Hypothesis H 0is a statement that the researcher does not wish to support. The hypothesis H 0
is set up to serve as a computational basis for the testing problem.
Opposite H 1is the denial of the hypothesis H 0 ; that is, if the null hypothesis is false, then the alternative must be true. And the researcher must collect data to try to achieve that.
Decision to reject or accept the hypothesis H 0 is based on information contained in a sample
drawn from the population. The sample values are used to calculate a single number, called a test statistic . The entire set of values for which this test statistic can have is divided into two regions. One region, consisting of values that support the alternative hypothesis H 1 , is called the rejection region .
The other region, consisting of values that do not contradict the null hypothesis, is called the acceptance region .
The acceptance and rejection regions are separated by a critical value of that test statistic. If this test statistic calculated from a particular sample has a value in the rejection region, then the null hypothesis is rejected, and the alternative hypothesis H 1is accepted. If the statistic falls in the acceptance region, then either the null hypothesis is accepted or the statistic is judged to be inconclusive. In either case, failure to reject H 1 implies that the data are insufficient to support H 1..
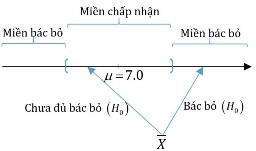
Example 6.2 Survey on the average score of students after graduation, of a faculty, of a university. We want to know if the average score of students is different from 7.0. Then the hypothesis and the opposite are as follows:
Hypothesis H 0 : 7.0 Equivalent H 1 : 7.0
The testing was done by surveying 100 students about their average score. And calculating
The average score of a student, the value is X. Because we are comparing the sample mean and the overall mean 7.0 , so the comparison must be within an allowable error. With that error
we open a range of values around 7.0 . If X is not in that region, we reject the hypothesis H 0 , that is, the opposite H 1true, otherwise we do not have enough evidence to reject H 0 . The diagram is as follows:
6.1.2 Type I error and type II error.
The decisions for the model will consist of true and false outcomes given by the following table:
The hypothetical reality is not
Decision
Correct | Wrong | |
Reject H 0 | Type I error: | Right decision |
Accept H 0 | Right decision | Type II error |
Maybe you are interested!
-
![Mobile Phone Usage in Hanoi Inner City Area
zt2i3t4l5ee
zt2a3gsconsumer,consumption,consumer behavior,marketing,mobile marketing
zt2a3ge
zc2o3n4t5e6n7ts
- Test the relationship between demographic variables and consumer behavior for Mobile Marketing activities
The analysis method used is the Chi-square test (χ2), with statistical hypotheses H0 and H1 and significance level α = 0.05. In case the P index (p-value) or Sig. index in SPSS has a value less than or equal to the significance level α, the hypothesis H0 is rejected and vice versa. With this testing procedure, the study can evaluate the difference in behavioral trends between demographic groups.
CHAPTER 4
RESEARCH RESULTS
During two months, 1,100 survey questionnaires were distributed to mobile phone users in the inner city of Hanoi using various methods such as direct interviews, sending via email or using questionnaires designed on the Internet. At the end of the survey, after checking and eliminating erroneous questionnaires, the study collected 858 complete questionnaires, equivalent to a rate of about 78%. In addition, the research subjects of the thesis are only people who are using mobile phones, so people who do not use mobile phones are not within the scope of the thesis, therefore, the questionnaires with the option of not using mobile phones were excluded from the scope of analysis. The number of suitable survey questionnaires included in the statistical analysis was 835.
4.1 Demographic characteristics of the sample
The structure of the survey sample is divided and statistically analyzed according to criteria such as gender, age, occupation, education level and personal income. (Detailed statistical table in Appendix 6)
- Gender structure: Of the 835 completed questionnaires, 49.8% of respondents were male, equivalent to 416 people, and 50.2% were female, equivalent to 419 people. The survey results of the study are completely consistent with the gender ratio in the population structure of Vietnam in general and Hanoi in particular (Male/Female: 49/51).
- Age structure: 36.6% of respondents are <23 years old, equivalent to 306 people. People from 23-34 years old
accounting for the highest proportion: 44.8% equivalent to 374 people, people aged 35-45 and >45 are 70 and 85 people equivalent to 8.4% and 10.2% respectively. Looking at the results of this survey, we can see that the young people - youth account for a large proportion of the total number of people participating in the survey. Meanwhile, the middle-aged people including two age groups of 35 - 45 and >45 have a low rate of participation in the survey. This is completely consistent with the reality when Mobile Marketing is identified as a Marketing service aimed at young people (people under 35 years old).
- Structure by educational level: among 835 valid responses, 541 respondents had university degrees, accounting for the highest proportion of ~ 75%, 102 had secondary school degrees, ~ 13.1%, and 93 had post-graduate degrees, ~ 11.9%.
- Occupational structure: office workers and civil servants are the group with the highest rate of participation with 39.4%, followed by students with 36.6%. Self-employed people account for 12%, retired housewives are 7.8% and other occupational groups account for 4.2%. The survey results show that the student group has the same rate as the group aged <23 at 36.6%. This shows the accuracy of the survey data. In addition, the survey results distributed by occupational criteria have a rate almost similar to the sample division rate in chapter 3. Therefore, it can be concluded that the survey data is suitable for use in analysis activities.
- Income structure: the group with income from 3 to 5 million has the highest rate with 39% of the total number of respondents. This is consistent with the income structure of Hanoi people and corresponds to the average income of the group of civil servants and office workers. Those
People with no income account for 23%, income under 3 million VND accounts for 13% and income over 5 million VND accounts for 25%.
4.2 Mobile phone usage in Hanoi inner city area
According to the survey results, most respondents said they had used the phone for more than 1 year, specifically: 68.4% used mobile phones from 4 to 10 years, 23.2% used from 1 to 3 years, 7.8% used for more than 10 years. Those who used mobile phones for less than 1 year accounted for only a very small proportion of ~ 0.6%. (Table 4.1)
Table 4.1: Time spent using mobile phones
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Alid
<1 year
5
.6
.6
.6
1-3 years
194
23.2
23.2
23.8
4-10 years
571
68.4
68.4
92.2
>10 years
65
7.8
7.8
100.0
Total
835
100.0
100.0
The survey indexes on the time of using mobile phones of consumers in the inner city of Hanoi are very impressive for a developing country like Vietnam and also prove that Vietnamese consumers have a lot of experience using this high-tech device. Moreover, with the majority of consumers surveyed having a relatively long time of use (4-10 years), it partly proves that mobile phones have become an important and essential item in peoples daily lives.
When asked about the mobile phone network they are using, 31% of respondents said they are using the network of Vietel company, 29% use the network of
of Mobifone company, 27% use Vinaphone companys network and 13% use networks of other providers such as E-VN telecom, S-fone, Beeline, Vietnammobile. (Figure 4.1).
Figure 4.1: Mobile phone network in use
Compared with the announced market share of mobile telecommunications service providers in Vietnam (Vietel: 36%, Mobifone: 29%, Vinaphone: 28%, the remaining networks: 7%), we see that the survey results do not have many differences. However, the statistics show that there is a difference in the market share of other networks because the Hanoi market is one of the two main markets of small networks, so their market share in this area will certainly be higher than that of the whole country.
