1.4. Ý nghĩa của nghiên cứu
Ý nghĩa khoa học:
- Nghiên cứu đưa ra cách xây dựng mạng tương tác Y học áp dụng trí tuệ nhân tạo bằng các thuật toán khác nhau.
- Các thuật toán được sử dụng có độ chính xác khác nhau khi áp dụng dữ liệu văn bản Y khoa được đưa vào máy tính, nghiên cứu này cho phép đánh giá được sự chính xác của từng thuật toán đối với bộ dữ liệu đã sử dụng.
- Diễn giải được cách thức xử lý thông tin của máy tính, đánh giá kết quả được đưa ra, từ đó có thể đánh giá và điều chỉnh nếu có sai sót trong việc đưa ra kết quả đánh giá.
Giá trị thực tiễn:
- Phục vụ cho nhân viên Y tế trong việc đưa ra chẩn đoán và quyết định điều trị cho bệnh nhân.
- Cung cấp công cụ hữu ích với tính cập nhật cao phục vụ trong Y tế.
- Xử lý được lượng thông tin lớn một cách nhanh chóng và chính xác.
Giá trị giáo dục:
- Trang bị cho chính mình các kiến thức về trí tuệ nhân tạo và ứng dụng trong Y học, cụ thể là ứng dụng trí tuệ nhân tạo vào xây dựng mạng tương tác Y học.
- Nghiên cứu có thể làm tài liệu tham khảo cho học sinh và sinh viên của các trường đại học Y Dược.
- Nghiên cứu có thể dùng làm tài liệu tham khảo và phát triển cho các đề tài sau này dựa vào những kết đã thu được.
CHƯƠNG 2: ĐỐI TƯỢNG VÀ PHƯƠNG PHÁP NGHIÊN CỨU
2.1. Đối tượng nghiên cứu
Dữ liệu được lựa chọn để phân tích là các Y văn, được viết bằng tiếng Anh và được sử dụng để giảng dạy cũng như áp dụng lâm sàng của các cơ sở giáo dục, Y học đã được công nhận trên thế giới, cụ thể các Y văn này là các sách, giáo trình của trường Đại học Oxford. Các Y văn này được biên soạn bởi các giáo sư, phó giáo sư và có sự tham gia của các giảng viên chuyên ngành, các thạc sỹ, các học giả, … là những người có kiến thức, nghiên cứu chuyên sâu trong lĩnh vực nhất định. Các Y văn tiếng Anh được viết rất chi tiết, đầy đủ và sử dụng từ ngữ chuyên ngành một cách chính xác chuẩn Quốc tế phù hợp với tất cả độc giả.
Dữ liệu được thu thập tại trang web: https://oxfordmedicine.com.
2.2. Phương pháp nghiên cứu
2.2.1. Xây dựng mạng
2.2.1.1. Tiền xử lý dữ liệu
Hệ thống tiền xử lý dữ liệu (Preprocessing) của Python (ngôn ngữ lập trình)
[11] được sử dụng để đọc và nhận diện văn bản thành các trang, từ. Các hình vẽ, mục lục, tài liệu tham khảo, phụ lục đều bị loại bỏ. Các từ tiếng Anh được chuyển về dạng từ gốc, ví dụ “program”, “programs”, “programer”, “programing” đều được chuyển thành “program”. Các từ không mang nghĩa đặc trưng cho Y học hay các lĩnh vực đặc thù (còn gọi là stopword) cũng bị loại bỏ. Sau quá trình này, tất cả các trang trong cùng một nhóm sách được chia ngẫu nhiên thành các tập con, mỗi tập con gồm khoảng 1000 trang và việc có nhiều tập con được dùng cho kiểm định giả thuyết thống kê, đánh giá mức độ tin cậy của giá trị tương tác.
2.2.1.2. Bán tự động đề xuất từ khóa
Các từ khoá có thể được tạo ra bằng cách chỉ định trực tiếp bởi con người hoặc do máy đề xuất căn cứ vào tần suất xuất hiện. Ở đây, chúng tôi kết hợp cả hai phương thức trên. Thuật toán học máy tiến hành đếm số lần xuất hiện của mỗi từ có trong dữ liệu. Bằng cách đưa vào giá trị ngưỡng, thuật toán tự động loại bỏ các từ có tần suất
dưới ngưỡng. Bước tiếp theo, chúng tôi lọc thủ công tối đa các từ hợp lý (liên quan đến Y học) làm từ khoá.
