In the dependency grammar, dependency is present and the word central is required. It is assumed that from the existence of the dependent word A it can be concluded that the existence of the central word B. The association grammar allows the association to occur or not. That gives the ability to distinguish between mandatory and optional components in the language’s syntax.

The concept from the center, the very important concept of the dependency model and many other grammar grammars such as HPSG [104] or X-bar theory, is still controversial. The association grammar does not use this concept and has been successful at the syntactic level. However, Schneider [109] argues that there may be some difficulties in semantic analysis without specifying the dependency orientation.
The rules of grammar contain information about word order, that is, about whether related words appear before or after the word described at a lexical entry, consistent with the lexicalization bias of most words. current grammar, suitable for languages where word order is important. That’s also why the linking grammar is flat.
Unlike in a dependent grammar, a graph representing an analysis in a linking grammar can be cyclical, for example when analyzing sentences with relative pronouns as shown in Figure 1.8. down here:

Figure 1.8. The cycle in sentence analysis
In Figure 1.8, the bond causing the main cycle is Bp. This is a form of semantic association that shows that the word represented by “who” is “elephant”.
By allowing cycles, a linking grammar can simultaneously represent syntactic and semantic information in links, while semantic information in a dependent grammar is often represented at a different level than the syntax layer. method (Multi-layer dependent grammar [109]).
Maybe you are interested!
-