According to a report by NielsenMobile (2009) [8], the number of prepaid mobile phone subscribers in Hanoi accounts for 95% of the total number of subscribers, however, the results of this survey show that the percentage of prepaid subscribers has decreased by more than 20%, only at 70.8%. On the contrary, the number of postpaid subscribers tends to increase from 5% in 2009 to 19.2%. Those who are simultaneously using both types of subscriptions account for 10%. (Table 4.2).
Table 4.2: Types of mobile phone subscribers
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Prepay
591
70.8
70.8
70.8
Pay later
160
19.2
19.2
89.9
Both of the above
84
10.1
10.1
100.0
Total
835
100.0
100.0
The above figures show the change in the psychology and consumption habits of Vietnamese consumers towards mobile telecommunications services, when the use of prepaid subscriptions and junk SIMs is replaced by the use of two types of subscriptions for different purposes and needs or switching to postpaid subscriptions to enjoy better customer care services.
In addition, the majority of respondents have an average spending level for mobile phone services from 100 to 300 thousand VND (406 ~ 48.6% of total respondents). The high spending level (> 500 thousand VND) is the spending level with the lowest number of people with only 8.4%, on the contrary, the low spending level (under 100 thousand VND) accounts for the second highest proportion among the groups of respondents with 25.4%. People with low spending levels mainly fall into the group of students and retirees/housewives - those who have little need to use or mainly use promotional SIM cards. (Table 4.3).
Table 4.3: Spending on mobile phone charges
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<100,000
212
25.4
25.4
25.4
100-300,000
406
48.6
48.6
74.0
300,000-500,000
147
17.6
17.6
91.6
>500,000
70
8.4
8.4
100.0
Total
835
100.0
100.0
The statistics in Table 4.3 are similar to the percentages in the NielsenMobile survey results (2009) with 73% of mobile phone users having medium spending levels and only 13% having high spending levels.
The survey results also showed that up to 31% ~ nearly one-third of respondents said they sent more than 10 SMS messages/day, meaning that on average they sent 1 SMS message for every working hour. Those with an average SMS message volume (from 3 to 10 messages/day) accounted for 51.1% and those with a low SMS message volume (less than 3 messages/day) accounted for 17%. (Table 4.4)
Table 4.4: Number of SMS messages sent per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
142
17.0
17.0
17.0
3-10 news
427
51.1
51.1
68.1
>10 news
266
31.9
31.9
100.0
Total
835
100.0
100.0
Similar to sending messages, those with an average message receiving rate (from 3-10 messages/day) accounted for the highest percentage of ~ 55%, followed by those with a high number of messages (over 10 messages/day) ~ 24% and those with a low number of messages received daily (under 3 messages/day) remained at the bottom with 21%. (Table 4.5)
Table 4.5: Number of SMS messages received per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
175
21.0
21.0
21.0
3-10 news
436
55.0
55.0
76.0
>10 news
197
24.0
24.0
100.0
Total
835
100.0
100.0
When comparing the data of the two result tables 4.4 and 4.5, we can see the reasonableness between the ratio of the number of messages sent and the number of messages received daily by the interview participants.
4.3 Current status of SMS advertising and Mobile Marketing
According to the interview results, in the 3 months from the time of the survey and before, 94% of respondents, equivalent to 785 people, said they received advertising messages, while only a very small percentage of 6% (only 50 people) did not receive advertising messages (Table 4.6).
Table 4.6: Percentage of people receiving advertising messages in the last 3 months
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Have
785
94.0
94.0
94.0
Are not
50
6.0
6.0
100.0
Total
835
100.0
100.0
The results of Table 4.6 show that consumers in the inner city of Hanoi are very familiar with advertising messages. This result is also the basis for assessing the knowledge, experience and understanding of the respondents in the interview. This is also one of the important factors determining the accuracy of the survey results.
In addition, most respondents said they had received promotional messages, but only 24% of them had ever taken the action of registering to receive promotional messages, while 76% of the remaining respondents did not register to receive promotional messages but still received promotional messages every day. This is the first sign indicating the weaknesses and shortcomings of lax management of this activity in Vietnam. (Table 4.7)
div.maincontent .s1 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s2 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s4 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s5 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s15 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s16 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 5.5pt; vertical-align: 3pt; } div.maincontent .s17 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 8.5pt; } div.maincontent .s18 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s20 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s21 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s22 { color: black; font-family:Courier New, monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s23 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s24 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s25 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s26 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s27 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 1.5pt; } div.maincontent .s28 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s29 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s30 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s31 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s32 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s33 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s36 { color: #F00; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s37 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s38 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 8.5pt; vertical-align: 5pt; } div.maincontent .s39 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s40 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 4pt; } div.maincontent .s41 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s42 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s43 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7.5pt; vertical-align: 5pt; } div.maincontent .s44 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s45 { color: #F00; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s46 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s47 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s48 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s49 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s50 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s51 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s52 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s53 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s54 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s55 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s56 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s57 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s58 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s59 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s60 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 13pt; } div.maincontent .s61 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s62 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s63 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .content_head2 { color: #F00; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s64 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s67 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s68 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s69 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s70 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; tex](https://tailieuthamkhao.com/uploads/2022/12/03/cac-nhan-to-anh-huong-den-hanh-vi-nguoi-tieu-dung-doi-voi-hoat-dong-13-1-120x90.jpg)
![Mobile Phone Usage in Hanoi Inner City Area
zt2i3t4l5ee
zt2a3gsconsumer,consumption,consumer behavior,marketing,mobile marketing
zt2a3ge
zc2o3n4t5e6n7ts
- Test the relationship between demographic variables and consumer behavior for Mobile Marketing activities
The analysis method used is the Chi-square test (χ2), with statistical hypotheses H0 and H1 and significance level α = 0.05. In case the P index (p-value) or Sig. index in SPSS has a value less than or equal to the significance level α, the hypothesis H0 is rejected and vice versa. With this testing procedure, the study can evaluate the difference in behavioral trends between demographic groups.
CHAPTER 4
RESEARCH RESULTS
During two months, 1,100 survey questionnaires were distributed to mobile phone users in the inner city of Hanoi using various methods such as direct interviews, sending via email or using questionnaires designed on the Internet. At the end of the survey, after checking and eliminating erroneous questionnaires, the study collected 858 complete questionnaires, equivalent to a rate of about 78%. In addition, the research subjects of the thesis are only people who are using mobile phones, so people who do not use mobile phones are not within the scope of the thesis, therefore, the questionnaires with the option of not using mobile phones were excluded from the scope of analysis. The number of suitable survey questionnaires included in the statistical analysis was 835.
4.1 Demographic characteristics of the sample
The structure of the survey sample is divided and statistically analyzed according to criteria such as gender, age, occupation, education level and personal income. (Detailed statistical table in Appendix 6)
- Gender structure: Of the 835 completed questionnaires, 49.8% of respondents were male, equivalent to 416 people, and 50.2% were female, equivalent to 419 people. The survey results of the study are completely consistent with the gender ratio in the population structure of Vietnam in general and Hanoi in particular (Male/Female: 49/51).
- Age structure: 36.6% of respondents are <23 years old, equivalent to 306 people. People from 23-34 years old
accounting for the highest proportion: 44.8% equivalent to 374 people, people aged 35-45 and >45 are 70 and 85 people equivalent to 8.4% and 10.2% respectively. Looking at the results of this survey, we can see that the young people - youth account for a large proportion of the total number of people participating in the survey. Meanwhile, the middle-aged people including two age groups of 35 - 45 and >45 have a low rate of participation in the survey. This is completely consistent with the reality when Mobile Marketing is identified as a Marketing service aimed at young people (people under 35 years old).
- Structure by educational level: among 835 valid responses, 541 respondents had university degrees, accounting for the highest proportion of ~ 75%, 102 had secondary school degrees, ~ 13.1%, and 93 had post-graduate degrees, ~ 11.9%.
- Occupational structure: office workers and civil servants are the group with the highest rate of participation with 39.4%, followed by students with 36.6%. Self-employed people account for 12%, retired housewives are 7.8% and other occupational groups account for 4.2%. The survey results show that the student group has the same rate as the group aged <23 at 36.6%. This shows the accuracy of the survey data. In addition, the survey results distributed by occupational criteria have a rate almost similar to the sample division rate in chapter 3. Therefore, it can be concluded that the survey data is suitable for use in analysis activities.
- Income structure: the group with income from 3 to 5 million has the highest rate with 39% of the total number of respondents. This is consistent with the income structure of Hanoi people and corresponds to the average income of the group of civil servants and office workers. Those
People with no income account for 23%, income under 3 million VND accounts for 13% and income over 5 million VND accounts for 25%.
4.2 Mobile phone usage in Hanoi inner city area
According to the survey results, most respondents said they had used the phone for more than 1 year, specifically: 68.4% used mobile phones from 4 to 10 years, 23.2% used from 1 to 3 years, 7.8% used for more than 10 years. Those who used mobile phones for less than 1 year accounted for only a very small proportion of ~ 0.6%. (Table 4.1)
Table 4.1: Time spent using mobile phones
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Alid
<1 year
5
.6
.6
.6
1-3 years
194
23.2
23.2
23.8
4-10 years
571
68.4
68.4
92.2
>10 years
65
7.8
7.8
100.0
Total
835
100.0
100.0
The survey indexes on the time of using mobile phones of consumers in the inner city of Hanoi are very impressive for a developing country like Vietnam and also prove that Vietnamese consumers have a lot of experience using this high-tech device. Moreover, with the majority of consumers surveyed having a relatively long time of use (4-10 years), it partly proves that mobile phones have become an important and essential item in peoples daily lives.
When asked about the mobile phone network they are using, 31% of respondents said they are using the network of Vietel company, 29% use the network of
of Mobifone company, 27% use Vinaphone companys network and 13% use networks of other providers such as E-VN telecom, S-fone, Beeline, Vietnammobile. (Figure 4.1).
Figure 4.1: Mobile phone network in use
Compared with the announced market share of mobile telecommunications service providers in Vietnam (Vietel: 36%, Mobifone: 29%, Vinaphone: 28%, the remaining networks: 7%), we see that the survey results do not have many differences. However, the statistics show that there is a difference in the market share of other networks because the Hanoi market is one of the two main markets of small networks, so their market share in this area will certainly be higher than that of the whole country.
According to a report by NielsenMobile (2009) [8], the number of prepaid mobile phone subscribers in Hanoi accounts for 95% of the total number of subscribers, however, the results of this survey show that the percentage of prepaid subscribers has decreased by more than 20%, only at 70.8%. On the contrary, the number of postpaid subscribers tends to increase from 5% in 2009 to 19.2%. Those who are simultaneously using both types of subscriptions account for 10%. (Table 4.2).
Table 4.2: Types of mobile phone subscribers
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Prepay
591
70.8
70.8
70.8
Pay later
160
19.2
19.2
89.9
Both of the above
84
10.1
10.1
100.0
Total
835
100.0
100.0
The above figures show the change in the psychology and consumption habits of Vietnamese consumers towards mobile telecommunications services, when the use of prepaid subscriptions and junk SIMs is replaced by the use of two types of subscriptions for different purposes and needs or switching to postpaid subscriptions to enjoy better customer care services.
In addition, the majority of respondents have an average spending level for mobile phone services from 100 to 300 thousand VND (406 ~ 48.6% of total respondents). The high spending level (> 500 thousand VND) is the spending level with the lowest number of people with only 8.4%, on the contrary, the low spending level (under 100 thousand VND) accounts for the second highest proportion among the groups of respondents with 25.4%. People with low spending levels mainly fall into the group of students and retirees/housewives - those who have little need to use or mainly use promotional SIM cards. (Table 4.3).
Table 4.3: Spending on mobile phone charges
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<100,000
212
25.4
25.4
25.4
100-300,000
406
48.6
48.6
74.0
300,000-500,000
147
17.6
17.6
91.6
>500,000
70
8.4
8.4
100.0
Total
835
100.0
100.0
The statistics in Table 4.3 are similar to the percentages in the NielsenMobile survey results (2009) with 73% of mobile phone users having medium spending levels and only 13% having high spending levels.
The survey results also showed that up to 31% ~ nearly one-third of respondents said they sent more than 10 SMS messages/day, meaning that on average they sent 1 SMS message for every working hour. Those with an average SMS message volume (from 3 to 10 messages/day) accounted for 51.1% and those with a low SMS message volume (less than 3 messages/day) accounted for 17%. (Table 4.4)
Table 4.4: Number of SMS messages sent per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
142
17.0
17.0
17.0
3-10 news
427
51.1
51.1
68.1
>10 news
266
31.9
31.9
100.0
Total
835
100.0
100.0
Similar to sending messages, those with an average message receiving rate (from 3-10 messages/day) accounted for the highest percentage of ~ 55%, followed by those with a high number of messages (over 10 messages/day) ~ 24% and those with a low number of messages received daily (under 3 messages/day) remained at the bottom with 21%. (Table 4.5)
Table 4.5: Number of SMS messages received per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
175
21.0
21.0
21.0
3-10 news
436
55.0
55.0
76.0
>10 news
197
24.0
24.0
100.0
Total
835
100.0
100.0
When comparing the data of the two result tables 4.4 and 4.5, we can see the reasonableness between the ratio of the number of messages sent and the number of messages received daily by the interview participants.
4.3 Current status of SMS advertising and Mobile Marketing
According to the interview results, in the 3 months from the time of the survey and before, 94% of respondents, equivalent to 785 people, said they received advertising messages, while only a very small percentage of 6% (only 50 people) did not receive advertising messages (Table 4.6).
Table 4.6: Percentage of people receiving advertising messages in the last 3 months
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Have
785
94.0
94.0
94.0
Are not
50
6.0
6.0
100.0
Total
835
100.0
100.0
The results of Table 4.6 show that consumers in the inner city of Hanoi are very familiar with advertising messages. This result is also the basis for assessing the knowledge, experience and understanding of the respondents in the interview. This is also one of the important factors determining the accuracy of the survey results.
