Consider the preferred subset of P4 for the set: R(A1, A2, A3) = {val1: (−5, 3, 4), val2: (−5, 4, 4),
val3: (5, 1, 8), val4: (5, 6, 6), val5: (−6, 0, 6),
val6: (−6, 0, 4), val7: (6, 2, 7)}
The “better than” graph of P4 for a subset R can be obtained by performing multiple “better-than” tests.
Maybe you are interested!
-

 General Theoretical Basis of Corporate Finance and Corporate Financial Analysis.
General Theoretical Basis of Corporate Finance and Corporate Financial Analysis. -
 Analysis of Current Status of Tourism Activities in Phong Dien District
Analysis of Current Status of Tourism Activities in Phong Dien District -
 Analysis of Capital Structure and Cost of Capital at Some Typical Enterprises
Analysis of Capital Structure and Cost of Capital at Some Typical Enterprises -
 Analysis of Capital Situation Through Balance Sheet
Analysis of Capital Situation Through Balance Sheet -
 Analysis and proposal of solutions to expand retail activities at Military Commercial Joint Stock Bank - 1
Analysis and proposal of solutions to expand retail activities at Military Commercial Joint Stock Bank - 1
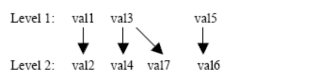
Hence the optimal Pareto set is {val1, val3, val5}. Note that for each P1, P2 and P3 there is at least one maximum value appearing in the optimal Pareto set: 5 and -5 for P1, 0 for P2 and 8 for P3.

Definition 6: Preferred priority: P1&P2
P1 is considered more important than P2; P2 is given attention only when P1 is not.
Attention:
Given P1 = (A1,
x
P = (A1 ∪ A2,
Definition 7: Preferred number type: rank F (P1, P2)
Given P1 = SCORE(A1, f1), P2 = SCORE(A2, f2) and an associative function F: ℝ × ℝ
→ ℝ , for x, y ∈ dom(A1) × dom(A2) we define: x
F(f1(x 1 ), f2(x 2 )) < F(f1(y 1 ), f2(y 2 ))
P = (A1 ∪ A2,
Note that rank p is not an orthogonal preferred structure like □ or &.
It can only be used for SCORE preference. But through versa, the product preference can be used as input data for all other preference structures.
1.3.3.2 Preferred aggregation structure.
Preferred structures combine (♦ , +, ⊕ )
Continuing a difference, the technical purpose. The intersection '♦' and non-intersection '+' assemble a preference P from the parts P 1 , P 2 , ... , P n , all operating on the same set of properties. Through versa, we will see later that the complex preference can be decoded into '♦' and '+'.
We call P1 = (A1,
Definition 8: Preferred delivery and preferred departure
Suppose P1 =(A,
a) P = (A, < P1♦P2) is an intersection preference, if: x
b) Given disjoint preferences P1 and P2, P = (A,
x
Definition 9: Preferred snow sum
Given P1 = (A1,
∩ dom(A2) = □ . Then P1 and P2 are disjoint preferences. Given a new named attribute A such that dom(A) := dom(A1) ∪ dom(A2).
Then P = (A,
x
dom(A1))
The linear sum ' ⊕ ' can be viewed as a suitable design and method.
The proof of the basic preference structure. With the appropriate notion of 'other- values' we have the following state:
A preferred POS is a linear sum of multiple sequences over the POS-set with multiple sequences over other values:
↔ ↔
POS = POS-set ⊕ other-values
Similarly we follow:
↔ ↔ ↔
POS/NEG = (POS-set ⊕ other-values ) ⊕ NEG-set
↔ ↔ ↔
POS/POS = (POS1-set ⊕ POS2-set ) ⊕ other-values
↔
EXPLICIT = E ⊕ other-values
At this point, we can sum all the results stated as follows, referring back to definition 4.
Proposition 1
Each preferred term defines a strict partial order preference .
This theorem shows us the flexibility of the preferred terms depending on the requirements in specific applications.
1.3.4 Preferred hierarchy.
Preferred structures C1 and C2 can be arranged in a hierarchy. We call C1 a preferred substructure of C2 (C1 < C2), if the definition of C1 can be obtained from the domain of C2 by some special constraints.
Non-empty hierarchy. Basic preferred structure:
↔ ↔
- POS/POS < EXPLICIT, if E-graph = (POS1-set) ⊕ (POS2-set)
- POS < POS/POS, if POS2-set = □
- POS < POS/NEG, if NEG-set = □
- NEG < POS/NEG, if POS-set = □
Hierarchy of numeric base preferred structures: ('N' stands for 'numeric')
- BETWEEN < SCORE, if A is 'N' and f(x) = − distance(x, [low, up])
- AROUND < BETWEEN, if low = up
- HIGHEST < SCORE, if A is 'N' and f(x) = x
- LOWEST < SCORE, if A is 'N' and f(x) = −x
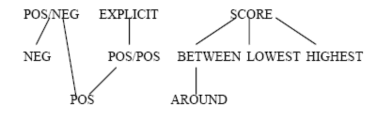
Hierarchy of complex preferred structures:
- '♦' < '⊗ '
- Not every preferred structure can be represented as a substructure of 'rank F '.[1]
Then we have specific constraints, sub-structural hierarchies are assigned.
type. In addition, there is an advantage for object-oriented software engineering that tries to save costs: The semantics of the constraint must be validated only for the highest-level preference structure. We further assume the derivation of the sub-situational structure, i.e. instead of the required structure also a sub-structure can be used. For example, rankF(P1, P2) requires that P1 and P2 are SCORE preferences. Instead, we also use preferences P1 and P2 constructed by AROUND and HIGHEST, in the given order.
1.4 Favorite Algebra.
Tight constraints are explicitly expressed by the precedence logic formulas, which can be implemented by logical algebra. Other preferences, which are expressed by preference conditions, are used to express simple constraints. It is therefore desirable to develop a preference algebra whose transformation rules lie in the preference conditions.
Further work will address the semantic issues of preference constraints. First we will need to consider the equivalence of preference terms.
Definition 10: Equivalence of preferred terms .
P1 = (A,
dom(A): x
If P1 ≡ P2, then the preferences P1 and P2 may be syntactically different, but the preferences represented by P1 and P2, .. are the same.
1.4.1 Set of algebraic laws.
Proposition 2 Associative and commutative laws . a) P1 □ P2 ≡ P2 □ P1
(P1 □ P2) □ P3 ≡ P1 □ (P2 □ P3) b) (P1 & P2) & P3 ≡ P1 & (P2 & P3)
c) P1♦ P2 ≡ P2 ♦ P1
(P1♦ P2)♦ P3 ≡ P1♦ (P2 ♦ P3) d) P1 + P2 ≡ P2 + P1
(P1 + P2) + P3 ≡ P1 + (P2 + P3)
e) (P1 ⊕ P2) ⊕ P3 ≡ P1 ⊕ (P2 ⊕ P3)
Proposition 3 Substitution rules for preferred terms
a) (S ↔ ) ∂ ≡ S ↔ for any set S , (P ∂ ) ∂ ≡ P b) (P1 ⊕ P2) ∂ ≡ P2 ∂ ⊕ P1 ∂
c) HIGHEST ≡ LOWEST ∂
d) POS ∂ ≡ NEG,
NEG ∂ ≡ POS if POS-set = NEG-set
e) P ♦ P ≡ P
f) P ♦ P δ ≡ P ♦ A ↔ ≡ A ↔ if P = (A,
g) If P1 and P2 are strings, then
P1 & P2 and P2 & P1 are strings.
∂
h) P & P ≡ P & P ≡ P
↔
i) P & A ≡ P if P = (A,
↔ ↔
j) A & P ≡ A if P = (A,
↔ ↔
k) P □ P ≡ P, A □ P ≡ A & P
↔ ∂ ↔
l) P □ A ≡ P □ P ≡ A if P = (A,
These rules are consistent with the expected visual semantics. For example, consider P □
∂ ↔ ∂
P ≡ A : When P and P are equally important, in case of conflict for the
The values of x and y are not dominant, instead of the remaining x and y being left unaffected.
∂
ranked. Then P and P are in conflict, the full domain becomes unranked.
↔
rank, reverse sequence A .
1.4.2 Prioritization and Pareto Preference Analysis
Practical interpretation of priority accumulation.
Proposition 4 Implementation for P1&P2
(a) P1&P2 ≡ P1 if P1 = (A,
↔
(b) P1&P2 ≡ P1 + (A1 &P2) if A1 ∩ A2 = □
Proposition 5. “Non-discrimination” theorem
P1 □ P2 ≡ (P1 & P2) ♦ (P2 & P1)
P1 and P2 are considered equally important by ' □ ', while both are given primary importance by ' & '. Any conflicts that arise are resolved in the transformation by the intersection ' ♦ '. As a result we have the state:
P1 □ P2 ≡ P1♦P2 if P1 = (A,
Hence '♦' is a preferred substructure of ' □ '.
1.5 Chapter Summary
We have presented a preference model that is well suited to database systems. Many real-world requirements are met by the preference model as a strict partial order: It incorporates non-numeric categories and numeric types. It has an intuitive semantics that is understood by everyone, and it can be mapped directly to mathematics. This preference model describes many of the features of frequently used preference structures. Including complex preference structures and preference algebraic rules, they will be the basis for query processing and optimization in Chapter 2.
Chapter II. PROCESSING AND OPTIMIZING RELATIONAL PREFERENCE QUERIES
2.1. Introduction
Preferences are an integral part of everyday life and commerce. Therefore, preferences must be a key factor in the design of user-oriented applications and Internet-based information systems. Human preferences are often expressed as a desire. Desires are unconstrained, but there is no limit that they can be satisfied at all times. In case the desire is not satisfied, then an equivalent, acceptable result must be accepted. Therefore, real-world preferences require a variation that is consistent with reality, that is, finding the best possible match between the desire and the reality that occurs. In other words, preferences are flexible. As we know, conventional query languages such as SQL do not provide a way to express preferences. This is a major shortcoming for database systems that support many important applications, typically in search engines for e-commerce or m-commerce. These are the key issues that preference queries will support in SQL or XML, which will make search engines better and more user-friendly. Preferences have been a major topic in many research institutes for decades, even in the economic and social sciences.
In this chapter, we focus on the key problem of preference queries. Typically, we study the challenging problem of optimal preference queries in relational databases.
2.2 Rating for favorite queries.
In SQL databases there seems to be a simple comparison. Queries against a relation R are stated as hard constraints, leading to all-or-none behavior: If the expected value is in R, you can get exactly what you want, in other cases you will not get the value.