Some sentences may not be fully parsed, part of it is also analyzed. The example in Figure 3.8. is the analysis for the sentence “Every empty-handed season is difficult to swallow”. This sentence is a passive but hidden word. Built-in links are still displayed even if the result is a syntax error.

Figure 3.8. The results of the link analysis of the sentence “Every empty season is difficult to swallow”
To evaluate the analysis results, when there was no sample corpus, 200 sample sentences were analyzed and edited by hand and stored as an analysis bank. With the sentence “Most mantises eat insects” and the analysis results in Figure 3.9 below:
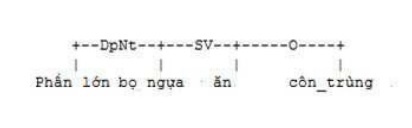
Figure 3.9. The results of the link analysis of the sentence “Most mantises eat insects”
The analysis results are stored in the same format as in [94]:
This work requires a lot of effort, especially with sentences in written articles, so the thesis has only created a small corpus. The details of the dataset are as follows:
Table 3.1. Sample corpus details for the link parser
| Numbers | Theme | Number of sentences | Average number of words/sentence |
| 1 | Vietnamese conversation | 50 | 7.6 |
| 2 | Sport | 50 | 12.7 |
| 3 | Life Sciences | 50 | 8.7 |
| 4 | Travel | 50 | 10.5 |
| total | 200 |
Maybe you are interested!
-

 Vietnamese linking grammar model - 13
Vietnamese linking grammar model - 13 -
 Application Algorithm To Expand Vietnamese Dictionary
Application Algorithm To Expand Vietnamese Dictionary -
 Test Results For Analyzing Simple Sentences And Simple Compound Sentences
Test Results For Analyzing Simple Sentences And Simple Compound Sentences -
 Vietnamese linking grammar model - 17
Vietnamese linking grammar model - 17 -
 Vietnamese linking grammar model - 18
Vietnamese linking grammar model - 18 -
 Vietnamese linking grammar model - 19
Vietnamese linking grammar model - 19
According to [94]. The parser is evaluated according to the following criteria:
Recall is the ratio between the number of chunks/constituents/relations (CCRs) returned by the parser that match the sample CCR and the total number of CCRs in the set. annotated sample
Precision is the ratio between the number of matching CCRs returned by the parser and the total number of CCRs received from the parser. CCR here is the link. The results are as shown in Table 3.2 below
Table 3.2. Link analysis results for sample sets
| Sample set | Accuracy | Coverage |
| 1 | 45.1% | 25.7% |
| 2 | 28.4% | 15.6% |
| 3 | 33.5% | 18.5% |
| 4 | 30.2% | 20.8% |
| average | 34.3% | 20.1% |
Among these sample sets, the set of dialogue sentences achieves the highest accuracy because it contains basic Vietnamese sentence patterns that easily satisfy the connections of the linking syntax. The common-sense sample set reached the second highest rate because in general, the sentences were translated from foreign texts and the sentence structure was quite simple. The tourism sample set is taken from a number of tour advertisements written by Vietnamese people, but the structure is also easy to understand and analyze. In the sample sets, the set of sports sentence samples, mainly translated from English, but the style is quite structured, many sentences have the order of the sentences changed or some parts are missing, so the results are the lowest.
It can be seen that the types of unsuccessful analysis sentences are compound sentences or simple sentences that change the position of components or have some hidden components.
3.2. Parsing for compound sentences
Parsing a multi-core sentence is much more complicated than a single sentence. For sentences with two or more cores, English is classified according to the relationship between the two clauses. If the relationship is parallel (using conjunctions “and”, “or”, “not only… but also” . . .), the sentence is called a “compound sentence”. If the relationships are of a major-subordinate nature (using the conjunctions “if”, “then”, “because”… ), the sentence is called a “complex sentence”. A complex-compound sentence is much more complex when it contains at least two parallel clauses and at least one subordinate clause. Vietnamese sentence classification is slightly different from English. Diep Quang Ban [1] distinguishes a compound sentence as a sentence containing two or more cores, in which no core includes another and a complex sentence containing two or more cores but one core includes the remaining cores. again. For example, the sentence “I was waiting for the car when a friend came running up” is classified as compound sentence while the sentence “The cat I bought has run away” is classified as complex sentence. The delineation of propositional boundaries in complex sentences may require a large corpus with machine learning methods, so it has not been mentioned in the thesis.
