WHERE Customer.CustomerNo = Order.CustomerNo AND Order.ItemNo = Item.ItemNo
AND Customer.FirstName = `John'
+ Hệ quản trị cơ sở dữ liệu hướng đối tượng (Object-Oriented DBMS)
Object-Oriented DBMS (OODBMS) sử dụng cách lưu trữ và nhận lại các đối tượng. Các đối tượng có thể gói dữ liệu và các ứng xử. Bởi vì dữ liệu trong một đối tượng có thể điều chỉnh bởi một đối tượng hay tập hợp các hộp tượng, các đối tượng tương tự như các nút trong một HDBMS được hiểu như sư tập các nút con.
Khả năng để truy vấn các đối tượng được được cung cấp thông qua tập hợp các phương thức thừa kế từ đối tượng cha đã được cung cấp sẵn bởi nền tảng OODBMS. Mỗi một đối tượng có thể cài đặt những phương thức này trong một phương cách tương tự cho mục đích của nó. Một SQL, gọi là OQL, cho phép truy vấn trong hệ thống theo một đường lối tiêu chuẩn được đề xuất bởi nhóm quản trị cơ sở dữ liệu hướng đối tượng (Object-Oriented DBMS-ODMG) tại địa chỉ http://www.odmg.org
Một sự thuận lợi lớn của của OODBMS là sự tích hợp trực tiếp với ngôn ngữ lập trình hướng đối tượng. Một sự thuận lợi khác là số lượng dữ liệu có thể được mô hình bởi OODBMS rất dễ dàng.
+ Tại sao sử dụng XML?
Trong các năm qua đã có sự trăn trở về phương cách truy cập dữ liệu lưu trữ qua các cơ sở dữ liệu kinh doanh và cung cấp khả năng kinh doanh trên mạng Internet. Trong những điều trăn trở trên cũng bao gồm khả năng trao đổi và vận chuyển giữa các hệ thống trong một hệ thống kinh doanh. Bởi vì có quá nhiều kiểu và nhiều hánh của DBMS tồn tại, hai thành phần sử dụng hai cơ sở dữ liệu khác nhau sẽ khó có thể tương thích với nhau. Dĩ nhiên, điều này có thể thực hiện được nếu được sử dụng trên một DBMS. Tuy nhiên, ngay cả khi chúng ta sử dụng cùng DBMS, lượt đồ dữ liệu cũng có thể khác nhau để chỉ định có thể sẽ khác nhau giữa hai hệ thống.
Do đó, có rất nhiều tổ chức đã cố gắng để truy cập dữ liệu qua toàn thế giới trong một kiểu dáng mà có thể dễ dàng quản lý và trong một định dạng tự nó định nghĩa và có tiêu chuẩn dễ dãi. Để giải quyết vấn đề này, môt vài ngành công nghiệp đã chuyển chúng sang XML.
- Sử dụng XML với một DBMS
Mặc dù XML đã đưa ra rất nhiều tiện lợi trong việc trao đổi dữ liệu, việc sử dụng nó với một DBMS có thể gây nên sự khó hiểu. Ví dụ, dữ liệu XML được cấu trúc tương thích với rất nhiều cơ sở dữ liệu. Điều này có nghĩa là tổ chức sắp xếp dữ liệu phải sử dụng trước khi XML có thể nhận dữ liệu từ hoặc lưu trữ trong một cơ sở dữ liệu. Trong nội dung này, chúng ta sẽ bàn luận về cách sử dụng XML với DBMS:
+ Mô hình dữ liệu
Một mô hình dữ liệu là một khái niệm ấn định các cấu trúc của dữ liệu. Các cấu trúc dữ liệu bao gồm các đối tượng dữ liệu, quan hệ giữa các đối tượng và luật để ấn định các phép toán có thể thực thi trên các đối tượng.
Trước khi chúng ta khảo sát vấn đề với mô hình dữ liệu, chúng ta phải hiểu rõ rằng các tài liệu XML có thể phân loại thành hai kiểu chính: trung tâm dữ liệu (data-centric ) và trung tâm tài liệu (document-centric). Sự phân loại này là rất quan trọng bởi vì nó thường ảnh hưởng đến khả năng được sử dụng bởi XML với một DBMS.
