function R (i : ↑ syntax - tree - node) : ↑ syntax - tree - node function T : ↑ syntax - tree - node;
Dùng token addop biểu diễn cho + và - ta có thể kết hợp hai luật sinh thành một luật sinh mới.
R → addop
T {R1.i := mknode(addop.lexeme, R.i, T.nptr)} R1 {R.s := R1.s }
R → ε {R.s := R.i } Ta có hàm R như sau:
function R(i : ↑ syntax_ tree_node) : ↑ syntax_tree_node;
var nptr, i1, s1, s : ↑ syntax_tree_node; addoplexeme : char;
begin
if lookahead = addop then
Có thể bạn quan tâm!
-

 Sử Dụng Độ Ưu Tiên Và Tính Kết Hợp Của Các Toán Tử Để Giải Quyết Đụng Độ
Sử Dụng Độ Ưu Tiên Và Tính Kết Hợp Của Các Toán Tử Để Giải Quyết Đụng Độ -
 Ðịnh Nghĩa Trực Tiếp Cú Pháp Với Thuộc Tính Kế Thừa L.in
Ðịnh Nghĩa Trực Tiếp Cú Pháp Với Thuộc Tính Kế Thừa L.in -
 Cài Đặt Một Máy Tính Tay Sử Dụng Bộ Phân Tích Cú Pháp Lr
Cài Đặt Một Máy Tính Tay Sử Dụng Bộ Phân Tích Cú Pháp Lr -
 Bảng Danh Biểu Lưu Giữ Các Tên Bị Giới Hạn Độ Dài
Bảng Danh Biểu Lưu Giữ Các Tên Bị Giới Hạn Độ Dài -
 Dịch Trực Tiếp Cú Pháp Thành Mã Lệnh 3 Địa Chỉ
Dịch Trực Tiếp Cú Pháp Thành Mã Lệnh 3 Địa Chỉ -
 Biểu Diễn Bộ Tam Gián Tiếp Cho Các Lệnh Ba Địa Chỉ
Biểu Diễn Bộ Tam Gián Tiếp Cho Các Lệnh Ba Địa Chỉ
Xem toàn bộ 200 trang tài liệu này.
begin /* luật sinh R → addop TR */ addoplexeme := lexval; match(addop);
nptr := T;
i1 := mknode(addoplexeme, i, nptr); s1 := R(i1);
s := s1;
end
else s := i; /* Luật sinh R → ε */
return s;
end;
BÀI TẬP CHƯƠNG III. PHÂN TÍCH CÚ PHÁP
3.1. Giải thích ý nghĩa các ký hiệu sau:
factor, Token, LL(k), LL(1), LR(k)
Hướng dẫn:
$: ký hiệu kết thúc
Id: danh biểu các biến
Factor: biểu thức trong dấu ngoặc
||: sự ghép các chuỗi
|: dấu hoặc
α: chuỗi dẫn xuất ε: luật sinh
Token: mã thông báo
LL(k): L đầu tiên viết tắt việc quét từ trái sang phải Left to right, L tiếp 3.2.Cho văn phạm
S aABe A Abc | b B d
Chuỗi nhập: abbcde Hãy Phân tích bottom-up
Hướng dẫn:
theo đưa ra suy dẫn trái nhất (leftmost derivation)
LL(1): thông thường k= 1 nên viết LL(1) hoặc LL sẽ không bị hiểu nhầm LR(k): k là một số chỉ việc nhìn trước k ký tự để quyết định hành động phân tích mỗi bước

3.3. Cho văn phạm sau
E E or T | T T T and F | F F (E) | not F| id
a. Nêu các thành phần văn phạm phi ngữ cảnh
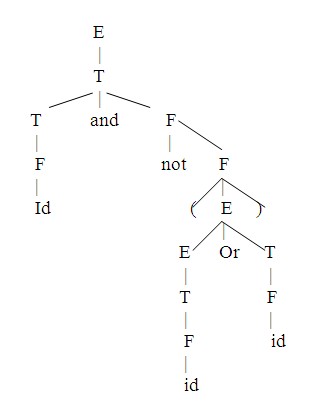
b. Vẽ cây phân tích cú pháp cho chuỗi nhập: id and not (id or id)
c. Vẽ cây cú pháp chú thích cho chuỗi nhập ở câu b
d. Thành lập lược đồ dịch
e. Khử đệ qui trái nếu có
f. Viết thủ tục phân tích cú pháp, đoán nhận trước Hướng dẫn:
a. G= ({E,T,F}, {or, and, not, id, (,)}, P, E}
b. Cây phân tích cú pháp
c. Vẽ cây cú pháp chú thích

