phương pháp tiếp cận nhân bản hoàn toàn là cấp quyền có thể được xử lý bằng kỹ thuật hiệu chỉnh truy vấn. Tuy nhiên việc quản lý thư mục sẽ tốn kém. Giải pháp lưu trữ tại các vị trí của các đối tượng cần truy xuất tốt hơn trong trường hợp tính chất cục bộ của tham chiếu rất cao.Tuy nhiên việc cấp quyền phân tán không thể kiểm soát được vào thời điểm biên dịch.
Khung nhìn có thể được coi mhư các đối tượng qua cơ chế cấp quyền. Khung nhìn được cấu tạo bởi các đối tượng cơ sở khác. Vì vậy khi trao quyền truy xuất đến một khung nhìn được dịch thành trao quyền truy xuất đến các đối tượng cơ sở. Nếu định nghĩa khung nhìn và các quy tắc cấp quyền được nhân bản hoàn toàn, thì việc phiên dịch khá đơn giản và được thực hiện tại chỗ. Phức tạp hơn khi định nghĩa khung nhìn và các đối tượng cơ sở của nó được lưu riêng thì phiên dịch sẽ là một thao tác hoàn toàn phân tán. cấp quyền được trao trên khung nhìn phụ thuộc vào quyền truy xuất của chủ nhân khung nhìn trên các đối tượng cơ sở. giải pháp ghi nhận thông tin liên kết tại các vị trí của mỗi đối tượng cơ sở.
Nhóm người sử dụng nghĩa là cấp quyền truy xuất chung cho nhiều người, với mục đích làm đơn giản hoá công việc quản lý cơ sở dữ liệu. Trong các hệ quản trị cơ sở dữ liệu tập trung, khái niệm mọi người sử dụng có thể đồng nhất với nhóm người sử dụng. Trong môi trường phân tán, mhóm người sử dụng biểu thị cho tất cả người sử dụng tại một vị trí cụ thể, được biểu thị public@site_s, là nhóm đặc biệt, được định nghĩa bởi lệnh sau:.
DEFINE GROUP
Vì trong môi trường phân tán, các chủ thể, các đối tượng phân tán tại nhiều vị trí khác nhau và quyền truy xuất thông tin đến một đối tượng có thẩuto cho nhiều nhóm phân tán khác nhau. Vì vậy vấn đề quản lý nhóm trong môi trường phân tán có một số vấn đề cần giải quyết. Nếu thông tin của nhóm và các quy tắc cấp quyền được nhân bản hoàn toàn tại tất cả các vị trí, thì việc duy trì quyền truy xuất tương tự như trong các hệ thống tập trung. Tuy nhiên việc duy trì các bản sao là tốn kém. Việc kiểm soát phi tập trung, tức là duy trì sự hoạt động tự trị vị trí sẽ khó khăn và phức tạp hơn rất nhiều.
Nhân bản hoàn toàn cho các thông tin cấp quyền có ưu điểm là kiểm soát cấp quyên đơn giản hơn và có thể thực hiện vào lúc biên dịch. Tuy nhiên, chi phí cho việc quản lý phân tán sẽ quá cao, nếu có rất nhiều vị trí trong hệ thống.
3.7.3. Kiểm soát tính toàn vẹn ngữ nghĩa
Một vấn đề quan trọng và khó khăn cho một hệ CSDL là bảo đảm được tính nhất quán cơ sở dữ liệu (Databasse Consistency). Một trạng thái CSDL được gọi là nhất quán nếu nó thỏa một tập các ràng buộc, được gọi là ràng buộc toàn vẹn ngữ nghĩa (Semantic Integrity Constrsint). Đảm bảo tính nhất quán của CSDL, kiểm soát toàn
Có thể bạn quan tâm!