Các tài liệu trung tâm dữ liệu XML
Tính chất chính của tài liệu trung tâm dữ liệu XML một một sự sắp xếp và cấu trúc dữ liệu bình thường và không có nội dung pha trộn. Các tài liệu trung tâm dữ liệu XML được thiết kế để sử dụng cho riêng ứng dụng và sự trao đổi giữa ứng dụng và ứng dụng. Các ví dụ bao gồm gởi hóa đơn, đặt giá cổ phiếu, danh sách sản phẩm và các tập tin cấu hình của ứng dụng.
Ví dụ dưới là một tài liệu trung tâm dữ liệu XML nó giữ thông tin liên lạc của một cá nhân trong một danh bạ điện thoại. Chú ý rằng, mỗi thông itn như Full Name, zip hoặc postal code được chỉ định trong một phần tử và không có sự pha trộn nội dung:
data_centric.xml
<?xml version="1.0"?>
<Contacts>
<Contact ContactNumber="197459531">
<FullName>Abercrombie, Kim</FullName>
<CompanyName>Tailspin Toys</CompanyName>
<EMail>akim@tailspintoys.com</EMail>
<PhoneNo type="business">1-415-123-1234</PhoneNo>
<Address>
<Street>123 Main St.</Street>
<City>San Francisco</City>
<State>CA</State>
<PostalCode>94116</PostalCode>
<CountryCode>US</CountryCode>
</Address>
</Contact>
<Contact ContactNumber="250021025">
<FullName>Chen, John Y.</FullName>
<CompanyName>Contoso, Ltd</CompanyName>
<EMail>johny.chen@contoso.com</EMail>
<PhoneNo>852-1234-5678</PhoneNo>
<Address>
<Street>99 Dry St.</Street>
<City>Cardiff</City>
<PostalCode>CF17XX</PostalCode>
<CountryCode>UK</CountryCode>
</Address>
</Contact>
</Contacts>
Các trung tâm tài liệu XML
Được thiết kế với sự hào phóng hơn sử dụng cấu trúc văn bản tự do cho mõi phần tử. Nó thường được sử dụng cho sự tùy biến của con người và có ít cấu trúc bình thường với sự pha trộn nội dung. Ví dụ như sách, thư, email và các tài liệu HTML/XHTML. Trong ví dụ dưới, nội dung pha trộn được sử dụng trong các phần tử <bullet> và <para>:
document_centric.xml:
<?xml version="1.0"?>
<chapter>
<number>4</number>
<title>Sample Chapter</title>
<author email="john.kelly@thephone-company.com">Kelly, John
</author>
<contents>
<header level="1">
<para>This is a sample paragraph.</para>
<list>
<bullet>This is <ref link="#12">item 1</ref></bullet>
<bullet>This is <ref link="#13">item 2</ref></bullet>
</list>
<header level="2">
<para>This is paragraph with embedded <bold>formatting
</bold>.</para>
</header>
</header>
</contents>
</chapter>
Các bàn luận về sự mô hình
Mặt diện của XML cho thấy nó có thể vừa khớp với một danh sách mô hình phân cấp (thừa kế). XML được xem như một cây lai. XML hầu như tương tự mới mô hình đối tượng bởi vì XML nó cũng bao gồm các nút và các nút chứa dữ liệu không đồng nhất. Mặt khác,
các tài liệu XML là hướng tài liệu, nó có thể lưu trữ dữ liệu hỗn hợp nên mang lại sự mềm dẻo. Về mặt này, XML dễ dàng tương thích với hầu hết DBMS.
Đa số DBMS đề cung cấp một cách gián tiếp với XML. Cung cấp để nhận tài liệu XML để sinh tài liệu nền sử dụng các luật đã dựng sẵn.
Sự phức tập của một nền tảng mô hình có thể được nắm giữ một sự phức tạp nhất định nghĩa là, một số DBMS không cung cấp bất kỳ công cụ dựng sẵn nào để lưu trữ và nhận tài liệu trung tâm dữ liệu nào.
Một số DBMS cho phép người dùng có thể lưu trữ tài liệu XML ở dạng đối tượng nhị phân lớn (Binary Large Object –BLOB) được thiết kế để lưu trữ dữ liệu phi cấu trúc hay dữ liệu nhị phân. Phương pháp này cho chúng ta sự tiện lợi được cung cấp bởi cơ sở dữ liệu như chuyển đối tượng, bảo mật và tập trung truy cập. Đa số các DMBS tinh vi có một công cụ nhận biết XML với khả năng truy vấn văn bản đầy đủ cho tài liệu XML lưu trữ trong cơ sở dữ liệu.
- Các kiểu dữ liệu
Nói một cách đúng đắng, văn bản là kiểu dữ liệu được hỗ trợ duy nhất trong một tài liệu XML. Đa số cơ sở dữ liệu có cung cấp các kiểu dữ liệu mạnh mẽ. Tuy nhiên, RDBMS sẽ chuyển dữ liệu từ văn bản trong tài liệu XML thành dữ liệu tương thích và ngược lại. Vấn đề lớn nhất gặp phải là không có định chuẩn quốc tề về vấn đề ấn định văn bản sang các dữ liệu khác. Các kiểu ngày tháng là khó giải quyết nhất vì các định dạng của nó quá nhiều.
May mắn thay, W3C XSD cung cấp các khai báo kiểu dữ liệu, bao gồm số và ngày, cho phép người dùng có thể định nghĩa kiểu dữ liệu của mỗi phần tử. RDBMS cũng cung cấp XSD có thể định nghĩa lưu đồ sdữ liệu của một bảng trong cơ sở dữ liệu sử dụng XML.
- Dữ liệu nhị phân
Bởi vì tất cả dữ liệu trong XML đều thuộc văn bản, dữ liệu nhị phân có thể được mã hóa trước khi có thể lưu trữ trong tài liệu XML. Có hai cách thông dụng để mã hóa dữ liệu nhị phân trong XML là không phân tích thực thể và mã hóa Base64. Với RDBMS cung cấp XSD, người sử dụng có thể chọn kiểu dữ liệu Base64Binary để lưu trữ dữ liệu nhị phân.
- Giá trị rỗng (NULL)
Dữ liệu với giá trị rỗng được chỉ định trong thế giới cơ sở dữ liệu. Chúng dùng để chỉ định các cột không ấn định dữ liệu, dữ liệu không hợp lệ, … Chú ý rằng nó khác với giá trị 0 hay chuỗi có chiều dài bằng không. Ví dụ, hai cột có giá trị null không bằng nhau trong khi hai giá trị chuỗi rỗng bằng nhau.
Trong XML, dữ liệu rỗng được chỉ định trong phần tử rỗng hay thuộc tính rỗng. Thay vì dùng phần tử rỗng hay thuộc tính rỗng, môt số RDBMS co phép người sử dụng định nghĩa giá trị rỗng trong một tài liệu bằng cách sử dụng kiểu dữ liệu xsi:null.
- Tập ký tự
Một ký tự là một dãy các ký tự được sử dụng phương thức ánh xạ và liên đới với cấu trúc dữ liệu. Đa số các nước Tây Âu sử dụng chuẩn ISO-8859-1 (cũng còn gọi là Latin-1), đây là dạng đơn giản thể hiện một ký tự bởi một byte. Với các ngôn ngữ khác, tập ký tự có thể có yêu cầu khác đi. Ví dụ, các ký tự Do Thái (Hebrew) sử dụng chuẩn ISO-8859-8. Một số ngôn ngữ còn yêu cầu cấu trúc và luật để bản đồ hóa phức tạp hơn. Ví dụ, đối với các ngôn ngữ Châu Á bao gồm hàng ngàn ký tự, như Trung Quốc, Nhật Bản và bảng mã Shift_JIS được sử dụng cho nước Nhật Bản. Cuối cùng, chuẩn Unicode cung cấp một ký tự 16 bit có thể chứa tất cả các ngôn ngữ thông dụng được sử dụng hiện nay.
Một charset khác với character set (tập ký tự). Để biết thêm chi tiết về sự khác nhau này hãy vào địa chỉ http://www.ietf.org/rfc/rfc2278.txt.
