trình này trông gần như giống nhau, nhưng do bản chất của dữ liệu, kiến trúc thường là hoàn toàn khác nhau.
2.2.2.2 Các thành phần của kiến trúc Big Data
Hoàn toàn không thể đưa ra giải pháp tối ưu nhất cho bất kỳ giải pháp big data nào trong 1 bài viết duy nhất, tuy nhiên, chúng ta có thể nói về các khối xây dựng cơ bản trong kiến trúc big data.
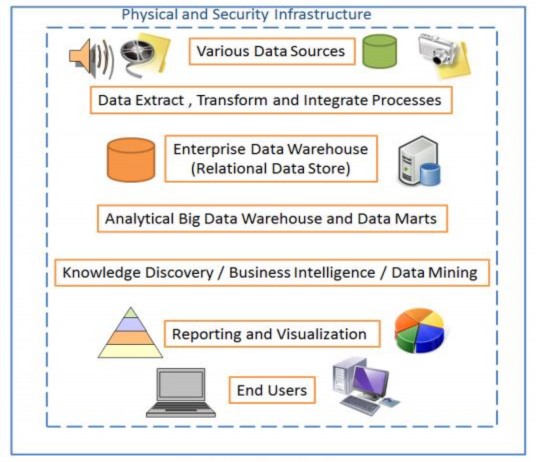
Hình 2.2.2.2 Kiến trúc Big Data [5]
Hình ảnh trên cho chúng ta cái nhìn tổng quan tốt về các thành phần khác nhau trong kiến trúc big data tương tác lẫn nhau. Trong big data, các nguồn dữ liệu khác nhau là 1 phần của kiến trúc do đó trích xuất, chuyển đổi và tích hợp (extract, transform and intergrate) là 1 trong những lớp quan trọng nhất của kiến trúc. Hầu hết các dữ liệu được lưu trữ trong quan hệ cũng như không quan hệ và các giải pháp kho dữ liệu. Theo nhu cầu kinh doanh, các dữ liệu đa dạng khác nhau được xử lý và
chuyển thành báo cáo trực quan với người dùng. Cũng giống như phần mềm, phần cứng cũng là phần quan trọng của kiến trúc big data. Trong kiến trúc big data, hạ tầng phần cứng vô cùng quan trọng và cần phải cài đặt ngăn chặn lỗi xảy ra, đảm bảo tính sẵn sàng cao.
NoSQL trong quản lý dữ liệu
Có thể bạn quan tâm!
-

 Nghiên cứu mô hình kiểm soát truy xuất cho dữ liệu lớn - 1
Nghiên cứu mô hình kiểm soát truy xuất cho dữ liệu lớn - 1 -
 Nghiên cứu mô hình kiểm soát truy xuất cho dữ liệu lớn - 2
Nghiên cứu mô hình kiểm soát truy xuất cho dữ liệu lớn - 2 -
 Namenode Và Quá Trình Tương Tác Giữa Client Và Hdfs
Namenode Và Quá Trình Tương Tác Giữa Client Và Hdfs -
 Cấu Trúc Dữ Liệu Lưu Trong Bộ Nhớ
Cấu Trúc Dữ Liệu Lưu Trong Bộ Nhớ -
 Giới Thiệu Mô Hình Tính Toán Mapreduce
Giới Thiệu Mô Hình Tính Toán Mapreduce
Xem toàn bộ 119 trang tài liệu này.
NoSQL là 1 thuật ngữ rất nổi tiếng và nó thật sự có ý nghĩa là Not Relational SQL hay Not Only SQL. Điều này là do trong kiến trúc big data, dữ liệu ở định dạng bất kỳ. Để mang tất cả dữ liệu cùng nhau thì công nghệ mối quan hệ là không đủ, do các công cụ mới, kiến trúc và các thuật toán khác được phát minh sẽ nhận tất cả các loại dữ liệu. Những điều này được gọi chung là NoSQL.
