4.3.3 Summary of factors and observed variables after EFA
In summary, after the author conducted EFA analysis for 5 independent variables and 1 dependent variable, the results of the number of factors and variables retained for the study were 5 independent variables (including 21 observed variables, including 6 observed variables proposed by the author, 15 variables inherited by the author from the 2006 adjusted HEdPERF scale) and 1 dependent factor (including 3 observed variables inherited by the author from Dang Thi Ho Thuy 2018) presented in the following table (see Appendix 11 for details).
Table 4.6: Summary of factors and observed variables after EFA
STT
Factor name | Observation variable | Number of observed variables | |
1 | Academic | Aca1, Aca2, Aca4 | 3 |
2 | Non-academic | N – Aca1, N- Aca2, N- Aca3, N-Aca4 | 4 |
3 | Reputation | Rep3, Rep4, Rep5 | 3 |
4 | Approach | Acc1, Acc2, Acc3, Acc4, Acc5, Acc6, Acc7 | 7 |
5 | Training program | Pro2, Pro3, Pro4, Pro5 | 4 |
6 | Student satisfaction | Sat1, Sat2, Sat3 | 3 |
Total | 24 | ||
Maybe you are interested!
-

 B: Summary Table of Observed Variables After 20 Comments
B: Summary Table of Observed Variables After 20 Comments -
![Mobile Phone Usage in Hanoi Inner City Area
zt2i3t4l5ee
zt2a3gsconsumer,consumption,consumer behavior,marketing,mobile marketing
zt2a3ge
zc2o3n4t5e6n7ts
- Test the relationship between demographic variables and consumer behavior for Mobile Marketing activities
The analysis method used is the Chi-square test (χ2), with statistical hypotheses H0 and H1 and significance level α = 0.05. In case the P index (p-value) or Sig. index in SPSS has a value less than or equal to the significance level α, the hypothesis H0 is rejected and vice versa. With this testing procedure, the study can evaluate the difference in behavioral trends between demographic groups.
CHAPTER 4
RESEARCH RESULTS
During two months, 1,100 survey questionnaires were distributed to mobile phone users in the inner city of Hanoi using various methods such as direct interviews, sending via email or using questionnaires designed on the Internet. At the end of the survey, after checking and eliminating erroneous questionnaires, the study collected 858 complete questionnaires, equivalent to a rate of about 78%. In addition, the research subjects of the thesis are only people who are using mobile phones, so people who do not use mobile phones are not within the scope of the thesis, therefore, the questionnaires with the option of not using mobile phones were excluded from the scope of analysis. The number of suitable survey questionnaires included in the statistical analysis was 835.
4.1 Demographic characteristics of the sample
The structure of the survey sample is divided and statistically analyzed according to criteria such as gender, age, occupation, education level and personal income. (Detailed statistical table in Appendix 6)
- Gender structure: Of the 835 completed questionnaires, 49.8% of respondents were male, equivalent to 416 people, and 50.2% were female, equivalent to 419 people. The survey results of the study are completely consistent with the gender ratio in the population structure of Vietnam in general and Hanoi in particular (Male/Female: 49/51).
- Age structure: 36.6% of respondents are <23 years old, equivalent to 306 people. People from 23-34 years old
accounting for the highest proportion: 44.8% equivalent to 374 people, people aged 35-45 and >45 are 70 and 85 people equivalent to 8.4% and 10.2% respectively. Looking at the results of this survey, we can see that the young people - youth account for a large proportion of the total number of people participating in the survey. Meanwhile, the middle-aged people including two age groups of 35 - 45 and >45 have a low rate of participation in the survey. This is completely consistent with the reality when Mobile Marketing is identified as a Marketing service aimed at young people (people under 35 years old).
- Structure by educational level: among 835 valid responses, 541 respondents had university degrees, accounting for the highest proportion of ~ 75%, 102 had secondary school degrees, ~ 13.1%, and 93 had post-graduate degrees, ~ 11.9%.
- Occupational structure: office workers and civil servants are the group with the highest rate of participation with 39.4%, followed by students with 36.6%. Self-employed people account for 12%, retired housewives are 7.8% and other occupational groups account for 4.2%. The survey results show that the student group has the same rate as the group aged <23 at 36.6%. This shows the accuracy of the survey data. In addition, the survey results distributed by occupational criteria have a rate almost similar to the sample division rate in chapter 3. Therefore, it can be concluded that the survey data is suitable for use in analysis activities.
- Income structure: the group with income from 3 to 5 million has the highest rate with 39% of the total number of respondents. This is consistent with the income structure of Hanoi people and corresponds to the average income of the group of civil servants and office workers. Those
People with no income account for 23%, income under 3 million VND accounts for 13% and income over 5 million VND accounts for 25%.
4.2 Mobile phone usage in Hanoi inner city area
According to the survey results, most respondents said they had used the phone for more than 1 year, specifically: 68.4% used mobile phones from 4 to 10 years, 23.2% used from 1 to 3 years, 7.8% used for more than 10 years. Those who used mobile phones for less than 1 year accounted for only a very small proportion of ~ 0.6%. (Table 4.1)
Table 4.1: Time spent using mobile phones
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Alid
<1 year
5
.6
.6
.6
1-3 years
194
23.2
23.2
23.8
4-10 years
571
68.4
68.4
92.2
>10 years
65
7.8
7.8
100.0
Total
835
100.0
100.0
The survey indexes on the time of using mobile phones of consumers in the inner city of Hanoi are very impressive for a developing country like Vietnam and also prove that Vietnamese consumers have a lot of experience using this high-tech device. Moreover, with the majority of consumers surveyed having a relatively long time of use (4-10 years), it partly proves that mobile phones have become an important and essential item in peoples daily lives.
When asked about the mobile phone network they are using, 31% of respondents said they are using the network of Vietel company, 29% use the network of
of Mobifone company, 27% use Vinaphone companys network and 13% use networks of other providers such as E-VN telecom, S-fone, Beeline, Vietnammobile. (Figure 4.1).
Figure 4.1: Mobile phone network in use
Compared with the announced market share of mobile telecommunications service providers in Vietnam (Vietel: 36%, Mobifone: 29%, Vinaphone: 28%, the remaining networks: 7%), we see that the survey results do not have many differences. However, the statistics show that there is a difference in the market share of other networks because the Hanoi market is one of the two main markets of small networks, so their market share in this area will certainly be higher than that of the whole country.
According to a report by NielsenMobile (2009) [8], the number of prepaid mobile phone subscribers in Hanoi accounts for 95% of the total number of subscribers, however, the results of this survey show that the percentage of prepaid subscribers has decreased by more than 20%, only at 70.8%. On the contrary, the number of postpaid subscribers tends to increase from 5% in 2009 to 19.2%. Those who are simultaneously using both types of subscriptions account for 10%. (Table 4.2).
Table 4.2: Types of mobile phone subscribers
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Prepay
591
70.8
70.8
70.8
Pay later
160
19.2
19.2
89.9
Both of the above
84
10.1
10.1
100.0
Total
835
100.0
100.0
The above figures show the change in the psychology and consumption habits of Vietnamese consumers towards mobile telecommunications services, when the use of prepaid subscriptions and junk SIMs is replaced by the use of two types of subscriptions for different purposes and needs or switching to postpaid subscriptions to enjoy better customer care services.
In addition, the majority of respondents have an average spending level for mobile phone services from 100 to 300 thousand VND (406 ~ 48.6% of total respondents). The high spending level (> 500 thousand VND) is the spending level with the lowest number of people with only 8.4%, on the contrary, the low spending level (under 100 thousand VND) accounts for the second highest proportion among the groups of respondents with 25.4%. People with low spending levels mainly fall into the group of students and retirees/housewives - those who have little need to use or mainly use promotional SIM cards. (Table 4.3).
Table 4.3: Spending on mobile phone charges
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<100,000
212
25.4
25.4
25.4
100-300,000
406
48.6
48.6
74.0
300,000-500,000
147
17.6
17.6
91.6
>500,000
70
8.4
8.4
100.0
Total
835
100.0
100.0
The statistics in Table 4.3 are similar to the percentages in the NielsenMobile survey results (2009) with 73% of mobile phone users having medium spending levels and only 13% having high spending levels.
The survey results also showed that up to 31% ~ nearly one-third of respondents said they sent more than 10 SMS messages/day, meaning that on average they sent 1 SMS message for every working hour. Those with an average SMS message volume (from 3 to 10 messages/day) accounted for 51.1% and those with a low SMS message volume (less than 3 messages/day) accounted for 17%. (Table 4.4)
Table 4.4: Number of SMS messages sent per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
142
17.0
17.0
17.0
3-10 news
427
51.1
51.1
68.1
>10 news
266
31.9
31.9
100.0
Total
835
100.0
100.0
Similar to sending messages, those with an average message receiving rate (from 3-10 messages/day) accounted for the highest percentage of ~ 55%, followed by those with a high number of messages (over 10 messages/day) ~ 24% and those with a low number of messages received daily (under 3 messages/day) remained at the bottom with 21%. (Table 4.5)
Table 4.5: Number of SMS messages received per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
175
21.0
21.0
21.0
3-10 news
436
55.0
55.0
76.0
>10 news
197
24.0
24.0
100.0
Total
835
100.0
100.0
When comparing the data of the two result tables 4.4 and 4.5, we can see the reasonableness between the ratio of the number of messages sent and the number of messages received daily by the interview participants.
4.3 Current status of SMS advertising and Mobile Marketing
According to the interview results, in the 3 months from the time of the survey and before, 94% of respondents, equivalent to 785 people, said they received advertising messages, while only a very small percentage of 6% (only 50 people) did not receive advertising messages (Table 4.6).
Table 4.6: Percentage of people receiving advertising messages in the last 3 months
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Have
785
94.0
94.0
94.0
Are not
50
6.0
6.0
100.0
Total
835
100.0
100.0
The results of Table 4.6 show that consumers in the inner city of Hanoi are very familiar with advertising messages. This result is also the basis for assessing the knowledge, experience and understanding of the respondents in the interview. This is also one of the important factors determining the accuracy of the survey results.
In addition, most respondents said they had received promotional messages, but only 24% of them had ever taken the action of registering to receive promotional messages, while 76% of the remaining respondents did not register to receive promotional messages but still received promotional messages every day. This is the first sign indicating the weaknesses and shortcomings of lax management of this activity in Vietnam. (Table 4.7)
div.maincontent .s1 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s2 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s4 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s5 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s15 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s16 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 5.5pt; vertical-align: 3pt; } div.maincontent .s17 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 8.5pt; } div.maincontent .s18 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s20 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s21 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s22 { color: black; font-family:Courier New, monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s23 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s24 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s25 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s26 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s27 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 1.5pt; } div.maincontent .s28 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s29 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s30 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s31 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s32 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s33 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s36 { color: #F00; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s37 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s38 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 8.5pt; vertical-align: 5pt; } div.maincontent .s39 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s40 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 4pt; } div.maincontent .s41 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s42 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s43 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7.5pt; vertical-align: 5pt; } div.maincontent .s44 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s45 { color: #F00; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s46 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s47 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s48 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s49 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s50 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s51 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s52 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s53 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s54 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s55 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s56 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s57 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s58 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s59 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s60 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 13pt; } div.maincontent .s61 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s62 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s63 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .content_head2 { color: #F00; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s64 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s67 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s68 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s69 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s70 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; tex](https://tailieuthamkhao.com/uploads/2022/12/03/cac-nhan-to-anh-huong-den-hanh-vi-nguoi-tieu-dung-doi-voi-hoat-dong-13-1-120x90.jpg) Mobile Phone Usage in Hanoi Inner City Area
zt2i3t4l5ee
zt2a3gsconsumer,consumption,consumer behavior,marketing,mobile marketing
zt2a3ge
zc2o3n4t5e6n7ts
- Test the relationship between demographic variables and consumer behavior for Mobile Marketing activities
The analysis method used is the Chi-square test (χ2), with statistical hypotheses H0 and H1 and significance level α = 0.05. In case the P index (p-value) or Sig. index in SPSS has a value less than or equal to the significance level α, the hypothesis H0 is rejected and vice versa. With this testing procedure, the study can evaluate the difference in behavioral trends between demographic groups.
CHAPTER 4
RESEARCH RESULTS
During two months, 1,100 survey questionnaires were distributed to mobile phone users in the inner city of Hanoi using various methods such as direct interviews, sending via email or using questionnaires designed on the Internet. At the end of the survey, after checking and eliminating erroneous questionnaires, the study collected 858 complete questionnaires, equivalent to a rate of about 78%. In addition, the research subjects of the thesis are only people who are using mobile phones, so people who do not use mobile phones are not within the scope of the thesis, therefore, the questionnaires with the option of not using mobile phones were excluded from the scope of analysis. The number of suitable survey questionnaires included in the statistical analysis was 835.
4.1 Demographic characteristics of the sample
The structure of the survey sample is divided and statistically analyzed according to criteria such as gender, age, occupation, education level and personal income. (Detailed statistical table in Appendix 6)
- Gender structure: Of the 835 completed questionnaires, 49.8% of respondents were male, equivalent to 416 people, and 50.2% were female, equivalent to 419 people. The survey results of the study are completely consistent with the gender ratio in the population structure of Vietnam in general and Hanoi in particular (Male/Female: 49/51).
- Age structure: 36.6% of respondents are <23 years old, equivalent to 306 people. People from 23-34 years old
accounting for the highest proportion: 44.8% equivalent to 374 people, people aged 35-45 and >45 are 70 and 85 people equivalent to 8.4% and 10.2% respectively. Looking at the results of this survey, we can see that the young people - youth account for a large proportion of the total number of people participating in the survey. Meanwhile, the middle-aged people including two age groups of 35 - 45 and >45 have a low rate of participation in the survey. This is completely consistent with the reality when Mobile Marketing is identified as a Marketing service aimed at young people (people under 35 years old).
- Structure by educational level: among 835 valid responses, 541 respondents had university degrees, accounting for the highest proportion of ~ 75%, 102 had secondary school degrees, ~ 13.1%, and 93 had post-graduate degrees, ~ 11.9%.
- Occupational structure: office workers and civil servants are the group with the highest rate of participation with 39.4%, followed by students with 36.6%. Self-employed people account for 12%, retired housewives are 7.8% and other occupational groups account for 4.2%. The survey results show that the student group has the same rate as the group aged <23 at 36.6%. This shows the accuracy of the survey data. In addition, the survey results distributed by occupational criteria have a rate almost similar to the sample division rate in chapter 3. Therefore, it can be concluded that the survey data is suitable for use in analysis activities.
- Income structure: the group with income from 3 to 5 million has the highest rate with 39% of the total number of respondents. This is consistent with the income structure of Hanoi people and corresponds to the average income of the group of civil servants and office workers. Those
People with no income account for 23%, income under 3 million VND accounts for 13% and income over 5 million VND accounts for 25%.
4.2 Mobile phone usage in Hanoi inner city area
According to the survey results, most respondents said they had used the phone for more than 1 year, specifically: 68.4% used mobile phones from 4 to 10 years, 23.2% used from 1 to 3 years, 7.8% used for more than 10 years. Those who used mobile phones for less than 1 year accounted for only a very small proportion of ~ 0.6%. (Table 4.1)
Table 4.1: Time spent using mobile phones
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Alid
<1 year
5
.6
.6
.6
1-3 years
194
23.2
23.2
23.8
4-10 years
571
68.4
68.4
92.2
>10 years
65
7.8
7.8
100.0
Total
835
100.0
100.0
The survey indexes on the time of using mobile phones of consumers in the inner city of Hanoi are very impressive for a developing country like Vietnam and also prove that Vietnamese consumers have a lot of experience using this high-tech device. Moreover, with the majority of consumers surveyed having a relatively long time of use (4-10 years), it partly proves that mobile phones have become an important and essential item in people's daily lives.
When asked about the mobile phone network they are using, 31% of respondents said they are using the network of Vietel company, 29% use the network of
of Mobifone company, 27% use Vinaphone company's network and 13% use networks of other providers such as E-VN telecom, S-fone, Beeline, Vietnammobile. (Figure 4.1).
Figure 4.1: Mobile phone network in use
Compared with the announced market share of mobile telecommunications service providers in Vietnam (Vietel: 36%, Mobifone: 29%, Vinaphone: 28%, the remaining networks: 7%), we see that the survey results do not have many differences. However, the statistics show that there is a difference in the market share of other networks because the Hanoi market is one of the two main markets of small networks, so their market share in this area will certainly be higher than that of the whole country.
According to a report by NielsenMobile (2009) [8], the number of prepaid mobile phone subscribers in Hanoi accounts for 95% of the total number of subscribers, however, the results of this survey show that the percentage of prepaid subscribers has decreased by more than 20%, only at 70.8%. On the contrary, the number of postpaid subscribers tends to increase from 5% in 2009 to 19.2%. Those who are simultaneously using both types of subscriptions account for 10%. (Table 4.2).
Table 4.2: Types of mobile phone subscribers
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Prepay
591
70.8
70.8
70.8
Pay later
160
19.2
19.2
89.9
Both of the above
84
10.1
10.1
100.0
Total
835
100.0
100.0
The above figures show the change in the psychology and consumption habits of Vietnamese consumers towards mobile telecommunications services, when the use of prepaid subscriptions and junk SIMs is replaced by the use of two types of subscriptions for different purposes and needs or switching to postpaid subscriptions to enjoy better customer care services.
In addition, the majority of respondents have an average spending level for mobile phone services from 100 to 300 thousand VND (406 ~ 48.6% of total respondents). The high spending level (> 500 thousand VND) is the spending level with the lowest number of people with only 8.4%, on the contrary, the low spending level (under 100 thousand VND) accounts for the second highest proportion among the groups of respondents with 25.4%. People with low spending levels mainly fall into the group of students and retirees/housewives - those who have little need to use or mainly use promotional SIM cards. (Table 4.3).
Table 4.3: Spending on mobile phone charges
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<100,000
212
25.4
25.4
25.4
100-300,000
406
48.6
48.6
74.0
300,000-500,000
147
17.6
17.6
91.6
>500,000
70
8.4
8.4
100.0
Total
835
100.0
100.0
The statistics in Table 4.3 are similar to the percentages in the NielsenMobile survey results (2009) with 73% of mobile phone users having medium spending levels and only 13% having high spending levels.
The survey results also showed that up to 31% ~ nearly one-third of respondents said they sent more than 10 SMS messages/day, meaning that on average they sent 1 SMS message for every working hour. Those with an average SMS message volume (from 3 to 10 messages/day) accounted for 51.1% and those with a low SMS message volume (less than 3 messages/day) accounted for 17%. (Table 4.4)
Table 4.4: Number of SMS messages sent per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
142
17.0
17.0
17.0
3-10 news
427
51.1
51.1
68.1
>10 news
266
31.9
31.9
100.0
Total
835
100.0
100.0
Similar to sending messages, those with an average message receiving rate (from 3-10 messages/day) accounted for the highest percentage of ~ 55%, followed by those with a high number of messages (over 10 messages/day) ~ 24% and those with a low number of messages received daily (under 3 messages/day) remained at the bottom with 21%. (Table 4.5)
Table 4.5: Number of SMS messages received per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
175
21.0
21.0
21.0
3-10 news
436
55.0
55.0
76.0
>10 news
197
24.0
24.0
100.0
Total
835
100.0
100.0
When comparing the data of the two result tables 4.4 and 4.5, we can see the reasonableness between the ratio of the number of messages sent and the number of messages received daily by the interview participants.
4.3 Current status of SMS advertising and Mobile Marketing
According to the interview results, in the 3 months from the time of the survey and before, 94% of respondents, equivalent to 785 people, said they received advertising messages, while only a very small percentage of 6% (only 50 people) did not receive advertising messages (Table 4.6).
Table 4.6: Percentage of people receiving advertising messages in the last 3 months
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Have
785
94.0
94.0
94.0
Are not
50
6.0
6.0
100.0
Total
835
100.0
100.0
The results of Table 4.6 show that consumers in the inner city of Hanoi are very familiar with advertising messages. This result is also the basis for assessing the knowledge, experience and understanding of the respondents in the interview. This is also one of the important factors determining the accuracy of the survey results.
In addition, most respondents said they had received promotional messages, but only 24% of them had ever taken the action of registering to receive promotional messages, while 76% of the remaining respondents did not register to receive promotional messages but still received promotional messages every day. This is the first sign indicating the weaknesses and shortcomings of lax management of this activity in Vietnam. (Table 4.7)
div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s15 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s16 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 5.5pt; vertical-align: 3pt; } div.maincontent .s17 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 8.5pt; } div.maincontent .s18 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s20 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s21 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s22 { color: black; font-family:"Courier New", monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s23 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s24 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s25 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s26 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s27 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 1.5pt; } div.maincontent .s28 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s29 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s30 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s31 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s32 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s33 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s36 { color: #F00; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s37 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s38 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 8.5pt; vertical-align: 5pt; } div.maincontent .s39 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s40 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 4pt; } div.maincontent .s41 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s42 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s43 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7.5pt; vertical-align: 5pt; } div.maincontent .s44 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s45 { color: #F00; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s46 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s47 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s48 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s49 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s50 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s51 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s52 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s53 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s54 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s55 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s56 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s57 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s58 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s59 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s60 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 13pt; } div.maincontent .s61 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s62 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s63 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .content_head2 { color: #F00; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s64 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s67 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s68 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s69 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s70 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; tex
Mobile Phone Usage in Hanoi Inner City Area
zt2i3t4l5ee
zt2a3gsconsumer,consumption,consumer behavior,marketing,mobile marketing
zt2a3ge
zc2o3n4t5e6n7ts
- Test the relationship between demographic variables and consumer behavior for Mobile Marketing activities
The analysis method used is the Chi-square test (χ2), with statistical hypotheses H0 and H1 and significance level α = 0.05. In case the P index (p-value) or Sig. index in SPSS has a value less than or equal to the significance level α, the hypothesis H0 is rejected and vice versa. With this testing procedure, the study can evaluate the difference in behavioral trends between demographic groups.
CHAPTER 4
RESEARCH RESULTS
During two months, 1,100 survey questionnaires were distributed to mobile phone users in the inner city of Hanoi using various methods such as direct interviews, sending via email or using questionnaires designed on the Internet. At the end of the survey, after checking and eliminating erroneous questionnaires, the study collected 858 complete questionnaires, equivalent to a rate of about 78%. In addition, the research subjects of the thesis are only people who are using mobile phones, so people who do not use mobile phones are not within the scope of the thesis, therefore, the questionnaires with the option of not using mobile phones were excluded from the scope of analysis. The number of suitable survey questionnaires included in the statistical analysis was 835.
4.1 Demographic characteristics of the sample
The structure of the survey sample is divided and statistically analyzed according to criteria such as gender, age, occupation, education level and personal income. (Detailed statistical table in Appendix 6)
- Gender structure: Of the 835 completed questionnaires, 49.8% of respondents were male, equivalent to 416 people, and 50.2% were female, equivalent to 419 people. The survey results of the study are completely consistent with the gender ratio in the population structure of Vietnam in general and Hanoi in particular (Male/Female: 49/51).
- Age structure: 36.6% of respondents are <23 years old, equivalent to 306 people. People from 23-34 years old
accounting for the highest proportion: 44.8% equivalent to 374 people, people aged 35-45 and >45 are 70 and 85 people equivalent to 8.4% and 10.2% respectively. Looking at the results of this survey, we can see that the young people - youth account for a large proportion of the total number of people participating in the survey. Meanwhile, the middle-aged people including two age groups of 35 - 45 and >45 have a low rate of participation in the survey. This is completely consistent with the reality when Mobile Marketing is identified as a Marketing service aimed at young people (people under 35 years old).
- Structure by educational level: among 835 valid responses, 541 respondents had university degrees, accounting for the highest proportion of ~ 75%, 102 had secondary school degrees, ~ 13.1%, and 93 had post-graduate degrees, ~ 11.9%.
- Occupational structure: office workers and civil servants are the group with the highest rate of participation with 39.4%, followed by students with 36.6%. Self-employed people account for 12%, retired housewives are 7.8% and other occupational groups account for 4.2%. The survey results show that the student group has the same rate as the group aged <23 at 36.6%. This shows the accuracy of the survey data. In addition, the survey results distributed by occupational criteria have a rate almost similar to the sample division rate in chapter 3. Therefore, it can be concluded that the survey data is suitable for use in analysis activities.
- Income structure: the group with income from 3 to 5 million has the highest rate with 39% of the total number of respondents. This is consistent with the income structure of Hanoi people and corresponds to the average income of the group of civil servants and office workers. Those
People with no income account for 23%, income under 3 million VND accounts for 13% and income over 5 million VND accounts for 25%.
4.2 Mobile phone usage in Hanoi inner city area
According to the survey results, most respondents said they had used the phone for more than 1 year, specifically: 68.4% used mobile phones from 4 to 10 years, 23.2% used from 1 to 3 years, 7.8% used for more than 10 years. Those who used mobile phones for less than 1 year accounted for only a very small proportion of ~ 0.6%. (Table 4.1)
Table 4.1: Time spent using mobile phones
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Alid
<1 year
5
.6
.6
.6
1-3 years
194
23.2
23.2
23.8
4-10 years
571
68.4
68.4
92.2
>10 years
65
7.8
7.8
100.0
Total
835
100.0
100.0
The survey indexes on the time of using mobile phones of consumers in the inner city of Hanoi are very impressive for a developing country like Vietnam and also prove that Vietnamese consumers have a lot of experience using this high-tech device. Moreover, with the majority of consumers surveyed having a relatively long time of use (4-10 years), it partly proves that mobile phones have become an important and essential item in people's daily lives.
When asked about the mobile phone network they are using, 31% of respondents said they are using the network of Vietel company, 29% use the network of
of Mobifone company, 27% use Vinaphone company's network and 13% use networks of other providers such as E-VN telecom, S-fone, Beeline, Vietnammobile. (Figure 4.1).
Figure 4.1: Mobile phone network in use
Compared with the announced market share of mobile telecommunications service providers in Vietnam (Vietel: 36%, Mobifone: 29%, Vinaphone: 28%, the remaining networks: 7%), we see that the survey results do not have many differences. However, the statistics show that there is a difference in the market share of other networks because the Hanoi market is one of the two main markets of small networks, so their market share in this area will certainly be higher than that of the whole country.
