NLU processes user messages using a pipeline where the following processing steps are configured sequentially:
Domain Classification
Classification)
Intent classification
Maybe you are interested!
-

 Solutions for tourism development in Tien Lang - 10
zt2i3t4l5ee
zt2a3gstourism, tourism development
zt2a3ge
zc2o3n4t5e6n7ts
- District People's Committees and authorities of communes with tourist attractions should support, promote, and provide necessary information to people, helping them improve their knowledge about tourism. Raise tourism awareness for local people.
*
* *
Due to limited knowledge and research time, the thesis inevitably has shortcomings. Therefore, I look forward to receiving guidance from teachers, experts as well as your comments to make the thesis more complete.
Chapter III Conclusion
Through the issues presented in Chapter II, we can come to some conclusions:
Based on the strengths of available tourism resources, the types of tourism in Tien Lang that need to be promoted in the coming time are sightseeing and resort tourism, discovery tourism, weekend tourism. To improve the quality and diversify tourism products, Tien Lang district needs to combine with local cultural tourism resources, at the same time combine with surrounding areas, build rich tourism products. The strengths of Tien Lang tourism are eco-tourism and cultural tourism, so developing Tien Lang tourism must always go hand in hand with restoring and preserving types of cultural tourism resources. Some necessary measures to support and improve the efficiency of exploiting tourism resources in Tien Lang are: strengthening the construction of technical facilities and labor force serving tourism, actively promoting and advertising tourism, and expanding forms of capital mobilization for tourism development.
CONCLUDE
I Conclusion
1. Based on the results achieved within the framework of the thesis's needs, some basic conclusions can be drawn as follows:
Tien Lang is a locality with great potential for tourism development. The relatively abundant cultural tourism resources and ecological tourism resources have great appeal to tourists. Based on this potential, Tien Lang can build a unique tourism industry that is competitive enough with other localities within Hai Phong city and neighboring areas.
In recent years, the exploitation of the advantages of resources to develop tourism and build tourist routes in Tien Lang has not been commensurate with the available potential. In terms of quantity, many resource objects have not been brought into the purpose of tourism development. In terms of time, the regular service time has not been extended to attract more visitors. Infrastructure and technical facilities are still weak. The labor force is still thin and weak in terms of expertise. Tourism programs and routes have not been organized properly, the exploitation content is still monotonous, so it has not attracted many visitors. Although resources have not been mobilized much for tourism development, they are facing the risk of destruction and degradation.
2. Based on the results of investigation, analysis, synthesis, evaluation and selective absorption of research results of related topics, the thesis has proposed a number of necessary solutions to improve the efficiency of exploiting tourism resources in Tien Lang such as: promoting the restoration and conservation of tourism resources, focusing on investment and key exploitation of ecotourism resources, strengthening the construction of infrastructure and tourism workforce. Expanding forms of capital mobilization. In addition, the thesis has built a number of tourist routes of Hai Phong in which Tien Lang tourism resources play an important role.
Exploiting Tien Lang tourism resources for tourism development is currently facing many difficulties. The above measures, if applied synchronously, will likely bring new prospects for the local tourism industry, contributing to making Tien Lang tourism an important economic sector in the district's economic structure.
REFERENCES
1. Nhuan Ha, Trinh Minh Hien, Tran Phuong, Hai Phong - Historical and cultural relics, Hai Phong Publishing House, 1993
2. Hai Phong City History Council, Hai Phong Gazetteer, Hai Phong Publishing House, 1990.
3. Hai Phong City History Council, History of Tien Lang District Party Committee, Hai Phong Publishing House, 1990.
4. Hai Phong City History Council, University of Social Sciences and Humanities, VNU, Hai Phong Place Names Encyclopedia, Hai Phong Publishing House. 2001.
5. Law on Cultural Heritage and documents guiding its implementation, National Political Publishing House, Hanoi, 2003.
6. Tran Duc Thanh, Lecture on Tourism Geography, Faculty of Tourism, University of Social Sciences and Humanities, VNU, 2006
7. Hai Phong Center for Social Sciences and Humanities, Some typical cultural heritages of Hai Phong, Hai Phong Publishing House, 2001
8. Nguyen Ngoc Thao (editor-in-chief, Tourism Geography, Hai Phong Publishing House, two volumes (2001-2002)
9. Nguyen Minh Tue and group of authors, Hai Phong Tourism Geography, Ho Chi Minh City Publishing House, 1997.
10. Nguyen Thanh Son, Hai Phong Tourism Territory Organization, Associate Doctoral Thesis in Geological Geography, Hanoi, 1996.