2.2.1.3. Lượng hóa ma trận tương tác
Lượng hoá ma trận tương tác: giá trị tương tác giữa các thực thể xuất phát từ vị trí tương đối của chúng trong văn bản. Chúng xuất hiện càng gần nhau thì khả năng có sự tương tác giữa chúng càng lớn và ngược lại. Trong định lượng, chúng tôi xây dựng thử nghiệm một hàm đánh giá tường minh f cho các cặp từ khoá (A, B) thoả mãn giả thuyết trên.
Cụ thể f(A, B) lượng hoá giá trị tương tác của B với A, được gọi là “A cites B” nghĩa là sự xuất hiện của A kéo theo sự xuất hiện của B. Gọi x và y lần lượt là thứ tự của câu chứa từ khoá A và B. Do giả thuyết về A xuất hiện trước rồi mới kéo theo B nên chúng ta chỉ lấy các cặp (x, y) thoả mãn x≤y. Khoảng các câu giữa cặp (A, B) này được định nghĩa là d(A, B) = (y–x).
Giá trị tương tác của A kéo theo B trong tập dữ liệu là một phép tổng:
n m
F(A, B) = ∑ ∑ f(d(Ax, By))
x=0 y≥x
Trong nghiên cứu thử nghiệm, chúng tôi sử dụng f là hàm Laplacian [36] với ý nghĩa mức độ tương tác sẽ giảm hàm mũ bậc nhất theo khoảng cách: f(x) = e−αx (α là hệ số dương).
Với định nghĩa trên, giá trị tương tác là một số dương, giá trị của nó càng lớn khi cặp từ khoá có càng nhiều vị trí gần nhau. Cũng lưu ý rằng: F(A, B) và F(B, A) là khác nhau, nó phù hợp với việc phản ánh thực tế rằng kết quả của sự tương tác ảnh hưởng lên mỗi yếu tố có mức độ nặng nhẹ khác nhau.
Như vậy, giá trị của “A cites B” là tổng khoảng cách của tất cả các cặp Ax, By sao cho By chỉ tính cho Ax duy nhất đứng trước nó trong văn bản. Điều này được minh hoạ ở Hình 2. 1.
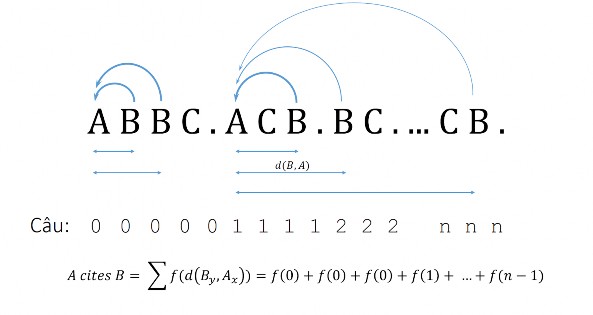
Hình 2. 1. Minh họa cách lượng hóa ảnh hưởng của từ khóa B lên từ khóa A
2.2.1.4. Lược giản mạng tương tác
Kiểm định thống kê mạng tương tác: Mạng tương tác được biểu diễn bởi một ma trận vuông từ sự tương tác của n thực thể. Tuy nhiên có những giá trị tương tác mang tính ngẫu nhiên đến từ tập dữ liệu. Ma trận này được xây dựng từ các tập con của dữ liệu, sử dụng kiểm định giả thuyết thống kê để bác bỏ các tương tác có độ tin cậy thấp.
̅𝑥̅̅1̅−̅𝑥̅̅2̅
Kiểm định thông kê t-test: t = .
𝑆∆
𝑆12 2
Trong đó: S∆ = √ + 𝑆2
𝑛1 𝑛2
̅𝑥̅1̅ : Giá trị trung bình của tập con thứ nhất
̅𝑥̅2̅ : Giá trị trung bình của tập con thứ 2 S1: Độ lệch chuẩn của tập con thứ nhất
S2: Độ lệch chuẩn của tập con thứ 2
n1: Tổng số giá trị trong tập con thứ nhất n2: Tổng số giá trị trong tập con thứ 2
Từ t ta sẽ suy ra được giá trị P-value (sử dụng Python), P-value > 0,01 thì được
coi là kết nối có độ tin cậy thấp.
