On the whole text (including sentence, paragraph, and item levels), the discourse analyzer gave an accuracy of 63%. At the sentence level, the accuracy achieved is approximately 80%. Deriving from the characteristics of Vietnamese compound sentences that most of the propositional limits can be detected by discursive signs combined with some syntactic features, the thesis has improved the discourse segmentation algorithm to a higher level. sentence to split the compound sentence into clauses, then build the discourse tree of the sentence. The clauses will be parsed separately, and the discursive relations between the clauses will be transformed into large connections in the linking grammar into a complete analysis of the entire sentence. This is possible because, for the association grammar model, the association requirement only determines the direction of the association, so there is no need for overly complex evaluations of dependencies. Since the scope of analysis is compound sentences, the limits of the propositions are quite clear.
The thesis used the names of 18 discursive relationships between the propositions [1] and [9] as the connection names. These connections are massive because they link phrases together. They are built between pairs of clauses according to the discourse tree of the sentence. Figure 3.10 shows the discourse tree of the sentence “It rained heavily and the wind was very strong, so I had to leave school, my mother had to leave work”. This sentence has 4 clauses denoted A1, B1, C1, D1. Discourse relations: cause, association, enumeration are transformed into connections. The connection between clauses must still satisfy the following requirements:
- Each connection must join two words
- Analysis of the connection of sentences must satisfy the properties of the linking grammar: flatness, connectivity, ordinality as well as satisfaction and exclusion.
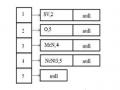
![Figure 3.10. Discourse analysis tree of the sentence “[it rained heavily and A1] [the wind was 1](uploads/2021/08/15/luan-an-tien-si-cntt-mo-hinh-van-pham-lien-ket-tieng-viet-17.jpg)
Figure 3.10. Discourse analysis tree of the sentence “[it rained heavily and A1] [the wind was very strong, so B1] [I had to leave school,C1] [my mother had to leave work.D1]”
To ensure flatness, that is, the links do not intersect when plotted over words, it is necessary to select one representative word from each clause to link. Each word in the clause will be assigned a weight (rank). The word with the least weight corresponding to the highest link will be chosen to represent the clause.
Thus, the parsing process for compound sentences needs to go through the following steps:
- Discourse segment
- Parse for each clause, adding the received links to the overall link.
- Build a discourse analysis tree for sentences.
- Browse the discourse analysis tree in the following order, adding connections for each discourse relation.
3.2.1. Building a tree of discourse
3.2.1.1.Discourse segment
The smallest piece of text between which discursive relations exist is called Elementary Discourse Units (EDU). The EDU can be a clause or a clause title.
The thesis on improving the algorithm of Marcu [89] for discourse segmentation. The notation for dividing text into prime fragments is essentially quite similar to that of English. Table 3.3. below allows to identify potential discursive signs in the text to be analyzed.
Table 3.4. Regular expressions represent some latent discursive cues
| Signal | How to know? |
| In spite of | [s ]In spite of(s| | ] |
| Because of | [s ]Because of(s| |n) |
| But | [,][s ]But(s| | ) |
| On the other hand | [,][s ]On the other hand(s| | ) |
| Still | [s ][,] Still(s| | ) |
| COMMA | ,[s| | ) |
| OPEN_OUT | [,][s ]+( |
| CLOSE PARENTHESIS | )(s| | ) |
| BRICK_BACKGROUND | [,][s ]+–(s| | ) |
| END_STORY | (“.”)|(“?”)|(“!”) |
Maybe you are interested!
-

 Application Algorithm To Expand Vietnamese Dictionary
Application Algorithm To Expand Vietnamese Dictionary -
 Test Results For Analyzing Simple Sentences And Simple Compound Sentences
Test Results For Analyzing Simple Sentences And Simple Compound Sentences -
 Vietnamese linking grammar model - 16
Vietnamese linking grammar model - 16 -
 Vietnamese linking grammar model - 18
Vietnamese linking grammar model - 18 -
 Vietnamese linking grammar model - 19
Vietnamese linking grammar model - 19 -
 Viterbi Type Algorithm To Find The Best Analysis
Viterbi Type Algorithm To Find The Best Analysis
Discourse segmentation algorithm [89] allows to read all the discursive signs of the text, each sign corresponds to one of 10 actions NOTHING, NORMAL, NORMAL_THEN_COMMA, COMMA, END, MATCH_PAREN, COMMA_PAREN, MATCH_DASH, SET_AND, SET_OR. The following are descriptions of some of the most common actions:
- The NOTHING action instructs the analyzer to treat the suggested phrase as a single word. That means no text unit limit is established when a suggested phrase with those actions is processed.
- The NORMAL action instructs the analyzer to add a text limit immediately preceding the occurrence of the signature. The text markers correspond to the border between elemental text units.
- The COMMA action instructs the parser to add a text limit immediately after the occurrence of the first comma of the input string. If the first comma is followed by “and” or “or” , the text boundary is placed after the occurrence of the following comma. If no comma is found before the end of the sentence, a text limit is established at the end of the sentence.
- The NORMAL_THEN_COMMA action instructs the parser to add a text limit immediately before the occurrence of the symbol and another text limit immediately after the occurrence of the first comma on the input text. If the first comma is followed by “and” or “or”, the processing is the same as in the COMMA action.
Based on the algorithm of Marcu [89], the thesis segments Vietnamese text with the following actions: COMMA, NORMAL, NOTHING, NORMAL_THEN_COMMA, END, SET_ AND, SET_OR, MATCH_PAREN, COMMA_PAREN, MATCH_DASH, PH.
After having built a parser on a linked grammar for a single sentence, the thesis used this tool to more thoroughly solve the problem of ambiguity with the word “and”.
Table 3.5 below gives some common discursive signs in Vietnamese and corresponding treatment actions for those discursive signs. In some cases, the sign’s handling action will not be used when the sign is handled by the preceding discursive sign action, for example in the sentence “Although it has no money, it spends wasteful”, the comma is handled by the COMMA action of the “though” sign.
Table 3.5. Action in response to certain discursive signs
| Signal | Location | Action |
| in spite of | B (Sentence beginning) | COMMA |
| because of | B | DUAL |
| But | M (Mid-sentence) | NORMAL |
| And | M | NORMAL_THEN_COMMA |
| Because the | B | DUAL |
| Candlestick | M | NORMAL |
| Comma | M | PH |
| Open brackets | M | MATCH_PAREN |
| Close parenthesis | E (End of sentence) | NOTHING |
| strikethrough | B | MATCH_DASH |
| End of sentence | E | NOTHING |
The action NORMAL_THEN_COMMA, is related to the word “and”. The thought process of the thesis when the discourse segmentation encounters the word “and” is as follows:
Read the next sign. Add a text limit after the next sign. If the sentence is read in its entirety, the text boundary mark is placed at the end of the sentence. Conduct a grammatical analysis of the association with the phrases before and after the word “and”.
If both phrases are received: from the beginning of the text in question before the word “and” and the word after the word “and” coming before the next discursive sign are propositions, then the word “and” has the role of acting. language in a sentence. Add a text limit after the “and” sign. Otherwise, the word “and” is a conjunction of sentence components that should be omitted.
The handling of the NORMAL_THEN_COMMA action, the action associated with the word “and” as in the algorithm described later.
Commas require more complex handling. In [89], commas are handled by the discourse analyzer in the two actions COMMA and NORMAL_THEN_COMMA, the other cases are ignored. Now the thesis deals with some other cases. When a comma is encountered, even though the term under consideration is a syntactically correct clause, it is unlikely that the text limit has been added immediately after the comma. It is necessary to consider whether the sign after the cluster is a comma. If it is a comma, the text limit will be filled in after the first sign other than a comma. For example, in the sentence “I bought many toys, cakes, and candies for my children to give you”, the text limit should be added after the word “candy” instead of after the word “toys”, even though the phrase “I buy a lot of toys” is a complete proposition. This work is done by the action PH associated with a comma.
