3.1. Chọn các phần tử tốt nhất từ P đưa vào tập ghi nhớ M.
3.2. Thay thế n phần tử có độ thích hợp thấp bằng một số phần tử mới được sinh ra ngẫu nhiên.
Bước 4. Lặp: lặp lại bước 2 và 3 cho tới khi gặp điều kiện dừng.
Trong thuật toán chọn lọc tích cực, việc bảo vệ tập Self S thực hiện bằng cách kiểm tra các cơ quan thụ cảm T cell về khả năng kết hợp với các phần tử thuộc tập S. Nếu một T cell không nhận diện được bất kỳ phần tử nào, nó sẽ bị loại bỏ. Trái lại, nó được chọn như một tế bào có khả năng miễn dịch và bổ sung vào quần thể có giá trị A.
Với ý tưởng đơn giản, các bước thực hiện không quá phức tạp phù hợp với thời gian cũng như cơ sở dữ liệu sử dụng trong nghiên cứu xây dựng chương trình. Cho nên trong nội dung đề tài sẽ sử dụng thuật toán NSA để xây dựng chương trình lọc thư rác. Bạn đọc quan tâm đến các thuật toán còn lại có thể tìm đọc tài liệu [10] và các tài liệu khác về hệ miễn dịch nhân tạo.
2.2.4. Sinh tập bộ dò
Để áp dụng hệ miễn dịch nhân tạo hay cụ thể phép chọn lọc tiêu cực xây dựng chương trình lọc thư rác, cần tạo ra tập bộ dò từ cơ sở dữ liệu mẫu đã có. Những thư điện tử thông thường trong cơ sở dữ liệu được chuyển đổi sang các xâu nhị phân độ dài ℓ bit, từ đó việc chọn lọc được tiến hành với các xâu nhị phân. Điều này nảy sinh vấn đề so khớp giữa xâu nhị phân của phần tử trong tập bộ dò với phần tử cần chọn lọc. Vấn đề so khớp bạn đọc quan tâm có thể tìm hiểu trong tài liệu [3].
Có nhiều thuật toán sinh tập bộ dò trong hệ miễn dịch nhân tạo, như: sinh tập bộ dò kết hợp chọn lọc âm tính và chọn lọc dương tính dựa trên rchunk,…; sinh tập bộ dò sử dụng bảng băm, sinh tập bộ dò theo mô hình tiền tố dựa trên rcontiguous.
Trong luận văn sẽ sử dụng phương pháp sinh tập bộ dò sử dụng bảng băm. Sau đây trình bày quá trình xây dựng.
Việc so khớp hai xâu bất kì thực chất là so khớp lần lượt r vị trí liên tiếp (r ℓ).
Do vậy, chắc chắn trong quá trình so khớp ta phải nhiều lần so khớp các đoạn có độ dài
r giống nhau, công việc này làm tốn nhiều thời gian tính toán. Để khắc phục nhược
điểm đó, trong tập các xâu lưu trong S ta có thể loại những xâu trùng nhau để tăng hiệu suất sử dụng bộ nhớ. Tuy nhiên công việc này lại đòi hỏi mất thêm thời gian tính toán.
Phương pháp tốt hơn cho công việc này là sử dụng bảng băm.
Phương pháp bảng băm
Tư tưởng: Ta sử dụng bảng A kiểu Boolean có n hàng và m cột với:
n = 2r và m = ℓ – r + 1
1 | … | M | |
0 | |||
1 | |||
…. | |||
n1 |
Có thể bạn quan tâm!
-

 Ứng dụng hệ miễn dịch nhân tạo cho lọc thư rác - Lương Văn Lâm - 2
Ứng dụng hệ miễn dịch nhân tạo cho lọc thư rác - Lương Văn Lâm - 2 -
 Các Kĩ Thuật Phát Hiện Và Ngăn Chặn Thư Rác
Các Kĩ Thuật Phát Hiện Và Ngăn Chặn Thư Rác -
 Tổng Quan Về Hệ Miễn Dịch Sinh Học
Tổng Quan Về Hệ Miễn Dịch Sinh Học -
 Quá Trình Kiểm Tra Phân Loại (Testing)
Quá Trình Kiểm Tra Phân Loại (Testing) -
 Ứng dụng hệ miễn dịch nhân tạo cho lọc thư rác - Lương Văn Lâm - 7
Ứng dụng hệ miễn dịch nhân tạo cho lọc thư rác - Lương Văn Lâm - 7 -
 Ứng dụng hệ miễn dịch nhân tạo cho lọc thư rác - Lương Văn Lâm - 8
Ứng dụng hệ miễn dịch nhân tạo cho lọc thư rác - Lương Văn Lâm - 8
Xem toàn bộ 69 trang tài liệu này.
Trong đó:
+ A[i, j] = 1: đoạn bit từ bit j đến bit thứ j + r – 1 của các s S có giá trị là i trong hệ đếm cơ số 10.
+ A[i, j] = 0: trong trường hợp ngược lại.
Bảng A được xây dựng bằng cách đọc lần lượt các đoạn r bit liên tiếp của các xâu trong S rồi tính giá trị thập phân của đoạn bit đó và gán A[i, j] tương ứng có giá trị bằng 1.
Ví dụ: Cho tập S = {10100; 00110; 10101; 01001; 11010}
Ta có ℓ = 5 và chọn r = 3. Vì vậy: Số dòng của bảng A: n = 2r = 23 = 8
Số cột của bảng A: m = ℓ – r + 1 = 5 – 3 + 1 = 3
1 | 2 | 3 | |
0 | 0 | 0 | 0 |
1 | 1 | 0 | 1 |
2 | 1 | 1 | 1 |
0 | 1 | 0 | |
4 | 0 | 1 | 1 |
5 | 1 | 1 | 1 |
6 | 1 | 0 | 1 |
7 | 0 | 0 | 0 |
3
Ta xây dựng được bảng A như sau:
*) Xét xâu 1: s1 = 10100
+ Với j = 1: ta có đoạn bit 101 (101)2 = (5)10 Vậy A[5, 1] = 1
+ Với j = 2: ta có đoạn bit 010 (010)2 = (2)10 Vậy A[2, 2] = 1
+ Với j = 3: ta có đoạn bit 100 (100)2 = (4)10 Vậy A[4, 3] = 1
*) Xét xâu 2: s2 = 00110
+ Với j = 1: ta được đoạn bit 001 (001)2 = (1)10 Vậy A[1, 1] = 1
+ Với j = 2: ta được đoạn bit 011 (011)2 = (3)10 Vậy A[3, 2] = 1
+Với j = 3: ta có đoạn bit 110 (110)2 = (6)10 Vậy A[6, 3] = 1
*) Xét xâu 3: s3 = 10101
+ Với j = 1: ta có đoạn bit 101 (101)2 = (5)10
Ta thấy A[5, 1] đã nhận giá trị là 1, do vậy đoạn bit 101 ở vị trí thứ nhất đã trùng với đoạn bit ở vị trí thứ nhất của một xâu trước đó. Vậy nên ta đã loại được các bit giống nhau.
+ Với j = 2: ta được đoạn bit 010 (010)2 = (2)10
Ta thấy A[2, 2] đã nhận giá trị là 1, do vậy đoạn bit 010 ở vị trí thứ hai đã trùng với đoạn bit ở vị trí thứ hai của một xâu trước đó. Vậy nên ta đã loại được các bit giống nhau.
+ Với j = 3: ta được đoạn bit 101 (101)2 = (5)10 Vậy A[5, 3] = 1.
Thực hiện tương tự với hai xâu còn lại ta sẽ thu được kết quả là bảng A ở trên.