In addition, most respondents said they had received promotional messages, but only 24% of them had ever taken the action of registering to receive promotional messages, while 76% of the remaining respondents did not register to receive promotional messages but still received promotional messages every day. This is the first sign indicating the weaknesses and shortcomings of lax management of this activity in Vietnam. (Table 4.7)
div.maincontent .s1 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s2 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s4 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s5 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s15 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s16 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 5.5pt; vertical-align: 3pt; } div.maincontent .s17 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 8.5pt; } div.maincontent .s18 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s20 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s21 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s22 { color: black; font-family:Courier New, monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s23 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s24 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s25 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s26 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s27 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 1.5pt; } div.maincontent .s28 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s29 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s30 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s31 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s32 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s33 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s36 { color: #F00; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s37 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s38 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 8.5pt; vertical-align: 5pt; } div.maincontent .s39 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s40 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 4pt; } div.maincontent .s41 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s42 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s43 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7.5pt; vertical-align: 5pt; } div.maincontent .s44 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s45 { color: #F00; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s46 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s47 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s48 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s49 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s50 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s51 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s52 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s53 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s54 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s55 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s56 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s57 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s58 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s59 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s60 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 13pt; } div.maincontent .s61 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s62 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s63 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .content_head2 { color: #F00; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s64 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s67 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s68 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s69 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s70 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; tex](data:image/svg+xml,%3Csvg%20xmlns=%22http://www.w3.org/2000/svg%22%20viewBox=%220%200%2075%2075%22%3E%3C/svg%3E) Mobile Phone Usage in Hanoi Inner City Area
zt2i3t4l5ee
zt2a3gsconsumer,consumption,consumer behavior,marketing,mobile marketing
zt2a3ge
zc2o3n4t5e6n7ts
- Test the relationship between demographic variables and consumer behavior for Mobile Marketing activities
The analysis method used is the Chi-square test (χ2), with statistical hypotheses H0 and H1 and significance level α = 0.05. In case the P index (p-value) or Sig. index in SPSS has a value less than or equal to the significance level α, the hypothesis H0 is rejected and vice versa. With this testing procedure, the study can evaluate the difference in behavioral trends between demographic groups.
CHAPTER 4
RESEARCH RESULTS
During two months, 1,100 survey questionnaires were distributed to mobile phone users in the inner city of Hanoi using various methods such as direct interviews, sending via email or using questionnaires designed on the Internet. At the end of the survey, after checking and eliminating erroneous questionnaires, the study collected 858 complete questionnaires, equivalent to a rate of about 78%. In addition, the research subjects of the thesis are only people who are using mobile phones, so people who do not use mobile phones are not within the scope of the thesis, therefore, the questionnaires with the option of not using mobile phones were excluded from the scope of analysis. The number of suitable survey questionnaires included in the statistical analysis was 835.
4.1 Demographic characteristics of the sample
The structure of the survey sample is divided and statistically analyzed according to criteria such as gender, age, occupation, education level and personal income. (Detailed statistical table in Appendix 6)
- Gender structure: Of the 835 completed questionnaires, 49.8% of respondents were male, equivalent to 416 people, and 50.2% were female, equivalent to 419 people. The survey results of the study are completely consistent with the gender ratio in the population structure of Vietnam in general and Hanoi in particular (Male/Female: 49/51).
- Age structure: 36.6% of respondents are <23 years old, equivalent to 306 people. People from 23-34 years old
accounting for the highest proportion: 44.8% equivalent to 374 people, people aged 35-45 and >45 are 70 and 85 people equivalent to 8.4% and 10.2% respectively. Looking at the results of this survey, we can see that the young people - youth account for a large proportion of the total number of people participating in the survey. Meanwhile, the middle-aged people including two age groups of 35 - 45 and >45 have a low rate of participation in the survey. This is completely consistent with the reality when Mobile Marketing is identified as a Marketing service aimed at young people (people under 35 years old).
- Structure by educational level: among 835 valid responses, 541 respondents had university degrees, accounting for the highest proportion of ~ 75%, 102 had secondary school degrees, ~ 13.1%, and 93 had post-graduate degrees, ~ 11.9%.
- Occupational structure: office workers and civil servants are the group with the highest rate of participation with 39.4%, followed by students with 36.6%. Self-employed people account for 12%, retired housewives are 7.8% and other occupational groups account for 4.2%. The survey results show that the student group has the same rate as the group aged <23 at 36.6%. This shows the accuracy of the survey data. In addition, the survey results distributed by occupational criteria have a rate almost similar to the sample division rate in chapter 3. Therefore, it can be concluded that the survey data is suitable for use in analysis activities.
- Income structure: the group with income from 3 to 5 million has the highest rate with 39% of the total number of respondents. This is consistent with the income structure of Hanoi people and corresponds to the average income of the group of civil servants and office workers. Those
People with no income account for 23%, income under 3 million VND accounts for 13% and income over 5 million VND accounts for 25%.
4.2 Mobile phone usage in Hanoi inner city area
According to the survey results, most respondents said they had used the phone for more than 1 year, specifically: 68.4% used mobile phones from 4 to 10 years, 23.2% used from 1 to 3 years, 7.8% used for more than 10 years. Those who used mobile phones for less than 1 year accounted for only a very small proportion of ~ 0.6%. (Table 4.1)
Table 4.1: Time spent using mobile phones
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Alid
<1 year
5
.6
.6
.6
1-3 years
194
23.2
23.2
23.8
4-10 years
571
68.4
68.4
92.2
>10 years
65
7.8
7.8
100.0
Total
835
100.0
100.0
The survey indexes on the time of using mobile phones of consumers in the inner city of Hanoi are very impressive for a developing country like Vietnam and also prove that Vietnamese consumers have a lot of experience using this high-tech device. Moreover, with the majority of consumers surveyed having a relatively long time of use (4-10 years), it partly proves that mobile phones have become an important and essential item in people's daily lives.
When asked about the mobile phone network they are using, 31% of respondents said they are using the network of Vietel company, 29% use the network of
of Mobifone company, 27% use Vinaphone company's network and 13% use networks of other providers such as E-VN telecom, S-fone, Beeline, Vietnammobile. (Figure 4.1).
Figure 4.1: Mobile phone network in use
Compared with the announced market share of mobile telecommunications service providers in Vietnam (Vietel: 36%, Mobifone: 29%, Vinaphone: 28%, the remaining networks: 7%), we see that the survey results do not have many differences. However, the statistics show that there is a difference in the market share of other networks because the Hanoi market is one of the two main markets of small networks, so their market share in this area will certainly be higher than that of the whole country.
According to a report by NielsenMobile (2009) [8], the number of prepaid mobile phone subscribers in Hanoi accounts for 95% of the total number of subscribers, however, the results of this survey show that the percentage of prepaid subscribers has decreased by more than 20%, only at 70.8%. On the contrary, the number of postpaid subscribers tends to increase from 5% in 2009 to 19.2%. Those who are simultaneously using both types of subscriptions account for 10%. (Table 4.2).
Table 4.2: Types of mobile phone subscribers
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Prepay
591
70.8
70.8
70.8
Pay later
160
19.2
19.2
89.9
Both of the above
84
10.1
10.1
100.0
Total
835
100.0
100.0
The above figures show the change in the psychology and consumption habits of Vietnamese consumers towards mobile telecommunications services, when the use of prepaid subscriptions and junk SIMs is replaced by the use of two types of subscriptions for different purposes and needs or switching to postpaid subscriptions to enjoy better customer care services.
In addition, the majority of respondents have an average spending level for mobile phone services from 100 to 300 thousand VND (406 ~ 48.6% of total respondents). The high spending level (> 500 thousand VND) is the spending level with the lowest number of people with only 8.4%, on the contrary, the low spending level (under 100 thousand VND) accounts for the second highest proportion among the groups of respondents with 25.4%. People with low spending levels mainly fall into the group of students and retirees/housewives - those who have little need to use or mainly use promotional SIM cards. (Table 4.3).
Table 4.3: Spending on mobile phone charges
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<100,000
212
25.4
25.4
25.4
100-300,000
406
48.6
48.6
74.0
300,000-500,000
147
17.6
17.6
91.6
>500,000
70
8.4
8.4
100.0
Total
835
100.0
100.0
The statistics in Table 4.3 are similar to the percentages in the NielsenMobile survey results (2009) with 73% of mobile phone users having medium spending levels and only 13% having high spending levels.
The survey results also showed that up to 31% ~ nearly one-third of respondents said they sent more than 10 SMS messages/day, meaning that on average they sent 1 SMS message for every working hour. Those with an average SMS message volume (from 3 to 10 messages/day) accounted for 51.1% and those with a low SMS message volume (less than 3 messages/day) accounted for 17%. (Table 4.4)
Table 4.4: Number of SMS messages sent per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
142
17.0
17.0
17.0
3-10 news
427
51.1
51.1
68.1
>10 news
266
31.9
31.9
100.0
Total
835
100.0
100.0
Similar to sending messages, those with an average message receiving rate (from 3-10 messages/day) accounted for the highest percentage of ~ 55%, followed by those with a high number of messages (over 10 messages/day) ~ 24% and those with a low number of messages received daily (under 3 messages/day) remained at the bottom with 21%. (Table 4.5)
Table 4.5: Number of SMS messages received per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
175
21.0
21.0
21.0
3-10 news
436
55.0
55.0
76.0
>10 news
197
24.0
24.0
100.0
Total
835
100.0
100.0
When comparing the data of the two result tables 4.4 and 4.5, we can see the reasonableness between the ratio of the number of messages sent and the number of messages received daily by the interview participants.
4.3 Current status of SMS advertising and Mobile Marketing
According to the interview results, in the 3 months from the time of the survey and before, 94% of respondents, equivalent to 785 people, said they received advertising messages, while only a very small percentage of 6% (only 50 people) did not receive advertising messages (Table 4.6).
Table 4.6: Percentage of people receiving advertising messages in the last 3 months
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Have
785
94.0
94.0
94.0
Are not
50
6.0
6.0
100.0
Total
835
100.0
100.0
The results of Table 4.6 show that consumers in the inner city of Hanoi are very familiar with advertising messages. This result is also the basis for assessing the knowledge, experience and understanding of the respondents in the interview. This is also one of the important factors determining the accuracy of the survey results.
In addition, most respondents said they had received promotional messages, but only 24% of them had ever taken the action of registering to receive promotional messages, while 76% of the remaining respondents did not register to receive promotional messages but still received promotional messages every day. This is the first sign indicating the weaknesses and shortcomings of lax management of this activity in Vietnam. (Table 4.7)
div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s15 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s16 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 5.5pt; vertical-align: 3pt; } div.maincontent .s17 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 8.5pt; } div.maincontent .s18 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s20 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s21 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s22 { color: black; font-family:"Courier New", monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s23 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s24 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s25 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s26 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s27 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 1.5pt; } div.maincontent .s28 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s29 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s30 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s31 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s32 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s33 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s36 { color: #F00; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s37 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s38 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 8.5pt; vertical-align: 5pt; } div.maincontent .s39 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s40 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 4pt; } div.maincontent .s41 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s42 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s43 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7.5pt; vertical-align: 5pt; } div.maincontent .s44 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s45 { color: #F00; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s46 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s47 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s48 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s49 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s50 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s51 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s52 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s53 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s54 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s55 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s56 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s57 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s58 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s59 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s60 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 13pt; } div.maincontent .s61 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s62 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s63 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .content_head2 { color: #F00; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s64 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s67 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s68 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s69 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s70 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; tex
Mobile Phone Usage in Hanoi Inner City Area
zt2i3t4l5ee
zt2a3gsconsumer,consumption,consumer behavior,marketing,mobile marketing
zt2a3ge
zc2o3n4t5e6n7ts
- Test the relationship between demographic variables and consumer behavior for Mobile Marketing activities
The analysis method used is the Chi-square test (χ2), with statistical hypotheses H0 and H1 and significance level α = 0.05. In case the P index (p-value) or Sig. index in SPSS has a value less than or equal to the significance level α, the hypothesis H0 is rejected and vice versa. With this testing procedure, the study can evaluate the difference in behavioral trends between demographic groups.
CHAPTER 4
RESEARCH RESULTS
During two months, 1,100 survey questionnaires were distributed to mobile phone users in the inner city of Hanoi using various methods such as direct interviews, sending via email or using questionnaires designed on the Internet. At the end of the survey, after checking and eliminating erroneous questionnaires, the study collected 858 complete questionnaires, equivalent to a rate of about 78%. In addition, the research subjects of the thesis are only people who are using mobile phones, so people who do not use mobile phones are not within the scope of the thesis, therefore, the questionnaires with the option of not using mobile phones were excluded from the scope of analysis. The number of suitable survey questionnaires included in the statistical analysis was 835.
4.1 Demographic characteristics of the sample
The structure of the survey sample is divided and statistically analyzed according to criteria such as gender, age, occupation, education level and personal income. (Detailed statistical table in Appendix 6)
- Gender structure: Of the 835 completed questionnaires, 49.8% of respondents were male, equivalent to 416 people, and 50.2% were female, equivalent to 419 people. The survey results of the study are completely consistent with the gender ratio in the population structure of Vietnam in general and Hanoi in particular (Male/Female: 49/51).
- Age structure: 36.6% of respondents are <23 years old, equivalent to 306 people. People from 23-34 years old
accounting for the highest proportion: 44.8% equivalent to 374 people, people aged 35-45 and >45 are 70 and 85 people equivalent to 8.4% and 10.2% respectively. Looking at the results of this survey, we can see that the young people - youth account for a large proportion of the total number of people participating in the survey. Meanwhile, the middle-aged people including two age groups of 35 - 45 and >45 have a low rate of participation in the survey. This is completely consistent with the reality when Mobile Marketing is identified as a Marketing service aimed at young people (people under 35 years old).
- Structure by educational level: among 835 valid responses, 541 respondents had university degrees, accounting for the highest proportion of ~ 75%, 102 had secondary school degrees, ~ 13.1%, and 93 had post-graduate degrees, ~ 11.9%.
- Occupational structure: office workers and civil servants are the group with the highest rate of participation with 39.4%, followed by students with 36.6%. Self-employed people account for 12%, retired housewives are 7.8% and other occupational groups account for 4.2%. The survey results show that the student group has the same rate as the group aged <23 at 36.6%. This shows the accuracy of the survey data. In addition, the survey results distributed by occupational criteria have a rate almost similar to the sample division rate in chapter 3. Therefore, it can be concluded that the survey data is suitable for use in analysis activities.
- Income structure: the group with income from 3 to 5 million has the highest rate with 39% of the total number of respondents. This is consistent with the income structure of Hanoi people and corresponds to the average income of the group of civil servants and office workers. Those
People with no income account for 23%, income under 3 million VND accounts for 13% and income over 5 million VND accounts for 25%.
4.2 Mobile phone usage in Hanoi inner city area
According to the survey results, most respondents said they had used the phone for more than 1 year, specifically: 68.4% used mobile phones from 4 to 10 years, 23.2% used from 1 to 3 years, 7.8% used for more than 10 years. Those who used mobile phones for less than 1 year accounted for only a very small proportion of ~ 0.6%. (Table 4.1)
Table 4.1: Time spent using mobile phones
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Alid
<1 year
5
.6
.6
.6
1-3 years
194
23.2
23.2
23.8
4-10 years
571
68.4
68.4
92.2
>10 years
65
7.8
7.8
100.0
Total
835
100.0
100.0
The survey indexes on the time of using mobile phones of consumers in the inner city of Hanoi are very impressive for a developing country like Vietnam and also prove that Vietnamese consumers have a lot of experience using this high-tech device. Moreover, with the majority of consumers surveyed having a relatively long time of use (4-10 years), it partly proves that mobile phones have become an important and essential item in people's daily lives.
When asked about the mobile phone network they are using, 31% of respondents said they are using the network of Vietel company, 29% use the network of
of Mobifone company, 27% use Vinaphone company's network and 13% use networks of other providers such as E-VN telecom, S-fone, Beeline, Vietnammobile. (Figure 4.1).
Figure 4.1: Mobile phone network in use
Compared with the announced market share of mobile telecommunications service providers in Vietnam (Vietel: 36%, Mobifone: 29%, Vinaphone: 28%, the remaining networks: 7%), we see that the survey results do not have many differences. However, the statistics show that there is a difference in the market share of other networks because the Hanoi market is one of the two main markets of small networks, so their market share in this area will certainly be higher than that of the whole country.
According to a report by NielsenMobile (2009) [8], the number of prepaid mobile phone subscribers in Hanoi accounts for 95% of the total number of subscribers, however, the results of this survey show that the percentage of prepaid subscribers has decreased by more than 20%, only at 70.8%. On the contrary, the number of postpaid subscribers tends to increase from 5% in 2009 to 19.2%. Those who are simultaneously using both types of subscriptions account for 10%. (Table 4.2).
Table 4.2: Types of mobile phone subscribers
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Prepay
591
70.8
70.8
70.8
Pay later
160
19.2
19.2
89.9
Both of the above
84
10.1
10.1
100.0
Total
835
100.0
100.0
The above figures show the change in the psychology and consumption habits of Vietnamese consumers towards mobile telecommunications services, when the use of prepaid subscriptions and junk SIMs is replaced by the use of two types of subscriptions for different purposes and needs or switching to postpaid subscriptions to enjoy better customer care services.
In addition, the majority of respondents have an average spending level for mobile phone services from 100 to 300 thousand VND (406 ~ 48.6% of total respondents). The high spending level (> 500 thousand VND) is the spending level with the lowest number of people with only 8.4%, on the contrary, the low spending level (under 100 thousand VND) accounts for the second highest proportion among the groups of respondents with 25.4%. People with low spending levels mainly fall into the group of students and retirees/housewives - those who have little need to use or mainly use promotional SIM cards. (Table 4.3).
Table 4.3: Spending on mobile phone charges
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<100,000
212
25.4
25.4
25.4
100-300,000
406
48.6
48.6
74.0
300,000-500,000
147
17.6
17.6
91.6
>500,000
70
8.4
8.4
100.0
Total
835
100.0
100.0
The statistics in Table 4.3 are similar to the percentages in the NielsenMobile survey results (2009) with 73% of mobile phone users having medium spending levels and only 13% having high spending levels.
The survey results also showed that up to 31% ~ nearly one-third of respondents said they sent more than 10 SMS messages/day, meaning that on average they sent 1 SMS message for every working hour. Those with an average SMS message volume (from 3 to 10 messages/day) accounted for 51.1% and those with a low SMS message volume (less than 3 messages/day) accounted for 17%. (Table 4.4)
Table 4.4: Number of SMS messages sent per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
142
17.0
17.0
17.0
3-10 news
427
51.1
51.1
68.1
>10 news
266
31.9
31.9
100.0
Total
835
100.0
100.0
Similar to sending messages, those with an average message receiving rate (from 3-10 messages/day) accounted for the highest percentage of ~ 55%, followed by those with a high number of messages (over 10 messages/day) ~ 24% and those with a low number of messages received daily (under 3 messages/day) remained at the bottom with 21%. (Table 4.5)
Table 4.5: Number of SMS messages received per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
175
21.0
21.0
21.0
3-10 news
436
55.0
55.0
76.0
>10 news
197
24.0
24.0
100.0
Total
835
100.0
100.0
When comparing the data of the two result tables 4.4 and 4.5, we can see the reasonableness between the ratio of the number of messages sent and the number of messages received daily by the interview participants.
4.3 Current status of SMS advertising and Mobile Marketing
According to the interview results, in the 3 months from the time of the survey and before, 94% of respondents, equivalent to 785 people, said they received advertising messages, while only a very small percentage of 6% (only 50 people) did not receive advertising messages (Table 4.6).
Table 4.6: Percentage of people receiving advertising messages in the last 3 months
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Have
785
94.0
94.0
94.0
Are not
50
6.0
6.0
100.0
Total
835
100.0
100.0
The results of Table 4.6 show that consumers in the inner city of Hanoi are very familiar with advertising messages. This result is also the basis for assessing the knowledge, experience and understanding of the respondents in the interview. This is also one of the important factors determining the accuracy of the survey results.
