,762 | |||||
RR2 | ,757 | ||||
RR3 | ,757 | ||||
GS1 | ,837 | ||||
GS4 | ,806 | ||||
GS5 | ,781 | ||||
GS3 | ,778 | ||||
GS2 | ,685 |
Có thể bạn quan tâm!
-

 Các Biến Qs Đo Lường Tính Hh Của Hoạt Động Của Các Nhtm
Các Biến Qs Đo Lường Tính Hh Của Hoạt Động Của Các Nhtm -
 Thống Kê Tần Số Thang Đo Tính Hh Của Hđkd Tại Các Nhtm
Thống Kê Tần Số Thang Đo Tính Hh Của Hđkd Tại Các Nhtm -
 Kết Quả Phân Tích Đánh Giá Độ Tin Cậy Của Thang Đo Tính Hh Của Hđkd Tại Các Nhtm
Kết Quả Phân Tích Đánh Giá Độ Tin Cậy Của Thang Đo Tính Hh Của Hđkd Tại Các Nhtm -
 Tầm Quan Trọng Của Các Nhân Tố Ảnh Hưởng Đến Tính Hh Của Hđkd Tại Các Nhtm Tại Tỉnh Vĩnh Long
Tầm Quan Trọng Của Các Nhân Tố Ảnh Hưởng Đến Tính Hh Của Hđkd Tại Các Nhtm Tại Tỉnh Vĩnh Long -
 Bubilek, O. (2017). Importance Of Internal Audit And Internal Control In An Organization-Case Study
Bubilek, O. (2017). Importance Of Internal Audit And Internal Control In An Organization-Case Study -
 Các nhân tố kiểm soát nội bộ ảnh hưởng đến tính hữu hiệu của hoạt động kinh doanh tại các ngân hàng thương mại tại tỉnh Vĩnh Long - 13
Các nhân tố kiểm soát nội bộ ảnh hưởng đến tính hữu hiệu của hoạt động kinh doanh tại các ngân hàng thương mại tại tỉnh Vĩnh Long - 13
Xem toàn bộ 159 trang tài liệu này.
(Nguồn: Kết quả phân tích dữ liệu từ phần mềm SPSS 20.0)
b. Thang đo tính HH của HĐKD tại các NHTM
Sau khi đánh giá giá trị thang đo các nhân tố của HTKSNB, tác giả tiến hành đánh giá giá trị thang đo tính HH của HĐKD tại các NHTM. Theo bảng 4.27 ta thấy, thang đo tính HH của HĐKD tại các NHTM có giá trị KMO = 0,622 > 0,5 và Sig. = 0,000 < 0,05 nên việc sử dụng phân tích EFA để đánh giá giá trị thang đo này là thích hợp.
Bảng 4.27. Kiểm định KMO và Bartlett cho thang đo tính HH của HĐKD tại các NHTM
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. | ,622 | |
Bartlett's Test of Sphericity | Approx. Chi-Square | 127,528 |
Df | 3 | |
Sig. | ,000 | |
(Nguồn: Kết quả phân tích dữ liệu từ phần mềm SPSS 20.0)
Bảng 4.28. Bảng phương sai trích cho thang đo tính HH của HĐKD tại các NHTM
Component | Initial Eigenvalues | Extraction Sums of Squared Loadings | ||||
Total | % of Variance | Cumulative % | Total | % of Variance | Cumulative % | |
1 | 1,899 | 63,305 | 63,305 | 1,899 | 63,305 | 63,305 |
2 | ,689 | 22,978 | 86,284 | |||
3 | ,411 | 13,716 | 100,000 | |||
(Nguồn: Kết quả phân tích dữ liệu từ phần mềm SPSS 20.0)
Theo bảng 4.28, giá trị Eigenvalue = 1,899 > 1 thì số nhân tố rút ra có ý nghĩa tóm tắt thông tin tốt nhất nên số nhân tố được trích là 1 nhân tố. Phương sai trích (Rotation Sums of Squared Loadings (Cumulative %) ) là 63,307% > 50% là đạt yêu cầu. Điều này chứng tỏ 63,307% biến thiên của dữ liệu được giải thích bởi 1 nhân tố duy nhất là phù hợp.
Bảng 4.29. Bảng ma trận cho thang đo tính HH của HĐKD tại các NHTM
Component | |
1 | |
HH2 | ,866 |
HH1 | ,772 |
HH3 | ,744 |
(Nguồn: Kết quả phân tích dữ liệu từ phần mềm SPSS 20.0)
Thang đo tính HH của HĐKD tại các NHTM bao gồm 3 biến QS và cả 3 biến QS này đều có hệ số tải nhân tố lớn hơn 0,5, điều này thể hiện các biến QS đều có ý nghĩa trong thực tiễn.
Kết luận, sau khi phân tích nhân tố khám phá EFA thu được kết quả như sau:
- Thang đo các thành phần của HTKSNB gồm 5 nhân tố, cụ thể:
Nhân tố MTKS gồm 7 biến QS là MT1, MT2, MT3, MT4, MT5, MT6 và MT7;
Nhân tố ĐGRR gồm 6 biến QS là RR1, RR2, RR3, RR4, RR5 và RR6;
Nhân tố TT & TT gồm 7 biến QS là TT1, TT2, TT3, TT4, TT6, TT7 và TT8;
Nhân tố HĐKS gồm 8 biến QS là KS1, KS2, KS3, KS4, KS5, KS6, KS8 và KS9;
Nhân tố GS gồm 5 biến QS là GS1, GS2, GS3, GS4 và GS5.
- Thang đo tính HH của HĐKD tại các NHTM gồm 1 nhân tố với 3 biến QS là HH1, HH2 và HH3.
4.1.5. Phân tích tương quan
Trước khi tiến hành kiểm định hồi quy thì cần phải phân tích tương quan giữa các biến độc lập và biến phụ thuộc để kiểm định mối quan hệ tuyến tính giữa các biến này.
Hệ số tương quan Pearson (r) nhận giá trị từ -1 đến +1. Điều kiện tương quan có ý nghĩa là giá trị Sig. < 0,05.
r = 0, có nghĩa là 2 biến không có sự tương quan;
r = 1 hoặc r = -1, có nghĩa là 2 biến có mối quan hệ tuyệt đối; r < 0, có sự tương quan nghịch giữa 2 biến;
r > 0, có sự tương quan thuận giữa 2 biến (Võ Thị Hồng Vi, 2017).
Bảng 4.30. Bảng phân tích tương quan giữa các biến độc lập và biến phụ thuộc
HH | KS | MT | RR | TT | GS | ||
HH | Pearson Correlation | 1 | ,414** | ,589** | ,306** | ,225** | ,187** |
Sig. (2-tailed) | ,000 | ,000 | ,000 | ,001 | ,007 | ||
KS | Pearson Correlation | ,414** | 1 | -,022 | ,027 | ,097 | ,236** |
Sig. (2-tailed) | ,000 | ,752 | ,697 | ,161 | ,001 | ||
MT | Pearson Correlation | ,589** | -,022 | 1 | -,036 | ,010 | ,003 |
Sig. (2-tailed) | ,000 | ,752 | ,601 | ,884 | ,962 | ||
RR | Pearson Correlation | ,306** | ,027 | -,036 | 1 | ,159* | -,030 |
Sig. (2-tailed) | ,000 | ,697 | ,601 | ,022 | ,665 | ||
TT | Pearson Correlation | ,225** | ,097 | ,010 | ,159* | 1 | ,129 |
Sig. (2-tailed) | ,001 | ,161 | ,884 | ,022 | ,062 | ||
GS | Pearson Correlation | ,187** | ,236** | ,003 | -,030 | ,129 | 1 |
Sig. (2-tailed) | ,007 | ,001 | ,962 | ,665 | ,062 | ||
**. Correlation is significant at the 0,01 level (2-tailed). | |||||||
*. Correlation is significant at the 0,05 level (2-tailed). | |||||||
(Nguồn: Kết quả phân tích dữ liệu từ phần mềm SPSS 20.0)
Từ phân tích tương quan giữa các biến, ta thấy rằng 5 biến độc lập là MTKS, ĐGRR, TT & TT, HĐKS và GS có mối quan hệ tương quan dương với biến phụ thuộc là tính HH của HĐKD tại các NHTM với mức ý nghĩa thống kê 1%. Cụ thể, hệ số tương quan của các biến độc lập so với biến phụ thuộc biến thiên từ 0,187 đến 0,589, trong đó biến MTKS có mức độ tương quan cao nhất với biến tính HH của HĐKD tại các NHTM có hệ số là 0,589 và biến GS có mức độ tương quan thấp nhất với hệ số là 0,187. Như vậy, các biến độc lập đều có mối tương quan tích cực đến biến phụ thuộc và có thể đưa vào để phân tích mô hình hồi quy.
4.1.6. Kiểm tra các giả định trong mô hình
Để kết quả phân tích hồi quy có ý nghĩa thì một số giả định cần được đảm bảo. Các giả định bao gồm giả định quan hệ tuyến tính, giả định phương sai các sai số không đổi, giả định về phân phối chuẩn của phần dư và giả định không vi phạm hiện tượng đa cộng tuyến. Tác giả sẽ tiến hành kiểm định từng giả định, kết quả như sau:
4.1.6.1. Giả định quan hệ tuyến tính
Tác giả sử dụng đồ thị phân tán giữa các phần dư đã được chuẩn hóa (Standardized residual) và giá trị dự đoán chuẩn hóa (Standardized predicted valued) mà mô hình hồi qui tuyến tính cho ra để kiểm định mối quan hệ tuyến tính giữa các biến độc lập và biến phụ thuộc (Hoàng Trọng và Chu Nguyễn Mộng Ngọc, 2008).
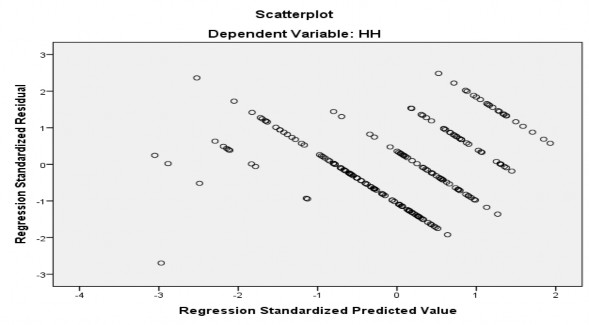
Hình 4.1. Đồ thị phân tán giữa phần dư chuẩn hóa và giá trị dự đoán chuẩn hóa
(Nguồn: Kết quả phân tích dữ liệu từ phần mềm SPSS 20.0)
Hình 4.1 cho thấy rằng phần dư phân tán rất ngẫu nhiên, phần dư chuẩn hóa phân bổ tập trung xung quanh đường tung độ 0 chứ không tạo thành một hình dạng nào. Điều này chứng mình không có mối quan hệ nào giữa phần dư và giá trị dụ đoán của mô hình (Hoàng Trọng và Chu Nguyễn Mộng Ngọc, 2008), vì vậy giả định quan hệ tuyến tính không bị vi phạm.
4.1.6.2. Giả định phương sai của sai số không đổi
Bảng 4.31. Bảng kiểm định giả định phương sai của sai số (phần dư)
Minimum | Maximum | Mean | Std. Deviation | N | |
Std. Predicted Value | -3,052 | 1,931 | ,000 | 1,000 | 209 |
Std. Residual | -2,697 | 2,483 | ,000 | ,988 | 209 |
(Nguồn: Kết quả phân tích dữ liệu từ phần mềm SPSS 20.0)
Từ kết quả ở bảng 4.31 ta thấy độ lớn của phần dư không thay đổi theo giá trị dự đoán. Đồng thời, kết hợp với hình 4.1, các phần dư phân bổ tập trung xung quanh đường tung độ, tức có nghĩa là quanh giá trị trung bình của phần dư trong một phạm vi không đổi. Vì vậy, phương sai của sai số không đổi.
4.1.6.3. Giả định về phân phối chuẩn của phần dư
Tác giả tiến hành kiểm định phân phối chuẩn của phần dư vì nếu như phần dư không tuân theo giả định phân phối chuẩn thì mô hình NC được sử dụng có thể không đúng, lúc này phương sai không phải là hằng số và số lượng phần dư không đủ nhiều để phân tích (Hoàng Trọng và Chu Nguyễn Mộng Ngọc, 2008). Trong NC này tác giả sử dụng 2 đồ thị để đánh giá phân phối chuẩn của phần dư là đồ thị P-P plot và đồ thị Histogram.
Theo đồ thị P- P plot ở hình 4.2, các điểm phân vị trong phân phối của phần dư tập trung thành 1 đường thẳng kỳ vọng. Như vậy, giả định phân phối chuẩn của phần dư không bị vi phạm. Đồng thời, theo đồ thị Histogram ở hình 4.3 cho thấy đường cong phân phối chuẩn có dạng hình chuông phù hợp với dạng đồ thị của phân phối chuẩn. Giá trị trung bình gần bằng 0, độ lệch chuẩn là 0,988 gần bằng 1, như vậy có thể nói, phân phối phần dư xấp xỉ chuẩn. Do đó, có thể kết luận rằng giả thiết phân phối chuẩn của phần dư không bị vi phạm.
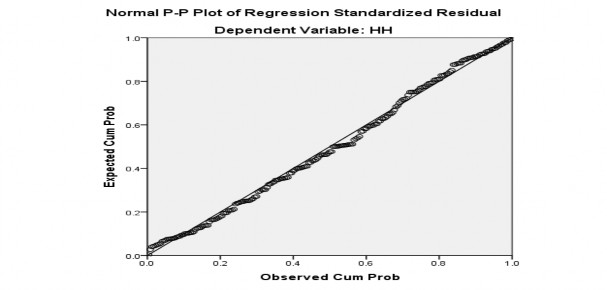
Hình 4.2. Đồ thị P-P plot của phần dư đã chuẩn hóa
(Nguồn: Kết quả phân tích dữ liệu từ phần mềm SPSS 20.0)
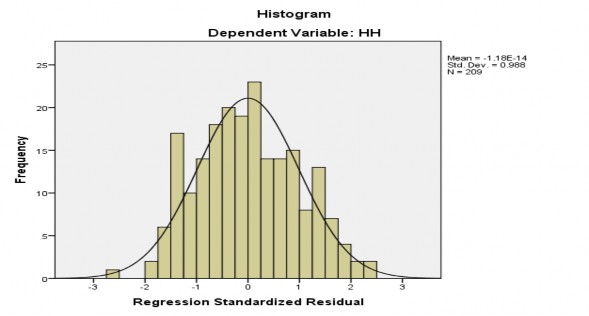
Hình 4.3. Đồ thị Histogram của phần dư – đã chuẩn hóa
(Nguồn: Kết quả phân tích dữ liệu từ phần mềm SPSS 20.0)
4.1.6.4. Giả định không có hiện tượng đa cộng tuyến
Đa cộng tuyến là hiện tượng xảy ra khi các biến độc lập trong mô hình có tương quan hoàn toàn với nhau. Để kiếm tra giả định này, tác giả sử dụng hệ số phóng đại phương sai VIF, khả năng đa cộng tuyến sẽ giảm khi hệ số phóng đại phương sai càng nhỏ (Nguyễn Đình Thọ, 2013). Từ bảng 4.32 ta thấy, không có nhân tố nào bị loại bỏ do Sig. kiểm định t của từng biến độc lập đều nhỏ hơn 0,05 và hệ số VIF các biến độc lập đều nhỏ hơn 2, như vậy không có đa cộng tuyến xảy ra. Do đó mối quan hệ giữa các biến độc lập không ảnh hưởng đáng kể đến kết quả giải thích của mô hình hồi quy.
Bảng 4.32. Bảng hệ số phóng đại phương sai - VIF
Unstandardized Coefficients | Standardized Coefficients | t | Sig. | Collinearity Statistics | ||||
B | Std. Error | Beta | Tolerance | VIF | ||||
1 | (Constant) | -,219 | ,250 | -,879 | ,381 | |||
KS | ,323 | ,036 | ,386 | 9,056 | ,000 | ,938 | 1,066 | |
TT | ,088 | ,030 | ,123 | 2,895 | ,004 | ,953 | 1,050 |
MT | ,386 | ,026 | ,607 | 14,673 | ,000 | ,998 | 1,002 |
RR | ,212 | ,030 | ,301 | 7,163 | ,000 | ,970 | 1,031 |
GS | ,052 | ,026 | ,087 | 2,020 | ,045 | ,930 | 1,076 |
(Nguồn: Kết quả phân tích dữ liệu từ phần mềm SPSS 20.0)
4.1.7. Kết quả kiểm định mô hình hồi quy
Kiểm định mô hình hồi quy bội nhằm kiểm định các giả thuyết NC với phương pháp khẳng định (phương pháp ENTER) kết hợp với phương pháp OLS (Ordinary Least Square) trong việc ước lượng các tham số của đám đông từ dữ liệu mẫu.
4.1.7.1. Kiểm định R2 hiệu chỉnh (Adjusted R Square ) và hệ số DW (Durbin- Watson)
R2 hiệu chỉnh dùng để phán ánh khả năng giải thích của mô hình đối với sự biến thien của biến phụ thuộc, R2 hiệu chỉnh có giá trị từ 50% trở lên là NC có thể sử dụng. DW dùng để kiểm định sự tương quan của các sai số kề nhau, có sự biến thiên từ 0 đến 4; nếu giá trị DW gần bằng 2 (từ 1 đến 3) thì các phần sai số không có tương quan chuỗi bậc nhất với nhau, dữ liệu thu thập được là tốt; nếu giá trị DW càng nhỏ, gần bằng 0 thì các phần sai số có tương quan thuận; nếu giá trị DW càng lớn, càng gần bằng 4 thì các phần sai số có tương quan nghịch (Võ Thị Hồng Vi, 2017).
Bảng 4.33 cho thấy, R2 hiệu chỉnh = 0,645 có nghĩa là 64,5%, có nghĩa là mô hình có khả năng giải thích 64,5% sự biến thiên của biến phụ thuộc là tính HH của HĐKD tại các NHTM. Đồng thời, hệ số DW = 2,006 có giá trị gần bằng 2 nên không có sự tương quan chuỗi bậc nhất. Vì vậy, dữ liệu NC thu thập được là tốt và phù hợp với mô hình NC.
Bảng 4.33. Bảng tóm tắt mô hình hồi quy
Model | R | R Square | Adjusted R Square | Std. Error of the Estimate | Durbin- Watson |
1 | ,808a | ,653 | ,645 | ,23525 | 2,006 |
a. Predictors: (Constant), GS, MT, RR, TT, KS | |||||
b. Dependent Variable: HH | |||||