-

 Cơ sơ dữ liệu phân tán - 20
Cơ sơ dữ liệu phân tán - 20 -
 Kiểm Tra Tính Đúng Đắn Khi Phân Mảnh Dọc
Kiểm Tra Tính Đúng Đắn Khi Phân Mảnh Dọc -
 Cơ sơ dữ liệu phân tán - 22
Cơ sơ dữ liệu phân tán - 22 -
 Đồ Thị Toán Tử Và Xác Đinh Biểu Thức Con Chung
Đồ Thị Toán Tử Và Xác Đinh Biểu Thức Con Chung -
 Đơn Giản Hóa Các Phép Kết Nối Giữa Các Quan Hệ Được Phân Mảnh Ngang Chính
Đơn Giản Hóa Các Phép Kết Nối Giữa Các Quan Hệ Được Phân Mảnh Ngang Chính -
 Sử Dụng Phép Suy Diễn Cho Các Phép Đơn Giản Hóa
Sử Dụng Phép Suy Diễn Cho Các Phép Đơn Giản Hóa
Xem toàn bộ 312 trang tài liệu này.
vẹn ngữ nghĩa bằng cách loại bỏ hoặc hoá giải các trình cập nhật làm cho CSDL không nhất quán. CSDL đã cập nhật nghĩa là đã thỏa tập các ràng buộc toàn vẹn.
Có hai loại ràng buộc toàn vẹn: ràng buộc cấu trúc ( Structural Constraint) và ràng buộc hành vi (Behavioral Constraint). Ràng buộc cấu trúc mô tả những đặc tính ngữ nghĩa cơ bản của mô hình. Ví dụ như ràng buộc khóa trong mô hình quan hệ, hoặc các liên kết một -nhiều giữa các đối tượng trong mô hình mạng. Ngược lại, ràng buộc hành vi mô tả mối liên kết giữa các đối tượng, như khái niệm phụ thuộc hàm trong mô hình quan hệ.
1) Kiểm soát toàn vẹn ngữ nghĩa tập trung
Một tiểu hệ thống kiểm soát toàn vẹn ngữ nghĩa có hai thành phần chính: một ngôn ngữ cho phép diễn tả và thao tác các phán đoán toàn vẹn, và một định chế chịu trách nhiệm thực hiện các hành động cụ thể nhằm ép buộc tính toàn ven khi có cập nhật.
a) Các loại ràng buộc: Bằng một ngôn ngữ cấp cao, người quản trị cơ sở dữ liệu có thể thiết lập được các ràng buộc toàn vẹn, khi tạo quan hệ hoặc khi quan hệ đã có dữ liệu, có chung một cú pháp. Ngôn ngữ này cho phép mô tả, ghi nhận hoặc loại bỏ ràng buộc toàn vẹn. Trong các hệ CSDL quan hệ, ràng buộc toàn vẹn được định nghĩa như là các phán đoán. Một phán đoán (Assertion) là một biểu thức đặc biệt được mô tả bằng phép tính quan hệ bộ, trong đó mỗi biến được lượng từ hóa với mọi (∀) hoặc tồn tại (∃). Vì vậy, một phán đoán có thể được xem như là một lượng từ hóa câu truy vấn, mang giá trị đúng hoặc sai cho mỗi bộ trong tích Đề các của các quan hệ được xác định bởi các biến bộ. Có ba loại ràng buộc toàn vẹn: ràng buộc tiền định, ràng buộc tiền dịch hoặc ràng buộc tổng quát.
b) Ép buộc thực thi ràng buộc: Ép buộc thực thi ràng buộc toàn vẹn nghĩa là thực hiện việc loại bỏ những chương trình cập nhật vi phạm một số ràng buộc nào đó. Một ràng buộc bị vi phạm do các hành động cập nhật hoặc do các phán đoán ràng buộc bị sai. Có hai phương pháp cơ bản cho phép loại bỏ các trình cập nhật phát sinh mâu thuẫn.