Here is the entire discourse segmentation algorithm. The input of the algorithm includes the sentence to be analyzed and the array of discursive signs in the sentence. The output of the algorithm is the input sentence filled with [] pairs to indicate the limit of the proposition. In this algorithm, the thesis has edited the NORMAL_THEN_COMMA action and added the PH action to handle ambiguities with “and”, “or” and commas. Other treatments according to [89].
| Enter: Story Array of n potential discourse markers that can appear in S: marker[n] Ra: Propositional title units of Method: //The italicized paragraphs are the treatment proposed by the thesis { status := nil; clauses := nil; parentheticals := nil; currClauseStart := 1; currParentStart := 1; for i from 1 to n // Handling the case where the status is saved { if MATCH_PAREN ∈ status if markerTextEqual(i,”)”) { parentheticals:= parentheticals ∪ textFromTo(currParentStart,offset(i)); status := status {MATCH_PAREN}; currParentStart := -1; continue; } if MATCH_DASH ∈ status if makerTextEqual(i,”-”) { parentheticals := parentheticals ∪ textFromTo(currParentstart,offset(i)); status := status {MATCH_DASH}; currParentStart := -1; continue; } if COMMA_PAREN ∈ status if markerTextEqual(i,”,”) && NextAdjacentMarkerisNotAnd()&& NextAdjacentMarkerIsNotOr() { parentheticals := parentheticals ∪ textFromTo(currParentStart,offset(i)); status := status {COMMA_PAREN}; currParentStart := -1; continue; } if COMMA ∈ status^markerTextEqual(i,”,”) ^ NextAdjacentMarkerisNotAnd()^ NextAdjacentMarkerIsNotOr() { clauses := clauses ∪ textFromTo(currClauseStart,offset(i),parentheticals); currClauseStart := i; status := status {COMMA}; parentheticals := nil; currParentStart := -1; continue; } if SET_AND ∈ status if markerAdjacent(i-1,i) ^ currClauseStart < i-1 { clauses:= clauses ∪textFromTo(currClauseStart,offset(i-1),parentheticals); currClauseStart := i-1; setDiscourse(i-1,yes);setDiscourse(i,yes); parentheticals := nil; status := status {SET_AND}; } if SET_OR ∈ status if markerAdjacent(i-1,i) ^ currClauseStart < i-1 { clauses:=clauses ∪textFromTo(currClausesStart,offset(i-1),parentheticals); currClausesStart := i-1; setDiscourse(i-1,yes); setDiscourse(i,yes); parenthethicals := nil; status := status{SET_OR}; } if NORMAL_THEN_COMMA ∈ status if not markerTextEqual(i,”,”) {clauses:=clauses ∪ textFromTo(currClauseStart, offset(i), parentheticals); status:= status{NORMAL_THEN_COMMA} parentheticals := nil; currParentStart := -1;} if PH ∈ status ^ not markerTextEqual(i,”,”) {if not markerTextEqual(i,”and”) if (isClause(textFromTo(offset(i), offset(i+1)) { clauses:=clauses ∪ textFromTo(currClauseStart, offset(i),parentheticals); currClauseStart:=i+1; } else { clauses:=clauses ∪ textFromTo(currClauseStart, offset(i),parentheticals); status:=status{PH}; } } swithch getActionType(i)) case DUAL: if markerAdjcent(i-1,i) { status := status ∪ {DAU_PHAY}; setDiscourse(i-1,yes);setDiscourse(i,yes); } else { clauses := clauses ∪ textFromTo(currClauseStart,offset(i),parentheticals); currClausesStart := offset(i); parentheticals := nil; setDiscourse(i,yes); } case NORMAL: clauses := clauses ∪ textFromTo(currClauseStart, offset(i), parentheticals); currClauseStart := offset(i); parentheticals := nil; setDiscourse(i,yes); case COMMA: if markerAdjacent(i-1.i) {setDiscourse(i-1,yes);setDiscourse(i,yes);status := status ∪ {COMMA};} case NORMAL_THEN_COMMA if isClause(textFromTo(currClauseStart,offset(i))^ isClause(textFromTo(offset(i), offset(i+1)) {clauses:= clauses ∪ textFromTo(currClauseStart,offset(i),parentheticals); status := status ∪ {getActionType(i)}; currClauseStart := offset(i);parentheticals := nil; setDiscourse(i,yes); } case PH: if isClause(textFromTo(currClauseStart, offset(i))^ isClause(textFromTo(offset(i),offset(i+1)) {clauses:= clauses ∪ textFromTo(currClauseStart,offset(i),parentheticals); clauses:= clauses ∪ textFromTo(offset(i)+1,offset(i+1),parentheticals); } else status:= status ∪ {getActionType(i)}; case NOTHING: if signalsRhetoricalRelations(i) setDiscourse(i,yes); case MATCH_PAREN,COMMA_PAREN,MATCH_DASH: status := status ∪ {getActionType(i)}; currParentStart := offset(i); case SET_AND, SET_OR: if status is neither MATCH_PAREN nor MATCH_DASH status := status ∪ {getActionType(i)}; } finishUpParentheticalsAndClauses(); End For |
Figure 3.11. Discourse segmentation algorithm (with ambiguity removal)
Explain the meaning of objects used in the algorithm:
- The status variable records a set of pre-processed cues that may still affect the boundary definition of clauses and the EDUs in parentheses. Initially, the value of the variable is set to NIL.
