa của lược đồ phân mảnh
Hệ thống thực hiện ngầm định tất cả các thao tác được yêu cầu thông qua lược đồ phân mảnh và lược đồ định vị.
Cấu trúc chương trình
- Bước 1: Nhận một tham số từ chương trình tựa- Pascal
Read(terminal, $iv1,…, $ivn, $Value_1,…,$Value_n)
- Bước 2: Truy xuất CSDL
Select *
From R
Where
Trong đó:
+ fn1,….,fnn là tên các trường
+ R là các quan hệ toàn cục
- Bước 3: Trả về kết quả như là một tham số
If #FOUND then Update
Set fn1 = $Value_1, …., fnn = $Value_n Where fn1 = $iv1 [and …..and fnn = $ivn]; else write (terminal, “Không tìm thấy”)
Trong đó:
+ fn1,….,fnn là tên các trường
+ $Value_1, …, $Value_n là các giá trị mới
Ví dụ 2.24: Xét quan hệ toàn cục nhân viên trong ví dụ 2.23
Select *