According to a report by NielsenMobile (2009) [8], the number of prepaid mobile phone subscribers in Hanoi accounts for 95% of the total number of subscribers, however, the results of this survey show that the percentage of prepaid subscribers has decreased by more than 20%, only at 70.8%. On the contrary, the number of postpaid subscribers tends to increase from 5% in 2009 to 19.2%. Those who are simultaneously using both types of subscriptions account for 10%. (Table 4.2).
Table 4.2: Types of mobile phone subscribers
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Prepay
591
70.8
70.8
70.8
Pay later
160
19.2
19.2
89.9
Both of the above
84
10.1
10.1
100.0
Total
835
100.0
100.0
The above figures show the change in the psychology and consumption habits of Vietnamese consumers towards mobile telecommunications services, when the use of prepaid subscriptions and junk SIMs is replaced by the use of two types of subscriptions for different purposes and needs or switching to postpaid subscriptions to enjoy better customer care services.
In addition, the majority of respondents have an average spending level for mobile phone services from 100 to 300 thousand VND (406 ~ 48.6% of total respondents). The high spending level (> 500 thousand VND) is the spending level with the lowest number of people with only 8.4%, on the contrary, the low spending level (under 100 thousand VND) accounts for the second highest proportion among the groups of respondents with 25.4%. People with low spending levels mainly fall into the group of students and retirees/housewives - those who have little need to use or mainly use promotional SIM cards. (Table 4.3).
Table 4.3: Spending on mobile phone charges
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<100,000
212
25.4
25.4
25.4
100-300,000
406
48.6
48.6
74.0
300,000-500,000
147
17.6
17.6
91.6
>500,000
70
8.4
8.4
100.0
Total
835
100.0
100.0
The statistics in Table 4.3 are similar to the percentages in the NielsenMobile survey results (2009) with 73% of mobile phone users having medium spending levels and only 13% having high spending levels.
The survey results also showed that up to 31% ~ nearly one-third of respondents said they sent more than 10 SMS messages/day, meaning that on average they sent 1 SMS message for every working hour. Those with an average SMS message volume (from 3 to 10 messages/day) accounted for 51.1% and those with a low SMS message volume (less than 3 messages/day) accounted for 17%. (Table 4.4)
Table 4.4: Number of SMS messages sent per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
142
17.0
17.0
17.0
3-10 news
427
51.1
51.1
68.1
>10 news
266
31.9
31.9
100.0
Total
835
100.0
100.0
Similar to sending messages, those with an average message receiving rate (from 3-10 messages/day) accounted for the highest percentage of ~ 55%, followed by those with a high number of messages (over 10 messages/day) ~ 24% and those with a low number of messages received daily (under 3 messages/day) remained at the bottom with 21%. (Table 4.5)
Table 4.5: Number of SMS messages received per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
175
21.0
21.0
21.0
3-10 news
436
55.0
55.0
76.0
>10 news
197
24.0
24.0
100.0
Total
835
100.0
100.0
When comparing the data of the two result tables 4.4 and 4.5, we can see the reasonableness between the ratio of the number of messages sent and the number of messages received daily by the interview participants.
4.3 Current status of SMS advertising and Mobile Marketing
According to the interview results, in the 3 months from the time of the survey and before, 94% of respondents, equivalent to 785 people, said they received advertising messages, while only a very small percentage of 6% (only 50 people) did not receive advertising messages (Table 4.6).
Table 4.6: Percentage of people receiving advertising messages in the last 3 months
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Have
785
94.0
94.0
94.0
Are not
50
6.0
6.0
100.0
Total
835
100.0
100.0
The results of Table 4.6 show that consumers in the inner city of Hanoi are very familiar with advertising messages. This result is also the basis for assessing the knowledge, experience and understanding of the respondents in the interview. This is also one of the important factors determining the accuracy of the survey results.
In addition, most respondents said they had received promotional messages, but only 24% of them had ever taken the action of registering to receive promotional messages, while 76% of the remaining respondents did not register to receive promotional messages but still received promotional messages every day. This is the first sign indicating the weaknesses and shortcomings of lax management of this activity in Vietnam. (Table 4.7)
div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s15 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s16 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 5.5pt; vertical-align: 3pt; } div.maincontent .s17 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 8.5pt; } div.maincontent .s18 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s20 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s21 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s22 { color: black; font-family:"Courier New", monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s23 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s24 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s25 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s26 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s27 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 1.5pt; } div.maincontent .s28 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s29 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s30 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s31 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s32 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s33 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s36 { color: #F00; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s37 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s38 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 8.5pt; vertical-align: 5pt; } div.maincontent .s39 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s40 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 4pt; } div.maincontent .s41 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s42 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s43 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7.5pt; vertical-align: 5pt; } div.maincontent .s44 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s45 { color: #F00; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s46 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s47 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s48 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s49 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s50 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s51 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s52 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s53 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s54 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s55 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s56 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s57 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s58 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s59 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s60 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 13pt; } div.maincontent .s61 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s62 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s63 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .content_head2 { color: #F00; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s64 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s67 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s68 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s69 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s70 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; tex -
![Qos Assurance Methods for Multimedia Communications
zt2i3t4l5ee
zt2a3gs
zt2a3ge
zc2o3n4t5e6n7ts
low. The EF PHB requires a sufficiently large number of output ports to provide low delay, low loss, and low jitter.
EF PHBs can be implemented if the output ports bandwidth is sufficiently large, combined with small buffer sizes and other network resources dedicated to EF packets, to allow the routers service rate for EF packets on an output port to exceed the arrival rate λ of packets at that port.
This means that packets with PHB EF are considered with a pre-allocated amount of output bandwidth and a priority that ensures minimum loss, minimum delay and minimum jitter before being put into operation.
PHB EF is suitable for channel simulation, leased line simulation, and real-time services such as voice, video without compromising on high loss, delay and jitter values.
Figure 2.10 Example of EF installation
Figure 2.10 shows an example of an EF PHB implementation. This is a simple priority queue scheduling technique. At the edges of the DS domain, EF packet traffic is prioritized according to the values agreed upon by the SLA. The EF queue in the figure needs to output packets at a rate higher than the packet arrival rate λ. To provide an EF PHB over an end-to-end DS domain, bandwidth at the output ports of the core routers needs to be allocated in advance to ensure the requirement μ > λ. This can be done by a pre-configured provisioning process. In the figure, EF packets are placed in the priority queue (the upper queue). With such a length, the queue can operate with μ > λ.
Since EF was primarily used for real-time services such as voice and video, and since real-time services use UDP instead of TCP, RED is generally
not suitable for EF queues because applications using UDP will not respond to random packet drop and RED will strip unnecessary packets.
2.2.4.2 Assured Forwarding (AF) PHB
PHB AF is defined by RFC 2597. The purpose of PHB AF is to deliver packets reliably and therefore delay and jitter are considered less important than packet loss. PHB AF is suitable for non-real-time services such as applications using TCP. PHB AF first defines four classes: AF1, AF2, AF3, AF4. For each of these AF classes, packets are then classified into three subclasses with three distinct priority levels.
Table 2.8 shows the four AF classes and 12 AF subclasses and the DSCP values for the 12 AF subclasses defined by RFC 2597. RFC 2597 also allows for more than three separate priority levels to be added for internal use. However, these separate priority levels will only have internal significance.
PHB Class
PHB Subclass
Package type
DSCP
AF4
AF41
Short
100010
AF42
Medium
100100
AF43
High
100110
AF3
AF31
Short
011010
AF32
Medium
011100
AF33
High
011110
AF2
AF21
Short
010010
AF22
Medium
010100
AF23
High
010110
AF1
AF11
Short
001010
AF12
Medium
001100
AF13
High
001110
Table 2.8 AF DSCPs
The AF PHB ensures that packets are forwarded with a high probability of delivery to the destination within the bounds of the rate agreed upon in an SLA. If AF traffic at an ingress port exceeds the pre-priority rate, which is considered non-compliant or “out of profile”, the excess packets will not be delivered to the destination with the same probability as the packets belonging to the defined traffic or “in profile” packets. When there is network congestion, the out of profile packets are dropped before the in profile packets are dropped.
When service levels are defined using AF classes, different quantity and quality between AF classes can be realized by allocating different amounts of bandwidth and buffer space to the four AF classes. Unlike
EF, most AF traffic is non-real-time traffic using TCP, and the RED queue management strategy is an AQM (Adaptive Queue Management) strategy suitable for use in AF PHBs. The four AF PHB layers can be implemented as four separate queues. The output port bandwidth is divided into four AF queues. For each AF queue, packets are marked with three “colors” corresponding to three separate priority levels.
In addition to the 32 DSCP 1 groups defined in Table 2.8, 21 DSCPs have been standardized as follows: one for PHB EF, 12 for PHB AF, and 8 for CSCP. There are 11 DSCP 1 groups still available for other standards.
2.2.5.Example of Differentiated Services
We will look at an example of the Differentiated Service model and mechanism of operation. The architecture of Differentiated Service consists of two basic sets of functions:
Edge functions: include packet classification and traffic conditioning. At the inbound edge of the network, incoming packets are marked. In particular, the DS field in the packet header is set to a certain value. For example, in Figure 2.12, packets sent from H1 to H3 are marked at R1, while packets from H2 to H4 are marked at R2. The labels on the received packets identify the service class to which they belong. Different traffic classes receive different services in the core network. The RFC definition uses the term behavior aggregate rather than the term traffic class. After being marked, a packet can be forwarded immediately into the network, delayed for a period of time before being forwarded, or dropped. We will see that there are many factors that affect how a packet is marked, and whether it is forwarded immediately, delayed, or dropped.
Figure 2.12 DiffServ Example
Core functionality: When a DS-marked packet arrives at a Diffservcapable router, the packet is forwarded to the next router based on
Per-hop behavior is associated with packet classes. Per-hop behavior affects router buffers and the bandwidth shared between competing classes. An important principle of the Differentiated Service architecture is that a routers per-hop behavior is based only on the packets marking or the class to which it belongs. Therefore, if packets sent from H1 to H3 as shown in the figure receive the same marking as packets from H2 to H4, then the network routers treat the packets exactly the same, regardless of whether the packet originated from H1 or H2. For example, R3 does not distinguish between packets from h1 and H2 when forwarding packets to R4. Therefore, the Differentiated Service architecture avoids the need to maintain router state about separate source-destination pairs, which is important for network scalability.
Chapter Conclusion
Chapter 2 has presented and clarified two main models of deploying and installing quality of service in IP networks. While the traditional best-effort model has many disadvantages, later models such as IntServ and DiffServ have partly solved the problems that best-effort could not solve. IntServ follows the direction of ensuring quality of service for each separate flow, it is built similar to the circuit switching model with the use of the RSVP resource reservation protocol. IntSer is suitable for services that require fixed bandwidth that is not shared such as VoIP services, multicast TV services. However, IntSer has disadvantages such as using a lot of network resources, low scalability and lack of flexibility. DiffServ was born with the idea of solving the disadvantages of the IntServ model.
DiffServ follows the direction of ensuring quality based on the principle of hop-by-hop behavior based on the priority of marked packets. The policy for different types of traffic is decided by the administrator and can be changed according to reality, so it is very flexible. DiffServ makes better use of network resources, avoiding idle bandwidth and processing capacity on routers. In addition, the DifServ model can be deployed on many independent domains, so the ability to expand the network becomes easy.
Chapter 3: METHODS TO ENSURE QoS FOR MULTIMEDIA COMMUNICATIONS
In packet-switched networks, different packet flows often have to share the transmission medium all the way to the destination station. To ensure the fair and efficient allocation of bandwidth to flows, appropriate serving mechanisms are required at network nodes, especially at gateways or routers, where many different data flows often pass through. The scheduler is responsible for serving packets of the selected flow and deciding which packet will be served next. Here, a flow is understood as a set of packets belonging to the same priority class, or originating from the same source, or having the same source and destination addresses, etc.
In normal state when there is no congestion, packets will be sent as soon as they are delivered. In case of congestion, if QoS assurance methods are not applied, prolonged congestion can cause packet drops, affecting service quality. In some cases, congestion is prolonged and widespread in the network, which can easily lead to the network being frozen, or many packets being dropped, seriously affecting service quality.
Therefore, in this chapter, in sections 3.2 and 3.3, we introduce some typical network traffic load monitoring techniques to predict and prevent congestion before it occurs through the measure of dropping (removing) packets early when there are signs of impending congestion.
3.1. DropTail method
DropTail is a simple, traditional queue management method based on FIFO mechanism. All incoming packets are placed in the queue, when the queue is full, the later packets are dropped.
Due to its simplicity and ease of implementation, DropTail has been used for many years on Internet router systems. However, this algorithm has the following disadvantages:
− Cannot avoid the phenomenon of “Lock out”: Occurs when 1 or several traffic streams monopolize the queue, making packets of other connections unable to pass through the router. This phenomenon greatly affects reliable transmission protocols such as TCP. According to the anti-congestion algorithm, when locked out, the TCP connection stream will reduce the window size and reduce the packet transmission speed exponentially.
− Can cause Global Synchronization: This is the result of a severe “Lock out” phenomenon. Some neighboring routers have their queues monopolized by a number of connections, causing a series of other TCP connections to be unable to pass through and simultaneously reducing the transmission speed. After those monopolized connections are temporarily suspended,
Once the queue is cleared, it takes a considerable amount of time for TCP connections to return to their original speed.
− Full Queue phenomenon: Data transmitted on the Internet often has an explosion, packets arriving at the router are often in clusters rather than in turn. Therefore, the operating mechanism of DropTail makes the queue easily full for a long period of time, leading to the average delay time of large packets. To avoid this phenomenon, with DropTail, the only way is to increase the routers buffer, this method is very expensive and ineffective.
− No QoS guarantee: With the DropTail mechanism, there is no way to prioritize important packets to be transmitted through the router earlier when all are in the queue. Meanwhile, with multimedia communication, ensuring connection and stable speed is extremely important and the DropTail algorithm cannot satisfy.
The problem of choosing the buffer size of the routers in the network is to “absorb” short bursts of traffic without causing too much queuing delay. This is necessary in bursty data transmission. The queue size determines the size of the packet bursts (traffic spikes) that we want to be able to transmit without being dropped at the routers.
In IP-based application networks, packet dropping is an important mechanism for indirectly reporting congestion to end stations. A solution that prevents router queues from filling up while reducing the packet drop rate is called dynamic queue management.
3.2. Random elimination method – RED
3.2.1 Overview
RED (Random Early Detection of congestion; Random Early Drop) is one of the first AQM algorithms proposed in 1993 by Sally Floyd and Van Jacobson, two scientists at the Lawrence Berkeley Laboratory of the University of California, USA. Due to its outstanding advantages compared to previous queue management algorithms, RED has been widely installed and deployed on the Internet.
The most fundamental point of their work is that the most effective place to detect congestion and react to it is at the gateway or router.
Source entities (senders) can also do this by estimating end-to-end delay, throughput variability, or the rate of packet retransmissions due to drop. However, the sender and receiver view of a particular connection cannot tell which gateways on the network are congested, and cannot distinguish between propagation delay and queuing delay. Only the gateway has a true view of the state of the queue, the link share of the connections passing through it at any given time, and the quality of service requirements of the
traffic flows. The RED gateway monitors the average queue length, which detects early signs of impending congestion (average queue length exceeding a predetermined threshold) and reacts appropriately in one of two ways:
− Drop incoming packets with a certain probability, to indirectly inform the source of congestion, the source needs to reduce the transmission rate to keep the queue from filling up, maintaining the ability to absorb incoming traffic spikes.
− Mark “congestion” with a certain probability in the ECN field in the header of TCP packets to notify the source (the receiving entity will copy this bit into the acknowledgement packet).
Figure 3. 1 RED algorithm
The main goal of RED is to avoid congestion by keeping the average queue size within a sufficiently small and stable region, which also means keeping the queuing delay sufficiently small and stable. Achieving this goal also helps: avoid global synchronization, not resist bursty traffic flows (i.e. flows with low average throughput but high volatility), and maintain an upper bound on the average queue size even in the absence of cooperation from transport layer protocols.
To achieve the above goals, RED gateways must do the following:
− The first is to detect congestion early and react appropriately to keep the average queue size small enough to keep the network operating in the low latency, high throughput region, while still allowing the queue size to fluctuate within a certain range to absorb short-term fluctuations. As discussed above, the gateway is the most appropriate place to detect congestion and is also the most appropriate place to decide which specific connection to report congestion to.
− The second thing is to notify the source of congestion. This is done by marking and notifying the source to reduce traffic. Normally the RED gateway will randomly drop packets. However, if congestion
If congestion is detected before the queue is full, it should be combined with packet marking to signal congestion. The RED gateway has two options: drop or mark; where marking is done by marking the ECN field of the packet with a certain probability, to signal the source to reduce the traffic entering the network.
− An important goal that RED gateways need to achieve is to avoid global synchronization and not to resist traffic flows that have a sudden characteristic. Global synchronization occurs when all connections simultaneously reduce their transmission window size, leading to a severe drop in throughput at the same time. On the other hand, Drop Tail or Random Drop strategies are very sensitive to sudden flows; that is, the gateway queue will often overflow when packets from these flows arrive. To avoid these two phenomena, gateways can use special algorithms to detect congestion and decide which connections will be notified of congestion at the gateway. The RED gateway randomly selects incoming packets to mark; with this method, the probability of marking a packet from a particular connection is proportional to the connections shared bandwidth at the gateway.
− Another goal is to control the average queue size even without cooperation from the source entities. This can be done by dropping packets when the average size exceeds an upper threshold (instead of marking it). This approach is necessary in cases where most connections have transmission times that are less than the round-trip time, or where the source entities are not able to reduce traffic in response to marking or dropping packets (such as UDP flows).
3.2.2 Algorithm
This section describes the algorithm for RED gateways. RED gateways calculate the average queue size using a low-pass filter. This average queue size is compared with two thresholds: minth and maxth. When the average queue size is less than the lower threshold, no incoming packets are marked or dropped; when the average queue size is greater than the upper threshold, all incoming packets are dropped. When the average queue size is between minth and maxth, each incoming packet is marked or dropped with a probability pa, where pa is a function of the average queue size avg; the probability of marking or dropping a packet for a particular connection is proportional to the bandwidth share of that connection at the gateway. The general algorithm for a RED gateway is described as follows: [5]
For each packet arrival
Caculate the average queue size avg If minth ≤ avg < maxth
div.maincontent .s1 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 15pt; }
div.maincontent .s2 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent .s3 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s4 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s5 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s6 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s7 { color: black; font-family:Wingdings; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s8 { color: black; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .s9 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s10 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 6pt; }
div.maincontent .s11 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s12 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; }
div.maincontent .s13 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-d](https://tailieuthamkhao.com/uploads/2022/05/15/danh-gia-hieu-qua-dam-bao-qos-cho-truyen-thong-da-phuong-tien-cua-chien-6-1-120x90.jpg) Qos Assurance Methods for Multimedia Communications
zt2i3t4l5ee
zt2a3gs
zt2a3ge
zc2o3n4t5e6n7ts
low. The EF PHB requires a sufficiently large number of output ports to provide low delay, low loss, and low jitter.
EF PHBs can be implemented if the output port's bandwidth is sufficiently large, combined with small buffer sizes and other network resources dedicated to EF packets, to allow the router's service rate for EF packets on an output port to exceed the arrival rate λ of packets at that port.
This means that packets with PHB EF are considered with a pre-allocated amount of output bandwidth and a priority that ensures minimum loss, minimum delay and minimum jitter before being put into operation.
PHB EF is suitable for channel simulation, leased line simulation, and real-time services such as voice, video without compromising on high loss, delay and jitter values.
Figure 2.10 Example of EF installation
Figure 2.10 shows an example of an EF PHB implementation. This is a simple priority queue scheduling technique. At the edges of the DS domain, EF packet traffic is prioritized according to the values agreed upon by the SLA. The EF queue in the figure needs to output packets at a rate higher than the packet arrival rate λ. To provide an EF PHB over an end-to-end DS domain, bandwidth at the output ports of the core routers needs to be allocated in advance to ensure the requirement μ > λ. This can be done by a pre-configured provisioning process. In the figure, EF packets are placed in the priority queue (the upper queue). With such a length, the queue can operate with μ > λ.
Since EF was primarily used for real-time services such as voice and video, and since real-time services use UDP instead of TCP, RED is generally
not suitable for EF queues because applications using UDP will not respond to random packet drop and RED will strip unnecessary packets.
2.2.4.2 Assured Forwarding (AF) PHB
PHB AF is defined by RFC 2597. The purpose of PHB AF is to deliver packets reliably and therefore delay and jitter are considered less important than packet loss. PHB AF is suitable for non-real-time services such as applications using TCP. PHB AF first defines four classes: AF1, AF2, AF3, AF4. For each of these AF classes, packets are then classified into three subclasses with three distinct priority levels.
Table 2.8 shows the four AF classes and 12 AF subclasses and the DSCP values for the 12 AF subclasses defined by RFC 2597. RFC 2597 also allows for more than three separate priority levels to be added for internal use. However, these separate priority levels will only have internal significance.
PHB Class
PHB Subclass
Package type
DSCP
AF4
AF41
Short
100010
AF42
Medium
100100
AF43
High
100110
AF3
AF31
Short
011010
AF32
Medium
011100
AF33
High
011110
AF2
AF21
Short
010010
AF22
Medium
010100
AF23
High
010110
AF1
AF11
Short
001010
AF12
Medium
001100
AF13
High
001110
Table 2.8 AF DSCPs
The AF PHB ensures that packets are forwarded with a high probability of delivery to the destination within the bounds of the rate agreed upon in an SLA. If AF traffic at an ingress port exceeds the pre-priority rate, which is considered non-compliant or “out of profile”, the excess packets will not be delivered to the destination with the same probability as the packets belonging to the defined traffic or “in profile” packets. When there is network congestion, the out of profile packets are dropped before the in profile packets are dropped.
When service levels are defined using AF classes, different quantity and quality between AF classes can be realized by allocating different amounts of bandwidth and buffer space to the four AF classes. Unlike
EF, most AF traffic is non-real-time traffic using TCP, and the RED queue management strategy is an AQM (Adaptive Queue Management) strategy suitable for use in AF PHBs. The four AF PHB layers can be implemented as four separate queues. The output port bandwidth is divided into four AF queues. For each AF queue, packets are marked with three “colors” corresponding to three separate priority levels.
In addition to the 32 DSCP 1 groups defined in Table 2.8, 21 DSCPs have been standardized as follows: one for PHB EF, 12 for PHB AF, and 8 for CSCP. There are 11 DSCP 1 groups still available for other standards.
2.2.5.Example of Differentiated Services
We will look at an example of the Differentiated Service model and mechanism of operation. The architecture of Differentiated Service consists of two basic sets of functions:
Edge functions: include packet classification and traffic conditioning. At the inbound edge of the network, incoming packets are marked. In particular, the DS field in the packet header is set to a certain value. For example, in Figure 2.12, packets sent from H1 to H3 are marked at R1, while packets from H2 to H4 are marked at R2. The labels on the received packets identify the service class to which they belong. Different traffic classes receive different services in the core network. The RFC definition uses the term behavior aggregate rather than the term traffic class. After being marked, a packet can be forwarded immediately into the network, delayed for a period of time before being forwarded, or dropped. We will see that there are many factors that affect how a packet is marked, and whether it is forwarded immediately, delayed, or dropped.
Figure 2.12 DiffServ Example
Core functionality: When a DS-marked packet arrives at a Diffservcapable router, the packet is forwarded to the next router based on
Per-hop behavior is associated with packet classes. Per-hop behavior affects router buffers and the bandwidth shared between competing classes. An important principle of the Differentiated Service architecture is that a router's per-hop behavior is based only on the packet's marking or the class to which it belongs. Therefore, if packets sent from H1 to H3 as shown in the figure receive the same marking as packets from H2 to H4, then the network routers treat the packets exactly the same, regardless of whether the packet originated from H1 or H2. For example, R3 does not distinguish between packets from h1 and H2 when forwarding packets to R4. Therefore, the Differentiated Service architecture avoids the need to maintain router state about separate source-destination pairs, which is important for network scalability.
Chapter Conclusion
Chapter 2 has presented and clarified two main models of deploying and installing quality of service in IP networks. While the traditional best-effort model has many disadvantages, later models such as IntServ and DiffServ have partly solved the problems that best-effort could not solve. IntServ follows the direction of ensuring quality of service for each separate flow, it is built similar to the circuit switching model with the use of the RSVP resource reservation protocol. IntSer is suitable for services that require fixed bandwidth that is not shared such as VoIP services, multicast TV services. However, IntSer has disadvantages such as using a lot of network resources, low scalability and lack of flexibility. DiffServ was born with the idea of solving the disadvantages of the IntServ model.
DiffServ follows the direction of ensuring quality based on the principle of hop-by-hop behavior based on the priority of marked packets. The policy for different types of traffic is decided by the administrator and can be changed according to reality, so it is very flexible. DiffServ makes better use of network resources, avoiding idle bandwidth and processing capacity on routers. In addition, the DifServ model can be deployed on many independent domains, so the ability to expand the network becomes easy.
Chapter 3: METHODS TO ENSURE QoS FOR MULTIMEDIA COMMUNICATIONS
In packet-switched networks, different packet flows often have to share the transmission medium all the way to the destination station. To ensure the fair and efficient allocation of bandwidth to flows, appropriate serving mechanisms are required at network nodes, especially at gateways or routers, where many different data flows often pass through. The scheduler is responsible for serving packets of the selected flow and deciding which packet will be served next. Here, a flow is understood as a set of packets belonging to the same priority class, or originating from the same source, or having the same source and destination addresses, etc.
In normal state when there is no congestion, packets will be sent as soon as they are delivered. In case of congestion, if QoS assurance methods are not applied, prolonged congestion can cause packet drops, affecting service quality. In some cases, congestion is prolonged and widespread in the network, which can easily lead to the network being "frozen", or many packets being dropped, seriously affecting service quality.
Therefore, in this chapter, in sections 3.2 and 3.3, we introduce some typical network traffic load monitoring techniques to predict and prevent congestion before it occurs through the measure of dropping (removing) packets early when there are signs of impending congestion.
3.1. DropTail method
DropTail is a simple, traditional queue management method based on FIFO mechanism. All incoming packets are placed in the queue, when the queue is full, the later packets are dropped.