2.2.2.5. Biểu diễn mạng tương tác
Ma trận tương tác là kết quả sau khi tính toán cho tất cả các cặp tương tác chéo trong của các từ trong tập hợp từ khoá. KG được vẽ dựa trên các tương tác có giá trị của ma trận và được hiệu chỉnh bằng thuật toán PageRank.
PageRank là công thức Toán học đánh giá giá trị của trang (Web Page) thông qua việc xem xét số lượng và chất lượng các trang liên kết đến nó. Trong nghiên cứu này, thay vì đánh giá giá trị của các trang ta sẽ đánh giá giá trị của các thực thể.
Thuật toán PageRank:
PR(T)= (1-d) + d*( + + ⋯ + )
𝑃𝑅(𝑇1) 𝑃𝑅(𝑇2) 𝑃𝑅(𝑇𝑛)
Trong đó:
𝐶(𝑇1)
𝐶(𝑇2)
𝐶(𝑇𝑛)
PR(T) + PR(T1) + PR(T2) +…+ PR(Tn) = 1
PR: Giá trị (Rank) của thực thể C: Số liên kết của 1 thực thể
T, T1, T2, …Tn: Các thực thể d: Xác suất lựa chọn thực thể
Và chúng tôi sử dụng phần mềm Gephi [24] để vẽ mạng tương tác.
2.2.2. Kiểm định mạng
Kiểm định mạng: Mạng tương tác biểu thị mối quan hệ giữa các thực thể bản chất là Unsupervised Learning chỉ đánh giá kết quả định tính, không đánh giá kết quả định lượng. Định tính hiệu quả của mạng là kiểm chứng sự phù hợp của các tri thức Y học (sự liên quan của các thực thể) với kiến thức lâm sàng.
Để đánh giá định tính hiệu quả của mạng tương tác, ta dự đoán mối liên quan giữa các thực thể. Ví dụ ta dự đoán mối liên quan Triệu chứng với Cơ quan. Một triệu chứng bất kỳ có thể có liên quan tới nhiều cơ quan, nhưng dựa vào trọng số (giá trị
tương tác) nó cho phép sắp xếp khả năng liên quan của các cơ quan theo thứ tự giảm dần.
CHƯƠNG 3: KẾT QUẢ VÀ BÀN LUẬN
3.1. Dữ liệu
Sau khi tìm kiếm, chúng tôi thu thập được 97 đầu sách giáo trình của Oxfords (tái bản mới nhất) với tổng cộng 76,277 trang và 32,334,498 từ được đề cấp tại Bảng
3.1. (chi tiết tại Phụ lục 1).
Bảng 3.1. Bảng thông kê tập dữ liệu gốc
Số trang | Số từ | |
Oxford American Handbook of Cardiology | 658 | 164,638 |
Oxford American handbook of clinical pharmacy | 752 | 173,881 |
Oxford American Handbook of Disaster Medicine | 801 | 183,485 |
Oxford American handbook of endocrinology and diabetes | 697 | 167,800 |
… | … | … |
Tổng dữ liệu | 76,277 | 32,334,498 |
Có thể bạn quan tâm!
-

 Bước đầu xây dựng mạng tương tác y học áp dụng trí tuệ nhân tạo lên dữ liệu sách y khoa của Đại học Oxford - 1
Bước đầu xây dựng mạng tương tác y học áp dụng trí tuệ nhân tạo lên dữ liệu sách y khoa của Đại học Oxford - 1 -
 Bước đầu xây dựng mạng tương tác y học áp dụng trí tuệ nhân tạo lên dữ liệu sách y khoa của Đại học Oxford - 2
Bước đầu xây dựng mạng tương tác y học áp dụng trí tuệ nhân tạo lên dữ liệu sách y khoa của Đại học Oxford - 2 -
 Mạng Tương Tác Y Học Dưới Góc Nhìn Toàn Cảnh Của Tập Dữ Liệu Gốc
Mạng Tương Tác Y Học Dưới Góc Nhìn Toàn Cảnh Của Tập Dữ Liệu Gốc -
 Mạng Tương Tác Y Học Dưới Góc Nhìn Toàn Cảnh Của Tập Dữ Liệu Thần Kinh
Mạng Tương Tác Y Học Dưới Góc Nhìn Toàn Cảnh Của Tập Dữ Liệu Thần Kinh -
 Mạng Tương Tác Triệu Chứng Và Cơ Quan Của Tập Dữ Liệu Thần Kinh
Mạng Tương Tác Triệu Chứng Và Cơ Quan Của Tập Dữ Liệu Thần Kinh
Xem toàn bộ 73 trang tài liệu này.