According to the views of Diep Quang Ban [1], Nguyen Chi Hoa [9], Tran Ngoc Them [23], the proposition is the smallest unit (element) of the text, the compound sentence is built from the “blocks” , each “block” is a proposition. The core compound can be parallel with two or more sides, can also be reciprocal (main and secondary) with exactly two sides [23], [28]. These conclusions are completely consistent with the theory of discourse structure.
For the traditional context-free grammar model, the subordinate clause in a compound sentence can be generated from the special non-terminating notation SBAR of the grammar. With a very large set of rules, ambiguity about the bounds of the proposition is very common. Also due to the large non-terminal symbol set, the parse tree for compound sentences is very complex. That will affect the speed and results of other processing such as text classification, text summarization, machine translation – processing problems based on the syntactic structure of sentences.
The dependency model parsers divide compound and complex sentences into clauses, parse each clause separately and then find the dependency relationship between the clauses to give the overall analysis. Many studies on parsing compound and complex sentences on dependent grammar have focused on the form of compound sentences and main – minor complex sentences such as those of Ohno group [99] , Utsuro group [125] for Japanese, Sang Soo Kim [74] for Korean. The dependency relationship between the main clause and the subordinate clause is determined by linguists. However, not all dependent grammar models allow to show the relationship between clauses, especially with parallel compound sentences. Many extensions of the dependency model have been built as in [65], [75] to represent the structure of multi-core sentences, but those representations become quite complex.
The problem of analyzing compound sentences has also been mentioned by Sleator and Temperley [111]. A special feature of the link parser is that it can parse some main and minor compound sentences through some special links such as CO (the link between the suggestive element and the subject of the following clause). , CC (associating clauses with coordinating conjunctions)… is established for conjunctions such as “because”, “although”, “but”… Thesis parser (to be said) to the previous item) also get the same result for Vietnamese. However, with the type of compound sentence with many complex clauses and relationships such as “If a cadre or civil servant is re-hired to work at the old agency or unit, the actual time of studying according to the training program will (indicated on the certificate or training degree awarded) is counted in the consideration of regular salary increment”, the link parser failed. That’s because the join requests do not show the relationship between the clauses in the sentence. Furthermore, using only conjunctions of conjunctions would require a lot of computation time. If you analyze each clause of a compound sentence separately and then combine them into an overall analysis, the above problems can be solved.
Rhetorical Structure Theory (Rhetorical Structure Theory) proposed by Mann and Thompson [86], allows to represent the relationship between elements in a text in the form of a tree with leaves as propositions. At the heart of discourse structure theory are the axioms of text structure outlined by Marcu in [89]:
Every text can be subdivided into a non-intersecting sequence of elemental text units, and a discursive tree is associated with the text satisfying the following conditions:
- There exists a one-to-one mapping between tree leaves and prime text units
- The tree obeys a set of constraints that can be inferred from the semantics and practice of using prime units as well as the relationships between those units. From the constraints it is possible to infer a discursive relationship between them. text units of different sizes.
- The relations used to join text units are divided into two types: isocoupler and syntactically dependent.
Research on the discursive structure of Vietnamese texts is also interested by many famous linguists. The thesis has used the results of linguistics of Nguyen Chi Hoa [9], Tran Ngoc Them [23] to build a discourse analyzer for Vietnamese texts. With a test corpus consisting of 5 articles on websites www.vnn.vn, www.vnexpress.net, www.dantri.com.vn, analyzed by linguists, the accuracy achieved is as follows:
Table 3.3. Discourse analyzer test results (not yet combined parser)
| Test text | Number of paragraphs | Number of sentences | Number of clauses | Number of prime units | Relationship number | Percentage correct |
| 1 | 11 | 29 | 54 | 46 | 52 | 64.27% |
| 2 | 8 | 21 | 21 | 25 | 37 | 58.43% |
| 3 | 5 | 12 | 30 | 19 | 29 | 62.78% |
| 4 | 10 | 32 | 50 | 37 | 40 | 59.20% |
| 5 | 1 | 3 | 6 | 6 | 15 | 95.09% |