Due to its simplicity and ease of implementation, DropTail has been used for many years on Internet router systems. However, this algorithm has the following disadvantages:
− Cannot avoid the phenomenon of “Lock out”: Occurs when 1 or several traffic streams monopolize the queue, making packets of other connections unable to pass through the router. This phenomenon greatly affects reliable transmission protocols such as TCP. According to the anti-congestion algorithm, when locked out, the TCP connection stream will reduce the window size and reduce the packet transmission speed exponentially.
− Can cause Global Synchronization: This is the result of a severe “Lock out” phenomenon. Some neighboring routers have their queues monopolized by a number of connections, causing a series of other TCP connections to be unable to pass through and simultaneously reducing the transmission speed. After those monopolized connections are temporarily suspended,
Once the queue is cleared, it takes a considerable amount of time for TCP connections to return to their original speed.
− Full Queue phenomenon: Data transmitted on the Internet often has an explosion, packets arriving at the router are often in clusters rather than in turn. Therefore, the operating mechanism of DropTail makes the queue easily full for a long period of time, leading to the average delay time of large packets. To avoid this phenomenon, with DropTail, the only way is to increase the router's buffer, this method is very expensive and ineffective.
− No QoS guarantee: With the DropTail mechanism, there is no way to prioritize important packets to be transmitted through the router earlier when all are in the queue. Meanwhile, with multimedia communication, ensuring connection and stable speed is extremely important and the DropTail algorithm cannot satisfy.
The problem of choosing the buffer size of the routers in the network is to “absorb” short bursts of traffic without causing too much queuing delay. This is necessary in bursty data transmission. The queue size determines the size of the packet bursts (traffic spikes) that we want to be able to transmit without being dropped at the routers.
In IP-based application networks, packet dropping is an important mechanism for indirectly reporting congestion to end stations. A solution that prevents router queues from filling up while reducing the packet drop rate is called dynamic queue management.
3.2. Random elimination method – RED
3.2.1 Overview
RED (Random Early Detection of congestion; Random Early Drop) is one of the first AQM algorithms proposed in 1993 by Sally Floyd and Van Jacobson, two scientists at the Lawrence Berkeley Laboratory of the University of California, USA. Due to its outstanding advantages compared to previous queue management algorithms, RED has been widely installed and deployed on the Internet.
The most fundamental point of their work is that the most effective place to detect congestion and react to it is at the gateway or router.
Source entities (senders) can also do this by estimating end-to-end delay, throughput variability, or the rate of packet retransmissions due to drop. However, the sender and receiver view of a particular connection cannot tell which gateways on the network are congested, and cannot distinguish between propagation delay and queuing delay. Only the gateway has a true view of the state of the queue, the link share of the connections passing through it at any given time, and the quality of service requirements of the
traffic flows. The RED gateway monitors the average queue length, which detects early signs of impending congestion (average queue length exceeding a predetermined threshold) and reacts appropriately in one of two ways:
− Drop incoming packets with a certain probability, to indirectly inform the source of congestion, the source needs to reduce the transmission rate to keep the queue from filling up, maintaining the ability to absorb incoming traffic spikes.
− Mark “congestion” with a certain probability in the ECN field in the header of TCP packets to notify the source (the receiving entity will copy this bit into the acknowledgement packet).
Figure 3. 1 RED algorithm
The main goal of RED is to avoid congestion by keeping the average queue size within a sufficiently small and stable region, which also means keeping the queuing delay sufficiently small and stable. Achieving this goal also helps: avoid global synchronization, not resist bursty traffic flows (i.e. flows with low average throughput but high volatility), and maintain an upper bound on the average queue size even in the absence of cooperation from transport layer protocols.
To achieve the above goals, RED gateways must do the following:
− The first is to detect congestion early and react appropriately to keep the average queue size small enough to keep the network operating in the low latency, high throughput region, while still allowing the queue size to fluctuate within a certain range to absorb short-term fluctuations. As discussed above, the gateway is the most appropriate place to detect congestion and is also the most appropriate place to decide which specific connection to report congestion to.
− The second thing is to notify the source of congestion. This is done by marking and notifying the source to reduce traffic. Normally the RED gateway will randomly drop packets. However, if congestion
If congestion is detected before the queue is full, it should be combined with packet marking to signal congestion. The RED gateway has two options: drop or mark; where marking is done by marking the ECN field of the packet with a certain probability, to signal the source to reduce the traffic entering the network.
− An important goal that RED gateways need to achieve is to avoid global synchronization and not to resist traffic flows that have a sudden characteristic. Global synchronization occurs when all connections simultaneously reduce their transmission window size, leading to a severe drop in throughput at the same time. On the other hand, Drop Tail or Random Drop strategies are very sensitive to sudden flows; that is, the gateway queue will often overflow when packets from these flows arrive. To avoid these two phenomena, gateways can use special algorithms to detect congestion and decide which connections will be notified of congestion at the gateway. The RED gateway randomly selects incoming packets to mark; with this method, the probability of marking a packet from a particular connection is proportional to the connection's shared bandwidth at the gateway.
− Another goal is to control the average queue size even without cooperation from the source entities. This can be done by dropping packets when the average size exceeds an upper threshold (instead of marking it). This approach is necessary in cases where most connections have transmission times that are less than the round-trip time, or where the source entities are not able to reduce traffic in response to marking or dropping packets (such as UDP flows).
3.2.2 Algorithm
This section describes the algorithm for RED gateways. RED gateways calculate the average queue size using a low-pass filter. This average queue size is compared with two thresholds: minth and maxth. When the average queue size is less than the lower threshold, no incoming packets are marked or dropped; when the average queue size is greater than the upper threshold, all incoming packets are dropped. When the average queue size is between minth and maxth, each incoming packet is marked or dropped with a probability pa, where pa is a function of the average queue size avg; the probability of marking or dropping a packet for a particular connection is proportional to the bandwidth share of that connection at the gateway. The general algorithm for a RED gateway is described as follows: [5]
For each packet arrival
Caculate the average queue size avg If minth ≤ avg < maxth
div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 15pt; }
div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s7 { color: black; font-family:Wingdings; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s8 { color: black; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .s9 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s10 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 6pt; }
div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s12 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; }
div.maincontent .s13 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-d
Qos Assurance Methods for Multimedia Communications
zt2i3t4l5ee
zt2a3gs
zt2a3ge
zc2o3n4t5e6n7ts
low. The EF PHB requires a sufficiently large number of output ports to provide low delay, low loss, and low jitter.
EF PHBs can be implemented if the output port's bandwidth is sufficiently large, combined with small buffer sizes and other network resources dedicated to EF packets, to allow the router's service rate for EF packets on an output port to exceed the arrival rate λ of packets at that port.
This means that packets with PHB EF are considered with a pre-allocated amount of output bandwidth and a priority that ensures minimum loss, minimum delay and minimum jitter before being put into operation.
PHB EF is suitable for channel simulation, leased line simulation, and real-time services such as voice, video without compromising on high loss, delay and jitter values.
Figure 2.10 Example of EF installation
Figure 2.10 shows an example of an EF PHB implementation. This is a simple priority queue scheduling technique. At the edges of the DS domain, EF packet traffic is prioritized according to the values agreed upon by the SLA. The EF queue in the figure needs to output packets at a rate higher than the packet arrival rate λ. To provide an EF PHB over an end-to-end DS domain, bandwidth at the output ports of the core routers needs to be allocated in advance to ensure the requirement μ > λ. This can be done by a pre-configured provisioning process. In the figure, EF packets are placed in the priority queue (the upper queue). With such a length, the queue can operate with μ > λ.
Since EF was primarily used for real-time services such as voice and video, and since real-time services use UDP instead of TCP, RED is generally
not suitable for EF queues because applications using UDP will not respond to random packet drop and RED will strip unnecessary packets.
2.2.4.2 Assured Forwarding (AF) PHB
PHB AF is defined by RFC 2597. The purpose of PHB AF is to deliver packets reliably and therefore delay and jitter are considered less important than packet loss. PHB AF is suitable for non-real-time services such as applications using TCP. PHB AF first defines four classes: AF1, AF2, AF3, AF4. For each of these AF classes, packets are then classified into three subclasses with three distinct priority levels.
Table 2.8 shows the four AF classes and 12 AF subclasses and the DSCP values for the 12 AF subclasses defined by RFC 2597. RFC 2597 also allows for more than three separate priority levels to be added for internal use. However, these separate priority levels will only have internal significance.
PHB Class
PHB Subclass
Package type
DSCP
AF4
AF41
Short
100010
AF42
Medium
100100
AF43
High
100110
AF3
AF31
Short
011010
AF32
Medium
011100
AF33
High
011110
AF2
AF21
Short
010010
AF22
Medium
010100
AF23
High
010110
AF1
AF11
Short
001010
AF12
Medium
001100
AF13
High
001110
Table 2.8 AF DSCPs
The AF PHB ensures that packets are forwarded with a high probability of delivery to the destination within the bounds of the rate agreed upon in an SLA. If AF traffic at an ingress port exceeds the pre-priority rate, which is considered non-compliant or “out of profile”, the excess packets will not be delivered to the destination with the same probability as the packets belonging to the defined traffic or “in profile” packets. When there is network congestion, the out of profile packets are dropped before the in profile packets are dropped.
When service levels are defined using AF classes, different quantity and quality between AF classes can be realized by allocating different amounts of bandwidth and buffer space to the four AF classes. Unlike
EF, most AF traffic is non-real-time traffic using TCP, and the RED queue management strategy is an AQM (Adaptive Queue Management) strategy suitable for use in AF PHBs. The four AF PHB layers can be implemented as four separate queues. The output port bandwidth is divided into four AF queues. For each AF queue, packets are marked with three “colors” corresponding to three separate priority levels.
In addition to the 32 DSCP 1 groups defined in Table 2.8, 21 DSCPs have been standardized as follows: one for PHB EF, 12 for PHB AF, and 8 for CSCP. There are 11 DSCP 1 groups still available for other standards.
2.2.5.Example of Differentiated Services
We will look at an example of the Differentiated Service model and mechanism of operation. The architecture of Differentiated Service consists of two basic sets of functions:
Edge functions: include packet classification and traffic conditioning. At the inbound edge of the network, incoming packets are marked. In particular, the DS field in the packet header is set to a certain value. For example, in Figure 2.12, packets sent from H1 to H3 are marked at R1, while packets from H2 to H4 are marked at R2. The labels on the received packets identify the service class to which they belong. Different traffic classes receive different services in the core network. The RFC definition uses the term behavior aggregate rather than the term traffic class. After being marked, a packet can be forwarded immediately into the network, delayed for a period of time before being forwarded, or dropped. We will see that there are many factors that affect how a packet is marked, and whether it is forwarded immediately, delayed, or dropped.
Figure 2.12 DiffServ Example
Core functionality: When a DS-marked packet arrives at a Diffservcapable router, the packet is forwarded to the next router based on
Per-hop behavior is associated with packet classes. Per-hop behavior affects router buffers and the bandwidth shared between competing classes. An important principle of the Differentiated Service architecture is that a router's per-hop behavior is based only on the packet's marking or the class to which it belongs. Therefore, if packets sent from H1 to H3 as shown in the figure receive the same marking as packets from H2 to H4, then the network routers treat the packets exactly the same, regardless of whether the packet originated from H1 or H2. For example, R3 does not distinguish between packets from h1 and H2 when forwarding packets to R4. Therefore, the Differentiated Service architecture avoids the need to maintain router state about separate source-destination pairs, which is important for network scalability.
Chapter Conclusion
Chapter 2 has presented and clarified two main models of deploying and installing quality of service in IP networks. While the traditional best-effort model has many disadvantages, later models such as IntServ and DiffServ have partly solved the problems that best-effort could not solve. IntServ follows the direction of ensuring quality of service for each separate flow, it is built similar to the circuit switching model with the use of the RSVP resource reservation protocol. IntSer is suitable for services that require fixed bandwidth that is not shared such as VoIP services, multicast TV services. However, IntSer has disadvantages such as using a lot of network resources, low scalability and lack of flexibility. DiffServ was born with the idea of solving the disadvantages of the IntServ model.
DiffServ follows the direction of ensuring quality based on the principle of hop-by-hop behavior based on the priority of marked packets. The policy for different types of traffic is decided by the administrator and can be changed according to reality, so it is very flexible. DiffServ makes better use of network resources, avoiding idle bandwidth and processing capacity on routers. In addition, the DifServ model can be deployed on many independent domains, so the ability to expand the network becomes easy.
Chapter 3: METHODS TO ENSURE QoS FOR MULTIMEDIA COMMUNICATIONS
In packet-switched networks, different packet flows often have to share the transmission medium all the way to the destination station. To ensure the fair and efficient allocation of bandwidth to flows, appropriate serving mechanisms are required at network nodes, especially at gateways or routers, where many different data flows often pass through. The scheduler is responsible for serving packets of the selected flow and deciding which packet will be served next. Here, a flow is understood as a set of packets belonging to the same priority class, or originating from the same source, or having the same source and destination addresses, etc.
In normal state when there is no congestion, packets will be sent as soon as they are delivered. In case of congestion, if QoS assurance methods are not applied, prolonged congestion can cause packet drops, affecting service quality. In some cases, congestion is prolonged and widespread in the network, which can easily lead to the network being "frozen", or many packets being dropped, seriously affecting service quality.
Therefore, in this chapter, in sections 3.2 and 3.3, we introduce some typical network traffic load monitoring techniques to predict and prevent congestion before it occurs through the measure of dropping (removing) packets early when there are signs of impending congestion.