Phương pháp phát hiện mâu thuẫn (không nhất quán): Một thao tác cập nhật u được thi hành sẽ biến đổi CSDL từ trạng thái D sang trạng thái Du..Thuật toán ép buộc phải khẳng định rằng mọi ràng buộc liên quan vẫn đúng trong Du bằng cách áp dụng các ràng buộc này để kiểm tra. Nếu trạng thái Du không nhất quán, hệ quản trị CSDL sẽ chuyển sang một trạng thái Du‟ khác bằng cách hiệu chỉnh lại Du hoặc phải khôi phục lại trạng thái D. Vì những kiểm tra này được áp dụng sau khi trạng thái của CSDL đã thay đổi nên được gọi là kiểm tra sau (Posttest). Phương pháp này
sẽ không hiệu quả nếu hệ thống phản hồi lại rất nhiều thao tác khi ràng buộc bị vi phạm.
Phương pháp ngăn chặn mâu thuẫn: Một thao tác chỉ được thực hiện nếu nó chuyển CSDL sang một trạng thái nhất quán khác. Các bộ cần cập nhật đã có sẵn (trong trường hợp chèn) hoặc phải truy nhập trong CSDL (trường hợp xóa hoặc hiệu chỉnh). Thuật toán ép buộc xác nhận rằng tất cả các ràng buộc có liên đới đều đúng sau khi cập nhật các bộ. Nói chung, nó được thực hiện bằng cách áp dụng các kiểm tra có được từ các ràng buộc cho các bộ. Như vậy, các kiểm tra được áp dụng trước khi trạng thái của CSDL bị thay đổi, nên gọi là các kiểm tra trước (Pretest). Phương pháp ngăn chặn này hiệu quả hơn phương pháp phát hiện vì không bao giờ phải hồi lại các thao tác cập nhật do ràng buộc bị vi phạm.
Thuật toán hiệu chỉnh truy vấn là một ví dụ về phương pháp ngăn chặn, có hiệu quả đặc biệt trong việc ép buộc các ràng buộc miền biến thiên. Nó đưa thêm lượng từ hóa phán đoán vào lượng từ hóa truy vấn bằng toán tử AND, vì thể câu truy vấn được hiệu chỉnh có thể được ép buộc toàn vẹn.
2) Kiểm soát toàn vẹn ngữ nghĩa phân tán
Các thuật toán đảm bảo tính toàn vẹn ngữ nghĩa của các CSDL phân tán, được mở rộng từ các phương pháp đơn giản trong phần kiểm soát toàn vẹn ngữ nghĩa tập trung. Giả thiết các thuật toán có tính đến yếu tố tự trị vị trí, nghĩa là mỗi vị trí có thể xử lý các câu truy vấn cục bộ và thực hiện việc kiểm soát dữ liệu như một hệ quản trị CSDL tập trung. Giả thiết này làm đơn giản việc mô tả phương pháp. Hai vấn đề chính của thiết kế một tiểu hệ thống kiểm soát toàn vẹn trong một hệ quả trị CSDL phân tán, đó là vấn đề định nghĩa và lưu trữ các phán đoán và vấn đề ép buộc thi hành các phán đoán này..
Định nghĩa các phán đoán toàn vẹn phân tán: Giả sử một phán đoán toàn vẹn được diễn tả bằng phép tính quan hệ bộ. Mỗi phán đoán được coi là một lượng từ hóa truy vấn, trong đó nó nhận giá trị đúng hoặc sai với mỗi bộ trong tích Đề các của các quan hệ được xác định bằng các biến bộ. Các phán đoán có thể liên quan đến dữ liệu lưu trên nhiều vị trí khác nhau. Vì vậy chọn vị trí lưu trữ phán đoán sao cho giảm thiểu chi phí kiểm tra toàn vẹn. Một chiến lược phán đoán toàn vẹn chia ra ba lớp:
Phán đoán riêng: là các phán đoán đơn biến đơn quan hệ. Chỉ đề cập đến các bộ được cập nhật, độc lập với phần còn lại của CSDL. Ràng buộc miền giá trị của ví dụ “Ngân sách của một dự án trong khoảng 500000 đến 1000000” là một phán đoán riêng. Phán đoán hướng tập hợp: Bao gồm các ràng buộc đa biến đơn quan hệ như phụ thuộc hàm (mã số nhân viên xác định tên nhân viên) và đa biến đa quan hệ như các
ràng buộc khóa ngoại.
Phán đoán có các hàm gộp: Đòi hỏi phải được xử lý đặc biệt do chi phí ước lượng hàm gộp.
