4.3. The machine translation system uses annotated selections
When translating a machine with a structure of two different source and target languages, the following problems always arise:
- Find exact word meanings – resolve ambiguities and word categories.
- Fix the difference in morphology of the two languages.
- Fix differences in word order.
These problems require parsing to be fully resolved. Since the associative grammar represents a direct association between words, the above processing is made easier.
Annotated selection form
Annotated Disjunct (ADJ) stores the meaning of a word when it is associated with a certain pattern. For example, the word “she” with the form ((O) (NtPd)) would mean “her”, while going with the form (( )(NtPd,SV)) would mean “she”, or when goes with the form (( )(SHA)) which in turn means “aunt” (the SHA link is implicit, use linking phrases like “my aunt”).
Annotated selection is a combination of (, , ) where the annotated collection belongs to the source word. The target word is the meaning of the source word in the target language when used with the corresponding verb form. In the Vietnamese-English translation system, annotated forms of the sentence “I love her” will be:
(I, I,(()(SV))))
(love, love, ((SV)(O))))
(she, her, ((O)(NtPd)))
Maybe you are interested!
-

 Vietnamese linking grammar model - 22
Vietnamese linking grammar model - 22 -
 Development Situation Of Machine Translation In Vietnam
Development Situation Of Machine Translation In Vietnam -
 Language Difference Between Vietnamese And English
Language Difference Between Vietnamese And English -
 Vietnamese linking grammar model - 26
Vietnamese linking grammar model - 26 -
 Test Results With Annotated Selection-Based Translator
Test Results With Annotated Selection-Based Translator -
 Vietnamese linking grammar model - 28
Vietnamese linking grammar model - 28
(hey,!,((NPd)())))
Sign ! Indicates the word to be deleted during translation.
As discussed in the first chapter, the association parser does not use the type word labeler. The word type is discovered through its associations. Therefore, not only avoid errors in word type, but also find a more precise meaning for the word.
In order to build a translator based on annotated collection, the three most important problems to be solved are:
- Find the meaning of the word
- Change sentence structure
- Finalize the translation
Figure 4.2. Below is a description of the architecture of the Vietnamese – English translation system based on annotated anthology. The system consists of 3 main parts:
- The preprocessor performs word separation for the input sentence. The system uses the magnetic separator vnTokenizer.
- The parser performs parsing using the link parser. In the limited time, the thesis does not address the problem of translating compound sentences, so the result obtained from the parser is a link analysis of a single sentence or a compound sentence with two clauses. Through analyzing the found links, the system determines the properties related to person, number, tense, form…
- The compilation that allows the creation of translations includes:
- Translate some special phrases: “going to school”, “they”…
- Look up word meanings according to selection form in ADJ dictionary.
- Change word morphology based on found attributes (realization).
- Find the best overall translation option.
Apart from the parser, the ADJ dictionary and the translation rule set are the most important components of the translation system. Other components such as the list of irregular verbs, the dictionary of idioms, the English corpus also effectively support the translation system to create good quality translations.
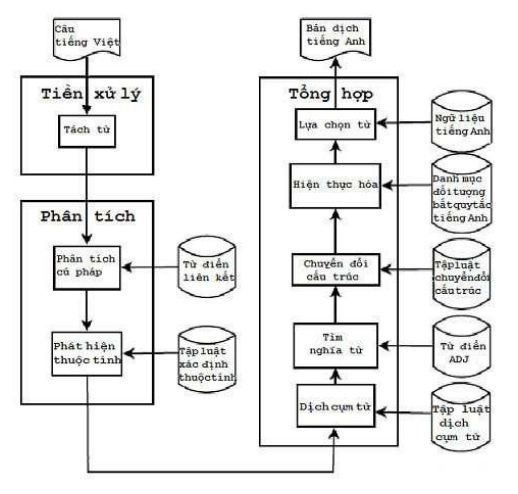
Figure 4.2. Architecture of an annotated collection based translation system
4.3.1.Find word meaning in ADJ dictionary
The ADJ dictionary will gather all the ADJs of the language. In principle, the ADJ dictionary must include the triads: word, colloquial form and the meaning of words in English when used with the corresponding tense. However, the number of forms of each word is very large. When the bilingual dictionary has nearly 100,000 entries, each of which is associated with all forms of the source word, the size of the ADJ dictionary will be extremely large. The thesis has edited the linked grammar dictionary towards a formula showing only one usage of the word.
Thus, with the same structure as the linked grammar dictionary, the ADJ dictionary has the English meaning of the word in addition to the formula, and the ADJ dictionary can replace the linked grammar dictionary in the analysis phase. syntax.
Here is an example of an excerpt from the ADJ dictionary:
because_because,because because: (GT_DT+ or CL+) & {PH+} & (EV- or (CO+ or QHT+))
reason_ reason!
is_do,is_because because
that: R- & CL+
/verb.transitive.trans: ((({TĐT1-} & {TĐT2_1-} & {RpVt- or RtVt- or
RfVt- or RhVt-} & {TĐT4-}) or TT_ĐT- or ({TT_ĐT-} & TĐT5-)) & {SV- or
ĐT_ĐT- or THI_ĐT- or LT_ĐT- or BI-} & {ĐT_XONG+} & {O+} & {ĐT_TT+} &
{ĐT_GT+} & {ĐT_LT+} & {THT- or THS+} & ({EV+} & {SDT5- or CL-} & {CO-}))
or ({SV-} & BI-)
In the ADJ dictionary, the entry /verb.transitive.trans is the entry containing the linking formulas of transitive verbs (with some exceptions which have their own linking formula) so it should be linked to a file meaning each verb. words with the linked formula stated. Here is the contents of the first lines of the file:
a_dua ape
a_dua flatter
a_dua follow
a_dua jawn_upon
a_tong act_as_an_accomplice_to
a_to imitate
know_well know_well
understand realize
Empty strings in a dictionary are represented by a “!”.
4.3.2.Development of translation laws
As shown in the translation diagram of the system in Figure 4.2, the translation system needs to use three sets of rules related to different jobs: attribute detection, phrase translation, structure transformation. The following is a detailed description of the typical rules and the context-free grammar that generates the rule.
In the rules, the symbols W1, W2, W3 represent words, D1, D2, D3 indicate the sequence of connection names that belong to the left or right list of a certain type.
Attribute detection rule
Attributes here are the information that needs to be stored for each word in order to transform it into the proper form, for example, plural nouns, tenses, verb forms, pronoun persons, comparative construction types. (equal comparison, superior comparison, first-order comparison). Here are some examples of attribute detection rules.
- Rules for detecting plural properties of nouns. Based on the DpNt connection of the plural adjectives “thes”, “thes”, and the “majority” it is possible to add the value PLURAL to the attribute of the noun associated with them:
W1(D1)(DpNt) W2(DpNt)(D2)
→ W1’W2’(number = PLURAL) (4.1)
- The law of detecting verb tenses. The tenses of verbs are shown by links with adverbs of tense. The past tense is represented by the links RpVt, RpVs, future tense RfVt, RfVs, continuous RcVt, RcVc, perfect RhVt, RhVc. Links of the past or future tense that appear in the analysis will be treated according to the rules that determine the tense attribute for verbs. With more complex tenses such as continuous or perfect tenses, not only the verb form changes but also other words such as “to be”, “to have”, so the attribute is evaluated as a property. form calculation.
W1(D1)(RpVt) W2(RpVt)(D2)→
W1’W2′(tense = PAST) (4.2)
W1(D1)(RfVt) *(RfVt)(D2) →
W1’W2′(tense = FUTURE) (4.3)
W1(D1)(RtVt) W2(RtVt)(D2) →
W1’W2′(tense = PRESENT) (4.4)
W1(D1)(RhVt) W2(RhVt)(D2) →
W1’W2′(tense = PRESENT_PARTICIPLE) (4.5)
- The law of determining the person of pronouns: for pronouns, there is no need to rely on the association because in Vietnamese the number of pronouns is quite small, so the law is based on the word value and type of word to identify person:
I[p]→ I(person = FIRST) (4.6)
anh[p]→ you (person = SECOND) (4.7)
it[p]→ he (person = THIRD) (4.8)
The symbol [p] in the rule represents the type of word that stands immediately to the left. This information is available in the linked dictionary.
After determining the person of the pronoun, the personal attribute must be spread to the verb to conjugate the correct person, especially the verb “is” because the corresponding verb “to be” is different in all aspects. All persons are represented by the following laws:
W1(D1)(SV) W2(SV)(D2)
→ W1’W2’(person = W1’.person) (4.9)
Verb “is”
W1(D1)(DT_LA) W2(DT_LA)(D2)
→ W1’W2’(person = W1’.person) (4.10)