 Lexicalization Probabilistic Context-Free Grammar
Lexicalization Probabilistic Context-Free Grammar -
 Approach Through Stroke Structure And Unified Grammar
Approach Through Stroke Structure And Unified Grammar -
 Vietnamese linking grammar model - 6
Vietnamese linking grammar model - 6 -
 Vietnamese linking grammar model - 8
Vietnamese linking grammar model - 8 -
 Links Of Nouns Act As Subject And Complement
Links Of Nouns Act As Subject And Complement -
 Vietnamese linking grammar model - 10
Vietnamese linking grammar model - 10
Dependent grammar and linking grammar also differ in the relationship between non-adjacent words. Associative flatness, similar to flatness in dependent grammars, requires that the arcs representing the association in a sentence do not intersect when plotted over words. With the requirement of flatness, some non-neighboring word relations may not be represented in the associative grammar model. For example, in the sentence “This shirt, even though it’s very expensive, I still buy it”, after drawing a link between the noun “shirt” and the adjective “expensive” and the verb “buy”, it will not be possible to draw the link between the word “even” with a comma while still ensuring flatness. There exist dependency grammars that are not projective, but flatness is required in associative grammars. Thankfully, sentences like the one in the example above are not common in practice.
1.4.2. Formal definitions of linking grammars
Through the informal description mentioned above, we can arrive at a formal description of the associated grammar and related concepts (according to [34]). The following concepts lead to the definition of a linking grammar.
1.4.2.1.Link network
As described above, a link net will represent the analysis of a certain phrase in terms of a link grammar. A link network can be visualized as a graph with vertices labeled as words and arcs labeled as connection types. The graph of the connected network is a flat, connected graph, with all the vertices ordered on the boundary of the graph.
The relation E is symmetric if and only if (x,y) E ⇔ (y, x) E
The relation E is reflexive if and only if (x, x) E
Definition 1.8. [34]
Assuming is an alphabet and Pr is the set of primitive types, (ν, ) is a perfectly ordered set,
- The vertex set V ⊆ ν is a finite non-empty subset of ν, denoted by (v1,… vn), n = | V | and v1 < … < vn;
- w: V → Σ maps each vertex to a word;
- The arc set E ⊆ V × V is a symmetric and reflexive subset of V×V;
- t: E → Pr maps each arc to a primitive type;
- The arcs do not intersect: if (a, b) ∈ E and (c, d) ∈ E such that a < b and c < d then neither a < c < b < d nor c < a < d < b ;
- Graph (V, E) is connected.
A link network is a structure (V, w, E, t), where:
The set of all connected networks on is denoted by NPr(Σ).
Definition 1.9. Results (yield) of the link network [34]
The result of a connected network N = ((v1,… .vn), w, E, t) is :
yield(N) = w(v1)… .w(vn) ∈ Σ+.
The result of the affiliate network is a syntactically correct association phrase.
1.4.2.2. Link button
The link node is a formal concept of a selection form.
Definition 1.10. The set of connected nodes on Pr, denoted Tp, is the set of pairs of two finite lists of Pr. Each link node X has a left list of ports denoted tn- … t1- and a right list of ports denoted t1+ … tm+. [34]
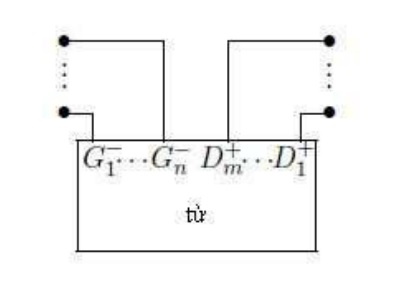
Figure 1.9. Link button
For each vertex v of the associative network N = (V, w, E, t), the set of arcs related to v can be divided into a left list (xn,v)… (x1,v) and a left list (xn,v)… (x1,v) the list must be (v,y1)… (v,ym), where xn < xn-1 < … < x1 < v < y1… < ym-1 < ym. Thus, v is related to the associated node node(v) = t(xn,v)-… t(x1,v)- t(v,y1)+. .. t(v,ym)+
1.4.2.3 Linking grammar
Definition 1.11. [34]
Let Σ be an alphabet. The association grammar is a structure G = (Σ, I) with I: Σ → Pf(Tp) (denoted Pf(X) is the set of all subsets of X).
Definition 1.12.
The interconnected network ((v1, … .vn), w, E, t) is produced by G if and only if G: w(vi) → t(vi) for all i, 0 ≤ i ≤ n.
Definition 1.13.
The sentence c1…cn ∈ Σ + is produced by associative grammar G if and only if there exists a linked network N such that c1, …, cn = yield (N) and N are produced by G.
Definition 1.14.
The language produced by the associative grammar G, denoted LΣ+(G) is the set of all sentences produced by G.
1.5. Conclude
Comparing the above-mentioned grammar models, it can be seen that the classical context-free grammar model still has some limitations with complex tree of structure, difficult to represent the relationship between non-adjacent components as well as many phenomena. peculiarities in each language. A grammar based on a context-free approach is a tree connection grammar that requires a very large tree bank, which is not currently available in Vietnam. The stroke approach is capable of representing a wide language class, but building a stroke system requires a lot of effort and extensive knowledge of Vietnamese.
As analyzed in Section 1.3, sentence analysis by dependency model has many advantages. That’s why dependency analyzers have been built for many languages. The first is a language with a free word order such as Russian [98], Turkish, Finnish [109]. However, that does not mean that the dependency model is only suitable for languages with free word order. Dependency parsing has also been successful in English [44], French [39], [40] and many other European languages. Dependency parsing is also noted for many Asian languages: Japanese [99], [125], Korean [74], [78], Chinese [118], Indonesian [72], Thai[119 ], Philippines [85].
The dependent grammar model is difficult to build without basic research in linguistics. For example, according to [2], there is still a lot of controversy about the composition of nouns: In Vietnamese, there are cases where the main element of grammar plays a secondary role in terms of grammar while the main element in terms of words. grammar plays a secondary role in grammar.
Example: Consider two sentences
- It was only 6 years old at the time
- He was only 6 years old when the August Revolution broke out
With the same position, the same structure, the noun “at” plays the main role in the upper sentence but plays a secondary role in the lower sentence. Furthermore, in the noun structure only the noun is the main element, or can the main component contain words other than the noun? So the question of which component depends on which component still has no exact answer.
Currently, there is only a Vietnamese dependency parser built by Nguyen Le Minh and colleagues [17]. This parser is built using the MST method, ie converting the problem of finding the dependent tree to the problem of finding the largest spanning tree in a graph, on a corpus of 450 labeled Vietnamese sentences and manual analysis. Thus, there is no real dependency grammar built for Vietnamese.
The thesis has decided to choose the linking grammar model for the following reasons:
- Linking grammar is also a form of dependency grammar. However, because the association only cares about the direction and does not determine which objects it depends on, the associations can be inferred from the grammar rules more easily.
- It is possible to represent semantic information through associations of associative grammars, so there are many possibilities to expand research on this model.
- In terms of language representation, Sleator and Temperley [111] proved that every linked grammar has an equivalent and converse context-free grammar, that is, these two theoretical models both represent the language class. context-free language. According to Jurafsky[70], natural languages that fall outside the class of context-free languages such as copying languages contain very special sentences, rarely encountered in practice. These languages are not within the scope of the thesis of interest.
- In general word order is important in Vietnamese. For example, in [2], Nguyen Tai Can wrote that “in Vietnamese nouns there is no type of determiner with a free order, sometimes in front, sometimes after”, the prefix at the beginning and the determinant at the end. Nouns have some fundamentally different characteristics. The structure of other types of short phrases is similar. Only a small number of sentence elements have flexible positions, such as time words (“yesterday”, “tonight”, etc.). Thus, the special association model emphasizing the position of the elements in the sentence is suitable for Vietnamese.
- Most languages of Southeast Asia are “resource-poor” languages, the sample corpus of these languages is small, so many machine translation systems still use the method of translation based on rules, in addition Syntax rules are also very effective for improving translation quality for other methods. With completely lexicalized features, the association model allows to edit and complete the translation quite well.
- Continuing related to the problem of machine translation, in Vietnamese, when switching to the past, future… the main verb does not change form but is added with auxiliary verbs indicating the tense. Therefore, when translating a Vietnamese sentence into a language with strong morphological changes, it is necessary to detect it through these auxiliary words. For example, the sentence “I am learning”, when translated into English, the verb “learn” is present continuous. However, if we consider the sentence “Yesterday, he came while I was studying” the verb “to” must be conjugated in the past tense, the verb “to learn” must be conjugated in the past continuous. These relationships can be represented in the translation model through the associations between the word “yesterday” and the verbs. Similarly, the way of addressing in Vietnamese is very complicated. Many phrases such as “he”, “them”, “we”, “them” act as pronouns, when translated into other languages often have to be translated into pronouns. The dictionary of linked grammars accepts formulas for phrases and formulas for only one or a few words, so the ability to handle many Vietnamese exceptions flexibly.