3.1. DropTail method
DropTail is a simple, traditional queue management method based on FIFO mechanism. All incoming packets are placed in the queue, when the queue is full, the later packets are dropped.
Due to its simplicity and ease of implementation, DropTail has been used for many years on Internet router systems. However, this algorithm has the following disadvantages:
− Cannot avoid the phenomenon of “Lock out”: Occurs when 1 or several traffic streams monopolize the queue, making packets of other connections unable to pass through the router. This phenomenon greatly affects reliable transmission protocols such as TCP. According to the anti-congestion algorithm, when locked out, the TCP connection stream will reduce the window size and reduce the packet transmission speed exponentially.
− Can cause Global Synchronization: This is the result of a severe “Lock out” phenomenon. Some neighboring routers have their queues monopolized by a number of connections, causing a series of other TCP connections to be unable to pass through and simultaneously reducing the transmission speed. After those monopolized connections are temporarily suspended,
Once the queue is cleared, it takes a considerable amount of time for TCP connections to return to their original speed.
− Full Queue phenomenon: Data transmitted on the Internet often has an explosion, packets arriving at the router are often in clusters rather than in turn. Therefore, the operating mechanism of DropTail makes the queue easily full for a long period of time, leading to the average delay time of large packets. To avoid this phenomenon, with DropTail, the only way is to increase the router's buffer, this method is very expensive and ineffective.
− No QoS guarantee: With the DropTail mechanism, there is no way to prioritize important packets to be transmitted through the router earlier when all are in the queue. Meanwhile, with multimedia communication, ensuring connection and stable speed is extremely important and the DropTail algorithm cannot satisfy.
The problem of choosing the buffer size of the routers in the network is to “absorb” short bursts of traffic without causing too much queuing delay. This is necessary in bursty data transmission. The queue size determines the size of the packet bursts (traffic spikes) that we want to be able to transmit without being dropped at the routers.
In IP-based application networks, packet dropping is an important mechanism for indirectly reporting congestion to end stations. A solution that prevents router queues from filling up while reducing the packet drop rate is called dynamic queue management.
3.2. Random elimination method – RED
3.2.1 Overview
RED (Random Early Detection of congestion; Random Early Drop) is one of the first AQM algorithms proposed in 1993 by Sally Floyd and Van Jacobson, two scientists at the Lawrence Berkeley Laboratory of the University of California, USA. Due to its outstanding advantages compared to previous queue management algorithms, RED has been widely installed and deployed on the Internet.
The most fundamental point of their work is that the most effective place to detect congestion and react to it is at the gateway or router.
Source entities (senders) can also do this by estimating end-to-end delay, throughput variability, or the rate of packet retransmissions due to drop. However, the sender and receiver view of a particular connection cannot tell which gateways on the network are congested, and cannot distinguish between propagation delay and queuing delay. Only the gateway has a true view of the state of the queue, the link share of the connections passing through it at any given time, and the quality of service requirements of the
traffic flows. The RED gateway monitors the average queue length, which detects early signs of impending congestion (average queue length exceeding a predetermined threshold) and reacts appropriately in one of two ways:
− Drop incoming packets with a certain probability, to indirectly inform the source of congestion, the source needs to reduce the transmission rate to keep the queue from filling up, maintaining the ability to absorb incoming traffic spikes.
− Mark “congestion” with a certain probability in the ECN field in the header of TCP packets to notify the source (the receiving entity will copy this bit into the acknowledgement packet).
Figure 3. 1 RED algorithm
The main goal of RED is to avoid congestion by keeping the average queue size within a sufficiently small and stable region, which also means keeping the queuing delay sufficiently small and stable. Achieving this goal also helps: avoid global synchronization, not resist bursty traffic flows (i.e. flows with low average throughput but high volatility), and maintain an upper bound on the average queue size even in the absence of cooperation from transport layer protocols.
To achieve the above goals, RED gateways must do the following:
− The first is to detect congestion early and react appropriately to keep the average queue size small enough to keep the network operating in the low latency, high throughput region, while still allowing the queue size to fluctuate within a certain range to absorb short-term fluctuations. As discussed above, the gateway is the most appropriate place to detect congestion and is also the most appropriate place to decide which specific connection to report congestion to.
− The second thing is to notify the source of congestion. This is done by marking and notifying the source to reduce traffic. Normally the RED gateway will randomly drop packets. However, if congestion
If congestion is detected before the queue is full, it should be combined with packet marking to signal congestion. The RED gateway has two options: drop or mark; where marking is done by marking the ECN field of the packet with a certain probability, to signal the source to reduce the traffic entering the network.
− An important goal that RED gateways need to achieve is to avoid global synchronization and not to resist traffic flows that have a sudden characteristic. Global synchronization occurs when all connections simultaneously reduce their transmission window size, leading to a severe drop in throughput at the same time. On the other hand, Drop Tail or Random Drop strategies are very sensitive to sudden flows; that is, the gateway queue will often overflow when packets from these flows arrive. To avoid these two phenomena, gateways can use special algorithms to detect congestion and decide which connections will be notified of congestion at the gateway. The RED gateway randomly selects incoming packets to mark; with this method, the probability of marking a packet from a particular connection is proportional to the connection's shared bandwidth at the gateway.
− Another goal is to control the average queue size even without cooperation from the source entities. This can be done by dropping packets when the average size exceeds an upper threshold (instead of marking it). This approach is necessary in cases where most connections have transmission times that are less than the round-trip time, or where the source entities are not able to reduce traffic in response to marking or dropping packets (such as UDP flows).
3.2.2 Algorithm
This section describes the algorithm for RED gateways. RED gateways calculate the average queue size using a low-pass filter. This average queue size is compared with two thresholds: minth and maxth. When the average queue size is less than the lower threshold, no incoming packets are marked or dropped; when the average queue size is greater than the upper threshold, all incoming packets are dropped. When the average queue size is between minth and maxth, each incoming packet is marked or dropped with a probability pa, where pa is a function of the average queue size avg; the probability of marking or dropping a packet for a particular connection is proportional to the bandwidth share of that connection at the gateway. The general algorithm for a RED gateway is described as follows: [5]
For each packet arrival
Caculate the average queue size avg If minth ≤ avg < maxth
div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 15pt; }
div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s7 { color: black; font-family:Wingdings; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s8 { color: black; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .s9 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s10 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 6pt; }
div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s12 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; }
div.maincontent .s13 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-d -
 Identify Rating Levels and Rating Scales
zt2i3t4l5ee
zt2a3gstourism,quan lan,quang ninh,ecology,ecotourism,minh chau,van don,geography,geographical basis,tourism development,science
zt2a3ge
zc2o3n4t5e6n7ts
of the islanders. Therefore, this indicator will be divided into two sub-indicators:
a1. Natural tourism attractiveness a2. Cultural tourism attractiveness
b. Tourist capacity
The two island communes in Quan Lan have different capacities to receive tourists. Minh Chau Commune is home to many standard hotels and resorts, attracting high-income domestic and international tourists. Meanwhile, Quan Lan Commune has many motels mainly built and operated by local people, so the scale and quality are not high, and will be suitable for ordinary tourists such as students.
c. Time of exploitation of Quan Lan Island Commune:
Quan Lan tourism is seasonal due to weather and climate conditions and festivals only take place on certain days of the year, specifically in spring. In Quan Lan commune, the period from April to June and from September to November is considered the best time to visit Quan Lan because the cultural tourism activities are mainly associated with festivals taking place during this time.
Minh Chau island commune:
Tourism exploitation time is all year round, because this is a place with a number of tourist attractions with diverse ecosystems such as Bai Tu Long National Park Research Center, Tram forest, Turtle Laying Beach, so besides coming to the beach for tourism and vacation in the summer, Minh Chau will attract research groups to come for tourism combined with research at other times of the year.
d. Sustainability
The sustainability of ecotourism sites in Quan Lan and Minh Chau communes depends on the sensitivity of the ecosystems to climate changes.
landscape. In general, these tourist destinations have a fairly high level of sustainability, because they are natural ecosystems, planned and protected. However, if a large number of tourists gather at certain times, it can exceed the carrying capacity and affect the sustainability of the environment (polluted beaches, damaged trees, animals moving away from their habitats, etc.), then the sustainability of the above ecosystems (natural ecosystems, human ecosystems) will also be affected and become less sustainable.
e. Location and accessibility
Both island communes have ports to take tourists to visit from Van Don wharf:
- Quan Lan – Van Don traffic route:
Phuc Thinh – Viet Anh high-speed boat and Quang Minh high-speed boat, depart at 8am and 2pm from Van Don to Quan Lan, and at 7am and 1pm from Quan Lan to Van Don. There are also wooden boats departing at 7am and 1pm.
- Van Don - Minh Chau traffic route:
Chung Huong high-speed train, Minh Chau train, morning 7:30 and afternoon 13:30 from Van Don to Minh Chau, morning 6:30 and afternoon 13:00 from Minh Chau to Van Don.
f. Infrastructure
Despite receiving investment attention, the issue of infrastructure and technical facilities for tourism on Quan Lan Island is still an issue that needs to be resolved because it has a direct impact on the implementation of ecotourism activities. The minimum conditions for serving tourists such as accommodation, electricity, water, communication, especially medical services, and security work need to be given top priority. Ecotourism spots in Minh Chau commune are assessed to have better infrastructure and technical facilities for tourism because there are quite complete and synchronous conditions for serving tourists, meeting many needs of domestic and foreign tourists.
3.2.1.4. Determine assessment levels and assessment scales
Corresponding to the levels of each criterion, the index is the score of those levels in the order of 4, 3, 2, 1 decreasing according to the standard of each level: very attractive (4), attractive (3), average (2), less attractive (1).
3.2.1.5. Determining the coefficients of the criteria
For the assessment of DLST in the two communes of Quan Lan and Minh Chau islands, the students added evaluation coefficients to show the importance of the criteria and indicators as follows:
Coefficient 3 with criteria: Attractiveness, Exploitation time. These are the 2 most important criteria for attracting tourists to tourism in general and eco-tourism in particular, so they have the highest coefficient.
Coefficient 2 with criteria: Capacity, Infrastructure, Location and accessibility . Because the assessment area is an island commune of Van Don district, the above criteria are selected by the author with appropriate coefficients at the average level.
Coefficient 1 with criteria: Sustainability. Quan Lan has natural and human-made ecotourism sites, with high biodiversity and little impact from local human factors. Most of the ecotourism sites are still wild, so they are highly sustainable.
3.2.1.6. Results of DLST assessment on Quan Lan island
a. Assessment of the potential for natural tourism development
For Minh Chau commune:
+ Natural tourism attractiveness is determined to be very attractive (4 points) and the most important coefficient (coefficient 3), so the score of the Attractiveness criterion is 4 x 3 = 12.
+ Capacity is determined as average (2 points) and the coefficient is quite important (coefficient 2), then the score of Capacity criterion is 2 x 2 = 4.
+ Exploitation time is long (4 points), the most important coefficient (coefficient 3) so the score of the Exploitation time criterion is 4 x 3 = 12.
+ Sustainability is determined as sustainable (4 points), the important coefficient is the average coefficient (coefficient 1), so the score of the Sustainability criterion is 4 x 1 = 4 points
+ Location and accessibility are determined to be quite favorable (2 points), the coefficient is quite important (coefficient 2), the criterion score is 2 x 2 = 4 points.
+ Infrastructure is assessed as good (3 points), the coefficient is quite important (coefficient 2), then the score of the Infrastructure criterion is 3 x 2 = 6 points.
The total score for evaluating DLST in Minh Chau commune according to 6 evaluation criteria is determined as: 12 + 4 + 12 + 4 + 4 + 6 = 42 points
Similar assessment for Quan Lan commune, we have the following table:
Table 3.3: Assessment of the potential for natural ecotourism development in Quan Lan and Minh Chau communes
Attractiveness of self-tourismof course
Capacity
Mining time
Sustainability
Location and accessibility
Infrastructure
Result
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
CommuneMinh Chau
12
12
4
8
12
12
4
4
4
8
6
8
42/52
Quan CommuneLan
6
12
6
8
9
12
4
4
4
8
4
8
33/52
b. Assessment of the potential for humanistic tourism development
For Quan Lan commune:
+ The attractiveness of human tourism is determined to be very attractive (4 points) and the most important coefficient (coefficient 3), so the score of the Attractiveness criterion is 4 x 3 = 12.
+ Capacity is determined to be large (3 points) and the coefficient is quite important (coefficient 2), then the score of the Capacity criterion is 3 x 2 = 6.
+ Mining time is average (3 points), the most important coefficient (coefficient 3) so the score of the Mining time criterion is 3 x 3 = 9.
+ Sustainability is determined as sustainable (4 points), the important coefficient is the average coefficient (coefficient 1), so the score of the Sustainability criterion is 4 x 1 = 4 points.
+ Location and accessibility are determined to be quite favorable (2 points), the coefficient is quite important (coefficient 2), the criterion score is 2 x 2 = 4 points.
+ Infrastructure is rated as average (2 points), the coefficient is quite important (coefficient 2), then the score of the Infrastructure criterion is 2 x 2 = 4 points.
The total score for evaluating DLST in Quan Lan commune according to 6 evaluation criteria is determined as: 12 + 6 + 6 + 4 + 4 + 4 = 36 points.