Các sách còn được lựa chọn để xếp vào 3 nhóm nhỏ hơn: nhóm Nội tiết, Thần kinh và Tim mạch để phục vụ cho việc đánh giá sự phụ thuộc của mạng tương tác vào nhóm các ngành hẹp hơn. Chi tiết về 3 nhóm được chỉ ra ở Bảng 3.2.
Bảng 3.2. Bảng thông kê tập dữ liệu nghiên cứu
Số trang | Số từ | |
Tất cả các đầu sách | 76,277 | 32,334,498 |
Tim mạch | 9,161 | 3,693,693 |
Nội tiết | 5,440 | 1,713,569 |
Thần kinh | 13,665 | 8,112,976 |
Trong nghiên cứu này, tôi xây dựng mạng tương tác Y học dựa vào phân tích dữ liệu văn bản Y khoa. Khác với các nghiên cứu trước của Linfeng Li cùng các cộng sự [17] phân tích hồ sơ bệnh án điện tử (EMR), các sách thường được trình bày chi
tiết hơn về mối quan hệ của các yếu tố, nhưng đồng thời cũng có nhiều từ nhiễu hơn, cấu trúc câu phức tạp hơn. Tính trật tự của việc sắp xếp các yếu tố cũng cao hơn so với bệnh án. Ví dụ: kiểu liệt kê triệu chứng ở bệnh án, các triệu chứng về mặt xuất hiện là ngang hàng. Tuy nhiên trong các sách, có thể sự sắp xếp trước sau của từng triệu chứng phản ánh mối tương tác nào đó giữa chúng hoặc giữa chúng với yếu tố khác. Mặc dù, nghiên cứu phân tích hồ sơ bệnh án có thể tìm ra tri thức mới, tuy nhiên chúng cần được kiểm chứng trước khi có thể phục vụ cho mục đích Y học. Do đó, việc phân tích dữ liệu sách kì vọng đưa ra được biểu đồ tương tác chi tiết, phục vụ cho đa mục đích.
3.2. Xây dựng mạng
3.2.1. Tiền xử lý dữ liệu
Dữ liệu từ 76,277 trang ban đầu với 32,334,498 từ, sau khi loại bỏ các trang phụ và các từ không được chọn đã giảm xuống còn 52,571 trang và 7,080,850 từ được đề cập tại Bảng 3.3. (chi tiết tại Phụ lục 1). Chúng được chia ngẫu nhiên tập hợp trang thành 50 tập con. Mỗi tập con có 1051 trang và 141,617 từ.
Bảng 3.3. Bảng thống kê tập dữ liệu gốc sau tiền xử lý
Số trang sau tiền xử lý | Số từ sau tiền xử lý | |
Oxford American Handbook of Cardiology | 355 | 22,326 |
Oxford American handbook of clinical pharmacy | 359 | 22,563 |
Oxford American Handbook of Disaster Medicine | 365 | 27,131 |
Oxford American handbook of endocrinology and diabetes | 510 | 32,103 |
… | … | … |
Tổng dữ liệu | 52,571 | 7,080,850 |
3.2.2. Danh sách từ khóa
Từ khoá được tạo chung từ toàn bộ tập dữ liệu. Sau bước tiền xử lý, các từ còn lại được tính số lần lặp lại trong mỗi tập con. Các từ có tần suất xuất hiện dưới ngưỡng mặc định 20 lần bị loại bỏ (các lần chạy thử đã cho thấy các từ có tần suất dưới ngưỡng đều bị loại bỏ khi áp dụng kiểm định giả thuyết thống kê). Tiến hành hợp nhất các từ được lựa chọn ở tất cả các tập dữ liệu con và lọc thủ công các thuật ngữ