11. Decision No. 2033/QD – UB on detailed planning of Tien Lang town, Hai Phong city until 2020.
12. Department of Culture, Information, Hai Phong Museum, Hai Phong relics
- National ranked scenic spot, Hai Phong Publishing House, 2005. 13. Tien Lang District People's Committee, Economic Development Planning -
Culture - Society of Tien Lang district to 2010.
14.Website www.HaiPhong.gov.vn
APPENDIX 1
List of national ranked monuments
STT
Name of the monument
Number, year of decisiondetermine
Location
1
Gam Temple
938 VH/QĐ04/08/1992
Cam Khe Village- Toan Thang commune
2
Doc Hau Temple
9381 VH/QĐ04/08/1992
Doc Hau Village –Toan Thang commune
3
Cuu Doi Communal House
3207 VH/QĐDecember 30, 1991
Zone II of townTien Lang
4
Ha Dai Temple
938 VH/QĐ04/08/1992
Ha Dai Village –Tien Thanh commune
APPENDIX II
STT
Name of the monument
Number, year of decision
Location
1
Phu Ke Pagoda Temple
178/QD-UBJanuary 28, 2005
Zone 1 - townTien Lang
2
Trung Lang Temple
178/QD-UBJanuary 28, 2005
Zone 4 – townTien Lang
3
Bao Khanh Pagoda
1900/QD-UBAugust 24, 2006
Nam Tu Village -Kien Thiet commune
4
Bach Da Pagoda
1792/QD-UB11/11/2002
Hung Thang Commune
5
Ngoc Dong Temple
177/QD-UBNovember 27, 2005
Tien Thanh Commune
6
Tomb of Minister TSNhu Van Lan
2848/QD-UBSeptember 19, 2003
Nam Tu Village -Kien Thiet commune
7
Canh Son Stone Temple
2160/QD-UBSeptember 19, 2003
Van Doi Commune –Doan Lap
8
Meiji Temple
2259/QD-UBSeptember 19, 2002
Toan Thang Commune
9
Tien Doi Noi Temple
477/QD-UBSeptember 19, 2005
Doan Lap Commune
10
Tu Doi Temple
177/QD-UBJanuary 28, 2005
Doan Lap Commune
11
Duyen Lao Temple
177/QD-UBJanuary 28, 2005
Tien Minh Commune
12
Dinh Xuan Uc Pagoda
177/QD-UBJanuary 28, 2005
Bac Hung Commune
13
Chu Khe Pagoda
177/QD-UBJanuary 28, 2005
Hung Thang Commune
14
Dong Dinh
2848/QD-UBNovember 21, 2002
Vinh Quang Commune
15
President's Memorial HouseTon Duc Thang
177/QD-UBJanuary 28, 2005
NT Quy Cao
Ha Dai Temple
Ben Vua Temple
Tien Lang hot spring
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 16pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 6pt; } div.maincontent .s9 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; tex
Solutions for tourism development in Tien Lang - 10
zt2i3t4l5ee
zt2a3gstourism, tourism development
zt2a3ge
zc2o3n4t5e6n7ts
- District People's Committees and authorities of communes with tourist attractions should support, promote, and provide necessary information to people, helping them improve their knowledge about tourism. Raise tourism awareness for local people.
*
* *
Due to limited knowledge and research time, the thesis inevitably has shortcomings. Therefore, I look forward to receiving guidance from teachers, experts as well as your comments to make the thesis more complete.
Chapter III Conclusion
Through the issues presented in Chapter II, we can come to some conclusions:
Based on the strengths of available tourism resources, the types of tourism in Tien Lang that need to be promoted in the coming time are sightseeing and resort tourism, discovery tourism, weekend tourism. To improve the quality and diversify tourism products, Tien Lang district needs to combine with local cultural tourism resources, at the same time combine with surrounding areas, build rich tourism products. The strengths of Tien Lang tourism are eco-tourism and cultural tourism, so developing Tien Lang tourism must always go hand in hand with restoring and preserving types of cultural tourism resources. Some necessary measures to support and improve the efficiency of exploiting tourism resources in Tien Lang are: strengthening the construction of technical facilities and labor force serving tourism, actively promoting and advertising tourism, and expanding forms of capital mobilization for tourism development.
CONCLUDE
I Conclusion
1. Based on the results achieved within the framework of the thesis's needs, some basic conclusions can be drawn as follows:
Tien Lang is a locality with great potential for tourism development. The relatively abundant cultural tourism resources and ecological tourism resources have great appeal to tourists. Based on this potential, Tien Lang can build a unique tourism industry that is competitive enough with other localities within Hai Phong city and neighboring areas.
In recent years, the exploitation of the advantages of resources to develop tourism and build tourist routes in Tien Lang has not been commensurate with the available potential. In terms of quantity, many resource objects have not been brought into the purpose of tourism development. In terms of time, the regular service time has not been extended to attract more visitors. Infrastructure and technical facilities are still weak. The labor force is still thin and weak in terms of expertise. Tourism programs and routes have not been organized properly, the exploitation content is still monotonous, so it has not attracted many visitors. Although resources have not been mobilized much for tourism development, they are facing the risk of destruction and degradation.
2. Based on the results of investigation, analysis, synthesis, evaluation and selective absorption of research results of related topics, the thesis has proposed a number of necessary solutions to improve the efficiency of exploiting tourism resources in Tien Lang such as: promoting the restoration and conservation of tourism resources, focusing on investment and key exploitation of ecotourism resources, strengthening the construction of infrastructure and tourism workforce. Expanding forms of capital mobilization. In addition, the thesis has built a number of tourist routes of Hai Phong in which Tien Lang tourism resources play an important role.
Exploiting Tien Lang tourism resources for tourism development is currently facing many difficulties. The above measures, if applied synchronously, will likely bring new prospects for the local tourism industry, contributing to making Tien Lang tourism an important economic sector in the district's economic structure.
REFERENCES
1. Nhuan Ha, Trinh Minh Hien, Tran Phuong, Hai Phong - Historical and cultural relics, Hai Phong Publishing House, 1993
2. Hai Phong City History Council, Hai Phong Gazetteer, Hai Phong Publishing House, 1990.
3. Hai Phong City History Council, History of Tien Lang District Party Committee, Hai Phong Publishing House, 1990.
4. Hai Phong City History Council, University of Social Sciences and Humanities, VNU, Hai Phong Place Names Encyclopedia, Hai Phong Publishing House. 2001.
5. Law on Cultural Heritage and documents guiding its implementation, National Political Publishing House, Hanoi, 2003.
6. Tran Duc Thanh, Lecture on Tourism Geography, Faculty of Tourism, University of Social Sciences and Humanities, VNU, 2006
7. Hai Phong Center for Social Sciences and Humanities, Some typical cultural heritages of Hai Phong, Hai Phong Publishing House, 2001
8. Nguyen Ngoc Thao (editor-in-chief, Tourism Geography, Hai Phong Publishing House, two volumes (2001-2002)
9. Nguyen Minh Tue and group of authors, Hai Phong Tourism Geography, Ho Chi Minh City Publishing House, 1997.
10. Nguyen Thanh Son, Hai Phong Tourism Territory Organization, Associate Doctoral Thesis in Geological Geography, Hanoi, 1996.
11. Decision No. 2033/QD – UB on detailed planning of Tien Lang town, Hai Phong city until 2020.
12. Department of Culture, Information, Hai Phong Museum, Hai Phong relics
- National ranked scenic spot, Hai Phong Publishing House, 2005. 13. Tien Lang District People's Committee, Economic Development Planning -
Culture - Society of Tien Lang district to 2010.
14.Website www.HaiPhong.gov.vn
APPENDIX 1
List of national ranked monuments
STT
Name of the monument
Number, year of decisiondetermine
Location
1
Gam Temple
938 VH/QĐ04/08/1992
Cam Khe Village- Toan Thang commune
2
Doc Hau Temple
9381 VH/QĐ04/08/1992
Doc Hau Village –Toan Thang commune
3
Cuu Doi Communal House
3207 VH/QĐDecember 30, 1991
Zone II of townTien Lang
4
Ha Dai Temple
938 VH/QĐ04/08/1992
Ha Dai Village –Tien Thanh commune
APPENDIX II
STT
Name of the monument
Number, year of decision
Location
1
Phu Ke Pagoda Temple
178/QD-UBJanuary 28, 2005
Zone 1 - townTien Lang
2
Trung Lang Temple
178/QD-UBJanuary 28, 2005
Zone 4 – townTien Lang
3
Bao Khanh Pagoda
1900/QD-UBAugust 24, 2006
Nam Tu Village -Kien Thiet commune
4
Bach Da Pagoda
1792/QD-UB11/11/2002
Hung Thang Commune
5
Ngoc Dong Temple
177/QD-UBNovember 27, 2005
Tien Thanh Commune
6
Tomb of Minister TSNhu Van Lan
2848/QD-UBSeptember 19, 2003
Nam Tu Village -Kien Thiet commune
7
Canh Son Stone Temple
2160/QD-UBSeptember 19, 2003
Van Doi Commune –Doan Lap
8
Meiji Temple
2259/QD-UBSeptember 19, 2002
Toan Thang Commune
9
Tien Doi Noi Temple
477/QD-UBSeptember 19, 2005
Doan Lap Commune
10
Tu Doi Temple
177/QD-UBJanuary 28, 2005
Doan Lap Commune
11
Duyen Lao Temple
177/QD-UBJanuary 28, 2005
Tien Minh Commune
12
Dinh Xuan Uc Pagoda
177/QD-UBJanuary 28, 2005
Bac Hung Commune
13
Chu Khe Pagoda
177/QD-UBJanuary 28, 2005
Hung Thang Commune
14
Dong Dinh
2848/QD-UBNovember 21, 2002
Vinh Quang Commune
15
President's Memorial HouseTon Duc Thang
177/QD-UBJanuary 28, 2005
NT Quy Cao
Ha Dai Temple
Ben Vua Temple
Tien Lang hot spring
