pages. Thus, a single page table entry can store mappings for multiple physical page frames. Clustered page tables are especially useful for disjoint address spaces, where memory references are discontinuous and scattered throughout the memory space.
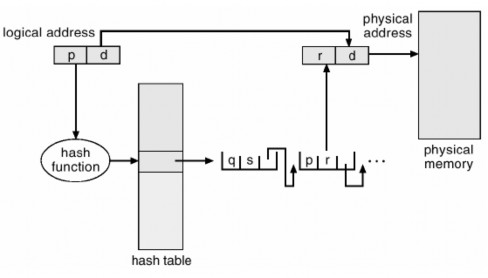
Figure 3.20 Hashed page table
c) Inverted page table: Typically, each process has a page associated with it. The page table has an entry for each page that the process is using (or a slot for each virtual address, regardless of the validity of the latter). This page table representation is natural because the paging process references the virtual addresses of the pages. The operating system must then translate this reference into a physical memory address. Since the table is ordered by virtual address, the operating system can calculate where in the table the physical address entry is linked to and use that value directly. One of the difficulties with this approach is that each page table can contain millions of entries. These tables can consume a large amount of physical memory, which is required just to keep track of how other physical memory is being used.
To solve this problem we can use an inverted page table. The inverted page table has one entry for each physical page (or frame) of memory. Each entry contains the virtual address of the page stored in that physical memory location, along with information about the process that owns that page. Therefore, there is only one page table in the system and it has only one entry for each page of physical memory. Figure 3.21 below shows the operation of the inverted page table.
Maybe you are interested!
-

 Building a system to monitor water level, temperature and send warnings via SMS/GSM network - 2
Building a system to monitor water level, temperature and send warnings via SMS/GSM network - 2 -
 Rules for Building a Fair Performance Management System
Rules for Building a Fair Performance Management System -
 Two Elements A And B Are In Two Consecutive Main Groups In The Periodic System. In Their Pure Substance State, A And B Do Not React With Each Other. Total Number Of Protons
Two Elements A And B Are In Two Consecutive Main Groups In The Periodic System. In Their Pure Substance State, A And B Do Not React With Each Other. Total Number Of Protons -
 Mapreduce And Hdfs (Optimal Features Of Mapreduce When Combined With Hdfs):hdfs Is Just A Distributed File System With Management Mechanisms Inside It.
Mapreduce And Hdfs (Optimal Features Of Mapreduce When Combined With Hdfs):hdfs Is Just A Distributed File System With Management Mechanisms Inside It. -
 A System Is A Composition Of Many Interrelated Components, Connected To The Environment By Inputs And Outputs
A System Is A Composition Of Many Interrelated Components, Connected To The Environment By Inputs And Outputs
Compare this to Figure 3.12, which illustrates the operation of a standard page table. Since a single page table in a system has many other address spaces that map to physical memory, inverted page tables typically require an address space identifier to be stored in each page table entry. Storing the address space identifier ensures that the mapping of the logical page for a given process is to the corresponding physical page frame. Examples of systems that use inverted page tables include the 64-bit UltraSPARC and PowerPC.
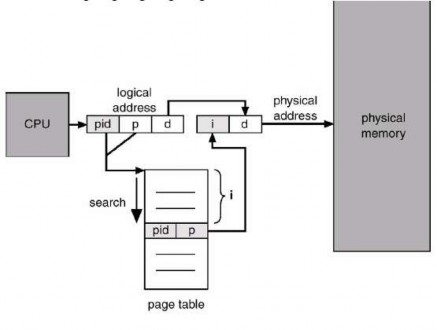
Figure 3.21 Reverse page table
To illustrate this method, we describe a simplified version of the inverted page table implementation used in the IBM RT. Each virtual address in the system contains a triplet:
<process-id, page-number, offset>.
Each entry in the inverted page table is a pair <process-id, page-number>, where the process-id serves as an address space identifier. When a memory reference occurs, a portion of the virtual address, consisting of <process-id, page-number>, is presented to the memory system. The inverted page table is then searched for a match. If a match is found at entry i, the physical address <i, offset> is generated. If not found, an invalid address access is attempted.