XML được thiết kế để hỗ trợ nhiều tập kí tự khác nhau như: Unicode, Databases. mặt khác, nó cũng hỗ trợ giúp đỡ cho một kí tự một cách tốt nhất. RDBMSs có thể hỗ trợ duy nhất một tập kí tự cho bảng hoặc cơ sở dữ liệu. Do đó, truy lại và lưu trữ tài liệu XLM bằng databases yêu cầu một quá trình chuyển đổi trực tiếp tập kí tự.
- Sử dụng XML với hệ thống cơ sở dữ liệu quan hệ
Ngày nay RDBMSs nổi trội như DBMS (hệ thống quản lí cơ sở dữ liệu). Nhiều tập đoàn lớn và nhỏ điều tin tưởng vào hệ thống RDBMSs để quản lí dữ liệu kinh doanh bằng những trình ứng dựng một cách tự động. bởi vì được yêu chuộng trong thế giới kinh doanh, XML thực thi hợp nhất với RDBMSs. Trong mục này chúng ta cùng khám phá nhiều cách khác mà RDBMSs đã hỗ trợ cho XML .
+ Nhận và lưu trữ các tài liệu trung tâm dữ liệu XML
Để nhận và lưu trữ các tài liệu trung tâm dữ liệu XML, đa số RDBMS cung cấp một máy ánh xạ cho phép chuyển đổi dữ liệu quan hệ sang XML và ngược lại. Nói một cách đại khái, các máy ánh xạ cung cấp hai dạng khác nhau: ánh xạ dựa trên tập kết quả và ánh xạ dựa trên giản đồ (schema).
Ánh xạ dựa trên kết quả
Kiểu ánh xạ dựa trên kết quả sẽ dựa trên các bảng tự nhiên của tập kết quả được sinh ra bởi các câu lệnh truy vấn SQL. Các cột và dòng in một tập kết quả thường được ánh xạ hoặc là các phần tử XML hoặc là các thuộc tính hay cả hai. Ví dụ dưới đây là một câu lệnh SQL đơn giản trả về các bảng ghi từ bảng Employee:
SELECT Employee_ID, First_Name, Last_Name, Dept_No FROM Employee
Câu truy vấn này sẽ sinh ra một tập kết quả có thể được xem giống như hình dưới:
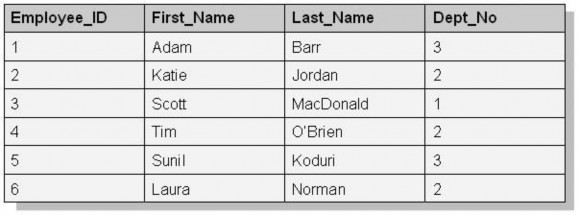
Để chuyển kết quả này sang một tài liệu XML, chúng ta có thể chỉ định ánh xạ các dòng giống như các phần tử của tài liệu XML và các cột giống như các thuộc tính của các phần tử này. Ví dụ dưới đây minh họa về sự biểu diễn kết quả trên bằng tập tin XML:
sample_query1.xml:
<?xml version="1.0"?>
<ROOT>
<row Employee_ID="1" First_Name="Adam" Last_Name="Barr" Dept_No="3"/>
<row Employee_ID="2" First_Name="Katie" Last_Name="Jordan" Dept_No="2"/>
<row Employee_ID="3" First_Name="Scott" Last_Name="MacDonald" Dept_No="1"/>
<row Employee_ID="4" First_Name="Tim" Last_Name="O'Brien" Dept_No="2"/>
<row Employee_ID="5" First_Name="Sunil" Last_Name="Koduri" Dept_No="3"/>
<row Employee_ID="6" First_Name="Laura" Last_Name="Norman" Dept_No="2"/>
</ROOT>
Để chắc chắn tài liệu XML này hợp không dạng, chúng ta phải thêm vào một phần tử gốc gọi là <ROOT>. Một phương án khác là dùng tên của bảng, trong trường hợp này Employee sẽ được gọi là phần tử gốc.