Nhận xét phương pháp sinh tập bộ dò sử dụng bảng băm
Kích thước bảng A phụ thuộc vào độ lớn của hai tham số ℓ và r. Với các
giá trị tham số hợp lý thì hoàn toàn có thể lưu bảng A ở bộ nhớ trong.
Các xâu bit có đoạn r bit tương ứng giống nhau sẽ tự động được loại bỏ vì ta chỉ cần biết đoạn bit đó nằm ở vị trí nào và có giá trị trong hệ 10 là bao nhiêu, ta lưu những đoạn trùng lặp nên tối ưu về bộ nhớ.
Vì A là bảng hai chiều, được lưu trữ trên bộ nhớ trong nên việc truy cập đến phần tử A[i, j] chỉ mất thời gian là O(1). Dù dữ liệu bảo vệ có thay đổi rất lớn đi nữa thì ta vẫn chỉ cần 1 bảng A có kích thước cố định 2r dòng, (ℓ r + 1) cột.
Độ phức tạp của thuật toán: 2r. ℓ.|D| (D là tập bộ dò).
2.3. Kết luận
Hệ miễn dịch nhân tạo là phương pháp mới lấy ý tưởng của hệ miễn dịch sinh học, nó gồm các thuật toán khác nhau. Thuật toán chọn lọc âm tính của hệ miễn dịch nhân tạo có thể sử dụng để xây dựng bộ lọc thư rác. Kỹ thuật dùng bảng là một cách tiếp cận đơn giản trong cài đặt thuật toán chọn lọc âm tính.
Chương 3
XÂY DỰNG CHƯƠNG TRÌNH LỌC THƯ RÁC
Trong chương này, trình bày các quá trình xây dựng chương trình; phân tích kết quả đạt được; so sánh kết quả với các phương pháp khác sử dụng phần mềm Weka.
3.1. Giới thiệu
Như đã trình bày ở chương 1. Để nghiên cứu, xây dựng bộ lọc thư rác người ta thường sử dụng các cơ sở dữ liệu đã được thống kê sẵn. Trong bài toán lọc thư rác của luận văn sẽ sử dụng cơ sở dữ liệu Spambase Data Set với số liệu thống kê của 4601 thư điện tử, trong đó có 1813 thư rác và 2788 thư thường. Cơ sở dữ liệu này thống kê khá đầy đủ và chính xác, được các chuyên gia hàng đầu nghiên cứu, sử dụng. Hơn nữa, nó phù hợp với thuật toán áp dụng cũng như thời gian thực hiện luận văn. Vì vậy, tôi sử dụng cơ sở dữ liệu này để thử nghiệm chương trình trong luận văn.
3.1.1. Bài toán lọc thư rác Input:
Số nguyên dương r [7,10], ℓ.
Cơ sở dữ liệu Spambase Data Set (lưu trong file *.txt)
Output: Kết quả về sự phát hiện thư rác hay thư thường thể hiện qua 10 lần thử nghiệm với 3 số liệu thống kê trung bình: Acc (Độ chính xác tổng thể), DR (Tỉ lệ phát hiện), FPR (lỗi phát hiện sai).
Chương trình lấy giá trị ℓ chính là độ dài các xâu nhị phân được chuyển đổi từ các số liệu thống kê 57 thuộc tính của từng email (trừ thuộc tính cuối cùng phân biệt thư rác và thư thường).
Giá trị của r được thử nghiệm lần lượt với các giá trị trong đoạn [7,10].
Việc thử
nghiệm chương trình được thực hiện theo quy tắc:
Tenfold cross
validation, thực hiện như sau:
Bước 1: Chia các email thường trong file nguồn (HAM.txt) ngẫu nhiên thành 10 phần ta được 10 file email thường.
Bước 2: Đọc số liệu trong 9 file email thường để huấn luyện.
Bước 3: Tiến hành kiểm tra (testing), thực hiện với 1 file email thường còn lại và tất cả các email spam. Số lượng các email thường và email rác mà chương trình phát hiện được sẽ được tính toán quy đổi ra 3 số liệu:
DR = TP/(TP + FN) FPR = FP/(TN + FP)
Acc = (TP + TN) /(TP + TN + FP + FN)
Trong đó:
+ TP : Số lượng email spam kết luận đúng.
+ TN: Số lượng email thường kết luận đúng.
+ FP : Số lượng email thường kết luận sai thành spam.
+ FN: Số lượng email spam kết luận sai thành email thường.
Chương trình thực hiện lặp bước hai và ba mười lần, mỗi lần sẽ tính toán và cho ra 3 số liệu trên. Sau đó lấy giá trị trung bình mười lần tính toán.
3.1.2. Xây dựng chương trình
3.1.2.1. Môi trường và công cụ
Môi trường: Sử dụng hệ điều hành Windows 7.
Công cụ: Chương trình được xây dựng bằng ngôn ngữ lập trình C# nằm trong bộ Visual Studio 2008 và chạy trên nền .NetFramework.
3.1.2.2. Giao diện chương trình
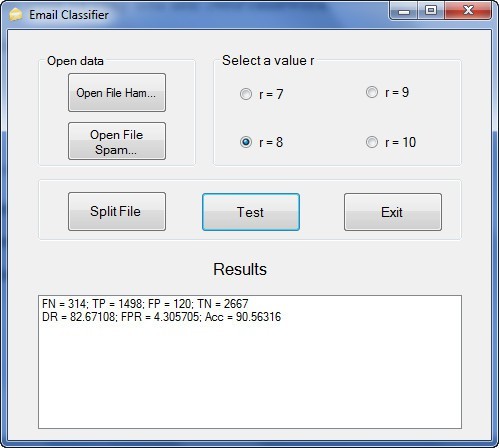
Hình 3.. Giao diện chương trình
Chức năng của các đối tượng trong giao diện:
Nút Open File Ham…: Mở file thư thường (Ham).
Nút Open File Spam…: Mở file thư rác (Spam).
Hộp Select a value r: Đặt giá trị cho r.
Nút Split File: Chia file nguồn của chương trình (file thư thường – HAM.txt, file thư spam – SPAM.txt).
Nút Test:
+ Tạo tập bộ dò từ các file thư thường.
+ Cho file thư thường còn lại (không sử dụng để tạo bộ dò) và file thư rác qua tập bộ dò thực hiện so khớp.
+ Tính toán và kết luận về khả năng phát hiện của tập bộ dò, hiển thị kết quả tại vùng Results.
Nút Exit: Thoát khỏi chương trình.
3.2. Các quá trình thực hiện chương trình
3.2.1. Quá trình chia file nguồn (Split file)
Input: file chứa số liệu thống kê 58 thuộc tính của thư thường HAM.txt
Output: 10 file thư thường: HSub 1.txt, HSub 2.txt, …, HSub 10.txt
Quá trình thực hiện
Trong cơ sở dữ liệu Spambase Data Set sử dụng có số liệu thống kê từng thuộc
tính của 4601 thư
điện tử
ghi trên từng dòng. Trong đó, có 1813 thư
rác và 2788 thư
thường, ta tạo 2 file HAM.txt chứa 2788 thư thường và SPAM.txt chứa 1813 thư rác. Sử dụng nút Open File Ham trên giao diện để tìm đường dẫn tới file HAM.txt Quá trình chia như sau:
Kiểm tra trong thư mục binDebug đã có các file HSub i.txt (i=1,…,10) chưa, nếu chưa có thì tạo các file này.
Lần lượt đọc từng dòng trong file HAM.txt, sinh ngẫu nhiên một số nn[1,10] ghi dòng dữ liệu trên vào file: HSub nn.txt.
Đóng các file vừa tạo.
3.2.2. Quá trình huấn luyện – Tạo tập bộ dò (Training) Input: Chọn 9 trong 10 file: HSub i.txt (i=1,…,10).