d. Thành lập lược đồ dịch

3.4. Cho văn phạm G chứa các luật sinh sau: Q → Q or T | T
T → T and F | F
F → ( Q) | not F | a
a) Hãy xây dựng bộ phân tích cú pháp dự đoán cho văn phạm.
b) Vẽ cây phân tích cú pháp cho câu nhập : a and not ( a or a ).
3.5. Cho văn phạm G chứa các luật sinh sau: S → AB
A → Ab | a B → cB | d
a) Xây dựng bộ phân tích cú pháp thứ tự ưu tiên cho văn phạm .
b) Hãy dùng bộ phân tích cú pháp đã xây dựng để phát sinh cây phân tích cú pháp cho câu nhập: abccd
3.6. Cho văn phạm mơ hồ như sau: S → AS | b
A → SA | a
a) Xây dựng họ tập hợp mục LR(0) cho văn phạm này.
b) Xây dựng bảng phân tích cú pháp SLR .
c) Thực hiện quá trình phân tích cú pháp SLR khả triển cho chuỗi nhập : abab
d) Xây dựng bảng phân tích cú pháp chính tắc .
e) Xây dựng bảng phân tích cú pháp LALR .
CHƯƠNG IV. PHÂN TÍCH NGỮ NGHĨA VÀ BẢNG DANH BIỂU
Nội dung chính:
Người lập trình đã đưa vào mã nguồn những danh biểu (identifier), đó là những tên hàm, tên biến, tên các bảng dữ liệu trong cơ sở dữ liệu do mình thiết kế, tên các field trong bảng …. Nói chung đó là các danh biểu người dùng đã đưa vào mã nguồn. Việc đưa vào này người sử dụng hiểu nhưng muốn máy tính hiểu, lập trình viên phải chủ động khai báo trước với trình biên dịch, danh biểu này tên gì, kiểu gì, loại gì: tên(là chuỗi ký tự), kiểu(nguyên, thực, chuỗi), dạng(một biến, một cấu trúc). Bộ phân tích từ vựng khi phân tích mã nguồn đã đưa các danh biểu này lưu vào trong một bảng gọi là bảng danh biểu. Phân tích ngữ nghĩa chính là bước kiểm tra để khi máy tính thực hiện các chỉ thị có liên quan đến danh biểu này thì biết truy xuất đến đâu để tìm danh biểu. Kiểm tra các danh biểu này đã được lập trình viên định nghĩa chưa (thực hiện quy định khai báo của ngôn ngữ lập trình) và sử dụng danh biểu có đúng với những gì đã khai báo không.
Chương này nêu ra cách thức bộ phân tích ngữ nghĩa thực hiện việc kiểm tra ngữ nghĩa các danh biểu do người dùng đưa vào mã nguồn.
Mục tiêu
Giúp cho bạn đọc hiểu để chương trình mà con người hiểu ( mã nguồn), muốn biên dịch thành dạng mã máy mà máy tính hiểu và thực hiện, những gì con người hiểu nhưng đã thông qua bước khai báo cho máy tính hiểu chưa và việc sử dụng các danh biểu này có đúng với khai báo không.
Để thông hiểu nhau, cả hai phải theo quy ước là sử dụng các danh biểu cài đặt sẵn và khi đưa vào và sử dụng danh biểu mới (một từ mã của lập trình viên), phải sử dụng các danh biểu cài đặt sẵn định nghĩa lại cho máy tính hiểu.
Yêu cầu chung
Đọc giả hiểu về việc sử dụng ngôn ngữ trong việc giao tiếp .
TÀI LIỆU THAM KHẢO CHƯƠNG 4:
[1] Dương Tuấn Anh (1986), “Giáo trình trình biên dịch” - NXB Đại Học Bách Khoa TPHCM
[2] Phạm Hồng Nguyên, “Giáo trình Chương trình Dịch” - NXB Đại Học Quốc Gia Hà Nội
[3] Phan Thị Tươi (2011), “Trình Biên Dịch” - (Trường Ðại học kỹ thuật Tp.HCM) - NXB Giáo dục
[4] Automata and Formal Language. An Introduction – Dean Kelley – Prentice Hall, Englewood Cliffs, New Jersey 07632.
[5] Compilers : Principles, Technique and Tools - Alfred V.Aho, Jeffrey D.Ullman - Addison - Wesley Publishing Company, 1986.
[6] Compiler Design – Reinhard Wilhelm, Dieter Maurer - Addison – Wesley Publishing Company, 1996.
[7] Design of Compilers : Techniques of Programming Language Translation - Karen A. Lemone - CRC Press, Inc, 1992.
[8] Modern Compiler Implementation in C - Andrew W. Appel – Cambridge University Press, 1997