Find discursive relationships with units that do not appear discursive signs
For units that do not appear discursive signs, based on Vietnamese characteristics, the thesis uses the algorithm to find co-occurring words proposed by Marcu [89]. Then, the discourse relations will be assigned as Connect or List.
Building a tree of discourse
To be able to build a tree of legal text structures, one must choose from the relationships to find a set of relations that form a legal text structure. The thesis builds a tree of legal structure of text by proof-theoretic method[89], using transformations to refer to legal structure.

The proof-theoretic method generates all sets of legitimate structured trees, with each set having the following parameters: kernel or satellite, leaf or root, relation name and tree members. Each tree is described with a Tree structure (status, type, promotion, left, right), where:
- status: describes the state of the node, be it Nuclear (N) or Satellite (S).
- type: name of the discourse relation.
- promotion: The set of values from 1 to n is the number of the most prominent propositions in the tree. The most prominent clause is the one that plays the most important role in the text represented by the node under consideration.
- left: description of the left subtree.
- right: description of the right subtree.
A leaf node can be described as a tree by assigning the Left and Right values to NULL and the type to LEAF.
According to [89], the proof-theoretic method allows building a text structure from 14 axioms. Here is an example of an axiom:
[S(l, b, Tree1(kernel, type1, p1, left1, right1), rr1) ^
Maybe you are interested!
-

 Test Results For Analyzing Simple Sentences And Simple Compound Sentences
Test Results For Analyzing Simple Sentences And Simple Compound Sentences -
 Vietnamese linking grammar model - 16
Vietnamese linking grammar model - 16 -
 Vietnamese linking grammar model - 17
Vietnamese linking grammar model - 17 -
 Vietnamese linking grammar model - 19
Vietnamese linking grammar model - 19 -
 Viterbi Type Algorithm To Find The Best Analysis
Viterbi Type Algorithm To Find The Best Analysis -
 Vietnamese linking grammar model - 21
Vietnamese linking grammar model - 21
S(b+1, h, Tree2(kernel, type2, p2, left2, right2), rr2) ^
rhel_rel(name, n1, n2) ∈ rr1∩ rr2^ n1∈ p1 ^ n2∈ p2^ paratactic(name)]
S(l, h, Tree(kernel, name, p1 ∪ p2, Tree1(…), Tree2(…)), rr1∩ rr2 {rhel_rel(name, l, n1, n2)}
This premise means:
If
- The text segment extending from unit l to unit b is represented by a tree structure Tree1 with discourse relation set rr1
- The text segment extending from unit b+1 to unit h is represented by a Tree2 tree with discourse relation set rr2.
- There exists a discourse relation rhel_rel(name, n1, n2) between paragraph n1 which is one of the prominent passages of paragraph [l, b] and paragraph n2 which is one of the prominent passages of [b+1, h] .
- The discourse relation rhel_rel(name, n1, n2) can extend on both paragraph [l, b] and paragraph
- [b+1, h]
- rhel_rel(name, n1, n2) rr1∩ rr2
- The above name relation is isoparactic (paratactic).
Then
- It is possible to combine the segment [l, b] and the segment [b+1, h] into a larger segment [l, h] whose state is the nucleus, the relationship type name, the prominent set is p1 ∪ p2 (p1 is the prominent set of [l, b], p2 being the prominent set of [b+1, h]), has two subtrees, tree1 and tree2.
- The current relation set will be rr1∩ rr2 {rhel_rel(name, l, n1, n2)
Choosing a Discourse Tree Similar to English, Vietnamese is a language with a left-to-right writing style. Vietnamese utterances tend to put the important clause first. Therefore, the thesis has followed the assessment of Marcu’s discourse tree in [89] in favor of left-skewed trees according to the following criteria:

In Figure 3.13 below are examples of discourse trees. The left-skewed tree has the value 1 as the maximum value. That represents a left-skewed tree preference.
The tree is balanced with w = 0 .
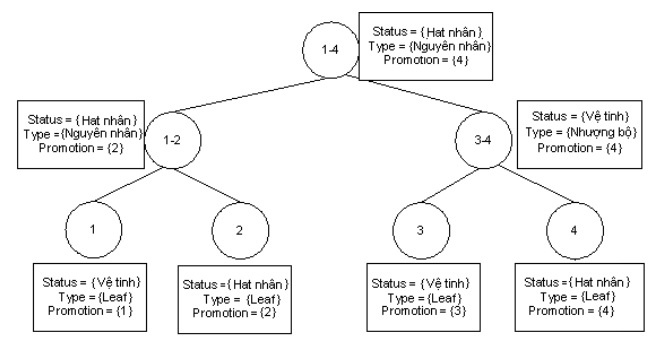
Left-skewed tree with w = 1
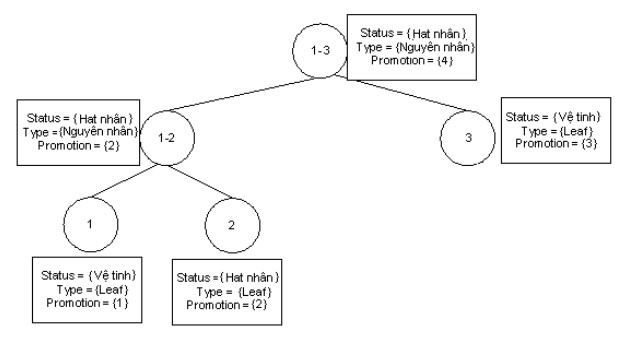
Right-skewed tree with w = -1
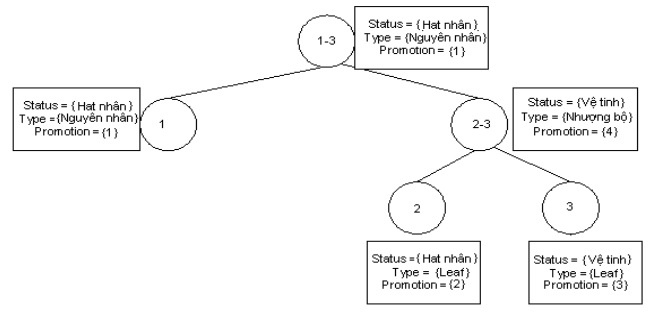
Figure 3.13. Discourse structure trees
3.2.2. Compound sentence parsing algorithm
The thesis has proposed an overall algorithm to parse a compound sentence represented as a sequence of words as follows:
Enter: Vietnamese sentence s separated from
Ra: Sentence analysis results include a list of connections
Method:
U [N] := Discourse_Segment(s);// U contains the discursive units of the sentence s
root := RS_Parse(); // The discourse parse tree of s has rootfor i:=1 to N
if Is_Unit (U[i])
{ Parse(U[i],LinkTemp);
Lnk.Add LinkTemp;
}
Insert_Link_From_RST_Tree(root);
After_Insert();
Figure 3.14. Parsing algorithm for compound sentences
In this algorithm,
- The variable Lnk contains all the links for the whole compound sentence. The LinkTemp variable contains the links for each clause.
- The Discourse_Segment function performs discourse segmentation for sentence s.
- The RS_Parse function allows building a tree to analyze the discourse of a sentence.
- The Is_Unit function returns true if the unit of discourse under consideration contains two or more words.
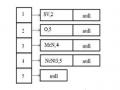
- Parse function is a parsing function, returns 1 if the sentence is syntactically correct, 0 otherwise. The result is saved in lnk. lnk has a structure as shown in Figure 3.16. Each list for each word is a linklist.
- The After_Insert function allows processing and linking with adverbial subordinate clauses: “yesterday”,”while”…
- The function Insert_Link_From_RST_Tree performs a traversal of the discourse tree of a sentence, adding links corresponding to each discourse relation.
Figure 3.15 below presents the function Insert_Link_From_RST_Tree proposed by the thesis.
In this function,
- The promotion attribute indicates the extent of the discursive relation to which clause in the sentence.
- The variable FirstWord returns the order of the word representing the first clause, LastWord returns the order of the word representing the second clause.
- The variable FirstMarker contains the discursive marker at the beginning of the text described by a subtree of the discursive tree, and the MidMarker contains the discursive marker in the middle of the text of the subtree of the discursive tree. Those two words need to be determined by the FindFirstMarker and FindMiddleMarker functions because depending on the processing, the discourse analysis algorithm may leave the discourse signature at the beginning or the end of the elemental discourse unit.
- The Represent function returns the word representing the clause under consideration.
- The IndexOfRepWord property returns the ordinal number of the word represented at the inner node of the discourse tree.
- The InsertLink function allows adding a relationship to the Linkage.
Insert_Link_From_RST_Tree (node)
{ if(IsLeaft(node) ) return;
InsertLinkFromRSTree(node.LeftChild);
InsertLinkFromRSTree(node.RightChild);
if (!IsLeaf(node))
if (IsLeaf(node.LeftChild) )
if(IsLeaf(node.RightChild)
{
FirstWord = Represent (node.LeftChild.promotion)
LastWord = Represent (node.RightChild.promotion)
}
else
{
FirstWord = Represent (node.LeftChild.promotion);
LastWord = node.RightChild. IndexOfRepWord;
}
else
if (IsLeaf(node.RightChild))
{FirstWord = node.LeftChild.IndexOfRepWord;
LastWord = Represent (node.RightChild.promotion);
}
else
{FirstWord = node.LeftChild. IndexOfRepWord;
LastWord = node.RightChild. IndexOfRepWord;
}
FirstMarker = FindFirstMarker (node);
MidMarker = FindMiddleMarker (node);
InsertLink(node, FirstWord, LastWord, FirstMarker, MidMarker,
node.Action);
}
}
Figure 3.15. Insert_Link_From_RST_Tree . function
3.2.3. Find words to connect clauses
If in the dependent grammar model, the word representing the main clause is from the center of the clause, then in the model of the linking grammar, it is necessary to choose the word that represents the clause.
Degree of connection Choosing a word to represent the proposition must ensure the demand for flatness of the association. After parsing for the clauses, the joins are stored again as a linked list.
Figure 3.16 below shows the link analysis storage structure of the sentence “I bought a flower”. 1, 2…5 is the ordinal number of the word. Each word has a linked list of connections with the words to its right. Information about each connection includes (type, destination, rank). For example (SV, 2, 0 ) indicates the association of the first word (“me”) and the second word (“buy”).