Although this mechanism reduces the amount of memory required to store each page table, it increases the amount of time required to look up the table when a reference occurs. Since the inverted page table is stored by physical address but the lookup occurs on virtual address, the entire page table may need to be searched for a match. This lookup
can take too long. To alleviate this problem, we use a hash table as shown in the figure below to limit the lookup. Of course, each access to the hash table adds a reference to the procedure, so that a virtual memory reference requires at least two real memory reads: one for the hash table entry and one for the page table. To improve performance, the TLB is searched first, before the hash table is looked up.
5) Shared Page
Another advantage of paging is the ability to share common code. This consideration is especially important in a time-sharing environment. Consider a system that supports 40 users, each executing a text editor. If the text editor contains 150 KB of code and 50 KB of data, we would need 8000 KB to support 40 users. However, if the code is reentrant code, it can be shared as shown in Figure 3.22. Here we see a three-page editor—each page of 50 KB; the large page size is used to simplify the figure—being shared among three processes. Each process has its own data page.
Reusable code (or pure code) is code that does not change by itself. If code is reusable, it never changes during execution. Therefore, two or more processes can execute the same code at the same time. Each process has its own copy of registers and data stores to manage the data for the execution of the process. Of course, the data for two different processes will be different for each process.
Only one copy of the editor needs to be kept in physical memory. Each user's page table maps to the same physical copy of the editor, but the data pages are mapped to different frames. Thus, to support 40 users, we need only one copy of the editor (150 KB) plus 40 copies of the 50 KB data space per user. Now the total space required is 2150 KB instead of 8000 KB—a huge savings.
Other widely used programs may also be shared - compilers, windowing systems, runtime libraries, database systems, etc. To be shared, the code must be reusable. The read-only nature of the shared code should not be left to the correctness of the code; the operating system should obey the
This feature. Sharing memory between processes on an operating system is similar to sharing the address space of a task by threads. Additionally, memory is shared as a method of interprocess communication. Some operating systems implement shared memory using shared pages.
Operating systems that use internal page tables have difficulty implementing shared memory. Shared memory is typically implemented as multiple virtual addresses (one for each process sharing the memory) that are mapped to a single physical address. However, this standard method cannot be used when there is only one virtual page entry per physical page, so a physical page cannot have two (or more) shared virtual addresses.
Page-based memory organization offers several other advantages to allow multiple processes to share the same physical page.
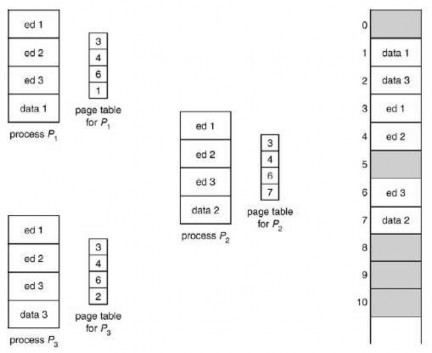
Figure 3.22 code sharing in a paging environment
3.1.6 Segmentation
An important aspect of memory management that becomes unavoidable with paging is the separation of the user's view of memory and the actual physical memory. The user's view of memory is not the same as physical memory. The user's view is mapped onto physical memory. The mapping allows for the distinction between logical memory and physical memory.
1) Basic method
Do users think of memory as a linear array of bytes, some containing instructions and others containing data? Most people say no. Rather, users prefer to see memory as a collection of variable-sized segments, with no need for ordering between segments (Figure 3.23).
How do we think of a program when we are writing it? We think of it as a main program with a collection of subroutines, procedures, functions, or modules. There may be different data structures: tables, arrays, stacks, variables, etc. Each of these modules or data elements is referenced by name. We say “the symbol table,” “the sqrt function,” “the main program,” regardless of the addresses in memory that these elements occupy. We do not care whether the symbol table is stored before or after the sqrt function. Each of these segments is of variable length; in fact, the length is determined by the purpose of the segment in the program. The elements in a segment are defined by their offsets from the beginning of the segment: the first statement of the program, the seventeenth entry in the symbol table, the fifth instruction of the sqrt function, etc.
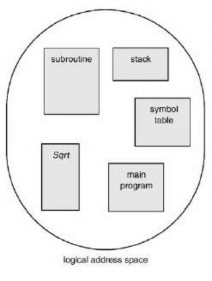
Figure 3.23 User's view of the program
Segmentation is a memory management mechanism that supports the user's view of memory. The logical address space is a collection of segments. Each segment has a name and a length. Addresses specify the segment name and the displacement within the segment. Thus, the user specifies each address by two quantities: the segment name and the displacement. (correspondingly
This mechanism is contrasted with paging, in which the user specifies only a single address, which is divided by the hardware into a page number and an offset, all invisible to the programmer).