Định nghĩa một phán đoán toàn vẹn có thể được bắt đầu tại một vị trí có lưu các quan hệ trong phán đoán. Quan hệ có thể bị phân mảnh, một vị từ phân mảnh là một trường hợp đặc biệt của phán đoán thuộc lớp 1. Các mảnh khác nhau của một quan hệ có thể có trên nhiều vị trí khác nhau. Vì vậy, định nghĩa một phán đoán toàn vẹn sẽ là một thao tác phân tán và được thực hiện qua hai bước. Bước đầu tiên biến đổi các phán đoán ở cấp cao thành các phán đoán biên dịch. Bước tiếp theo là lưu trữ các phán đoán này tùy theo lớp phán đoán. Các phán đoán thuộc lớp 3 được xử lý giống như các phán đoán thuộc lớp 1 hoặc 2, tùy thuộc vào đặc tính của chúng là riêng hay theo tập hợp.
Phán đoán riêng: Định nghĩa phán đoán được gửi đến tất cả vị trí lưu trữ mảnh của quan hệ có mặt trong phán đoán. Phán đoán phải tương thích với dữ liệu của quan hệ tại mỗi vị trí. Tính tương thích có thể được kiểm tra ở hai cấp: cấp vị từ và cấp dữ liệu.
Trước tiên, tương thích vị từ được xác nhận bằng cách so sánh vị từ phán đoán với vị từ mảnh. Một phán đoán C được coi là không tương thích với vị từ mảnh p nếu “C đúng” dẫn đến “p sai”, và ngược lại thì được coi là tương thích. Nếu không tương thích tại một vị trí, định nghĩa phán đoán phải bị loại bỏ ở mức toàn cục vì các bộ của mảnh đó không thỏa mãn ràng buộc toàn vẹn này. Nếu có tương thích vị từ, phán đoán sẽ được kiểm tra ứng với thể hiện của mảnh. Nếu thể hiện đó không thỏa mãn phán đoán thì nó cũng bị loại bỏ ở mức toàn cục. Nếu tương thích, phán đoán sẽ được lưu lại tại mỗi vị trí. Việc kiểm tra tính tương thích được thực hiện cho các phán đoán biên dịch với kiểu cập nhật là “chèn” (các bộ trong các mảnh coi như là “được chèn vào”).
Phán đoán hướng tập hợp: Phán đoán hướng tập hợp thuộc loại đa quan hệ, nghĩa là có các vị từ kết nối. Tuy nhiên mỗi phán đoán biên dịch chỉ được liên kết với một quan hệ. Vì vậy định nghĩa phán đoán có thể được gửi đến tất cả các vị trí chứa các mảnh được các biến này tham chiếu. Việc kiểm tra tính tương thích bao gồm các mảnh của quan hệ được sử dụng trong vị từ nối. Tương thích vị từ sẽ không có tác dụng vì không thể suy một vị từ mảnh P sai nếu phán đoán C (dựa trên vị từ kết nối) là đúng. Vì vậy, cần phải kiểm tra C theo dữ liệu, đòi hỏi phải nối mỗi mảnh của quan hệ R với tất cả các mảnh của quan hệ S, là hai quan hệ có trong vị từ kết nối. Như vậy chi phí sẽ rất cao như các phép kết nối. Cần phải tối ưu hóa bằng cách xử lý truy vấn phân tán. Ba tình huống theo mức chi phí có thể xảy ra:
- Các mảnh của R được dẫn xuất từ các mảnh của S dựa vào một kết nối nửa trên thuộc tính được dùng trong vị từ kết nối. Trong trường hợp này kiểm tra tương thích có chi phí thấp vì bộ của S đối sánh được với một bộ của R sẽ ở cùng một vị trí.
- S được phân mảnh trên thuộc tính kết nối. Mỗi bộ của R phải được so sánh với tối đa một mảnh của S, vì giá trị thuộc tính nối của bộ thuộc R có thể được dùng để tìm vị trí mảnh tương ứng của S.