Với mỗi dòng trong tập kết quả, chúng ta phát sinh một phần tử <row> trong tài liệu XML. Các cột được gán vào thuộc tính của mỗi phần tử <row>. Một phương pháp khác là gán mỗi cột thành một phần tử con của mỗi phần tử <row>, giống như trong ví dụ sau:
sample_query2.xml
<?xml version="1.0"?>
<ROOT>
<row>
<Employee_ID>1</Employee_ID>
<First_Name>Adam</First_Name>
<Last_Name>Barr</Last_Name>
<Dept_No>3</Dept_No>
</row>
<row>
<Employee_ID>2</Employee_ID>
<First_Name>Katie</First_Name>
<Last_Name>Jordan</Last_Name>
<Dept_No>2</Dept_No>
</row>
<row>
<Employee_ID>3</Employee_ID>
<First_Name>Scott</First_Name>
<Last_Name>MacDonald</Last_Name>
<Dept_No>1</Dept_No>
</row>
<row>
<Employee_ID>4</Employee_ID>
<First_Name>Tim</First_Name>
<Last_Name>O'Brien</Last_Name>
<Dept_No>2</Dept_No>
</row>
<row>
<Employee_ID>5</Employee_ID>
<First_Name>Sunil</First_Name>
<Last_Name>Koduri</Last_Name>
<Dept_No>3</Dept_No>
</row>
<row>
<Employee_ID>6</Employee_ID>
<First_Name>Laura</First_Name>
<Last_Name>Norman</Last_Name>
<Dept_No>2</Dept_No>
</row>
</ROOT>
Một lợi thế khác của kỹ thuật ánh xạ dựa trên kết quả là phát sinh tài liệu XML một cách tự động phản ánh dữ liệu sống và giản đồ thông tin ấn định trong tập kết quả của mỗi tài liệu XML được phát sinh. Nghĩa là, để điều khiển số cột và dòng trong một tập kết quả bằng cách sử dụng câu lệnh SQL, chúng ta có thể tự động giới hạn số lượng dữ liệu sẽ nằm trong kết quả xuất ra tài liệu XML. Trong ví dụ sau, câu lệnh truy vấn SQL sẽ phát sinh tập kết quả và chuyển sang tài liệu XML:
SELECT CONCATENATE( LastName, ` `, FirstName ) AS FullName FROM Employee
WHERE LastName = `Jordan'
Tài liệu sẽ XML sẽ giống như sau: sample_query3.xml
<?xml version="1.0">
<ROOT>
<row Employee_ID="2" FullName="Jordan, Katie"/>
</ROOT>
Chỉ có một dòng đúng với điều kiện chỉ định trong mệnh đề WHERE. Cũng như vậy, chúng ta phát sinh tự động một thuộc tính FullName từ kết quả trong tài liệu XML:
Ánh xạ dựa trên kết quả sẽ có chức năng iệu quả bao gồm các dòng gốc từ một hay nhiều bảng. Kết quả sau là ví dụ cho sự liên kết nhiều bảng trong câu lệnh truy vấn SQL:
SELECT Dept.Dept_ID, Dept.Dept_Name, Employee.Employee_ID,
CONCATENATE( Employee.Last_Name, ' ', Employee.First_Name ) AS Employee_Name
FROM Dept, Employee
WHERE Dept.Dept_ID = Employee.Dept_ID ORDER BY Dept.Dept_ID, Employee.Employee_ID
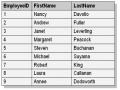
Câu lệnh truy vấn này sẽ phát sinh tập kết quả giống như sau:
Dept_ Name | Employe e_ID | Employee_Names |
Có thể bạn quan tâm!
-

 Lập trình web nâng cao XML - Trường CĐN Đà Lạt - 3
Lập trình web nâng cao XML - Trường CĐN Đà Lạt - 3 -
 Lập trình web nâng cao XML - Trường CĐN Đà Lạt - 4
Lập trình web nâng cao XML - Trường CĐN Đà Lạt - 4 -
 Lập trình web nâng cao XML - Trường CĐN Đà Lạt - 5
Lập trình web nâng cao XML - Trường CĐN Đà Lạt - 5 -
 Lập trình web nâng cao XML - Trường CĐN Đà Lạt - 7
Lập trình web nâng cao XML - Trường CĐN Đà Lạt - 7 -
 Lập trình web nâng cao XML - Trường CĐN Đà Lạt - 8
Lập trình web nâng cao XML - Trường CĐN Đà Lạt - 8 -
 Xây Dựng Giao Diện Người Sử Dụng Dựa Vào Xml.
Xây Dựng Giao Diện Người Sử Dụng Dựa Vào Xml.
Xem toàn bộ 258 trang tài liệu này.
1 | IT | 3 | McDonald, Scott |
2 | HR | 2 | Jordan, Katie |
2 | HR | 4 | O'Brien, Tim |
3 | HR | 6 | Norman, Laura |
3 | Operati ons | 1 | Barr, Adam |
4 | Operati ons | 5 | Koduri, Sunil |
sample_query4.xml
<?xml version="1.0"?>
<ROOT>
<row Dept_ID="1" Dept_Name="IT" Employee_ID="3" Employee_Name="MacDonald, Scott"/>
<row Dept_ID="2" Dept_Name="HR" Employee_ID="2" Employee_Name="Jordan, Katie"/>
<row Dept_ID="2" Dept_Name="HR" Employee_ID="4" Employee_Name="O'Brien, Tim"/>
<row Dept_ID="2" Dept_Name="HR" Employee_ID="6" Employee_Name="Norman, Laura"/>
<row Dept_ID="3" Dept_Name="Operations" Employee_ID="1" Employee_Name="Barr, Adam"/>
<row Dept_ID="3" Dept_Name="HR" Employee_ID="5" Employee_Name="Koduri, Sunil"/>
</row>
</ROOT>
Tài liệu XML nhiều bảng có một tính chất quan trọng. Nó không mô tả sự thừa kế tự nhiên của tập kết quả. Theo ý tưởng, nhóm mỗi dòng Employee có Dept_ID nằm dưới. Xem xét ví dụ sau:
sample_query5.xml
<?xml version="1.0"?>
<ROOT>
<Dept Dept_ID="1" Dept_Name="IT">
<Employee Employee_ID="3" Employee_Name="MacDonald, Scott"/>
</Dept>
<Dept Dept_ID="2" Dept_Name="HR">
<Employee Employee_ID="2" Employee_Name="Jordan, Katie"/>
<Employee Employee_ID="4" Employee_Name="O'Brien, Tim"/>
<Employee Employee_ID="6" Employee_Name="Norman, Laura"/>
</Dept>
<Dept Dept_ID="3" Dept_Name="Operations">
<Employee Employee_ID="1" Employee_Name="Barr, Adam"/>
<Employee Employee_ID="5" Employee_Name="Koduri, Sunil"/>
</Dept>
</ROOT>
Chú ý rằng, chúng ta cần phần tử có thể chứa để nắm giữ dữ liệu Dept. Để thay thế cho việc sử dụng phần tử <row>, chúng ta quyết định sử dụng tên của phần tử này tương ứng với tên của nó trong bảng, <Dept>. Tương tự, chúng ta sử dụng tên các phần tử để lưu trữ dữ liệu trong mỗi dòng của bảng Employee là phần tử <Employee>.
Để chuyển kết quả trên vào tài liệu XML lồng ghép, một RDBMS cần phải đánh dấu các dòng của tập kết quả trong từ trên xuống dưới và các cột theo kiểu từ trái qua phải. Dùng cách so sánh giá trị của các cột trong dòng hiện tại với những dòng trước, một RDBMS có thể suy luận cấu trúc cần thiết của tập kết quả. Thứ tự lồng ghép được xác định bởi một thứ tự mà trong đó các cột sẽ hiển thị trong tập kết quả.
Để minh họa tốt hơn cho sự phức tạp này, các bước sau sẽ được xử lý với tập kết quả ở trên. Trước tiên, chúng ta sử dụng dữ liệu đánh dấu của XML, chúng ta sẽ phát sinh các phần tử đầu và phần tử gốc, giống như sau:
<?xml version="1.0"?>
<ROOTSET>
Bấy giờ, hãy bắt đầu tử phần tử trên cùng của tập kết quả. Bởi vì đây là dòng đầu tiên, tuy nhiên, chúng ta chỉ cần nhớ các giá trị ở đây. Chúng ta không phát sinh bất kỳ XML tại điểm này. Chúng ta có thể di chuyển sáng dòng thứ hai.