Similar assessment with Minh Chau commune we have the following table:
Table 3.4: Assessment of the potential for developing humanistic eco-tourism in Quan Lan and Minh Chau communes
Attractiveness of human tourismliterature
Capacity
Mining time
Sustainability
Location and accessibility
Infrastructure
Result
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Quan CommuneLan
12
12
6
8
9
12
4
4
4
8
4
8
39/52
Minh CommuneChau
6
12
4
8
12
12
4
4
4
8
6
8
36/52
Basically, both Minh Chau and Quan Lan localities have quite favorable conditions for developing ecotourism. However, Quan Lan commune has more advantages to develop ecotourism in a humanistic direction, because this is an area with many famous historical relics such as Quan Lan Communal House, Quan Lan Pagoda, Temple worshiping the hero Tran Khanh Du, ... along with local festivals held annually such as the wind praying ceremony (March 15), Quan Lan festival (June 10-19); due to its location near the port and long exploitation time, the beaches in Quan Lan commune (especially Quan Lan beach) are no longer hygienic and clean to ensure the needs of tourists coming to relax and swim; this is also an area with many beautiful landscapes such as Got Beo wind pass, Ong Phong head, Voi Voi cave, but the ability to access these places is still very limited (dirt hill road, lots of gravel and rocks), especially during rainy and windy times; In addition, other natural resources such as mangrove forests and sea worms have not been really exploited for tourism purposes and ecotourism development. On the contrary, Minh Chau commune has more advantages in developing ecotourism in the direction of natural tourism, this is an area with diverse ecosystems such as at Rua De Beach, Bai Tu Long National Park Conservation Center...; Minh Chau beach is highly appreciated for its natural beauty and cleanliness, ranked in the top ten most beautiful beaches in Vietnam; Minh Chau commune is also home to Tram forest with a large area and a purity of up to 90%, suitable for building bridges through the forest (a very effective type of natural ecotourism currently applied by many countries) for tourists to sightsee, as well as for the purpose of studying and researching.
Figure 3.1: Thenmala Forest Bridge (India) Source: https://www.thenmalaecotourism.com/(August 21, 2019)
3.2.2. Using SWOT matrix to evaluate Quan Lan island tourism
General assessment of current tourism activities of Quan Lan island is shown through the following SWOT matrix:
Table 3.5: SWOT matrix evaluating tourism activities on Quan Lan island
Internal agent
Strengths- There is a lot of potential for tourism development, especially natural ecotourism and humanistic ecotourism.- The unskilled labor force is relatively abundant.- resource environmentunpolluted, still
Weaknesses- Poorly developed infrastructure, especially traffic routes to tourist destinations on the island.- The team of professional staff is still weak.- Tourism products in general
quite wild, originalintact
general and DLST in particularalone is monotonous.
External agents
Opportunity- Tourism is a key industry in the socio-economic development strategy of the province and Van Don economic zone.- Quan Lan was selected as a pilot area for eco-tourism development within the framework of the green growth project between Quang Ninh province and the Japanese organization JICA.- The flow of tourists and especially ecotourism in the world tends toincreasing
Challenge- Weather and climate change abnormally.- Competition in tourism products is increasingly fierce, especially with other localities in the province such as Ha Long, Mong Cai...- Awareness of tourists, especially domestic tourists, about ecotourism and nature conservation is not high.
Through summary analysis using SWOT matrix we see that:
To exploit strengths and take advantage of opportunities, it is necessary to:
- Diversify products and service types (build more tourism routes aimed at specific needs of tourists: experiential tourism immersed in nature, spiritual cultural tourism...)
- Effective exploitation of resources and differentiated products (natural resources and human resources)
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s3 { color: #0D0D0D; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; vertical-align: -3pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; vertical-align: -2pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; vertical-align: -1pt; } div.maincontent .s9 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Symbol, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:Wingdings; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 5pt; } div.maincontent .s15 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 5pt; } div.maincontent .s16 { color: black; font-family:Cambria, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s17 { color: #080808; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s18 { color: #080808; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s20 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; } div.maincontent .s21 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s22 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s23 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s24 { color: #212121; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; tex
Identify Rating Levels and Rating Scales
zt2i3t4l5ee
zt2a3gstourism,quan lan,quang ninh,ecology,ecotourism,minh chau,van don,geography,geographical basis,tourism development,science
zt2a3ge
zc2o3n4t5e6n7ts
of the islanders. Therefore, this indicator will be divided into two sub-indicators:
a1. Natural tourism attractiveness a2. Cultural tourism attractiveness
b. Tourist capacity
The two island communes in Quan Lan have different capacities to receive tourists. Minh Chau Commune is home to many standard hotels and resorts, attracting high-income domestic and international tourists. Meanwhile, Quan Lan Commune has many motels mainly built and operated by local people, so the scale and quality are not high, and will be suitable for ordinary tourists such as students.
c. Time of exploitation of Quan Lan Island Commune:
Quan Lan tourism is seasonal due to weather and climate conditions and festivals only take place on certain days of the year, specifically in spring. In Quan Lan commune, the period from April to June and from September to November is considered the best time to visit Quan Lan because the cultural tourism activities are mainly associated with festivals taking place during this time.
Minh Chau island commune:
Tourism exploitation time is all year round, because this is a place with a number of tourist attractions with diverse ecosystems such as Bai Tu Long National Park Research Center, Tram forest, Turtle Laying Beach, so besides coming to the beach for tourism and vacation in the summer, Minh Chau will attract research groups to come for tourism combined with research at other times of the year.
d. Sustainability
The sustainability of ecotourism sites in Quan Lan and Minh Chau communes depends on the sensitivity of the ecosystems to climate changes.
landscape. In general, these tourist destinations have a fairly high level of sustainability, because they are natural ecosystems, planned and protected. However, if a large number of tourists gather at certain times, it can exceed the carrying capacity and affect the sustainability of the environment (polluted beaches, damaged trees, animals moving away from their habitats, etc.), then the sustainability of the above ecosystems (natural ecosystems, human ecosystems) will also be affected and become less sustainable.
e. Location and accessibility
Both island communes have ports to take tourists to visit from Van Don wharf:
- Quan Lan – Van Don traffic route:
Phuc Thinh – Viet Anh high-speed boat and Quang Minh high-speed boat, depart at 8am and 2pm from Van Don to Quan Lan, and at 7am and 1pm from Quan Lan to Van Don. There are also wooden boats departing at 7am and 1pm.
- Van Don - Minh Chau traffic route:
Chung Huong high-speed train, Minh Chau train, morning 7:30 and afternoon 13:30 from Van Don to Minh Chau, morning 6:30 and afternoon 13:00 from Minh Chau to Van Don.
f. Infrastructure
Despite receiving investment attention, the issue of infrastructure and technical facilities for tourism on Quan Lan Island is still an issue that needs to be resolved because it has a direct impact on the implementation of ecotourism activities. The minimum conditions for serving tourists such as accommodation, electricity, water, communication, especially medical services, and security work need to be given top priority. Ecotourism spots in Minh Chau commune are assessed to have better infrastructure and technical facilities for tourism because there are quite complete and synchronous conditions for serving tourists, meeting many needs of domestic and foreign tourists.
3.2.1.4. Determine assessment levels and assessment scales
Corresponding to the levels of each criterion, the index is the score of those levels in the order of 4, 3, 2, 1 decreasing according to the standard of each level: very attractive (4), attractive (3), average (2), less attractive (1).
3.2.1.5. Determining the coefficients of the criteria
For the assessment of DLST in the two communes of Quan Lan and Minh Chau islands, the students added evaluation coefficients to show the importance of the criteria and indicators as follows:
Coefficient 3 with criteria: Attractiveness, Exploitation time. These are the 2 most important criteria for attracting tourists to tourism in general and eco-tourism in particular, so they have the highest coefficient.
Coefficient 2 with criteria: Capacity, Infrastructure, Location and accessibility . Because the assessment area is an island commune of Van Don district, the above criteria are selected by the author with appropriate coefficients at the average level.
Coefficient 1 with criteria: Sustainability. Quan Lan has natural and human-made ecotourism sites, with high biodiversity and little impact from local human factors. Most of the ecotourism sites are still wild, so they are highly sustainable.
3.2.1.6. Results of DLST assessment on Quan Lan island
a. Assessment of the potential for natural tourism development
For Minh Chau commune:
+ Natural tourism attractiveness is determined to be very attractive (4 points) and the most important coefficient (coefficient 3), so the score of the Attractiveness criterion is 4 x 3 = 12.
+ Capacity is determined as average (2 points) and the coefficient is quite important (coefficient 2), then the score of Capacity criterion is 2 x 2 = 4.
+ Exploitation time is long (4 points), the most important coefficient (coefficient 3) so the score of the Exploitation time criterion is 4 x 3 = 12.
+ Sustainability is determined as sustainable (4 points), the important coefficient is the average coefficient (coefficient 1), so the score of the Sustainability criterion is 4 x 1 = 4 points
+ Location and accessibility are determined to be quite favorable (2 points), the coefficient is quite important (coefficient 2), the criterion score is 2 x 2 = 4 points.
+ Infrastructure is assessed as good (3 points), the coefficient is quite important (coefficient 2), then the score of the Infrastructure criterion is 3 x 2 = 6 points.
The total score for evaluating DLST in Minh Chau commune according to 6 evaluation criteria is determined as: 12 + 4 + 12 + 4 + 4 + 6 = 42 points
Similar assessment for Quan Lan commune, we have the following table:
Table 3.3: Assessment of the potential for natural ecotourism development in Quan Lan and Minh Chau communes
Attractiveness of self-tourismof course
Capacity
Mining time
Sustainability
Location and accessibility
Infrastructure
Result
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
CommuneMinh Chau
12
12
4
8
12
12
4
4
4
8
6
8
42/52
Quan CommuneLan
6
12
6
8
9
12
4
4
4
8
4
8
33/52
b. Assessment of the potential for humanistic tourism development
For Quan Lan commune:
+ The attractiveness of human tourism is determined to be very attractive (4 points) and the most important coefficient (coefficient 3), so the score of the Attractiveness criterion is 4 x 3 = 12.
+ Capacity is determined to be large (3 points) and the coefficient is quite important (coefficient 2), then the score of the Capacity criterion is 3 x 2 = 6.
+ Mining time is average (3 points), the most important coefficient (coefficient 3) so the score of the Mining time criterion is 3 x 3 = 9.
+ Sustainability is determined as sustainable (4 points), the important coefficient is the average coefficient (coefficient 1), so the score of the Sustainability criterion is 4 x 1 = 4 points.
+ Location and accessibility are determined to be quite favorable (2 points), the coefficient is quite important (coefficient 2), the criterion score is 2 x 2 = 4 points.
+ Infrastructure is rated as average (2 points), the coefficient is quite important (coefficient 2), then the score of the Infrastructure criterion is 2 x 2 = 4 points.
The total score for evaluating DLST in Quan Lan commune according to 6 evaluation criteria is determined as: 12 + 6 + 6 + 4 + 4 + 4 = 36 points.
Similar assessment with Minh Chau commune we have the following table:
Table 3.4: Assessment of the potential for developing humanistic eco-tourism in Quan Lan and Minh Chau communes
Attractiveness of human tourismliterature
Capacity
Mining time
Sustainability
Location and accessibility
Infrastructure
Result
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Point
DarkMulti
Quan CommuneLan
12
12
6
8
9
12
4
4
4
8
4
8
39/52
Minh CommuneChau
6
12
4
8
12
12
4
4
4
8
6
8
36/52
Basically, both Minh Chau and Quan Lan localities have quite favorable conditions for developing ecotourism. However, Quan Lan commune has more advantages to develop ecotourism in a humanistic direction, because this is an area with many famous historical relics such as Quan Lan Communal House, Quan Lan Pagoda, Temple worshiping the hero Tran Khanh Du, ... along with local festivals held annually such as the wind praying ceremony (March 15), Quan Lan festival (June 10-19); due to its location near the port and long exploitation time, the beaches in Quan Lan commune (especially Quan Lan beach) are no longer hygienic and clean to ensure the needs of tourists coming to relax and swim; this is also an area with many beautiful landscapes such as Got Beo wind pass, Ong Phong head, Voi Voi cave, but the ability to access these places is still very limited (dirt hill road, lots of gravel and rocks), especially during rainy and windy times; In addition, other natural resources such as mangrove forests and sea worms have not been really exploited for tourism purposes and ecotourism development. On the contrary, Minh Chau commune has more advantages in developing ecotourism in the direction of natural tourism, this is an area with diverse ecosystems such as at Rua De Beach, Bai Tu Long National Park Conservation Center...; Minh Chau beach is highly appreciated for its natural beauty and cleanliness, ranked in the top ten most beautiful beaches in Vietnam; Minh Chau commune is also home to Tram forest with a large area and a purity of up to 90%, suitable for building bridges through the forest (a very effective type of natural ecotourism currently applied by many countries) for tourists to sightsee, as well as for the purpose of studying and researching.