- The parentheticals variable records the set of units in parentheses associated with a given clause. Initially, the value of the variable is equal to NIL.
- The clauses variable records all the EDUs in the sentence under consideration, except the EDUs in parentheses. Initially, the value of the variable is equal to NIL.
- The variable currParentStart (Start of Parentheses) records the position of the unit start point in parentheses. Its value is initially set to -1, meaning that no units in any of the parentheses have been found yet.
- The variable currClauseStart (Clause start point) records the position at which the EDU under consideration begins. Initially, its value is 1- because the first EDU of the sentence starts at offset 1.
- The sign function textEqual(i, s) has the value true if the ith phrase in the array of discourse signs is s. Otherwise, the function has the value false.
- The offset(i) function returns the position of the ith hint word of the marker[n] array in the s.offset sentence depending on the “position” parameter of the suggested word. If the position value is B, the function returns the value where the hint phrase begins. If its value is E, the function returns where the hint term ends.
- The textFromTo(i, j) function returns the EDU value between offsets i and j in sentence S.
- The textFromTo(i, j, parentheticals) function returns the text unit between offset i and j in sentence S with additional information about the units in brackets. The set of units in brackets is stored in the parentheticals variable.
- The setDiscourse(i, yes) function sets the i-th discourse-function flag value to “yes”, indicating that the i-th sign has a discursive function.
- The function getActionType(i) has the value of the action of the i-th discourse sign in sentence S.
- The function signalsRhetoricalRelations(i) (Signs of a discursive relationship) has the value true if the ith suggested word has a discursive role in the sentence.
- The function finishUpParentheticalsAndClauses() saves the undefined text as EDUs after processing the array of potential discourse signs of the sentence.
- The isClause(s) function proposed by the thesis will analyze the text included in the linking grammar and return the correct results if the paragraph is syntactically correct and contains the core (containing at least one of the three links SV, DT_LA and SA).
| boolean isClause (s) {linkage lnk;int n;connection c; n=NumberOfWord(s) if (PARSE(s,lnk)!=0) //s correct syntax {for(i=1;i<=n;i++) for each c in lnk.linklist(i) {if(c.type=“SV” or c.type=“DT_LA” or c.type=“SA”)//s contain the core {return true; break;} } return false; } return false;//s syntax error } |
Figure 3.12. isClause . function
For example: With sentence S as “It was raining heavily and the wind was very strong, so I had to miss school, my mother had to leave work”, the array marker[4] has the values of the elements as “and”, “should”, sign commas and end sentences. The word “and” is associated with the action NORMAL_THEN_COMMA. In the algorithm’s processing in Figure 3.11, the value of isClause function with the phrases “it rains a lot” and “the wind is very strong” is true, so the Clauses set of clauses is added with the clause “it rains a lot and” and NORMAL_THEN_COMMA is saved in status. When dealing with the “should” sign with the NORMAL action, the clause “the wind is very strong so” is added to Clauses, the status is empty. When a comma is encountered, because the isClause function with the phrase “I have to leave school,” and the phrase after the comma “my mother has to leave work” both evaluate to true, these two clauses are added to Clauses. The ending sign corresponds to the NOTHING action, so do not add new clauses to Clauses. The results of discourse analysis when testing are presented in Figure 3.19.