2.3 Các ứng dụng của dữ liệu lớn
Có 4 lợi ích Big Data có thể mang lại: cắt giảm chi phí; giảm thời gian; tăng thời gian phát triển, tối ưu hóa sản phẩm; hỗ trợ con người đưa ra những quyết định đúng và hợp lý hơn. Thí dụ, khi mua sắm online trên eBay, Amazon hoặc những trang thương mại điện tử, các trang này sẽ đưa ra những sản phẩm gợi ý tiếp theo. Nếu chúng ta xem điện thoại, nó sẽ gợi ý mua thêm ốp lưng, pin dự phòng; hoặc khi mua áo thun sẽ có thêm gợi ý quần jean, dây nịt...
Do đó, nghiên cứu được sở thích, thói quen của khách hàng cũng gián tiếp giúp doanh nghiệp bán được nhiều hàng hóa hơn. Những thông tin về thói quen, sở thích này có được từ lượng dữ liệu khổng lồ các doanh nghiệp thu thập trong lúc khách hàng ghé thăm và tương tác với trang web của mình. Chỉ cần doanh nghiệp biết khai thác một cách có hiệu quả Big Data, nó không chỉ giúp tăng lợi nhuận cho chính họ mà giúp tiết kiệm thời gian cho khách hàng trong mua sắm.
Xu hướng Google rút ra từ những từ khóa tìm kiếm liên quan đến dịch H1N1 đã được chứng minh rất sát với kết quả do 2 hệ thống cảnh báo cúm độc lập Sentinel GP và HealthStat đưa ra. Dữ liệu của Flu Trends được cập nhật gần như theo thời gian thực, sau đó được đối chiếu với số liệu từ những trung tâm dịch bệnh ở nhiều nơi trên thế giới. Theo Oracle, việc phân tích Big Data và những dữ liệu dung lượng
lớn đã giúp các tổ chức kiếm được 10,66USD cho mỗi 1USD chi phí phân tích, tức gấp 10 lần.
Một trường học tại Hoa Kỳ có được sự tăng trưởng doanh thu 8 triệu USD mỗi năm, còn một công ty tài chính ẩn danh khác tăng 1.000% lợi nhuận trên tổng số tiền đầu tư của mình trong vòng 3 năm. Trong World Cup, Big Data cũng đưa ra dự báo đội tuyển Đức sẽ vô địch.
Thị trường Big Data được nhận định có giá trị tới 100 tỷ USD vào năm 2010 và đang không ngừng tăng với tốc độ chóng mặt. Chẳng hạn, hiện thế giới có tới 4,6 tỷ thuê bao điện thoại di động và có từ 1-2 tỷ người dùng internet. Từ năm 1990- 2005, hơn 1 tỷ người trên thế giới tham gia vào tầng lớp trung lưu, tức nhu cầu lưu trữ và sử dụng thông tin của thế giới tăng lên nhiều lần.
Nếu để ý một chút, chúng ta sẽ thấy khi mua sắm online trên eBay, Amazon hoặc những trang tương tự, trang này cũng sẽ đưa ra những sản phẩm gợi ý tiếp theo cho bạn, ví dụ khi xem điện thoại, nó sẽ gợi ý cho bạn mua thêm ốp lưng, pin dự phòng; hoặc khi mua áo thun thì sẽ có thêm gợi ý quần jean, dây nịt... Do đó, nghiên cứu được sở thích, thói quen của khách hàng cũng gián tiếp giúp doanh nghiệp bán được nhiều hàng hóa hơn.
Vậy những thông tin về thói quen, sở thích này có được từ đâu? Chính là từ lượng dữ liệu khổng lồ mà các doanh nghiệp thu thập trong lúc khách hàng ghé thăm và tương tác với trang web của mình. Chỉ cần doanh nghiệp biết khai thác một cách có hiệu quả Big Data thì nó không chỉ giúp tăng lợi nhuận cho chính họ mà còn tăng trải nghiệm mua sắm của người dùng, chúng ta có thể tiết kiệm thời gian hơn nhờ những lời gợi ý so với việc phải tự mình tìm kiếm.