In addition, most respondents said they had received promotional messages, but only 24% of them had ever taken the action of registering to receive promotional messages, while 76% of the remaining respondents did not register to receive promotional messages but still received promotional messages every day. This is the first sign indicating the weaknesses and shortcomings of lax management of this activity in Vietnam. (Table 4.7)
div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s15 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s16 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 5.5pt; vertical-align: 3pt; } div.maincontent .s17 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 8.5pt; } div.maincontent .s18 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s20 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s21 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s22 { color: black; font-family:"Courier New", monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s23 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s24 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s25 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s26 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s27 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 1.5pt; } div.maincontent .s28 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s29 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s30 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s31 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s32 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s33 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s36 { color: #F00; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s37 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s38 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 8.5pt; vertical-align: 5pt; } div.maincontent .s39 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s40 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 4pt; } div.maincontent .s41 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s42 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s43 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7.5pt; vertical-align: 5pt; } div.maincontent .s44 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s45 { color: #F00; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s46 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s47 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s48 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s49 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s50 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s51 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s52 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s53 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s54 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s55 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s56 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s57 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s58 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s59 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s60 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 13pt; } div.maincontent .s61 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s62 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s63 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .content_head2 { color: #F00; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s64 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s67 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s68 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s69 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s70 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; tex -
 Testing Factors Affecting Customer Satisfaction With Savings Deposit Services At Dong A Bank
Testing Factors Affecting Customer Satisfaction With Savings Deposit Services At Dong A Bank -
 Average Proportion of Enterprises by Size in the Period 2000-2009 (Source: General Statistics Office)
Average Proportion of Enterprises by Size in the Period 2000-2009 (Source: General Statistics Office) -
 Measure 2: Develop a Management Plan for Testing and Evaluating Students' English Proficiency
Measure 2: Develop a Management Plan for Testing and Evaluating Students' English Proficiency -
 Hypothesis Testing About the Significance of Regression Coefficients
Hypothesis Testing About the Significance of Regression Coefficients
Type I error : Reject H 0when in fact H 0true. The probability of making a type I error is denoted by the symbol .
Type II error : Accept H 0when in fact H 0false. The probability of making a type II error is denoted by the symbol .
The appropriateness of a statistical test is measured by the probability of making a type I error and a type II error. Because is the probability of rejecting H 0When in fact this hypothesis is true, this is a measure of the chance of falsely rejecting H 0. Because is the probability of accepting H 0When
In fact this hypothesis is false, so its complement, 1 is the probability of rejecting H 0 when
This hypothesis is false. Probability 1 is called the power of the model's test .
Another way to report the test results is through the p-value . The probability of making a type I error is often called the significance level of the test model, and during the test we can choose different significance levels (for example 0.05 z /2 1.96 ,
0.01 z /2 2.58 ,…) so sometimes the test result rejects at the first significance level, but accepts at the second significance level. So sometimes the reports will choose the lowest significance level for the test model to be meaningful.
The observed p -value or significance level is the smallest value of for which the test models
statistically significant
If a test result is statistically significant with 0.10 but not significant with
0.05 then we can understand the p value as a number in the range 0.05 p 0.10 . In other words, if the p value is less than the value , then we reject the hypothesis H 0and vice versa.
6.2. HYPOTHESIS TESTING FOR A POPULATION PROPORTION VALUE.
6.2.1 Analysis.
Consider a population and a characteristic A , each element in the population has only two properties: it has property A or it does not have property A. Considering a specific data sample, we need to test the hypothesis that the proportion of type A elements in this population is p , then p is equal to the value p 0given or not with significance level .
Observe each element and see if the observed element has property A or not. Do the job.
n times, respectively is the data sample. Let X be the random variable indexing the element with property A
, combining the assumption p p 0 we have (according to chapters 3 and 6) we have:
np 0 1p 0
X ~ N np , np 1 p z
X np 0
~ N 0;1
o 0 0
Let f be the proportion of elements with property A in n observed elements. We have
z X np 0
X p
np 0 1 p 0
n 0
np 0 1 p 0
n
f p 0
p 0 1 p 0
n ~ N 0;1
The z value is a measure of the difference between f (the proportion of elements with property A in the data sample, represented by p ) and p 0.
In the test problem with the hypothesis H 0: p p 0and the opposite H 1: p p 0.
The significance level is equally divided between the two sides and P z z /2 : is the probability of deciding to reject the hypothesis H 0when in fact the hypothesis H 0correct.
That is, we accept the covariance H 1 when z z /2 or
z z /2
In the test problem with the hypothesis H 0: p p 0and the opposite H 1: p p 0.
The significance level α is right-sided and P zz : is the probability of deciding to reject the hypothesis H 0when in fact the hypothesis H 0correct.
That is, we accept the contradiction H 1 when z z
In the test problem with the hypothesis H 0: p p 0and the opposite H 1: p p 0.
The significance level α is right-sided and P z z : is the probability of deciding to reject the hypothesis H 0when in fact the hypothesis H 0correct.
That is, we accept the covariance H 1 when z z
1. Null hypothesis H 0 : p p 0
2. Hypothesis
3. Statistical value
Where f is the proportion of elements with characteristic A in the sample. The statistical value is: z
4. Rejection Domain
6.2.2 Testing model.
Two-sided testing
One-sided test | |
H 1 : p p 0 | H 1 : p p 0 H 1 : p p 0 |
f p 0 p 0 1 p 0
n
Two-sided testing
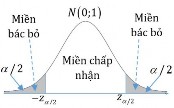
Parallelism : H 1 : p p 0
Reject H 0 when:
z z /2
z z z z /2
/2
One-sided inspection Opposite : H 1 : p p 0 Reject H 0 when: z z /2 | One-sided inspection
Opposite : H 1 : p p 0 Reject H 0 when: z z |
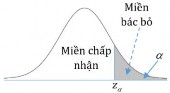
f p 0 p 0 1 p 0
n
Example 6.3 Previous reports of a survey of the family background of freshmen at a university reported that 86% of first-year university students had some financial support. This year, the university conducted a similar survey on the same issue, asking 1,000 randomly selected freshmen and found that 890 students received financial support from their families. With a significance level of 5% , are the above reports still true for this year's student situation?
Solution. The testing model in this case has the form
1.
H 0 : p 86% and H 1 : p 86%
Where p is the proportion of freshmen receiving financial aid from their families.
And the given data is: n 1000 and f 890 0.89
2.
1000
The statistic used in this model is z
3.
In which p 0 0.86 so we have z 2,734
The significance level of the test is 5% corresponding to the z percentile /2 1.96 .
Conclusion : because the statistical value is higher than the z- percentilez /2 so we can completely reject the hypothesis H 0, that is
The percentage of freshmen this year receiving financial aid from their families is different than reported in previous years.
6.3. HYPOTHESIS TESTING FOR A POPULATION MEAN.
6.3.1 Analysis.
Consider a population, let be the average value of the population, based on a specific sample we need to check
assume that the population mean is equal to the value 0given zero with significance level .
Let X be a random variable indicating the value of an element in the population, assuming X has a normal distribution law X ~ N ; 2 , 2is the population variance. Consider a data sample, with sample size n and mean
of the sample is X , (according to chapter 5) we have X ~ N ; 2 . Combining the assumption
, put:
n 0
z X X 0
2
n
n ~ N 0;1
The value of z measures the difference between the sample mean (represented by ) and the null hypothesis test model H 0: 0.
0, is the statistical value
In case the total variance is unknown, we replace the total variance with the
n 1
n 1 S 2
2
sample error S 2 . Set:
z X X . 1 X .