So sánh dòng hai với dòng đầu tiên, chúng ta ngay lập tức nhận ra sự thay đổi dữ liệu, chúng ta cần phát sinh các phần tử trong tài liệu XML. Bởi vì, chúng ta nhìn thấy hai nhóm các cột thuộc về hai bảng khác nhau trong các dòng này. Dept_ID và Dept_Name của bảng Dept và Employee_ID và Employee_Name của bảng Employee. Chúng ta biết chúng ta cần hai phần tử phân cách để lưu giữ các giá trị của mỗi cột. Hơn nữa, bởi vì mỗi cột trong bảng Dept nằm trước của Employee, chúng ta cần phải lồng ghép các phần tử đúng với cá dòng của bảng Employee trong bảng Dept. Ví dụ sau cho chúng ta thấy kết quả xử lý:
<Dept Dept_ID="1" Dept_Name="IT">
<Employee Employee_ID="3" Employee_Name="MacDonald, Scott"/>
Đến đây, chúng ta phát sinh các phần tử và thuộc tính cho dòng trước (dòng một) và không cho dòng hiện tại. Bởi vì, tại điểm này cho chúng ta biết mỗi một dòng trước khác với dòng hiện tại. Do đó, chúng ta phát sinh dữ liệu XML cho dòng trước và nhớ dữ liệu trong dòng hiện tại. Đây là mẫu thường dùng để chúng ta tiếp tục cho đến khi chúng ta kết thúc tập kết quả.
Sau khi di chuyển sang dòng thứ 3 và so sánh nó với dòng trước (dòng hai), chúng ta thấy cả hai Dept_ID và Dept_Nam giống dòng trước nhưng Employee_ID và Employee_Nam có thay đổi. Nghĩa là chúng ta cần phải thêm phần tử <Employee> để miêu tả dữ liệu Employee nằm trong dòng trước.
Chúng ta cần phát sinh một phần tử <Dept> mới như trong ví dụ sau:
</Dept>
<Dept Dept_ID="2" Dept_Name="HR">
<Employee Employee_ID="2" Employee_Name="Jordan, Katie"/>
Bây giờ, chúng ta di chuyển sang dòng thứ tư, so sánh với dòng trước, giá trị cột của bản Employee có sự thay đổi, có nghĩa là chúng ta phải phát sinh thêm một phần tử
<Employee> mới. Kết quả như sau:
<Employee Employee_ID="4" Employee_Name="O'Brien, Tim"/>
Sang dòng thứ 5, chúng ta gặp tình trạng tương tự như dòng hai. Do đó, chúng ta sử dụng cách tương tự và phát sinh các phần tử cần thiết. Kết quả như sau:
<Employee Employee_ID="6" Employee_Name="Norman, Laura"/>
</Dept>
<Dept Dept_ID="3" Dept_Name="Operations">
Bây giờ, chúng ta xử lý dòng sáu. Đầu tiên, chúng ta thấy giá trị cột của Employee có sự thay đổi, chúng ta phát sinh phần tử mới <Employee> như minh họa:
<Employee Employee_ID="1" Employee_Name="Barr, Adam"/> Kết quả xử cuối cùng là đóng các tag đã mở:
<Employee Employee_ID="5" Employee_Name="Koduri, Sunil"/>
</Dept>
</ROOT>
Ánh xạ dựa trên giản đồ (Shema)
Trong một cơ sở dữ liệu quan hệ, quan hệ giữa hai bảng có thể sử dụng khóa ngoại. Do đó, chúng ta có thể mô hình một sự miêu tả XML của cơ sở dữ liệu dựa trên các thông tin trong một giản đồ cơ sở dữ liệu. chú ý rằng, phương pháp ánh xạ này thường được sử dụng trong lúc thiết kế để phát sinh một XML DTD hày giản đồ XSD. Về khía cạnh này, đa số ứng dụng làm việc một sự hiểu biết lược đồ cơ sở dữ liệu, phương pháp này không phù hợp để lưu trữ các tài liệu XML ngẫu nhiên trong cơ sở dữ liệu.
Để nghiên cứu sâu hơn về XSD, chúng ta có thể vào trang Web: http://www.w3.org/TR/xmlschema-0/.
Phát sinh giản đồ XSD từ giản đồ cơ sở dữ liệu
Một thử nghiệm trong phần này là phát sinh một giản đồ XSD đúng với cả hai bảng như
sau:
db_schema1.sql: CREATE TABLE Dept
(
DeptID INT PRIMARY KEY NOT NULL, DeptName VARCHAR( 20 ) NOT NULL
)
CREATE TABLE Employee (
EmployeeID INT PRIMARY KEY NOT NULL,
FirstName VARCHAR( 20 ),
LastName VARCHAR( 20 ) NOT NULL,
DeptID NUMBER REFERENCES Dept( Dept_ID ) NOT NULL
)
Đầu tiên chúng ta cần mô hình một XSD cho một bảng. Chúng ta bắt đầu với bảng Employee. Mỗi dữ liệu cột trong bảng Employee, tên là FirstName và LastName, chúng ta cần phải phát sinh hai phần tử tương ứng trong XSD. Trước khi chúng ta có thể làm điều này, chúng ta cần định nghĩa một kiểu dữ liệu để mô hình VARCHAR(20) để sử dụng cho FirstName và LastName trong giản đồ cơ sở dữ liệu của chúng ta. Chúng ta sử dụng kiểu dữ liệu xsd:string với giới hạn 20 ký tự.
<xsd:simpleType name="varchar20">
<xsd:restriction base="xsd:string">
<xsd:maxLength value="20"/>
</xsd:restriction>
</xsd:simpleType>
Bây giờ chúng ta có thể định nghĩa hai phần tử FirstName và LastName với kiểu varchar20
<xsd:element name="FirstName" type="varchar20"/>
<xsd:element name="LastName" use="required" type="varchar20"/>
Chú ý rằng, chúng ta đã thêm một kiểu dữ liệu mới mang tên varchar20, chúng ta cũng chỉ định LastName là bắt buộc bởi vì nó được định nghĩa không được rỗng trong giản đồ cơ sở dữ liệu.
Tiếp theo, chúng ta xử lý trường khóa chính của bảng Employee, tên là EmployeeID. Trước tiên, chúng ta mô hình nó thành một phần tử không trùng lặp và bắt buộc (unique và required):
<xsd:element name="EmployeeID" use="required" type="xsd:int">
<xsd:unique name="EmployeeUnique">
<xsd:selector xpath="my:Employee"/>
<xsd:field xpath="EmployeeID"/>
</xsd:unique>
</xsd:element>
Chú ý rằng phần tử EmployeeID được định nghĩa bằng cách sử dụng phần tử
<xsd:unique>. Phần tử <xsd:selector> chỉ định rằng giá trị của EmployeeID phải là duy nhất trong phần tử <Employee>. (Chúng ta cũng bao gồm địn nghĩa cho một không gian URI khi chúng ta hoàn thành tài liệu XSD của chúng ta). Phần tử <xsd:field> đi kèm với
<xsd:unique> để định nghĩa phần tử EmployeeID.
Sự mô hình của chúng ta cho trường EmployeeID có một vấn đề. Trong một giản đồ cơ sở dữ liệu, một cột có thể định nghĩa là không trùng lặp nhưng không phải là khóa chính. Như vừa nói, EmployeeID là bắt buộc nhưng chúng ta cần phải chỉ định EmployeeID là khóa chính.
XSD không định nghĩa trực tiếp khóa chính. Một phương pháp có thể được sử dụng trong tài liệu XSD là <appinfo><annotation>. Một <appinfo> <annotation> tương tự như chỉ thị xử lý trong XML 1 bởi vì nó được dùng để chuyển thông tin cho ứng dụng xử lý. Do đó, chúng ta thêm vào tài liệu XSD của chúng ta như sau:
<xsd:element name="EmployeeID" use="required" type="xsd:int">
<xsd:unique name="EmployeeUnique">
<xsd:selector xpath="my:Employee"/>
<xsd:field xpath="EmployeeID"/>
<xsd:annotation>
<xsd:appinfo>