- S không được phân mảnh trên thuộc tính kết nối. Mỗi bộ của R phải được so sánh với tất cả các bộ của R đều được đảm bảo tương thích thì phán đoán sẽ được lưu lại tại mỗi vị trí.
Chương 4
BIẾN ĐỔI CÁC TRUY VẤN TOÀN CỤC THÀNH CÁC TRUY VẤN MẢNH
Một thao tác truy xuất trong một ứng dụng có thể được biểu diễn như là một truy vấn tham chiếu đến các quan hệ toàn cục. DDBMS phải biến đổi truy vấn này thành các truy vấn đơn giản hơn mà chúng chỉ tham chiếu đến các mảnh. Chương này giải quyết phép biến đổi này.
Có nhiều cách khác nhau để biến đổi một truy vấn trên các quan hệ toàn cục được gọi là truy vấn toàn cục (global query) thành các truy vấn trên các mảnh được gọi là truy vấn mảnh (fragment query). Các biến đổi khác nhau này tạo ra các truy vấn mảnh tương đương theo nghĩa chúng tạo ra cùng kết quả. Vì lí do này, chương này cũng giải quyết các phép biến đổi tương đương (equivalence transformation), nghĩa là các quy tắc có thể được áp dụng cho một truy vấn để viết truy vấn này thành một biểu thức tương đương.
Các quy tắc tương đương được sử dụng để đơn giản hóa biểu thức truy vấn (query expression). Ví dụ xác định các biểu thức con chung và các phép toán được “phân tán” cho các mảnh. Tuy nhiên, điều nhấn mạnh trong chương này là tính đầy đủ (completeness) và tính đúng đắn (correctness) của phép biến đổi. Mục tiêu của chúng ta là đưa ra một tập hợp các quy tắc biến đổi tương đương và bao quát tất cả các khía cạnh liên quan đến các phép biến đổi truy vấn.
Các nội dung chính trong chương này:
- Các kỹ thuật được sử dụng trong các hệ thống tập trung để biến đổi truy vấn. Trước tiên, chúng ta đưa ra cách biểu diễn truy vấn bằng cách sử dụng một cây truy vấn (query tree). Sau đó chúng ta đưa ra một cách tiếp cận về ngữ nghĩa cho các phép biến đổi tương đương và cuối cùng cho thấy cách biến đổi một cây truy vấn thành một đồ thị truy vấn (query graph) để xác định các biểu thức con chung trong một truy vấn. Ở đây, chúng ta đưa ra nhiều nhắc nhở này bởi vì nó liên hệ chặt chẽ với những gì đi theo sau. Hơn nữa, các khía cạnh này trong các CSDL phân tán càng quan trọng hơn so với trong các CSDL tập trung và phép biến đổi truy vấn được đưa vào trong các môi trường phân tán.
Các truy vấn toàn cục được biến đổi thế nào thành các truy vấn mảnh. Chúng ta nêu ra một ánh xạ chuẩn tắc (canomical mapping) và cho thấy ánh xạ chuẩn tắc là đúng đắn. Sau đó, chúng ta sử dụng các phép biến đổi tương đương để biến đổi biểu thức chuẩn tắc (canomical mapping) của truy vấn. Cơ sở của các phép biến đổi này là áp dụng các phép toán đại số (algebraic operation). Chẳng hạn phép chiếu và phép
chọn, để làm giảm kích thước của các toán hạng của chúng càng nhiều càng tốt trên mỗi mảnh trước khi truyền dữ liệu giữa các nơi.
Các truy vấn có liên quan đến cách đánh giá của việc gom nhóm từng phần: mệnh đề GROUP BY của lệnh SELECT và các hàm kết hợp (aggregate function). Chúng ta mở rộng đại số quan hệ (relational algebra) để bao quát các vấn đề này, và sau đó nêu ra một số phép biến đổi tương đương áp dụng cho các phép toán mới. Cơ sở của các phép toán này là phân tán việc xử lý đến các mảnh.