X
S

n
~
n 1 S 2
S
n
n
X
In there
~ N 0;1 and
2
2 n 1
so z
S
n ~ t n 1
n
But when the sample size is larger than 30, the Student's t-test is approximately equal to the normal distribution. So when the method

unknown population error and sample size n 30 , we have:
z X
S
n ~ N 0;1
Two-sided testing | One-sided test |
H 1 : 0 | H 1 : 0 H 1 : 0 |
6.3.2 Compare the overall mean with a number when the variance is known.
1. Null hypothesis H 0 : 0 .
2. Alternative hypothesis.
3. Statistical value
Statistical value: z X 0n
4. Rejection Domain
Two-sided testing
Equivalent : H 1 : 0 Reject H 0 when: z z /2 z z /2 | One-sided inspection
Equivalent: H 1 : 0 Reject H 0 when: z z | One-sided inspection
Parallelism: H 1 : 0 Reject H 0 when: z z |
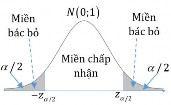
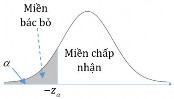

1. Null hypothesis H 0: 0.
2. Alternative hypothesis.
3. Statistical value
Statistical value: z X 0n
S
4. Rejection Domain
a. Case of sample size n 30, statistical value has normal distribution: z~ N 0;1 .
6.3.3 Comparing a population mean with a number when the variance is unknown.
Two-sided testing
One-sided test | |
H 1 : 0 | H 1 : 0 H 1 : 0 |
S / n
Two-sided testing
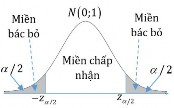
Equivalent : H 1 : 0
Reject H 0 when:
z z /2
z z
/2
One-sided inspection
Equivalent: H 1 : 0 Reject H 0 when: z z | 1 fee inspection
Parallelism: H 1 : 0 Reject H 0 when: z z | |
b. Case where sample size n 30, statistical value has Student distribution, degrees of freedom n 1 : z ~ t n 1 . 2-way inspection 1-fee inspection 1-way inspection
Equivalent : H 1 : 0 Equivalent : H 1 : 0 Opposite : H 1 : 0 Reject H 0 when : Reject H 0 when : z t n 1 z t n 1 z tn 1 /2 z tn 1 /2 | ||
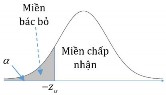
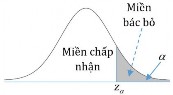
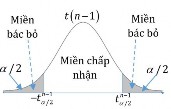


Example 6.4 Daily output at a chemical plant, recorded for n 50 days, there is a sample mean and standard deviation X 871 tons and S 21 tons. Test the hypothesis that the average daily output of the factory is 880 tons per day versus the alternative hypothesis of either greater or less than 880 tons per day.
Prize:
Testing model:
1. H 0 : 880 tons and H 1 : 880 tons
Where is the average output of the chemical plant in one day.
2. Statistical value: z X 0
In which X 871; 880; S 21; n 50 , so we have z 3.03
3.
4.
With 0.05 ; we have z /2 1.96
Conclusion: because z z /2 so we reject the hypothesis H 0; that is 880 tons is wrong.
Example 6.5 A survey of tuna catches in a certain area of the ocean over the past year reported that the average weight of a tuna in previous years was approximately 30.31 pounds.
1 pound 0.453592kg . But recently tuna fishing has increased, affecting the importance of
Average weight of a tuna in the area, survey sample of 20 fish gives the following data table:
18.9 | 39.6 | 34.4 | 19.6 | 24.1 | 39.6 | 12.2 | 25.5 | 22.1 | |
33.7 | 37.2 | 43.4 | 41.7 | 27.5 | 29.3 | 21.1 | 23.8 | 43.2 | 24.4 |
Ask whether the above data sample is strong enough to reject the above argument with significance level 5%
Solution. The corresponding testing model for the problem is: 1. H 0 : 30,31 and H 1 : 30.31
Where is the average weight of a tuna caught in this sea area.
2. Statistical value of the model: (small sample size n )20 ; total variance unknown) :
z X 0
S
n
With the obtained data we have n 20 ; X 28,935 ; S 9.5074 . So we have the value of the statistic:
z 0.6468 .
3.
4.
With significance level 5% we have the percentile using t n 1 t 192,093 .
/2 0.025
Conclusion z t 19 so there is not enough evidence to reject the null hypothesis H , that is, the mean weight
0.025
The average weight of a tuna in these waters is still 30.31 pounds.
0
6.4. HYPOTHESIS TESTING FOR THE TOTAL VARIANCE.
6.4.1 Analysis
0
Overall, let 2is the variance of the population, based on a specific data sample, we need to test the hypothesis that the population variance is equal to the value 2given or not with significance level .
In the case where the population knows the mean value is and combines the hypothesis H : 2 2. With sample
0 0
data in turn receives the value X iwith i 1, n , we have
X ~ N , 2 X i ~ N 0;1 with i 1, n .
i 0
0
According to the definition of Chi-square distribution we have:
n
X i
2
i 1 ~ 2
2 n
0
Thus is the statistical value in the hypothesis testing model H : 2 2, with the law of distribution
0 0
Chi squared degrees of freedom n .
In the case where the population mean is unknown, with S 2 being the sample variance of the data, the pseudo-match
set H : 2 2 , in Chapter 5 we have:
0 0
n 1 S 2
2
0
2
~
n 1
And we have now as the statistical value for the test model H : 2 2, when the average is unknown
0 0
overall, and has a Chi-square distribution with degrees of freedom n 1 .
1.
2.
Null hypothesis H : 2 2 .
0
0
Assume alternative.
3. Statistical value.
6.4.2 Compare the overall variance with a number when the mean µ is known.
Two-sided testing
One-sided test | |
H : 2 2 | H : 2 2 |
1 0 | 1 0 |
H : 2 2 | |
1 0 |
With : overall average.
n
x 2
i
Statistical value: i 1
2
0
4. Rejection domain.
The statistical value has a Chi-square distribution with degrees of freedom n : ~ 2
n
Two-sided testing
Correspondence: H : 2 2 1 0 Reject H 0 when: n 1 /2 n /2 | 1 fee inspection
Correspondence: H : 2 2 1 0 Reject H 0 when: n 1 | One-sided inspection
Correspondence: H : 2 2 1 0 Reject H 0 when: n |
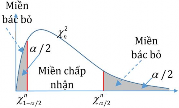
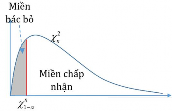
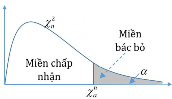
Two-sided testing | One-sided test |
H : 2 2 | H : 2 2 |
1 0 | 1 0 |
H : 2 2 | |
1 0 |
6.4.3 Comparing the overall variance with a number when the mean µ is unknown.
1. Null hypothesis H : 2 2 .
0 0
2. Alternative hypothesis.
3. Statistical value. With
n 1 S 2
Statistical value: 2
0
4. Rejection domain.
The statistical value has a Chi-square distribution with degrees of freedom n 1 : ~ 2
n 1
Two-sided testing Correspondence: H : 2 2 1 0 Reject H 0 when: n 1 1 /2 n 1 /2 | One-sided inspection Congruence: H : 2 2 1 0 Reject H 0 when: n 1 1 | One-sided inspection
Correspondence: H : 2 2 1 0 Reject H 0 when: n 1 |