Người dùng cuối sẽ được hưởng lợi từ việc tối ưu hóa như thế, chứ bản thân người dùng khó mà tự mình phát triển hay mua các giải pháp để khai thác Big Data bởi giá thành của chúng quá đắt, có thể đến cả trăm nghìn đô. Ngoài ra, lượng dữ liệu mà chúng ta có được cũng khó có thể xem là “Big” nếu chỉ có vài Terabyte sinh ra trong một thời gian dài.
Ngoài ra, ứng dụng được Big Data có thể giúp các tổ chức, chính phủ dự đoán được tỉ lệ thất nghiệp, xu hướng nghề nghiệp của tương lai để đầu tư cho những hạng mục đó, hoặc cắt giảm chi tiêu, kích thích tăng trưởng kinh tế, v/v... thậm chí là ra phương án phòng ngừa trước một dịch bệnh nào đó, giống như trong phim World War Z, nước Israel đã biết trước có dịch zombie nên đã nhanh chóng xây tường thành ngăn cách với thế giới bên ngoài.
2.4 Các mô hình dữ liệu lớn
2.4.1 Hadoop Apache
2.4.1.1 Hadoop là gì?
Apache Hadoop định nghĩa:
“Apache Hadoop là một framework dùng để chạy những ứng dụng trên 1 cluster lớn được xây dựng trên những phần cứng thông thường1.Hadoop hiện thực mô hình Map/Reduce, đây là mô hình mà ứng dụng sẽ được chia nhỏ ra thành nhiều phân đoạn khác nhau, và các phần này sẽ được chạy song song trên nhiều node khác nhau. Thêm vào đó, Hadoop cung cấp 1 hệ thống file phân tán (HDFS) cho phép lưu trữ dữ liệu lên trên nhiều node. Cả Map/Reduce và HDFS đều được thiết kế sao cho framework sẽ tự động quản lý được các lỗi, các hư hỏng về phần cứng của các node.” [23]
Wikipedia định nghĩa:
“Hadoop là một framework nguồn mở viết bằng Java cho phép phát triển các ứng dụng phân tán có cường độ dữ liệu lớn một cách miễn phí. Nó cho phép các ứng dụng có thể làm việc với hàng ngàn node khác nhau và hàng petabyte dữ liệu. Hadoop lấy được phát triển dựa trên ý tưởng từ các công bố của Google về mô hình MapReduce và hệ thống file phân tán Google File System (GFS).”[22]
Vậy ta có thể kết luận như sau:
1) Hadoop là một framework cho phép phát triển các ứng dụng phân tán.
2) Hadoop viết bằng Java. Tuy nhiên, nhờ cơ chế streaming, Hadoop cho phép phát triển các ứng dụng phân tán bằng cả java lẫn một số ngôn ngữ lập trình khác như C++, Python, Pearl.
1. Phần cứng thông thường: dịch từ thuật ngữ commodity hardware, tức các loại phần cứng thông thường, rẻ tiền. Các phần cứng này thường có khả năng hỏng hóc cao. Thuật ngữ này dùng để phân biệt với các loại phần cứng chuyên dụng đắt tiền, khả năng xảy ra lỗi thấp như các supermicrocomputer chẳng hạn.
3) Hadoop cung cấp một phương tiện lưu trữ dữ liệu phân tán trên nhiều node, hỗ trợ tối ưu hoá lưu lượng mạng, đó là HDFS. HDSF che giấu tất cả các thành phần phân tán, các nhà phát triển ứng dụng phân tán sẽ chỉ nhìn thấy HDFS như một hệ thống file cục bộ bình thường.
4) Hadoop giúp các nhà phát triển ứng dụng phân tán tập trung tối đa vào phần logic của ứng dụng, bỏ qua được một số phần chi tiết kỹ thuật phân tán bên dưới (phần này do Hadoop tự động quản lý).
5) Hadoop là Linux-based. Tức Hadoop chỉ chạy trên môi trường Linux .
2.4.1.2 Lịch sử Hadoop
Hadoop được tạo ra bởi Dough Cutting, người sáng tạo ra Apache Lucene – bộ thư viện tạo chỉ mục tìm kiếm trên text được sử dụng rộng rãi. Hadoop bắt nguồn từ Nutch, một ứng dụng search engine nguồn mở. Nutch được khởi xướng từ năm 2002, và một hệ thống search engine (gồm crawler
và tìm kiếm) nhanh chóng ra đời. Tuy nhiên, các nhà kiến trúc sư của Nutch nhanh chóng nhận ra rằng Nutch sẽ không thể mở rộng ra để có thể thực hiện vai trò searcher engine của mình trên tập dữ liệu hàng tỷ trang web (lúc khả năng của Nutch chỉ có thể crawl tối đa 100 triệu trang). Nguyên nhân chính của giới hạn này là do Nutch lúc này chỉ chạy trên một máy đơn (stand alone) nên gặp phải các khuyết điểm:
![]()
với hơn 100 triệu trang ta cần 1 Tetabyte đĩa cứng, và với khối lượng hàng tỷ trang web đang có trên mạng thì cần có tới hàng chục petabye để lưu trữ.
![]()
dữ liệu lớn như vậy, việc truy xuất tuần tự để phân tích dữ liệu và index trở nên rất chậm chạp, và thời gian để đáp ứng các câu truy vấn tìm kiếm (search query) là không hợp lý. Việc phải truy xuất vào các file có kích thước lớn được tạo ra trong quá trình crawl và index cũng là một thách thức lớn. Năm 2003, Google công bố kiến trúc của hệ thống file phân tán GFS (viết tắt từ Google File System) của họ. Các nhà kiến trúc sư của Nutch thấy rằng GFS sẽ giải quyết được nhu cầu lưu trữ các file rất lớn từ quá trình crawl và index. Năm 2004, họ bắt tay vào việc ứng dụng kiến trúc của GFS vào cài đặt một hệ thống file phân
tán nguồn mở có tên Nutch Distributed File System (NDFS). Năm 2004, Google lại công bố bài báo giới thiệu MapReduce. Vào đầu năm 2005, các nhà phát triển Nutch đã xây dựng được phiên bản MapReduce trên Nutch, và vào giữa năm 2005, tất cả các thuật toán chính của Nutch đều được cải tiến lại để chạy trên nền NDFS và MapReduce. NDFS và MapRecude trong Nutch đã nhanh chóng tìm được các ứng dụng của mình bên ngoài lĩnh vực search engine, và vào tháng hai 2006 Dough Cutting đã tách riêng NDFS và MapReduce ra để hình thành một dự án độc lập có tên Hadoop. Cùng thời gian này, Dough Cutting gia nhập vào Yahoo!. Tại đây ông được tạo một môi trường tuyệt vời để phát triển Hadoop và vào tháng 2 năm 2008 Yahoo đã công bố sản phẩm search engine của họ được xây dựng trên một Hadoop cluster có kích thước 10.000 nhân vi xử lý. [26]
2.4.1.3 Các thành phần của Hadoop
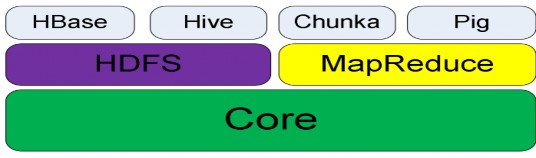
Ngày nay, ngoài NDFS (đã được đổi tên lại thành HDFS-Hadoop Distributed File System) và MapReduce, đội ngũ phát triển Hadoop đã phát triển các dự án con dựa trên HDFS và MapReduce. Hiện nay, Hadoop gồm có các dự án con sau:
![]()
Hình 2.4.1.1 Cấu trúc các thành phần của Hadoop [22] I/O. Đây là phần lõi để xây dựng nên HDFS và MapReduce.
![]()
rk giúp phát triển các ứng dụng phân tán theo mô hình MapReduce một cách dễ dàng và mạnh mẽ, ứng dụng phân tán MapReduce có thể chạy trên một cluster lớn với nhiều node.
![]()
năng tối ưu hoá việc sử dụng băng thông giữa các node. HDFS có thể được sử dụng để chạy trên một cluster lớn với hàng chục ngàn node.
![]()
-oriented). HBase sử dụng HDFS làm hạ tầng cho việc lưu trữ dữ liệu bên dưới, và cung cấp khả năng tính toán song song dựa trên MapReduce.
![]()
trên HDFS và cung cấp một ngôn ngữ truy vấn dựa trên SQL.
![]()
và phân tích dữ liệu. Chukwa chạy các collector (các chương trình tập hợp dữ liệu), các collector này lưu trữ dữ liệu trên HDFS và sử dụng MapReduce để phát sinh các báo cáo.
![]()
song song. Trong khuôn khổ của luận văn này, chúng tôi chỉ nghiên cứu hai phần quan trọng nhất của Hadoop, đó là HDFS và MapReduce.
2.4.1.4 Ứng dụng của Hadoop trong một số công ty:
Ngày nay, ngoài Yahoo!, có nhiều công ty sử dụng Hadoop như là một công cụ để lưu trữ và phân tích dữ liệu trên các khối dữ liệu lớn như:
![]()
hiển thị trên profile của tác giả), logs và các nguồn dữ liệu phát sinh trong quá trình hoạt động của Twitter.
![]()
liệu. Các dữ liệu này được dùng làm nguồn cho các báo cáo phân tích và máy học. Hiện tại, facebook có 2 Hadoop cluster chính: một cluster 1100 máy với 8800 nhân và 12 Petabyte ổ cứng lưu trữ.
![]()
-Amazon: Sử dụng Hadoop để đánh giá chỉ số tìm kiếm sản phẩm trên Amazon, xử lý đến hàng triệu Session mỗi ngày. Các cluster của A9.com có độ lớn từ 1-100 node.
Và còn rất nhiều công ty hiện đang sử dụng Hadoop vào việc lưu trữ và xử lý dữ liệu, đặc biệt cho các nguồn dữ liệu lớn với kích thước lên tới hàng petabyte.
2.4.1.5 Tổng quan của một Hadoop cluster:
Như đã giới thiệu ở các phần trên, HDFS và MapReduce là hai thành phần chính của một Hadoop cluster. Nhìn chung, kiến trúc của Hadoop là kiến trúc master-
slave, và cả hai thành phần HDFS và MapReduce đều tuân theo kiến trúc master- slave này. Kiến trúc một Hadoop cluster như sau:
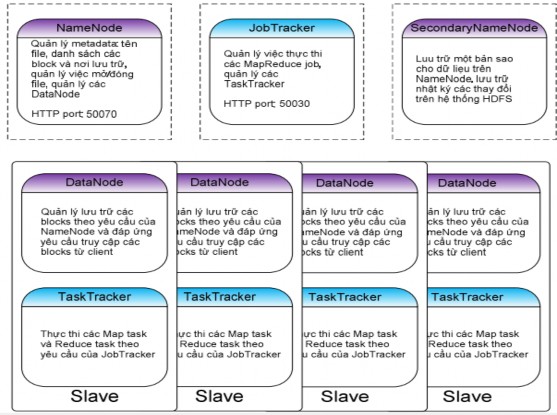

Hình 2.4.1.2 Tổng quan một Hadoop cluster
Trên một hadoop cluster, có duy nhất một node chạy NameNode, một node chạy JobTracker (NameNode và JobTracker có thể nằm trên cùng một máy vật lý, tuy nhiên trên các cluster thật sự với hàng trăm, hàng nghìn node thì thường phải tách riêng NameNode và JobTracker ra các máy vật lý khác nhau). Có nhiều node slave, mỗi node slave thường đóng 2 vai trò: một là DataNode, hai là TaskTracker. NameNode và DataNode chịu trách nhiệm vận hành hệ thống file phân tán HDFS với vai trò cụ thể được phân chia như sau:
![]()
-data của hệ thống HDFS như file system space, danh sách các file trên hệ thống và các block id tương ứng của từng file, quản danh sách slave và tình trạng hoạt động