All three translations have limitations. The ADJ translation failed to detect the possessive relationship of the word “world” while the VEtrans translation translated it but failed to translate the top-level comparative adjective and mistranslated the word “species”. Google translation translates very well the phrase “fastest in the world” but has an error in the word “hunting leopard”.
Comparing the entire corpus, it can be seen that with commonly used phrases, Google gives more “real” results. However, the results of the translation system of the thesis and VEtran are usually more correct in terms of syntax and morphology, in which the translation system of the thesis is somewhat “fluent”, due to the connection established to each individual word. separate. Obviously, combining different methods will improve the quality of the translation.

Currently, because there is not a corpus large enough to completely solve the problem of ambiguity in parsing, the accuracy of the parser is still not high. For the corpus of 336 conversation sentences, there are still many phrases in spoken form, not yet in the corpus of all written sentences, so the return results of the parser are still low (precision): 22.7%, coverage (recall): 28.8%, F-score: 0.28). If the parser results are used as-is, the quality of the translation system may not be accurately assessed. To study the overall effect of the components in the system on translation quality, the thesis has tested on the following two systems:
ADJ1: Allows to eliminate possible errors in the parsing process by defining some constraints to choose the correct parsing of the sentence, namely foreshadowing certain pairs of words that are certain to occur. link. This is also the technique used in [94] to limit the number of analyses. The input sentence has corrected the result of word separation. Parser accuracy for ADJ1 is 80.2%, coverage 81.4%, F-score 0.81.
ADJ2: Does not allow binding and word splitting.
Although the dataset is still small, the thesis has used the BLEU method [100] with parameters n= 2, 3, 4, 5 to compare with the results achieved by VETran and Google. The obtained results are shown in Table 4.4.
Table 4.4. Compare the results of translation systems
| VEtran | ADJ1 | ADJ2 | ||
| 2 | 0.169816 | 0.209987 | 0.263627 | 0.157450 |
| 3 | 0.133085 | 0.140612 | 0.181787 | 0.091807 |
| 4 | 0.109895 | 0.096798 | 0.127502 | 0.059650 |
| 5 | 0.090472 | 0.069292 | 0.091302 | 0.036461 |
Maybe you are interested!
-
 The Machine Translation System Uses Annotated Selections
The Machine Translation System Uses Annotated Selections -
 Vietnamese linking grammar model - 26
Vietnamese linking grammar model - 26 -
 Test Results With Annotated Selection-Based Translator
Test Results With Annotated Selection-Based Translator -
 Vietnamese linking grammar model - 29
Vietnamese linking grammar model - 29 -
 Vietnamese linking grammar model - 30
Vietnamese linking grammar model - 30 -
 Vietnamese linking grammar model - 31
Vietnamese linking grammar model - 31
The chart in Figure 4.5 allows to compare the BLEU scores of the above translation systems of the thesis with two popular Vietnamese – English translation systems, Google Translation and Vetrans.
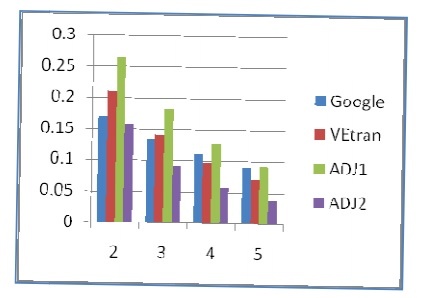
Figure 4.5. Compare BLEU scores of systems
The problem of ambiguity when applying the law
This is a problem that all rule-based translation systems must deal with. However, with the strict rules of the associative grammar model, the probability of ambiguity occurring is very small. It is for the following reasons:
- The system’s translation rule set includes three subsets. The order of applying the rule as shown in the diagram in Figure 4.2 is: attribute definition → phrase translation → structure transformation. The ambiguity when applying the rule (if any) can only occur in each subset. However, with associative grammar, the rule is only used when both conditions are satisfied:
– The word under consideration appears in the law.
– All word associations mentioned in the rule must be satisfied.
- In addition, the exclude attribute of some rules (described above) also helps to reduce ambiguity. Therefore, when parsing a given sentence, it is very unlikely that ambiguity will occur when applying the rule. Among the three sets of rules of the system, there is no rule that can cause ambiguity in the selection process. The ambiguity mainly occurs when analyzing, for example, the two sentences “I sell flowers very quickly” and “I sell flowers very fresh” can lead to confusion when there is no indication that the adjective indicates the quality. modifies the word “flower” or the word “sell”. However, once the analysis has been determined, if it is:
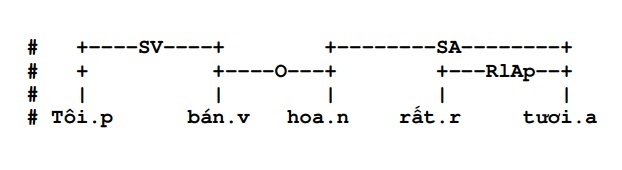
then the law of changing word order applies. If the selected analysis is:
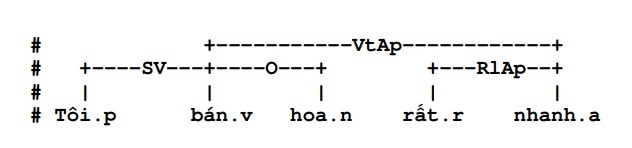
then the law on changing the meaning of the word “fast” to English adverbs is applied.
4.4. Conclude
The translation system uses annotated anthology built for the purpose of illustrating the Vietnamese representation of the associated grammar. However, if evaluated as a translation system, the results are also remarkable: with good results of the word separator and parser, the system achieves slightly better results than Google and VEtran . Note that, to achieve this result, the system’s translation rule set does not have up to 300 rules, much less than VEtran and does not need to use a bilingual corpus. Although it is only a test on a small corpus, it can be seen that the ability to use associative grammar models for machine translation problems is very promising.
Although certain results have been achieved in Vietnamese-English machine translation, the system still has unresolved problems:
- Translate sentences with coordination structure using large connections, for example, the Vietnamese phrase in [4]“a healthy, tall and kind student”. Translating this type of sentence requires an accurate parsing, which can only be achieved by de-ambiguating the conjugation in sentences containing the words “and” and commas.
- Translation of compound and complex sentences: Compound sentences and complex sentences contain two or more cores, in which complex sentences contain one core that covers the remaining cores [1].In the sample corpus, there are some sentences with 2 clauses, but the translation quality of these sentences is not good. It can be seen that the processing of compound sentences is feasible because we have built a parser that can handle conjugate ambiguities quite well and parse compound sentences with many clauses.
The limited recognition of clauses in complex sentences, as well as the subject cluster components, sometimes requires the establishment of a link between non-adjacent words. The current treatments to split clauses or solve ambiguity about adverbial phrases are all in the direction of machine learning approach on large corpus. The system will continue to be developed in this direction when a large enough sample corpus has been built.
Another problem that also causes difficulties in processing: translating phrases of the form n – 1 (n from Vietnamese to 1 word in English). In addition to the very common phrases that the thesis has dealt with, the support of idiom dictionary and bilingual sample corpus is needed.
With the completely lexicalized feature of the associative grammar, the translation rules of the system show the very own and unique characteristics of the source and target languages. This job definitely requires a deep understanding of the syntax and grammar of both languages. The translation code can be completely changed if the source-target language pair is changed, which means it is difficult to use for another language pair. However, to extend the translation system, it may be of interest to use tools that allow linguists to define syntax rules [31]. If this approach is followed, the chart parsing from the link grammar is also easier than other models because the link analysis is already in the form of a graph. Thus, it is possible to take into account the possibility of extending the translation system to other language pairs.
As mentioned, because there are not enough resources to build a complete machine translation system, the thesis’s machine translation system aims at illustrating the Vietnamese representation of the associated grammar. However, with the translation quality is quite convincing, combining this translation model with the translation system according to the statistical approach will definitely improve the translation quality because it can combine the fluency of the statistical method. with precision of morphological and syntactic variations. One of the examples of that is the combination of link analysis to complete the translation in the machine translation system based on the example. The percentage of translated sentences that are completely correct with the sample sentences has increased quite a bit. The combination of statistical approach and linking grammar is the development direction of the system in the coming time.