Left side
The left side of the rule consists of a number of words and forms to link those words together. There is a slight difference between the anthology of words and the anthem described in the rule. The selection form in the rule only states the connections that the rule will handle. Before and after these joins in the join form of each word there can be other connections. For example, the join form ( )(SA, SA) appearing in the rule means that the rule will deal with two consecutive named joins. SA in the right list and handle no connections in the left list.

Example: The following left-hand side describes the phrase “going to school”. This phrase consists of the word “go” and the word “learn.” The two words are linked together by a DI . link
đi(SV)(DI) học(DI)()
Meanwhile, the left side
anh(O)(NtPd) *(NtPd)()
describe a phrase consisting of the word “he” and any word with an NtPd link to the left (“he.” “ta”,”that”). This phrase will be on the left hand side of the law that defines the English definition as “him”.
Right side
Maybe you are interested!
-

 Language Difference Between Vietnamese And English
Language Difference Between Vietnamese And English -
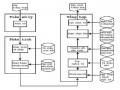 The Machine Translation System Uses Annotated Selections
The Machine Translation System Uses Annotated Selections -
 Vietnamese linking grammar model - 26
Vietnamese linking grammar model - 26 -
 Vietnamese linking grammar model - 28
Vietnamese linking grammar model - 28 -
 Vietnamese linking grammar model - 29
Vietnamese linking grammar model - 29 -
 Vietnamese linking grammar model - 30
Vietnamese linking grammar model - 30
The right-hand side lists the string to be replaced on the left-hand side, which can contain the following objects:
- $i (i = 1, 2, 3…) the meaning of the word ranked i on the left side.
- Function calls with the structure
( ).
The following four functions are used in the rules:
set-string (word, new-string) Replace word word with new string new-string.
set-feature (word, name, value) Set the value of the attribute by name only.
copy-feature(word, name, ref ) Copies attribute value by name of word word to name attribute of word by ref .
remove-feature (word, name) Removes the attribute named name of the word only by word.
Code of construction according to the above grammar is stored in an XML file with the following structure:
< !−− luat trong nhom −−>
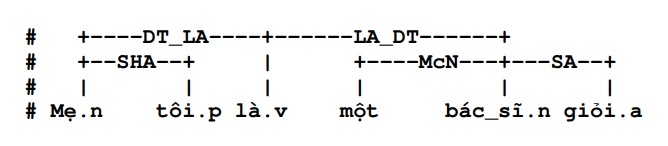
excludes=“ past,future”> … In this set of rules, Rules are read from XML files, analyzed and processed automatically according to the grammar. With a fairly simple syntax, users can easily add new rules. The main laws are listed in Appendix 4. 4.3.3.Complete translation sentences After detecting the attribute, moving the position, and transforming the appropriate morphology, there are still some problems to be done to create a good quality translation. That is: – Nouns act as adjectives. When translating into English, it needs to be converted into an adjective, for example “gold medal”, gold here is a word indicating material with a CH link, it needs to be converted to the corresponding adjective. – Adjectives or verbs that come after “thing”, “work” convert the whole phrase into a noun. The thesis has built a set of laws that cover these phenomena Word meaning selection: Although we have gone through many stages of de-ambiguation in the parsing process, here we can still encounter the phenomenon of word meaning ambiguity, that is when a Vietnamese word corresponds to many language meanings. He is different. For example, the word “do” can mean “make” or “manufacture” (Note that the word “do” with the corresponding meaning “work” is associated with a different formula than the word “do” has two meanings above). Thus, even if only a single association analysis is selected, there can still be many translations corresponding to different combinations of words. The problem here is to choose the most “fluent” combination, that is, the way most commonly used by native speakers. The thesis has solved by using the English corpus and calculating the probability to choose the best translation. The corpus chosen is a reduced COCA (containing only those n-grams appearing three or more times) [136]. Sentence S with words w1, w2,. . .wn is selected based on the following criteria: 4.3.4.Test results with annotated selection-based translator As the scope of interest was limited from the beginning, testing the translation system with ADJ is to illustrate the performance ability of Vietnamese associative grammar, but there is still much to be improved to become a popular translation tool. . However, building a test corpus is also a challenge. Currently, there is no standard corpus for Vietnamese – English translation, so we have built our own corpus. The translation system is built using the Java engine to integrate with the parsers. The corpus consists of 336 sentences collected from books teaching Vietnamese to foreigners at an advanced level [18]. The advantage of this sample set is that they are written by Vietnamese professors and the English translation has been carefully vetted. Here is an example that illustrates the operation of the translation system to process some sentence patterns: 1.”My mother is a good doctor” Parse result: The selection forms found for each word are: mother: ()(SHA DT_LA) me: (SHA)() is: (DT_LA)(LA_DT) one: ()(McN) Doctor: (McN LA_DT)(SA) good: (SA)() Để dịch câu này, các luật sau đã được áp dụng The translation given by the thesis system and the Google system is the same: My mother is a good doctor Translation results with VEtran: My mother is a jurisprudent physician. The translation results of the three systems are not significantly different. The system of the thesis and Google has a comparison with the sample data when choosing words, so the translation is “good doctor” while VEtran uses the phrase “jurisprudent physician” in terms of meaning in the Vietnamese – English dictionary. realistic sense. 2. “Cheetah is the fastest animal in the world” Parse results Types of recruitment received: cheetah: ()(DT_LA) is: (DT_LA)(LA_DT) species: ()(Animal) Animals: (L.A. DT)(SA) fast: (SA)(TT_SS) most: (TT_SS)(NHAT_DT) world: (NHAT_DTv)() The translation process through many rules is depicted in Figure 4.4 below: Figure 4.4. The process of translating the sentence “The cheetah is the fastest animal in the world” Performance results of the ADJ . translation system Cheetah is the quickest animal world Cheetah is world’ s fast animal the kind. Alert hunt is the world’s fastest animal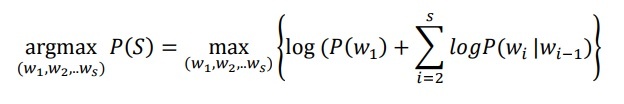

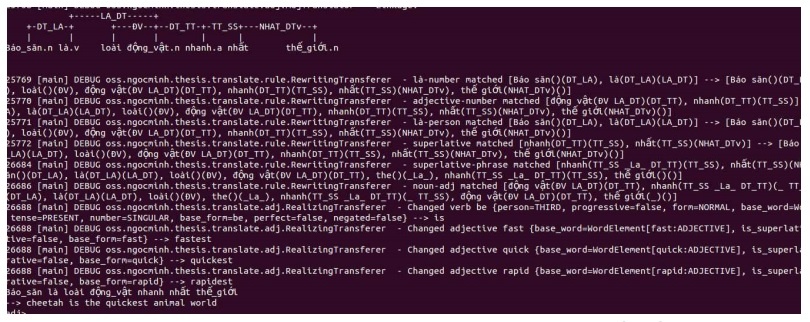
Results obtained with VEteran:
Results given by Google: