∑ 𝑛−1 ∑ 𝑚−1 𝑀(𝑥 𝑖 , 𝑦 𝑗 )
𝑆(𝑋, 𝑌) =
𝑖=0 𝑗=0
𝑛 + 𝑚 − ∑ 𝑛−1 ∑ 𝑚−1 𝑀(𝑥 𝑖 , 𝑦 𝑗 )
In there:
𝑖=0 𝑗=0
- S(X, Y) : Similarity between 2 character strings X and Y.
- x, y : The set of words in string X and Y respectively (non-duplicated words).
- n, m : The number of non-duplicated words in the character strings X and Y, respectively.
- 𝑴(𝒙 𝒊 , 𝒚 𝒋 ) : Semantic similarity index of 2 words 𝑥 𝑖 and 𝑦 𝑗 based on word2vec dictionary.
For example: Given the following 2 sentences:
- X: How to express your feelings to your girlfriend .
- Y: How to confess your love to your girlfriend .
After word segmentation, we will have two corresponding word sets as follows:
- x = {way, to, express, feelings, to, girlfriend}
- y = {way, to, confess, love, to, girlfriend}
- n = 6, m = 6
It is easy to see that two sets x and y have a common set of words ( intersection ):
{how, to, with, girlfriend} (4 elements)
And the two sets x and y combine together ( the composition ) to form the set of words:
{way, to, express, confess, feelings, love, to, girlfriend} (8 elements)
If we apply the Jaccard Similarity formula, the similarity between the two sentences will be:
𝐽(𝑋, 𝑌) = 4
8
= 0.5 (1)
Based on the word2vec dictionary, we will have a semantic similarity index matrix of words in two strings X and Y as follows:
M(x, y)
way | to | confess | love | with | girlfriend | |
way | 1 | 0 | 0 | 0 | 0 | 0 |
to | 0 | 1 | 0 | 0 | 0 | 0 |
express | 0 | 0 | 0.619774 | 0 | 0 | 0 |
emotional | 0 | 0 | 0 | 0.705005 | 0 | 0 |
with | 0 | 0 | 0 | 0 | 1 | 0 |
girlfriend | 0 | 0 | 0 | 0 | 0 | 1 |
Maybe you are interested!
-

 Smart knowledge search system on wikihow domain - 9
Smart knowledge search system on wikihow domain - 9 -
 Integrating word morphology information into English-Vietnamese statistical machine translation system - 1
Integrating word morphology information into English-Vietnamese statistical machine translation system - 1 -
 The Nature and Role of the Internal Control System
The Nature and Role of the Internal Control System -
 Some Solutions to Improve the Legal System of Alimony
Some Solutions to Improve the Legal System of Alimony -
 Model system to assess the suitability of Vietnam's population-economic development process - 21
Model system to assess the suitability of Vietnam's population-economic development process - 21
Table 4: Similarity index matrix between words according to Word2vec
Then the similarity between two strings X and Y calculated by the proposed method will be:
𝑆(𝑋, 𝑌) = 1+1+0.619774+0.705005+1+1 6+6−(1+1+0.619774+0.705005+1+1)
= 5.324779
6.675221
≈ 0.7977 (2)
Looking at the two similarity results (1) and (2), it shows that the proposed method will produce higher similarity results if the two input strings contain synonyms.
Data set
The data used in this thesis was collected from the wikiHow website (https://www.wikihow.com/) . This is an online community website with a wiki nature. Founded in 2005 by Jack Herrick, as of 2017 wikiHow contains more than 190,000 free tutorial articles and more than 1.6 million registered users [14].
The data used in this thesis only includes Vietnamese articles. This data is spread across many areas of life such as:
- Entertainment Arts
- Cars and Other Vehicles
- Computers and Electronics
- Education and Communication
- Family Life
- Finance and Business
- Food and Entertainment
- Health
- Hobbies and Crafts
- Holidays and Traditions
- Housing and Gardening
- Personal Care and Style
- Pets and Animals
- Philosophy and Religion
- Relationship
- Sports and Aesthetics
- Tourism
- Working World
- Young people.
In each area, there are a collection of articles on how to do/recipes to solve problems in our daily lives that we often encounter, for example: How to make KFC fried chicken, How to roast cashews, How to cook rice in the microwave, How to identify ringworm, Treatments for nail fungus... Each article includes one or more methods of implementation and specific steps for each method through text and illustrations. The articles
This article was contributed and edited by many editors, researchers and experts.
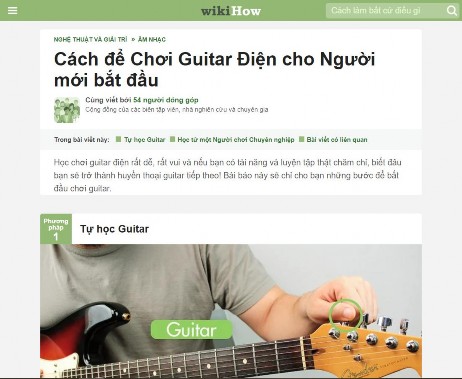
Figure 14: Data illustration from WikiHow
The total number of articles collected is about 10,000, each article has about one to four different methods.
Building the system
3.3.1. Collect data from wikiHow and index the data into Elasticsearch
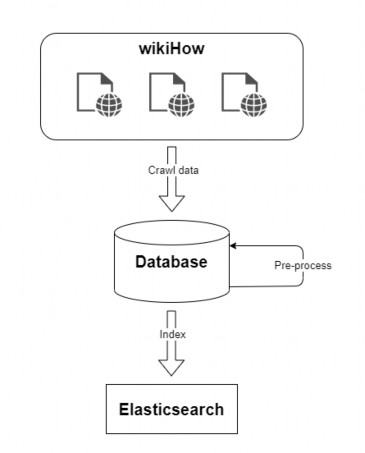
Figure 15: Collecting data and indexing data into Elasticsearch
3.3.1.1. Collect data from wikiHow website
To collect data from the wikiHow website, I built a tool (hereinafter I call it web-crawler) that has the function of collecting all the links of the articles on the website https://wikihow.vn . With those links, this tool will download the article's data and extract the article's information to store in the database.
To extract information from the website, the web-crawler used the Jsoup library. This is a Java library that works with html data. Jsoup provides many APIs for pulling and extracting data from websites in a flexible, convenient way and is well used with the HTML5 DOM method and CSS selectors. [15]
To get the most complete list of links, the web-crawler creates a queue to store the links it discovers in wikiHow. The elements in the queue contain information about the website’s url and the type of the url. The types of urls are divided into the following categories:
- Category: this is the link of the categories, as mentioned in the introduction of wikiHow, it will include 19 major categories about areas of life such as: Arts and Entertainment, Cars and Other Vehicles, Computers and Electronics, Education and Media, Family Life...
- Page: in each category there will usually be a lot of articles, so wikiHow will arrange these articles into pages and each page will usually include a maximum of 80 article titles in that category, and have 1 or more pages, depending on the number of articles in the category.
- Article: this is the direct link to the article. And it will be where we can get full information about the content of the article.
Initializing the above queue, the tool will put in all 19 links of 19 main categories in wikiHow and are of type category. We collect direct links to articles by taking the elements in the above queue one by one, if the element is taken out of the queue:
- Category type: we will use Jsop to extract website content information according to the saved url.
o If we find that the item only includes one page, we will create a clone of that element and convert it to page type and keep the same url. Then push this new element into the queue.
o If the category has many pages, we will iterate with an increasing variable and then change the parameter on the url to see how many pages the category has. The loop will stop when the increasing variable will create a url where the website does not exist. For example: when we have the category "Computers and electronics" with the category link:
https://www.wikihow.vn/Category:Computers-and-Electronics
We will browse the urls in turn: https://www.wikihow.vn/Category:Computers-and-Electronics?pg=1 https://www.wikihow.vn/Category:Computers-and-Electronics?pg=2 https://www.wikihow.vn/Category:Computers-and-Electronics?pg=3
…
When the pg parameter in the url will create a link with no content. Then it will be the limit of the number of pages in the current category. And similarly, we will create new elements with the type of page and the url is the url above. Then push this new element into the queue.
- Has a page type: when downloading the source code of the website corresponding to the url of this element, we will get a list of urls of articles in the following format: https://www.wikihow.vn/Save-files-to-USB
https://www.wikihow.vn/Change-default-language-in-Google-Chrome https://www.wikihow.vn/Change-country-on-YouTube
For each url above, we will create an element with the article type and corresponding url and put it in the queue.
- There is an article type: we will keep it as is (we can clone a corresponding element to push into the queue).
The above loop will execute until all the elements in the queue are of type article.
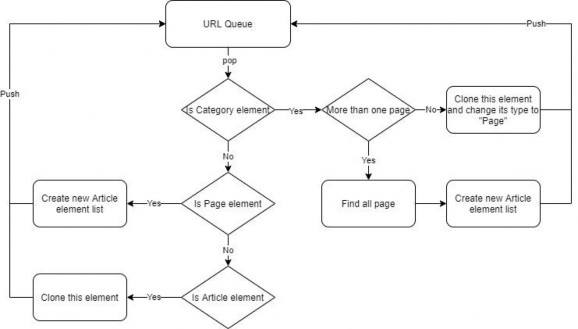
Figure 16: Flow diagram of the data collection mechanism on wikiHow
Once we have all the urls of all the articles on wikiHow, the web-crawler will pull the content of the website and extract the information. The information we can collect from an article will usually be:
- The title of the article, located at the top of the web page. This will be followed by a summary or description of the article (marked number 1 in image 18).
- Methods to perform (marked part number 2 in photo 18).
- For each method, there will be a specific step-by-step description and possibly an image (marked number 3 in photo 18).