Figure 3.1: Thenmala Forest Bridge (India) Source: https://www.thenmalaecotourism.com/(August 21, 2019)
3.2.2. Using SWOT matrix to evaluate Quan Lan island tourism
General assessment of current tourism activities of Quan Lan island is shown through the following SWOT matrix:
Table 3.5: SWOT matrix evaluating tourism activities on Quan Lan island
Internal agent
Strengths- There is a lot of potential for tourism development, especially natural ecotourism and humanistic ecotourism.- The unskilled labor force is relatively abundant.- resource environmentunpolluted, still
Weaknesses- Poorly developed infrastructure, especially traffic routes to tourist destinations on the island.- The team of professional staff is still weak.- Tourism products in general
quite wild, originalintact
general and DLST in particularalone is monotonous.
External agents
Opportunity- Tourism is a key industry in the socio-economic development strategy of the province and Van Don economic zone.- Quan Lan was selected as a pilot area for eco-tourism development within the framework of the green growth project between Quang Ninh province and the Japanese organization JICA.- The flow of tourists and especially ecotourism in the world tends toincreasing
Challenge- Weather and climate change abnormally.- Competition in tourism products is increasingly fierce, especially with other localities in the province such as Ha Long, Mong Cai...- Awareness of tourists, especially domestic tourists, about ecotourism and nature conservation is not high.
Through summary analysis using SWOT matrix we see that:
To exploit strengths and take advantage of opportunities, it is necessary to:
- Diversify products and service types (build more tourism routes aimed at specific needs of tourists: experiential tourism immersed in nature, spiritual cultural tourism...)
- Effective exploitation of resources and differentiated products (natural resources and human resources)
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s3 { color: #0D0D0D; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; vertical-align: -3pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; vertical-align: -2pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; vertical-align: -1pt; } div.maincontent .s9 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Symbol, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:Wingdings; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 5pt; } div.maincontent .s15 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 5pt; } div.maincontent .s16 { color: black; font-family:Cambria, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s17 { color: #080808; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s18 { color: #080808; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s20 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; } div.maincontent .s21 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s22 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s23 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s24 { color: #212121; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; tex -
 Descriptive Statistics of Observed Variables Tangible Media Factor
Descriptive Statistics of Observed Variables Tangible Media Factor
(Source: Author's synthesis)
4.4 Multiple regression analysis
4.4.1 Test the correlation between independent variables and dependent variables
Before regression analysis, we need to consider the correlation between the independent variable and the dependent variable (using Pearson correlation). If any independent variable has a strong correlation with the dependent variable, meaning Sig. (2-tailed) < 0.05, it will be included in the regression because it is statistically significant, but any variable with Sig. (2-tailed) > 0.05 will not.
entered into the regression because it was not statistically significant. The results of the Pearson correlation test between the independent and dependent variables are shown in Appendix 12.
Table 4.7: Correlation results between independent variables and dependent variables
Factor
N | Student satisfaction with training service quality create | ||
Academic | Correlate Pearson | 208 | 0.742 ** |
Sig. (2-tailed) | 0.000 | ||
Non-academic | Correlate Pearson | 208 | 0.735 ** |
Sig. (2-tailed) | 0.000 | ||
Reputation | Correlate Pearson | 208 | 0.496 ** |
Sig. (2-tailed) | 0.000 | ||
Approach | Correlate Pearson | 208 | 0.523 ** |
Sig. (2-tailed) | 0.000 | ||
Training program | Correlate Pearson | 208 | 0.698 ** |
Sig. (2-tailed) | 0.000 |
(Source: Author processed data using SPSS software)
From the above results, we can see that the dependent variable has a linear correlation with 5 independent variables at the significance level of 0.000 < 0.05 and the correlation coefficient between the dependent variable "Satisfaction" and the independent variable "Academic" is 0.742; the correlation coefficient between the dependent variable and the independent variable "Non-academic" is 0.735; the correlation coefficient between the dependent variable and the independent variable "Reputation" is 0.496; the correlation coefficient between the dependent variable and the independent variable "Access" is 0.523; the correlation coefficient between the variable
dependent variable with the independent variable “Training Program” is 0.698. Thus, these factors are used to enter into linear regression analysis in the next section.
4.4.2 Linear regression analysis
Table 4.8: Results of the first regression coefficient
Model
Regression coefficient not standardized | Regression coefficient standardized | t (t-Test) | Significance level Sig. | |||
B | Error standard | Beta | ||||
1 | Constant | -0.162 | 0.172 | -0.944 | 0.346 | |
Academic | 0.357 | 0.038 | 0.390 | 9,304 | 0.000 | |
Non-academic | 0.310 | 0.039 | 0.343 | 7,920 | 0.000 | |
Reputation | 0.064 | 0.040 | 0.067 | 1,593 | 0.113 | |
Approach | 0.071 | 0.047 | 0.063 | 1,492 | 0.137 | |
Programme train | 0.233 | 0.046 | 0.239 | 5,048 | 0.000 | |
(Source: The author processed data using SPSS software) The first regression analysis results showed that the correlation coefficient value was 0.880 > 0.5; the coefficient of determination R 2 adjusted = 0.769 at the significance level of 0.000 < 0.05, so the adjusted R 2 is statistically significant or in other words, the 5 independent variables included in the regression model affected 76.9% of the change in the dependent variable, the remaining 23.1% was due to variables outside the model and random errors. In addition, the Durbin-Watson index = 1.940 is within the allowable range from 1 to 3, so there is no autocorrelation phenomenon. However, looking at Table 4.8 to examine the reliability of the independent variables in the model, we see that there are 2 independent variables, "Reputation" and "Approach", with Sig. (significance level) are 0.113 and 0.137 > 0.05 (5% confidence level), respectively. Therefore, these two independent variables will be eliminated in the next regression analysis, but the independent variable with the larger value will be eliminated first. Therefore, in this case, the variable "Approach" will be eliminated first and the author will analyze the regression model for the second time. After eliminating the variable "approach" to analyze the regression model for the next time, the result
The results show that all parameters such as VIF, Tolorence, t stat and Sig. are satisfied (Appendix 12). The results of linear regression analysis are shown as follows:
Table 4.9: Results of the second regression coefficient
Model
Unstandardized regression coefficients | Standardized regression coefficient | t (t-Test) | Significance level Sig. | |||
B | Standard error | Beta | ||||
1 | Constant | -0.47 | 0.154 | -0.308 | 0.758 | |
Academic | 0.368 | 0.038 | 0.402 | 9,725 | 0.000 | |
Non-academic | 0.310 | 0.039 | 0.343 | 7,885 | 0.000 | |
Reputation | 0.081 | 0.038 | 0.085 | 2,115 | 0.036 | |
Programme train | 0.252 | 0.045 | 0.258 | 5,646 | 0.000 | |
(Source: Author processed data using SPSS software)
Table 4.10: Model synthesis coefficients
Tissue
image
R | R 2 | R 2 effect adjust | Standard error of estimate | Durbin- Watson | |
1 | 0.879 | 0.773 | 0.768 | 0.30021 | 1,935 |
(Source: Author processed data using SPSS software)
The results show that the correlation coefficient value is 0.879 > 0.5; this is a suitable model to use to evaluate the relationship between the dependent variable and the independent variables. In addition, the adjusted coefficient of determination R2 value is 0.768, which means that the constructed linear regression model fits the data 76.8%. In other words, 76.8% of the satisfaction with the training quality of students of the Faculty of Tourism, HUFI is explained by the independent variables of this regression model, the rest is due to errors and other factors. This difference can also be explained by the fact that the research model does not focus on the values and personal characteristics of students such as psychology, personality, etc. Therefore, the observed variable values in the study can only explain 76.8% of the satisfaction with the training quality of students of the Faculty of Tourism, HUFI. And this is also one of the limitations of the topic and will be developed in future studies.
Table 4.11: Testing the suitability of the overall linear regression model
ANOVA a
Model | Total average direction | Df | Mean square jar | F | Sig. | |
1 | Regression | 62,130 | 4 | 15,533 | 172,346 | 0.000 b |
Balance | 18,295 | 203 | 0.090 | |||
Total | 80,425 | 207 | ||||
(Source: Author processed data using SPSS software)
The nature of the population is very large, so it is very time-consuming and costly to collect the population, so the author chooses the sample size in the population to infer the population. Therefore, when performing the test in Table 4.11, the author wants his sample size to meet the criteria to be able to infer the research population. The F test is used to evaluate the suitability of this linear regression model to generalize and apply to the population or not? Specifically in this case, the Sig. value of the F test is 0.000 < 0.05, so the linear regression model built is suitable for the population. Thus, finally in the analysis of the linear regression model, we have the following table of results:
Table 4.12: Regression coefficient results and multicollinearity statistics
Model
Unstandardized coefficient | Coefficient standardize | t | Significance level Sig. | Multicollinearity statistics | ||||
B | Error standard | Beta | Tolerance | VIF | ||||
1 | Constant | -0.047 | 0.154 | -0.308 | 0.758 | |||
Academic | 0.368 | 0.038 | 0.402 | 9,725 | 0.000 | 0.656 | 1,525 | |
Non-academic | 0.310 | 0.039 | 0.343 | 7,885 | 0.000 | 0.594 | 1,685 | |
Reputation | 0.081 | 0.038 | 0.085 | 2,115 | 0.036 | 0.696 | 1,437 | |
Programme train | 0.252 | 0.045 | 0.258 | 5,646 | 0.000 | 0.535 | 1,868 | |
(Source: Author processed data using SPSS software)
Based on the results of Table 4.12, the author finds that firstly, the Sig. value of the t-test for each independent variable is less than 0.05, which means that the independent variables included in the model are all significant. Second, the standardized regression coefficient, the factors that have
The standardized regression weights have positive signs, meaning that these independent variables have a positive impact on the dependent variable. Finally, all VIF coefficients are < 2, so there is no multicollinearity (Nguyen Dinh Tho, 2011).
From the above results, the standardized linear regression equation is constructed as follows:
Satisfaction with training services of students of Faculty of Tourism, HUFI = 0.402*Academic + 0.343*Non-academic + 0.085*Reputation + 0.258* Training program.
Through the standardized multivariate regression equation above, we can see that there are 4 factors including Academic, Non-academic, Reputation and Training Program that all have a proportional impact on the satisfaction with the training service quality of students of the Faculty of Tourism, HUFI. In addition, the higher the Beta value of these variables, the greater the impact on the satisfaction with the training service quality of students of the Faculty of Tourism, HUFI. The author arranges in order the level of influence of each independent variable on the dependent variable from strongest to weakest as follows:
- First, “Academics” has the most influence with coefficient β = 0.402.
- Second is “Non-academic” which has the next influence with coefficient β = 0.343.
- The third is “Training Program” with coefficient β = 0.258.
- Finally, “Reputation” has the weakest impact with coefficient β = 0.085.
4.4.3 Detecting violations of necessary assumptions in linear regression
- Assume the residuals are normally distributed
To detect violations of the normal distribution assumption of the residuals, we will use two drawing tools of SPSS software: Histogram and PP plot.
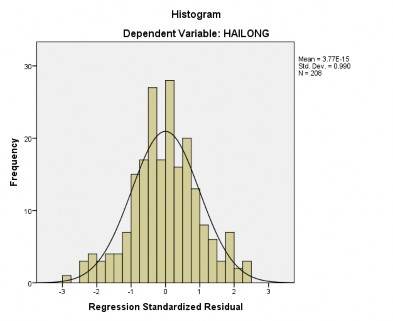
Figure 4.1: Histogram of standardized residual scatter
(Source: Results of author's survey data processing)
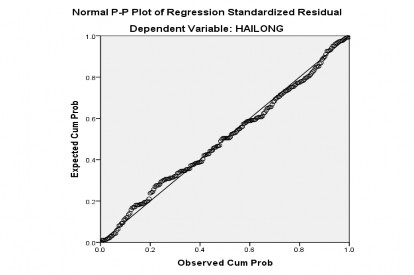
Figure 4.2: PP Plot of standardized regression residuals
(Source: Results of author's survey data processing)
Figure 4.1 shows that almost all the frequency columns are in the bell-shaped graph with mean error close to 0 (Mean value = 3.77E-15 and standard deviation Std.Dev. = 0.990). In addition, Figure 4.2 shows that almost all the observations are distributed around the sample linear regression line. Therefore, the study of
We have a roughly normal distribution, that is, the assumption of normal distribution of the residuals is not violated.
- Assume linearity and constant error variance
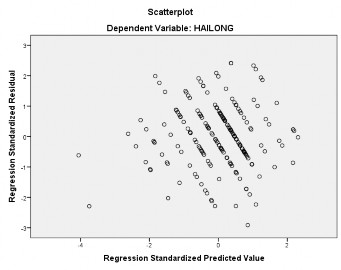
Figure 4.3: Scatter plot of residuals and predicted values of linear regression model
(Source: Results of author's survey data processing)
Figure 4.3 shows that a total of 208 observations are clustered into straight lines, with very few observations falling outside, so it can be concluded that the relationship between the independent and dependent variables in this study is linear.
4.4.4 Testing the hypotheses of the formal research model
Based on the results of Table 4.12, the author concludes that there are 4 hypotheses including H1, H2, H3 and H5 with Sig values all less than 0.05 and the β coefficients are all positive, so these hypotheses are all accepted, as well as the factors all have a positive impact on student satisfaction with the training service quality at the Faculty of Tourism, HUFI with a confidence level of 95%; however, hypothesis H4 is rejected or not accepted because it has Sig > 0.05. Hypothesis H4 states that access has a positive impact on student satisfaction with the training service quality at the Faculty of Tourism, HUFI. Finally, through analysis and evaluation, the research model is adjusted as follows: