CHAPTER 4
MACHINE TRANSLATION SYSTEM
USE ANNOUNCEMENT FORM
4.1. Machine translation overview
4.1.1. Development situation of machine translation in Vietnam

Machine translation is a very interesting field of IT due to the need to translate a large number of documents in the fastest time. According to Dinh Dien [3], the main approaches of machine translation are as follows:
- Law-based approach: is the approach of many translation systems related to Vietnamese. This direction is effective when translating on a small scale, however, the effort to build conversion systems is very large.
- Statistical approach: Difficult to achieve high quality especially when the corpus is limited. Difficult to monitor intermediate outcomes for intervention.
- Knowledge-based approach: requires “understanding” the entire text, which is very difficult to achieve.
- Approach on example: simple in theory, can give high quality if the text is simple, the structure is repeated.
- The corpus-based approach: when there is a large corpus, use machine learning to draw language rules. Easy to update changes and extensions of the language.
- In addition, a hybrid method between the above methods is the choice of many translation systems.
Currently, there are a number of machine translation systems in Vietnam such as:
- Nacentech’s EVtran-Vetran system chaired by Dr. Le Khanh Hung [10].
- Vietgle system of Lac Viet.
- Vietnamese – English translation system chaired by Associate Professor Phan Thi Tuoi [124].
- English – Vietnamese translation system EVTS chaired by Assoc. Ho Si Dam [93].
- Translation system of computer documents of the University of Natural Sciences – Vietnam National University, Ho Chi Minh City [3].
- Some translation systems by Vietnamese researchers at JAIST [115].
- Google Translation system.
- The English – Vietnamese translation system is based on studying the law of double conversion from bilingual documents by Assoc. Dinh Dien [3].
The above systems are mainly English – Vietnamese translation systems to take advantage of the rich linguistic resources of English. The number of Vietnamese – English translation systems is very small: VEtran system, Google Translation, some experimental systems of Ho Chi Minh City Polytechnic University, JAIST… Among them, two systems are widely disseminated. is Google’s translation system according to the statistical approach, the VEtran system according to the rule-based approach.
Maybe you are interested!
-

 Viterbi Type Algorithm To Find The Best Analysis
Viterbi Type Algorithm To Find The Best Analysis -
 Vietnamese linking grammar model - 21
Vietnamese linking grammar model - 21 -
 Vietnamese linking grammar model - 22
Vietnamese linking grammar model - 22 -
 Language Difference Between Vietnamese And English
Language Difference Between Vietnamese And English -
 The Machine Translation System Uses Annotated Selections
The Machine Translation System Uses Annotated Selections -
 Vietnamese linking grammar model - 26
Vietnamese linking grammar model - 26
The difference between Vietnamese and English is the difference between an Eastern language and a Western language, focusing in a few main areas: morphology, word order, non-adjacent dependency relations. long distance dependency). Associative grammar, due to its complete lexicalization, is able to demonstrate morphological dependence well (according to Schneider [109]). Word order can also be detected from the association between words. Some relationships between non-adjacent words can be represented by associations, others cannot because of the violation of the planarity condition.
After building a model of Vietnamese associative grammar, the thesis tests the machine translation model as a demonstration of the model’s ability to represent Vietnamese features.
The associative grammar model has been applied to build translation systems from English to European languages such as German [135], Russian [134], Turkish [133] or Sanskrit – a language The Indian language [71] is based on the corresponding conversion of the links between the two languages (the English-Russian translation system alone has a statistical combination). These systems have responded quite well to morphological changes such as tense, form, gender, number, and manner. However, when the source language and the target language have large differences in syntax and grammar, it is difficult to produce quality translations. That is also the reason the above systems only stop at the test level for a small set of sentences. Another translation system based on linked grammar is the translation system of Petronas University, Malaysia [29], [30], [129] translating from English to Indonesian. The system allows to look up word meanings, transform syntax through Annotated Disjunct (ADJ). The system has given quite good translation results into Indonesian – a Southeast Asian language that does not have as rich resources for automatic processing as Vietnamese.
The translation system of the thesis has selected the ADJ tool. Each ADJ essentially contains: a word of the source language, its suffix, and the corresponding meaning of the word in the target language when used with the given collocation. ADJ dictionary allows to determine the exact definition of words according to the topology in the sentence.
Building a syntax conversion rule is a must for every rule-based translation system. With two main issues mentioned by Nguyen Phuong Thai [115] group, which are differences in morphology and word order, the linking grammar model proves to be very advantageous to transform word morphology, while changing word order. Wording is also quite easy because the structure of the link analysis is quite simple.
4.1.2. Methods for assessing the quality of machine translation
Evaluating the quality of machine translation is difficult. Even when the translation is evaluated by humans, there are many different opinions about the quality. For automatic machine translation, it is necessary to provide criteria to quantify the accuracy of the translation. The following two criteria are of interest to most automated assessment methods:
- Adequacy: The amount of information of the reference translation contained in the evaluated translation.
- Fluency: Does the translation accurately represent the commonly used natural structures of the target language.
The main approaches to automatically evaluate translation quality are: based on accuracy (BLEU, NIST) [51], based on coverage (METEOR), based on Levenshtein distance assessment, based on Error rate…
The BLEU (BiLingual Evaluation Understudy) method was proposed by Papineni [100]. This is a method that uses a weighted average of the variable-length phrase comparisons of the translation in question with the reference translation, combined with an assessment of the translation length. BLEU is most commonly used to assess the quality of machine translation at home and abroad. The thesis has chosen the BLEU measure to evaluate the translation quality. BLEU score is calculated according to the formula:
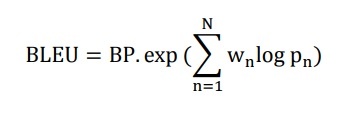
or on a logarithmic scale:
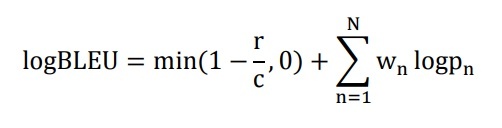
In which, BP is the short translation penalty (brevity penalty) calculated by the formula:
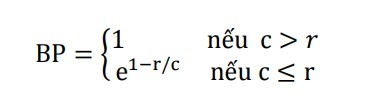
c is the translation length under consideration, r is the reference translation length.
pn is the matching n-gram ratio between the translation under consideration and the reference translation, calculated by the following formula:
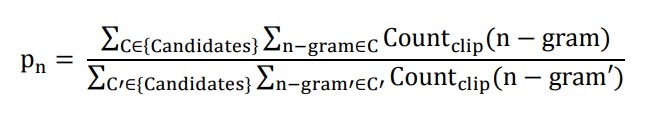
Here n-gram is related to the translation under consideration, and n-gram’ is related to the reference translation.