Các truy vấn tham số (parametric query), nghĩa là các truy vấn này có chứa các điều kiện chọn bao gồm các tham số mà giá trị sẽ được xác định ở thời gian thực hiện. Các truy vấn là các thao tác truy xuất cơ bản tiêu biểu trong các ứng dụng tham số (parametric application) như được nêu ra trong chương 2. Chúng ta nêu ra các biện pháp biến đổi tương đương có thể được sử dụng như thế nào để cải tiến tính hiệu quả của chúng.
4.1. Các phép biến đổi tương đương dùng cho các truy vấn
Một truy vấn quan hệ (relational query) có thể được biểu diễn bằng cách sử dụng các ngôn ngữ khác nhau. Ở đây, chúng ra sử dụng đại số quan hệ và ngôn ngữ SQL cho mục đích này. Hầu hết các truy vấn SQL đều có thể đựơc biến đổi thành các biểu thức đại số quan hệ tương đương và ngược lại. Do đó, bất kỳ các ngôn ngữ nêu trên có thể được sử dụng để biểu diễn ngữ nghĩa của truy vấn. Tuy nhiên, chúng ta có thế diễn dịch một biểu thức quan hệ đại số (expression of relational algebra) không chỉ là sự đặc tả ngữ nghĩa của một truy vấn, mà còn là sự đặc tả của một chuỗi các phép toán) sequence of operations). Từ quan điểm này, hai biểu thức có cùng ngữ nghĩa có thể mô tả hai chuỗi phép toán khác nhau.
Ví dụ 4.1:
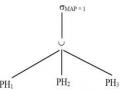
MANV, MAQL MAP=1 (NV) và MAP=1 MANV, MAQL (NV)
là các biểu thức tương đương nhưng định nghĩa hai chuỗi phép toán khác nhau. Trong chương này, vì chúng ta quan tâm đến thứ tự thực hiện của các phép toán,
bắt đầu từ việc sử dụng các biểu thức đại số quan hệ ban đầu và phân tích các phép biến đổi tương đương của chúng.
4.1.1. Cây toán tử của một truy vấn
1) Mục đích:
- Dùng để biểu diễn các truy vấn
- Giúp theo dòi các thao tác trên biểu thức
- Xác định một thứ tự bộ phận mà trong đó các phép toán phải được thực hiện cho ra kết quả của truy vấn.
2) Cấu tạo cây:
- Nút lá: chứa các quan hệ toàn cục
- Các nút trung gian và nút gốc: biểu diễn
+ phép toán một ngôi (unary operation)
+ phép toán hai ngôi (binary operation)
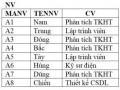
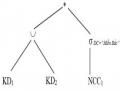
Ví dụ 4.2: Xét hệ thống quản lý kinh doanh của một công ty trong ví dụ 2.13 và có một ứng dụng: Đưa ra mã của nhà cung cấp đã cung cấp hàng mà có địa chỉ ở Nam Định.
Truy vấn Q1 tương ứng với biểu thức đại số quan hệ:
Q1: MANCC (DC= “Nam Định” (NCC >< MANCC = MANCC KD))
Cây toán tử của truy vấn Q1:
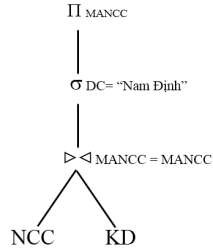
Cây toán tử của một biểu thức đại số quan hệ có thể được xem như một cây phân tích cú pháp (pharse tree) của chính biểu thức đó, giả sử có văn phạm sau đây:
R identifier
R (R)
R un_op R un_op F A
bin_op - F <F <
Để dễ biểu diễn, chúng ta loại bỏ trong cây phân tích cú pháp các dấu ngoặc trong luật sinh thứ hai và chúng được thể hiện bởi cấu trúc của cây toán tử.
4.1.2. Các phép biến đổi tương đương dùng cho đại số quan hệ
1) Quan hệ tương tương
Hai quan hệ là tương đương khi các bộ của chúng biểu diễn cùng ánh xạ từ các tên thuộc tính vào các giá trị ngay cả khi thứ tự của các thuộc tính là khác nhau.
2) Biểu thức tương đương