To simplify implementation, segments are numbered and referred to by segment number, rather than by segment name. Therefore, the logical address contains a tuple of two:
<segment-number, offset>
<number of segments, displacement>
Typically, the user program is compiled, and the compiler automatically generates segments that reflect the input program. A Pascal program might generate its own segments as follows:
1) Global variables
2) Procedure call stack, to store parameters and return addresses
3) The code of each procedure or function
4) Local variables of each procedure and function
A compiler can create a separate segment for each common block. Arrays can be assigned separate segments. The loader can take all these segments and assign them segment numbers.
2) Hardware
Although users can refer to objects in a program by a two-dimensional address, physical memory is a one-dimensional sequence of bytes. Therefore, we must define an implementation that maps user-defined two-dimensional addresses to one-dimensional physical addresses. This mapping is effected by a segment table. Each entry in the segment table has a segment base and a segment limit. The segment base contains the starting physical address where the segment is located in memory, whereas the segment limit determines the length of the segment.
Using the segment table shown in Figure 3.24, a logical address has two parts: the segment number s and the segment offset d. The segment number is used as an index into the segment table. The offset d of the logical address must be between 0 and the segment limit. Otherwise, we will trap the operating system (the physical address goes past the end of the segment). If this offset is valid, it is added to the base value of
segment to generate the physical memory address of the desired byte. Thus, the segment table is an array of base and limit register pairs.
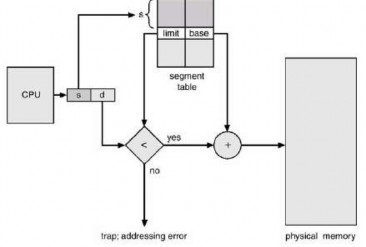
Figure 3.24 Segmentation hardware
Consider the case shown in Figure 3.25. We have five segments numbered 0 through 4. The segments are stored in physical memory as shown. The segment table has a separate entry for each segment, giving the starting address of the segment in physical memory (or base) and the length of the segment (or limit). For example, segment 2 is 400 bytes long and starts at location 4300. Therefore, a reference to byte 53 of segment 2 is mapped to location 4300 + 53 = 4353. A reference to segment 3, byte 852, is mapped to 3200 (the base value of segment 3) + 852 = 4052. A reference to byte 1222 of segment 0 results in a trap to the operating system, since this segment is only 1000 bytes long.
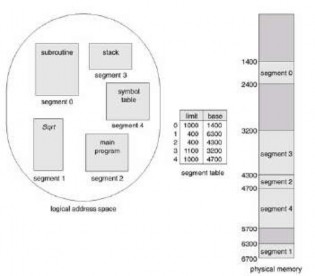
Figure 3.25 Example of segmentation
a) Protect and share
A special advantage of segmentation is the protection associated with the segments. Since segments represent a defined part of the program, it is likely that all entries in the segment will be used in the same way. Therefore, some segments are instructions, while others are data. In a modern architecture, instructions do not modify themselves, so instruction segments can be defined as read-only or executable. The memory-mapped hardware checks the protection bits associated with each entry in the segment table to prevent illegal accesses to memory, such as attempts to write to a read-only segment or use read-only segments as data. By replacing an array in its own segment, the memory management hardware automatically checks that the array indexes are valid and do not go beyond the array's bounds. Therefore, many program errors are detected by the hardware before they can cause major damage.
Another advantage involves sharing code or data. Each process has a segment table associated with it. The dispatcher uses this segment table to define hardware segments when a process is allocated a CPU. Segments are shared when the segment table entries of two different processes point to the same physical location (Figure 3.26).
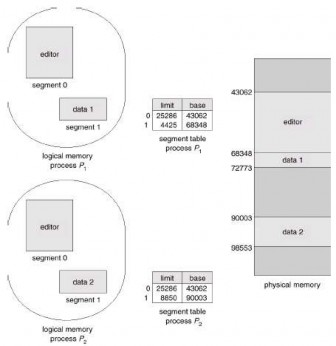
Figure 3.26 Sharing segments in a segmented memory system