They can assign each workstation to a set of projects, and can control the assignment of resources between projects.
A BOINC-based project provides its own servers. Workstations download application executables and data files from the server, perform tasks (by running the applications against specified data files), and upload output files to the server. The BOINC software includes server-side components, such as schedulers and processes to manage the allocation and aggregation of tasks [12], and a web-based interface for volunteers and project administrators.
Maybe you are interested!
-

 Comparison of Geographical Conditions, Structure of Culture and Tourism Activities
Comparison of Geographical Conditions, Structure of Culture and Tourism Activities -
 Comparison of Distribution by Number of Cesarean Sections Between Studies
Comparison of Distribution by Number of Cesarean Sections Between Studies -
 Comparison of Activity-Based Costing and Traditional Costing
Comparison of Activity-Based Costing and Traditional Costing -
 Comparison of the effects of two methods of complete intravenous anesthesia with Propofol with and without target concentration control - 2
Comparison of the effects of two methods of complete intravenous anesthesia with Propofol with and without target concentration control - 2 -
 Comparison of Imported Raw Materials Value and Export Turnover of Vietnam's Leather and Footwear
Comparison of Imported Raw Materials Value and Export Turnover of Vietnam's Leather and Footwear
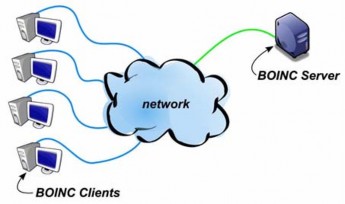
Figure 1-5. Basic model of BOINC
1.3.2.2 Basic features of BOINC [23]
Project independence: There are many different projects that use BOINC, but the projects are completely independent of each other. Each project has its own server and database, there is no central directory for all projects. What they have in common is that they all use BOINC as their software platform.
Flexibility in use: Volunteers can participate in many projects; they control those projects, manage and allocate resources to the projects. When a project ends or is not working, the resources for it will be reclaimed and allocated to other projects.
Flexible development: Applications written in C, C++ or Fortran can run BOINC applications with little or no modification. An application can consist of multiple files (multi-program). New versions of the application can be automatically deployed and updated.
Security: BOINC protects against possible attacks. For example, digital signatures based on public key encryption protect against the distribution of viruses…
Performance and portability: BOINC server software is extremely efficient. Therefore, a central server can dispatch and control millions of jobs in a day. The server architecture is also highly scalable, making it easy to increase server capacity or be ready to add more machines.
Open Source: BOINC itself is provided as open source, both the BOINC server and the BOINC client. However, BOINC applications are not necessarily open source.
Big data computing: BOINC supports applications that generate or use large amounts of data, or require large amounts of memory. Data distribution and aggregation can be split across multiple servers. Participants exchange large amounts of data discreetly. Users can specify memory or bandwidth limits. Jobs are sent only to machines that can complete them.
Multi-platform : BOINC client versions are available for most popular platforms (Mac OS X, Windows, Linux and other Unix systems such as Ubuntu, Fedora, Redhat…). Workstations can use multiple CPUs.
Extensible software architecture: The key components of BOINC are well documented and publicly available; this allows third-party developers to easily create software and websites that extend BOINC.
Volunteer community: BOINC provides web-based tools such as message boards, volunteer profiles, and private messaging;
This makes it easy for volunteers to form online communities to exchange and help each other.
1.3.2.3BOINC Architecture
BOINC consists of server and client components (see Figure 1.5). The BOINC client runs project applications. Applications are linked to the runtime system, the functions of which include process control, checkpointing, and graphs [13]. The client performs CPU scheduling (implemented on top of the local operating system scheduler, at the operating system level, BOINC runs applications at priority 0). It can preempt applications either by delaying them (and leaving them in memory) or by instructing them to exit. The BOINC server performs the provisioning of applications and work units, handles the computation results, and manages the distribution and aggregation of data.
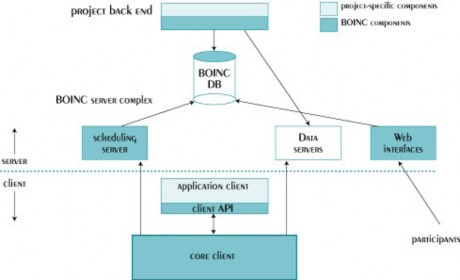
Figure 1-6. BOINC architecture
All network connections in BOINC are initiated by clients. A client communicates with a project task assignment server [12] via HTTP. The request is an XML data file that includes a description of the hardware and performance, a list of completed tasks, and a request for a fixed amount (expressing a CPU time limit) of additional work. Response messages
consists of a list of new jobs (each job is described by an XML element that lists the application, input and output files, including the location of the servers from which data from each file can be downloaded). Sometimes clients have physical connections that are down. As a result, a computer may connect a few times a day. During the network connection period, BOINC attempts to load enough jobs to keep the computer busy until the next connection. The figure below shows the sequence of execution between the client and the server.

Figure 1-7. Interaction between workstation and server
1.3.3 Scheduling in volunteer computing
According to the concept of volunteer computing system above, a volunteer computing system includes many workstations connected to the server, in which the workstations connect to the server to get the job and execute it and return the results to the server, and the server executes the selection of workstations to assign tasks. Therefore, the process of processing and executing these jobs includes four related policies [14], [15]:
CPU Scheduling: Of the jobs that can run now, which jobs can run.
Job Picking: When to propose a project for multiple jobs, which projects
offered and how many jobs offered.
Submit job: When a project receives a job request, it sends which job.it sends which job.
Estimated completion time: Estimates how long the CPU will maintain the job.
Scheduling in volunteer computing systems plays a very important role in improving the overall execution time of the system. For workstations it helps in CPU scheduling and fetching jobs. For servers scheduling helps in maximizing the number of jobs executed and reducing the execution time of the system.
1.3.3.1 Client-side scheduling
Workstation scheduling is the CPU scheduling and job-picking policies, which must consider the following inputs: First, the workstation's hardware characteristics, such as the number of processors. The workstation keeps track of various application characteristics, such as its execution fraction (the fraction of time it is running and is allowed to do computation), and statistics about its network connections. Second, the user's priorities. These include: Shared resources for each project, processor usage limits (conditions for computation while the machine is in use, the maximum number of CPUs used, and the largest fraction of CPU time used), connection intervals (the minimum time between network activity periods, which is used to provide a hint of how often the workstations are connected to the network), etc. Finally each job has a number of project-specific parameters, including an estimate of the number of project-specific cursor operators and the final time for the workstation to report the job.
1.3.3.2Server-side scheduling
Server-side scheduling is about making optimal use of volunteer resources. The problem of server-side scheduling is about sending jobs and estimating the completion time of the jobs. There are many studies on server-side scheduling to optimize volunteer resources. The commonly used scheduling policy in BOINC is first come first serve, in which the first available jobs are assigned to workstations that require the first job to meet the uniform redundancy criteria for the distribution of multiple HR jobs (HR distributes similar jobs to workstations with similar computing capabilities, meaning they have the same operating system and processors from the same manufacturer). In [19], the authors proposed a threshold-based scheduling policy, which
This policy sets two thresholds one for workstation capability and one for workstation reliability and uses these thresholds to verify the jobs assigned to workstations. It will not assign jobs to workstations whose reliability and capability ratios are lower than the defined threshold values. These thresholds are in the range of 0 to 1. When a workstation requests a new job, the server calculates the workstation capability and reliability ratio based on the workstation's job performance history. If both ratios are greater than the defined thresholds, the workstation is assigned the job otherwise the workstation is not assigned the job. The workstation's performance is calculated based on the total number of jobs assigned to the workstation and the number of jobs the workstation has completed so far (it is equal to the ratio of completed jobs to total assigned jobs), while the workstation's reliability is the ratio of completed jobs that give correct results to the number of jobs completed by the workstation.
1.3.3.3Reliability-based fault-tolerant scheduling
Basically, a volunteer computing system allows public access, so a growing problem is how to protect the system from the sabotage of many malicious users submitting fake results. In [17], the authors proposed a precision-based scheduling technique, which uses redundancy in the execution of jobs to assign to a group of workstations, the clustering of workstations is performed in three steps: (1) Estimating the reliability ratios of the individual workstation nodes, (2) Using the estimated reliability ratios of the workstations to calculate the exact feasibleness (LOC) of the possible groups. (3) Grouping the workstations for the LOC-based task assignment to estimate the maximum number of inputs and the success rate of completing the task. In [8], the author discussed various fault tolerance techniques to protect systems against malicious volunteers such as voting, checkpointing, backtracking and blacklisting. In particular, the author introduced the definition of reliability and proposed a new reliability-based fault tolerance technique. In this new technique, the reliability of a result is estimated as the probability
conditions for the results to be accurate. The execution of a task will be repeated on the computers many times until the final result achieves a sufficiently high reliability. It is demonstrated that the proposed reliability-based fault tolerance technique can perform faster than other traditional techniques such as voting and checkpointing under the same error rate requirements.
In [10], the author extended Sarmenta's work to more common cases by dealing with parallel computing systems containing more volunteer machines than tasks. Since in this case, a task is re-executed in multiple volunteer machines to make good use of the redundant resources. It was found that existing reliability-based fault tolerance techniques are not effective for this type of parallel applications because they do not take into account the case where the same task is re-executed on multiple volunteer machines at the same time. As a result, the existing reliability-based algorithms achieve low computational performance within the execution time limit. The author proposed a priority-based scheduling algorithm according to the performance of the volunteer machines for this case. It was shown that applying this algorithm increased the performance of the reliability-based fault tolerance technique in the case where there are more volunteer machines than tasks.
However, it should be noted that the fault tolerance technique proposed by Sarmenta and the author's priority-based scheduling technique do not take into account the reliability of the workstations and the tasks being executed, so the reliability-based algorithm does not achieve the best performance within the execution time limit. In this thesis, I focus on combining the computing power and reliability of the workstations with the reliability of the tasks being executed to improve the overall performance within the execution time limit while still ensuring the reliability requirement and propose an efficient scheduling algorithm called “Round Robin Scheduling Based on Reliability and Execution Priority”. The effectiveness of the algorithm will be verified by simulations in section 5.
Currently to evaluate the reliability of volunteer scheduling algorithms one can use
using simulators such as SIMBA, SIMBOINC but due to the process of contacting the authors to request the source code of the simulators, there were difficulties and I only received the source code of the SIMBA simulator from author Derrick Kondo after using the VCSIM simulator and completing the simulation. Due to the lack of time for me to further test the simulation results on the SIMBA simulator, in my thesis I used the VCSIM simulator to simulate the proposed algorithms.
1.3.4 Comparison with grid computing and peer-to-peer computing
1.3.4.1 Grid calculation
Grid computing and Volunteer computing are similar in that they both use multiple computers connected together to perform a common task. However, grid computing does not have a central server but is divided into small clusters, each of which can be further divided into smaller units, the smallest of which is a regular PC, whose task is to compute and return results. Think of grid computing with reference to the sharing of computing resources within and between organizations.
- Each organization can act as either a producer or a customer of the resource (as in the electric grid, power companies can buy or sell energy from other companies, depending on the changing requirements).
- Organizations are responsible for each other, if one organization behaves improperly, other organizations can refuse to cooperate, share resources with them and vice versa.
Thus, grid computing is accountable and not secretive. Participants are responsible for results, conflicts, errors, etc. (a fundamental difference from volunteer computing).
1.3.4.2 Peer-to-peer computing
The most fundamental difference is that peer-to-peer computing has no servers. It is simply PCs connected to each other, with no central master. Files and other data are exchanged between “peers” (i.e. PCs) without involving a central server. This differs from volunteer computing: