Y () X () D()
Chúng ta có thể biểu diễn Y( ) dưới dạng phức như sau:
Y () | Y () | e jy ()
Khi đó |Y( )| là biên độ phổ, và y () là pha của tín hiệu đã bị nhiễu. Phổ của tín hiệu nhiễu D() có thể được biểu diễn dạng biên độ và pha:
D() | D() | e jd ()
(3.2)
(3.3)
Có thể bạn quan tâm!
-

 Áp dụng thuật toán Wiener Filtering nâng cao chất lượng tiếng nói - 2
Áp dụng thuật toán Wiener Filtering nâng cao chất lượng tiếng nói - 2 -
 Mức Nhiễu Và Tiếng Nói (Được Đo Bằng Spl Db) Trong Các Môi Trường
Mức Nhiễu Và Tiếng Nói (Được Đo Bằng Spl Db) Trong Các Môi Trường -
 Thang Điểm Đánh Giá Chất Lượng Tiếng Nói Theo Mos
Thang Điểm Đánh Giá Chất Lượng Tiếng Nói Theo Mos -
 Thực Hiện Xử Lý Các File Âm Thanh Bị Nhiễu Với Snr =5Db
Thực Hiện Xử Lý Các File Âm Thanh Bị Nhiễu Với Snr =5Db -
 Áp dụng thuật toán Wiener Filtering nâng cao chất lượng tiếng nói - 7
Áp dụng thuật toán Wiener Filtering nâng cao chất lượng tiếng nói - 7 -
 Áp dụng thuật toán Wiener Filtering nâng cao chất lượng tiếng nói - 8
Áp dụng thuật toán Wiener Filtering nâng cao chất lượng tiếng nói - 8
Xem toàn bộ 69 trang tài liệu này.
(3.4)
Biên độ phổ của nhiễu |D( )| không xác định được, nhưng có thể thay thế bằng giá trị trung bình của nó được tính trong khi không có tiếng nói(tiếng nói bị dừng), và pha của tín hiệu nhiễu có thể thay thế bằng pha của tín hiệu bị nhiễu y () , việc làm này không ảnh hưởng đến tính dễ nghe của tiếng nói, có thể ảnh hưởng đến chất lượng
của tiếng nói là làm thay đổi pha của tiếng nói nhưng cũng chỉ vài độ.
Ta có thể ước lượng được biên độ của phổ tín hiệu sạch X () từ Y() bằng một hàm phi tuyến được xác định như sau :
G()
G() X () / Y ()
có thể được áp dụng theo Wiener Filtering:
E{ S() 2 }
(3.5)
Trong đó
Ps () và
G() (3.6)
E{ S() 2 } E{ D() 2 }
Pd () là phổ công suất của tin hiệu sạch.
Đặt Priori SNR và Posteriori SNR như sau:
E{ S() 2 }
SNRpri
E{ D() 2 }
(3.7)
SNRpost
E{Y () 2 }
2
(3.8)
E{ D() }
Một khó khăn trong các thuật toán nâng cao chất lượng tiếng nói là ta không có tín hiệu trước tín hiệu sạch s[n] nên ta không thể biết phổ của nó. Do đó ta không thể
tính được
SNRpri
mà trong các hệ thống nâng cao chất lượng giọng nói thì
SNRpri là
tham số rất cần thiết để ước lượng tín hiệu sạch.Trong các hệ thống nâng cao chất
lượng giọng nói có thể ước lượng được thích hợp vào các phương trình sau:
SNRpri và
SNR post
bằng cách cho các thông số
t t 1 2
P d () P d () (1 ) Dt ()
(3.9)
SNRpost
E{Y () 2 }
t
P d ()
^ t 1
S
2
()
(3.10)
t
t
(3.11)
SNRpri ( ) (1
) PSNRpost ( ) 1
P d ()
Trong đó P[.] là hàm chỉnh lưu bán sóng có dạng như sau:
P( X ) X
0 ,
, X 0
(3.12)
Và chỉ số [.]t để tín hiệu tại khoảng thời gian đang xử lý.
Trong phương trình nếu cho hệ số ta có thể ước lượng được
SNR post . Trong thực tế hệ số =0.98 rất tốt cho các tín hiệu có SNR<4dB.
SNRpri bằng
Từ phương trình (3.18) và (3.19) có G() theo WF như sau:
G()
SNRpri
1 SNRpri
(3.13)
Priori SNR
Sơ đồ khối của thuật toán Wiener Filtering:
Tín hiệu bị nhiễu
^
Y ()
Ước lượng, cập nhật nhiễu
FFT
|.|2
| D() | p
SNR
Hàm xử lý
giảm nhiễuWF
pri
|.|1/2
IFFT
Pha của tín hiệu
Tín hiệu sau khi tăng cường
Hình 3.2 Sơ đồ khối của thuật toán Wiener Filtering.
3.4 OVERLAP VÀ ADDING TRONG QUÁ TRÌNH XỬ LÝ TÍN HIỆU TIẾNG NÓI
3.4.1 Phân tích tín hiệu theo từng frame
Do tín hiệu cần xử lý của chúng ta là tín hiệu liên tục, nên khi chúng ta biến đổi FFT trực tiếp tín hiệu từ miền thời gian mà không thông qua một quá trình tiền xử lý nào trước đó thì tín hiệu sau khi được biến đổi FFT sẽ biến đổi nhanh, lúc đó chúng ta
không thể thực hiện được các thuật toán xử lý triệt nhiễu trong tín hiệu vì khi đó tín hiệu được xem là động.
Chính vì vậy, tín hiệu của chúng ta cần phải được phân tích thành những khung tín hiệu(frame) liên tục trong miền thời gian trước khi chuyển sang miền tần số bằng biến đổi FFT. Khi tín hiệu được phân tích thành các frame liên tục, thì trong từng frame, tín hiệu của chúng ta sẽ biến đổi chậm và nó được xem là tĩnh. Nếu tín hiệu được phân tích theo từng frame thì khi đó các thuật toán xử lý triệt nhiễu trong tín hiệu mới có thể thực hiện được một cách hiệu quả. Và cách phân tích tín hiệu của chúng ta là “frame by frame”.
Để thực hiện việc phân tích tín hiệu thành các frame, cần sử dụng các loại cửa sổ thích hợp. Ở đây, chúng ta sử dụng cửa sổ Hamming, với N = 256 mẫu trong từng frame :
1 0.85185 .cos((2k 1)/ N )
, k 0,..., N 1 (3.14)
N : kích thước của frame m : số lượng frame
Hình 3.3 Phân tích tín hiệu thành các frame.
3.4.2 Overlap và Adding
Sau khi phân tích tín hiệu thành các frame liên tục trong miền thời gian bằng cửa sổ Hamming, nếu các frame này liên tục với nhau và không theo một điều kiện nào cả thì khi thực hiện biến đổi FFT thì vô tình chúng ta đã làm suy giảm tín hiệu do Hamming là cửa sổ phi tuyến.
Nên khi thực hiện phân tích tín hiệu thành các frame thì yêu cầu đặt ra là các frame phải sắp xếp chồng lên nhau, gọi là “overlap”. Việc xếp chồng các frame với nhau sẽ được thực hiện theo một tỷ lệ chồng lấp thích hợp, thông thường là 40% hoặc 50%.
Sau khi các frame tín hiệu được xử lý triệt nhiễu trong miền tần số, các frame này được liên kết lại nhau bằng phương pháp thích hợp với phương pháp phân tích tín hiệu thành các frame ở đầu vào gọi là “adding”.
Tập hợp các mẫu tín hiệu trong cùng một frame sau khi được phân tích ở đầu vào gọi là một “segment”. Với cách thực hiện phân tích và liên kết các frame bằng phương pháp overlap và adding thì tín hiệu của chúng ta thu được sau khi xử lý triệt nhiễu sẽ không bị méo dạng và sẽ không xuất hiện hiện tượng “giả nhiễu”.
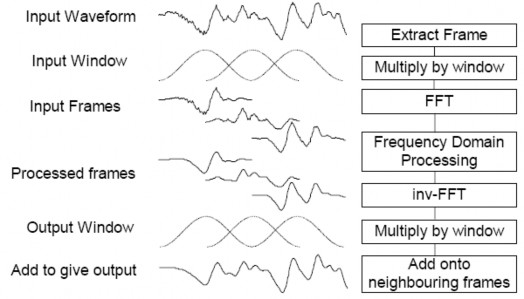
Hình 3.4 quá trình thực hiện overlap và adding.
3.5 ƯỚC LƯỢNG VÀ CẬP NHẬT NHIỄU
Phương thức ước lượng nhiễu có thể ảnh hưởng lớn đến chất lượng của tín hiệu sau khi được tăng cường. Nếu nhiễu được ước lượng quá nhỏ thì nhiễu sẽ vẫn còn trong tín hiệu và nó sẽ được nghe thấy, còn nếu như nhiễu được ước lượng quá lớn thì tiếng nói sẽ bị méo, và làm sẽ làm tính dễ nghe của tiếng nói bị ảnh hưởng. Cách đơn giản nhất để ước lượng và cập nhật phổ của nhiễu trong đoạn tín hiệu không có mặt của tiếng nói sử dụng thuật toán thăm dò hoạt động của tiếng nói (voice activity detection - VAD). Tuy nhiên phương pháp đó chỉ thoả mãn đối với nhiễu không thay đổi(nhiễu trắng), nó sẽ không hiệu quả trong các môi trường thực tế (ví dụ như nhà hàng), ở những nơi đó đặc tính phổ của nhiễu thay đổi liên tục. Trong mục này chúng ta sẽ đề cập đến thuật toán ước lượng nhiễu thay đổi liên tục và thực hiện trong lúc tiếng nói hoạt động, thuật toán này sẽ phù hợp môi trường có nhiễu thay đổi cao.
3.5.1 Voice activity detection
Quá trình xử lý để phân biệt khi nào có tiếng nói hoạt động, khi nào không có tiếng nói (im lặng) được gọi là sự thăm dò hoạt động của tiếng nói – Voice activity detection (VAD). Thuật toán VAD có tín hiệu ra ở dạng nhị phân quyết định trên một nền tảng frame-by-frame, khi đó frame có thể xấp xỉ 20-40 ms. Một đoạn tiếng nói có chứa tiếng nói hoạt động thì VAD = 1, còn nếu tiếng nói không hoạt động hay đó chính là nhiễu thì VAD = 0.
Có một vài thuật toán VAD được đưa ra dựa trên nhiều đặc tính của tín hiệu. Các thuật toán VAD được đưa ra sớm nhất thì dựa vào các đặc tính như mức năng lượng, zero-crossing, đặc tính cepstral, phép đo khoảng cách phổ Itakura LPC, phép đo chu kỳ.
Phần lớn các thuật toán VAD đều phải đối mặt với vấn đề là điều kiện SNR thấp, đặc biệt khi nhiễu bị thay đổi. Một thuật toán VAD có độ chính xác trong môi trường thay đổi không thể đủ trong các ứng dụng của Speech enhancement, nhưng việc ước lượng nhiễu một cách chính xác là rất cần thiết tại mọi thời điểm khi tiếng nói hoạt động.
3.5.2 Quá trình ước lượng và cập nhật nhiễu
Nhiễu sẽ được ước lượng lúc ban đầu bằng cách lấy trung bình biên độ phổ của tín hiệu bị nhiễu
1
D () 1 M)
i
(3.15)
M i0
Yi (
Sau đó, sử dụng phương pháp VAD để nhận biết các frame tiếp theo, frame nào là frame nhiễu và sẽ cập nhật nhiễu đó cho các frame tiếp theo. Để có thể nhận biết được frame nào là nhiễu thì chúng ta thực hiện so sánh biên độ phổ của nhiễu được ước lượng với biên độ phổ của tín hiệu bị nhiễu :
1 Y ()
T 20 log
|i| d
(3.16)
2Di1 ()
Nếu
T 12dB
thì frame đó không phải là frame có tiếng nói, khi đó ta có thể
cập nhật lại nhiễu đã được ước lượng trước đó.
3.6 KẾT LUẬN CHƯƠNG
Nội dung của chương giúp nguyên lý Wiener Filtering. Để thuật toán có thể thực hiện được thì cần phải phân tích tín hiệu thành các frame và các frame phải xếp chồng lên nhau, và sau khi các frame được xử lý trong miền tần số và chuyển đổi về lại miền
thời gian thì các frame đó phải được liên kết lại với nhau theo đúng phương pháp tương ứng với phương pháp phân tích tín hiệu ở đầu vào, quá trình đó gọi là overlap và adding. Chính điều đó sẽ làm cho tín hiệu của chúng ta sau khi xử lý triệt nhiễu sẽ không bị méo, đảm bảo chất lượng của tiếng nói. Nội dung của chương cũng trình bày vấn đề ước lượng nhiễu, đây là cái chính mà speech enhancement cần giải quyết, nó quyết định tính hiệu quả của thuật toán và chất lượng của tiếng nói sau khi xử lý triệt nhiễu.
CHƯƠNG 4: MÔ PHỎNG BẰNG PHẦN MỀM MATLAB
4.1 GIỚI THIỆU CHƯƠNG
Dựa vào lý thuyết đã nghiên cứu được, chương này đã xây dựng các lưu đồ thuật toán và thực hiện các thuật toán giảm nhiễu mô phỏng bằng Matlab, sau đó đánh giá các kết quả thu được chủ yếu bằng phương pháp đánh giá Objective Measure.
4.2 QUY TRÌNH THỰC HIỆN VÀ ĐÁNH GIÁ THUẬT TOÁN
Xây dựng các thuật toán
Triển khai thuật toán trên Matlab
Thực hiện xử lý tiếng nói bằng các thuật toán giảm nhiễu
Thực hiện các thuật toán đánh giá dựa trên các kết quả đạt được sau khi xử lý
Nhận xét đánh giá
Hình 4.1. Sơ đồ thực hiện và đánh giá thuật toán tăng cường
Xây dựng thuật toán : dựa trên các cơ sở toán học, các phép biến đổi trong miền thời gian và tần số đối với xử lý tín hiệu số để xây dựng nên các thuật toán xử lý nhiễu trong tiếng nói.
Triển khai trên Matlab: từ thuật toán đã xây dựng được, thực viết mã nguồn bằng ngôn ngữ lập trình và sử dụng các công cụ trên Matlab tạo nên chương trình thực hiện xử lý nhiễu trong tiếng nói trên nền Matlab.
Thực hiện xử lý tiếng nói bằng các thuật toán: thực hiện xử lý triệt nhiễu trong các file âm thanh bị nhiễu bằng chương trình đã xây dựng ở trên.
Thực hiện các phương pháp đánh giá dựa trên các kết quả đạt được sau khi xử lý
: sau khi các file âm thanh bị nhiễu với các mức độ và loại nhiễu khác nhau đã được xử lý triệt nhiễu, cùng với các file âm thanh sạch tương ứng, ta sử dụng các phương
pháp đánh giá của Speech enhancement để thực kiểm tra, đánh giá tính hiệu của thuật toán.
Nhận xét đánh giá: từ các kết quả sau khi thực hiện các phương pháp đánh giá đã có ở trên, đưa ra các kết luận đánh giá : thuật toán nào thích hợp cho loại nhiễu nào, với mức độ bao nhiêu, thuật toán nào có khả xử lý nhiễu tốt hơn trong mọi trường hợp.