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 16pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 6pt; } div.maincontent .s9 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; tex -
 Theoretical Research Method: Collecting Documents Related to the Thesis, Analyzing, Synthesizing to Build a Theoretical Framework
Theoretical Research Method: Collecting Documents Related to the Thesis, Analyzing, Synthesizing to Build a Theoretical Framework -
 Research proposal for developing ecotourism to support biodiversity conservation in Vu Quang National Park, Vu Quang district, Ha Tinh province - 13
Research proposal for developing ecotourism to support biodiversity conservation in Vu Quang National Park, Vu Quang district, Ha Tinh province - 13 -
 Qualitative Research to Refine Model and Build Scale
Qualitative Research to Refine Model and Build Scale -
![Mobile Phone Usage in Hanoi Inner City Area
zt2i3t4l5ee
zt2a3gsconsumer,consumption,consumer behavior,marketing,mobile marketing
zt2a3ge
zc2o3n4t5e6n7ts
- Test the relationship between demographic variables and consumer behavior for Mobile Marketing activities
The analysis method used is the Chi-square test (χ2), with statistical hypotheses H0 and H1 and significance level α = 0.05. In case the P index (p-value) or Sig. index in SPSS has a value less than or equal to the significance level α, the hypothesis H0 is rejected and vice versa. With this testing procedure, the study can evaluate the difference in behavioral trends between demographic groups.
CHAPTER 4
RESEARCH RESULTS
During two months, 1,100 survey questionnaires were distributed to mobile phone users in the inner city of Hanoi using various methods such as direct interviews, sending via email or using questionnaires designed on the Internet. At the end of the survey, after checking and eliminating erroneous questionnaires, the study collected 858 complete questionnaires, equivalent to a rate of about 78%. In addition, the research subjects of the thesis are only people who are using mobile phones, so people who do not use mobile phones are not within the scope of the thesis, therefore, the questionnaires with the option of not using mobile phones were excluded from the scope of analysis. The number of suitable survey questionnaires included in the statistical analysis was 835.
4.1 Demographic characteristics of the sample
The structure of the survey sample is divided and statistically analyzed according to criteria such as gender, age, occupation, education level and personal income. (Detailed statistical table in Appendix 6)
- Gender structure: Of the 835 completed questionnaires, 49.8% of respondents were male, equivalent to 416 people, and 50.2% were female, equivalent to 419 people. The survey results of the study are completely consistent with the gender ratio in the population structure of Vietnam in general and Hanoi in particular (Male/Female: 49/51).
- Age structure: 36.6% of respondents are <23 years old, equivalent to 306 people. People from 23-34 years old
accounting for the highest proportion: 44.8% equivalent to 374 people, people aged 35-45 and >45 are 70 and 85 people equivalent to 8.4% and 10.2% respectively. Looking at the results of this survey, we can see that the young people - youth account for a large proportion of the total number of people participating in the survey. Meanwhile, the middle-aged people including two age groups of 35 - 45 and >45 have a low rate of participation in the survey. This is completely consistent with the reality when Mobile Marketing is identified as a Marketing service aimed at young people (people under 35 years old).
- Structure by educational level: among 835 valid responses, 541 respondents had university degrees, accounting for the highest proportion of ~ 75%, 102 had secondary school degrees, ~ 13.1%, and 93 had post-graduate degrees, ~ 11.9%.
- Occupational structure: office workers and civil servants are the group with the highest rate of participation with 39.4%, followed by students with 36.6%. Self-employed people account for 12%, retired housewives are 7.8% and other occupational groups account for 4.2%. The survey results show that the student group has the same rate as the group aged <23 at 36.6%. This shows the accuracy of the survey data. In addition, the survey results distributed by occupational criteria have a rate almost similar to the sample division rate in chapter 3. Therefore, it can be concluded that the survey data is suitable for use in analysis activities.
- Income structure: the group with income from 3 to 5 million has the highest rate with 39% of the total number of respondents. This is consistent with the income structure of Hanoi people and corresponds to the average income of the group of civil servants and office workers. Those
People with no income account for 23%, income under 3 million VND accounts for 13% and income over 5 million VND accounts for 25%.
4.2 Mobile phone usage in Hanoi inner city area
According to the survey results, most respondents said they had used the phone for more than 1 year, specifically: 68.4% used mobile phones from 4 to 10 years, 23.2% used from 1 to 3 years, 7.8% used for more than 10 years. Those who used mobile phones for less than 1 year accounted for only a very small proportion of ~ 0.6%. (Table 4.1)
Table 4.1: Time spent using mobile phones
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Alid
<1 year
5
.6
.6
.6
1-3 years
194
23.2
23.2
23.8
4-10 years
571
68.4
68.4
92.2
>10 years
65
7.8
7.8
100.0
Total
835
100.0
100.0
The survey indexes on the time of using mobile phones of consumers in the inner city of Hanoi are very impressive for a developing country like Vietnam and also prove that Vietnamese consumers have a lot of experience using this high-tech device. Moreover, with the majority of consumers surveyed having a relatively long time of use (4-10 years), it partly proves that mobile phones have become an important and essential item in peoples daily lives.
When asked about the mobile phone network they are using, 31% of respondents said they are using the network of Vietel company, 29% use the network of
of Mobifone company, 27% use Vinaphone companys network and 13% use networks of other providers such as E-VN telecom, S-fone, Beeline, Vietnammobile. (Figure 4.1).
Figure 4.1: Mobile phone network in use
Compared with the announced market share of mobile telecommunications service providers in Vietnam (Vietel: 36%, Mobifone: 29%, Vinaphone: 28%, the remaining networks: 7%), we see that the survey results do not have many differences. However, the statistics show that there is a difference in the market share of other networks because the Hanoi market is one of the two main markets of small networks, so their market share in this area will certainly be higher than that of the whole country.
According to a report by NielsenMobile (2009) [8], the number of prepaid mobile phone subscribers in Hanoi accounts for 95% of the total number of subscribers, however, the results of this survey show that the percentage of prepaid subscribers has decreased by more than 20%, only at 70.8%. On the contrary, the number of postpaid subscribers tends to increase from 5% in 2009 to 19.2%. Those who are simultaneously using both types of subscriptions account for 10%. (Table 4.2).
Table 4.2: Types of mobile phone subscribers
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Prepay
591
70.8
70.8
70.8
Pay later
160
19.2
19.2
89.9
Both of the above
84
10.1
10.1
100.0
Total
835
100.0
100.0
The above figures show the change in the psychology and consumption habits of Vietnamese consumers towards mobile telecommunications services, when the use of prepaid subscriptions and junk SIMs is replaced by the use of two types of subscriptions for different purposes and needs or switching to postpaid subscriptions to enjoy better customer care services.
In addition, the majority of respondents have an average spending level for mobile phone services from 100 to 300 thousand VND (406 ~ 48.6% of total respondents). The high spending level (> 500 thousand VND) is the spending level with the lowest number of people with only 8.4%, on the contrary, the low spending level (under 100 thousand VND) accounts for the second highest proportion among the groups of respondents with 25.4%. People with low spending levels mainly fall into the group of students and retirees/housewives - those who have little need to use or mainly use promotional SIM cards. (Table 4.3).
Table 4.3: Spending on mobile phone charges
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<100,000
212
25.4
25.4
25.4
100-300,000
406
48.6
48.6
74.0
300,000-500,000
147
17.6
17.6
91.6
>500,000
70
8.4
8.4
100.0
Total
835
100.0
100.0
The statistics in Table 4.3 are similar to the percentages in the NielsenMobile survey results (2009) with 73% of mobile phone users having medium spending levels and only 13% having high spending levels.
The survey results also showed that up to 31% ~ nearly one-third of respondents said they sent more than 10 SMS messages/day, meaning that on average they sent 1 SMS message for every working hour. Those with an average SMS message volume (from 3 to 10 messages/day) accounted for 51.1% and those with a low SMS message volume (less than 3 messages/day) accounted for 17%. (Table 4.4)
Table 4.4: Number of SMS messages sent per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
142
17.0
17.0
17.0
3-10 news
427
51.1
51.1
68.1
>10 news
266
31.9
31.9
100.0
Total
835
100.0
100.0
Similar to sending messages, those with an average message receiving rate (from 3-10 messages/day) accounted for the highest percentage of ~ 55%, followed by those with a high number of messages (over 10 messages/day) ~ 24% and those with a low number of messages received daily (under 3 messages/day) remained at the bottom with 21%. (Table 4.5)
Table 4.5: Number of SMS messages received per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
175
21.0
21.0
21.0
3-10 news
436
55.0
55.0
76.0
>10 news
197
24.0
24.0
100.0
Total
835
100.0
100.0
When comparing the data of the two result tables 4.4 and 4.5, we can see the reasonableness between the ratio of the number of messages sent and the number of messages received daily by the interview participants.
4.3 Current status of SMS advertising and Mobile Marketing
According to the interview results, in the 3 months from the time of the survey and before, 94% of respondents, equivalent to 785 people, said they received advertising messages, while only a very small percentage of 6% (only 50 people) did not receive advertising messages (Table 4.6).
Table 4.6: Percentage of people receiving advertising messages in the last 3 months
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Have
785
94.0
94.0
94.0
Are not
50
6.0
6.0
100.0
Total
835
100.0
100.0
The results of Table 4.6 show that consumers in the inner city of Hanoi are very familiar with advertising messages. This result is also the basis for assessing the knowledge, experience and understanding of the respondents in the interview. This is also one of the important factors determining the accuracy of the survey results.
In addition, most respondents said they had received promotional messages, but only 24% of them had ever taken the action of registering to receive promotional messages, while 76% of the remaining respondents did not register to receive promotional messages but still received promotional messages every day. This is the first sign indicating the weaknesses and shortcomings of lax management of this activity in Vietnam. (Table 4.7)
div.maincontent .s1 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s2 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s4 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s5 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s15 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s16 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 5.5pt; vertical-align: 3pt; } div.maincontent .s17 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 8.5pt; } div.maincontent .s18 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s20 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s21 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s22 { color: black; font-family:Courier New, monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s23 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s24 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s25 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s26 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s27 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 1.5pt; } div.maincontent .s28 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s29 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s30 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s31 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s32 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s33 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s36 { color: #F00; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s37 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s38 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 8.5pt; vertical-align: 5pt; } div.maincontent .s39 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s40 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 4pt; } div.maincontent .s41 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s42 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s43 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7.5pt; vertical-align: 5pt; } div.maincontent .s44 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s45 { color: #F00; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s46 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s47 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s48 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s49 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s50 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s51 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s52 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s53 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s54 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s55 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s56 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s57 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s58 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s59 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s60 { color: #00F; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; font-size: 13pt; } div.maincontent .s61 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s62 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s63 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .content_head2 { color: #F00; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s64 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s67 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s68 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s69 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s70 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; tex](https://tailieuthamkhao.com/uploads/2022/12/03/cac-nhan-to-anh-huong-den-hanh-vi-nguoi-tieu-dung-doi-voi-hoat-dong-13-1-120x90.jpg) Mobile Phone Usage in Hanoi Inner City Area
zt2i3t4l5ee
zt2a3gsconsumer,consumption,consumer behavior,marketing,mobile marketing
zt2a3ge
zc2o3n4t5e6n7ts
- Test the relationship between demographic variables and consumer behavior for Mobile Marketing activities
The analysis method used is the Chi-square test (χ2), with statistical hypotheses H0 and H1 and significance level α = 0.05. In case the P index (p-value) or Sig. index in SPSS has a value less than or equal to the significance level α, the hypothesis H0 is rejected and vice versa. With this testing procedure, the study can evaluate the difference in behavioral trends between demographic groups.
CHAPTER 4
RESEARCH RESULTS
During two months, 1,100 survey questionnaires were distributed to mobile phone users in the inner city of Hanoi using various methods such as direct interviews, sending via email or using questionnaires designed on the Internet. At the end of the survey, after checking and eliminating erroneous questionnaires, the study collected 858 complete questionnaires, equivalent to a rate of about 78%. In addition, the research subjects of the thesis are only people who are using mobile phones, so people who do not use mobile phones are not within the scope of the thesis, therefore, the questionnaires with the option of not using mobile phones were excluded from the scope of analysis. The number of suitable survey questionnaires included in the statistical analysis was 835.
4.1 Demographic characteristics of the sample
The structure of the survey sample is divided and statistically analyzed according to criteria such as gender, age, occupation, education level and personal income. (Detailed statistical table in Appendix 6)
- Gender structure: Of the 835 completed questionnaires, 49.8% of respondents were male, equivalent to 416 people, and 50.2% were female, equivalent to 419 people. The survey results of the study are completely consistent with the gender ratio in the population structure of Vietnam in general and Hanoi in particular (Male/Female: 49/51).
- Age structure: 36.6% of respondents are <23 years old, equivalent to 306 people. People from 23-34 years old
accounting for the highest proportion: 44.8% equivalent to 374 people, people aged 35-45 and >45 are 70 and 85 people equivalent to 8.4% and 10.2% respectively. Looking at the results of this survey, we can see that the young people - youth account for a large proportion of the total number of people participating in the survey. Meanwhile, the middle-aged people including two age groups of 35 - 45 and >45 have a low rate of participation in the survey. This is completely consistent with the reality when Mobile Marketing is identified as a Marketing service aimed at young people (people under 35 years old).
- Structure by educational level: among 835 valid responses, 541 respondents had university degrees, accounting for the highest proportion of ~ 75%, 102 had secondary school degrees, ~ 13.1%, and 93 had post-graduate degrees, ~ 11.9%.
- Occupational structure: office workers and civil servants are the group with the highest rate of participation with 39.4%, followed by students with 36.6%. Self-employed people account for 12%, retired housewives are 7.8% and other occupational groups account for 4.2%. The survey results show that the student group has the same rate as the group aged <23 at 36.6%. This shows the accuracy of the survey data. In addition, the survey results distributed by occupational criteria have a rate almost similar to the sample division rate in chapter 3. Therefore, it can be concluded that the survey data is suitable for use in analysis activities.
- Income structure: the group with income from 3 to 5 million has the highest rate with 39% of the total number of respondents. This is consistent with the income structure of Hanoi people and corresponds to the average income of the group of civil servants and office workers. Those
People with no income account for 23%, income under 3 million VND accounts for 13% and income over 5 million VND accounts for 25%.
4.2 Mobile phone usage in Hanoi inner city area
According to the survey results, most respondents said they had used the phone for more than 1 year, specifically: 68.4% used mobile phones from 4 to 10 years, 23.2% used from 1 to 3 years, 7.8% used for more than 10 years. Those who used mobile phones for less than 1 year accounted for only a very small proportion of ~ 0.6%. (Table 4.1)
Table 4.1: Time spent using mobile phones
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Alid
<1 year
5
.6
.6
.6
1-3 years
194
23.2
23.2
23.8
4-10 years
571
68.4
68.4
92.2
>10 years
65
7.8
7.8
100.0
Total
835
100.0
100.0
The survey indexes on the time of using mobile phones of consumers in the inner city of Hanoi are very impressive for a developing country like Vietnam and also prove that Vietnamese consumers have a lot of experience using this high-tech device. Moreover, with the majority of consumers surveyed having a relatively long time of use (4-10 years), it partly proves that mobile phones have become an important and essential item in people's daily lives.
When asked about the mobile phone network they are using, 31% of respondents said they are using the network of Vietel company, 29% use the network of
of Mobifone company, 27% use Vinaphone company's network and 13% use networks of other providers such as E-VN telecom, S-fone, Beeline, Vietnammobile. (Figure 4.1).
Figure 4.1: Mobile phone network in use
Compared with the announced market share of mobile telecommunications service providers in Vietnam (Vietel: 36%, Mobifone: 29%, Vinaphone: 28%, the remaining networks: 7%), we see that the survey results do not have many differences. However, the statistics show that there is a difference in the market share of other networks because the Hanoi market is one of the two main markets of small networks, so their market share in this area will certainly be higher than that of the whole country.
According to a report by NielsenMobile (2009) [8], the number of prepaid mobile phone subscribers in Hanoi accounts for 95% of the total number of subscribers, however, the results of this survey show that the percentage of prepaid subscribers has decreased by more than 20%, only at 70.8%. On the contrary, the number of postpaid subscribers tends to increase from 5% in 2009 to 19.2%. Those who are simultaneously using both types of subscriptions account for 10%. (Table 4.2).
Table 4.2: Types of mobile phone subscribers
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Prepay
591
70.8
70.8
70.8
Pay later
160
19.2
19.2
89.9
Both of the above
84
10.1
10.1
100.0
Total
835
100.0
100.0
The above figures show the change in the psychology and consumption habits of Vietnamese consumers towards mobile telecommunications services, when the use of prepaid subscriptions and junk SIMs is replaced by the use of two types of subscriptions for different purposes and needs or switching to postpaid subscriptions to enjoy better customer care services.
In addition, the majority of respondents have an average spending level for mobile phone services from 100 to 300 thousand VND (406 ~ 48.6% of total respondents). The high spending level (> 500 thousand VND) is the spending level with the lowest number of people with only 8.4%, on the contrary, the low spending level (under 100 thousand VND) accounts for the second highest proportion among the groups of respondents with 25.4%. People with low spending levels mainly fall into the group of students and retirees/housewives - those who have little need to use or mainly use promotional SIM cards. (Table 4.3).
Table 4.3: Spending on mobile phone charges
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<100,000
212
25.4
25.4
25.4
100-300,000
406
48.6
48.6
74.0
300,000-500,000
147
17.6
17.6
91.6
>500,000
70
8.4
8.4
100.0
Total
835
100.0
100.0
The statistics in Table 4.3 are similar to the percentages in the NielsenMobile survey results (2009) with 73% of mobile phone users having medium spending levels and only 13% having high spending levels.
The survey results also showed that up to 31% ~ nearly one-third of respondents said they sent more than 10 SMS messages/day, meaning that on average they sent 1 SMS message for every working hour. Those with an average SMS message volume (from 3 to 10 messages/day) accounted for 51.1% and those with a low SMS message volume (less than 3 messages/day) accounted for 17%. (Table 4.4)
Table 4.4: Number of SMS messages sent per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
142
17.0
17.0
17.0
3-10 news
427
51.1
51.1
68.1
>10 news
266
31.9
31.9
100.0
Total
835
100.0
100.0
Similar to sending messages, those with an average message receiving rate (from 3-10 messages/day) accounted for the highest percentage of ~ 55%, followed by those with a high number of messages (over 10 messages/day) ~ 24% and those with a low number of messages received daily (under 3 messages/day) remained at the bottom with 21%. (Table 4.5)
Table 4.5: Number of SMS messages received per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
175
21.0
21.0
21.0
3-10 news
436
55.0
55.0
76.0
>10 news
197
24.0
24.0
100.0
Total
835
100.0
100.0
When comparing the data of the two result tables 4.4 and 4.5, we can see the reasonableness between the ratio of the number of messages sent and the number of messages received daily by the interview participants.
4.3 Current status of SMS advertising and Mobile Marketing
According to the interview results, in the 3 months from the time of the survey and before, 94% of respondents, equivalent to 785 people, said they received advertising messages, while only a very small percentage of 6% (only 50 people) did not receive advertising messages (Table 4.6).
Table 4.6: Percentage of people receiving advertising messages in the last 3 months
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Have
785
94.0
94.0
94.0
Are not
50
6.0
6.0
100.0
Total
835
100.0
100.0
The results of Table 4.6 show that consumers in the inner city of Hanoi are very familiar with advertising messages. This result is also the basis for assessing the knowledge, experience and understanding of the respondents in the interview. This is also one of the important factors determining the accuracy of the survey results.
In addition, most respondents said they had received promotional messages, but only 24% of them had ever taken the action of registering to receive promotional messages, while 76% of the remaining respondents did not register to receive promotional messages but still received promotional messages every day. This is the first sign indicating the weaknesses and shortcomings of lax management of this activity in Vietnam. (Table 4.7)
div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s15 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s16 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 5.5pt; vertical-align: 3pt; } div.maincontent .s17 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 8.5pt; } div.maincontent .s18 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s20 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s21 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s22 { color: black; font-family:"Courier New", monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s23 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s24 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s25 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s26 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s27 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 1.5pt; } div.maincontent .s28 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s29 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s30 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s31 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s32 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s33 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s36 { color: #F00; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s37 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s38 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 8.5pt; vertical-align: 5pt; } div.maincontent .s39 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s40 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 4pt; } div.maincontent .s41 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s42 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s43 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7.5pt; vertical-align: 5pt; } div.maincontent .s44 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s45 { color: #F00; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s46 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s47 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s48 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s49 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s50 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s51 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s52 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s53 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s54 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s55 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s56 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s57 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s58 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s59 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s60 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 13pt; } div.maincontent .s61 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s62 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s63 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .content_head2 { color: #F00; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s64 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s67 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s68 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s69 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s70 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; tex
Mobile Phone Usage in Hanoi Inner City Area
zt2i3t4l5ee
zt2a3gsconsumer,consumption,consumer behavior,marketing,mobile marketing
zt2a3ge
zc2o3n4t5e6n7ts
- Test the relationship between demographic variables and consumer behavior for Mobile Marketing activities
The analysis method used is the Chi-square test (χ2), with statistical hypotheses H0 and H1 and significance level α = 0.05. In case the P index (p-value) or Sig. index in SPSS has a value less than or equal to the significance level α, the hypothesis H0 is rejected and vice versa. With this testing procedure, the study can evaluate the difference in behavioral trends between demographic groups.
CHAPTER 4
RESEARCH RESULTS
During two months, 1,100 survey questionnaires were distributed to mobile phone users in the inner city of Hanoi using various methods such as direct interviews, sending via email or using questionnaires designed on the Internet. At the end of the survey, after checking and eliminating erroneous questionnaires, the study collected 858 complete questionnaires, equivalent to a rate of about 78%. In addition, the research subjects of the thesis are only people who are using mobile phones, so people who do not use mobile phones are not within the scope of the thesis, therefore, the questionnaires with the option of not using mobile phones were excluded from the scope of analysis. The number of suitable survey questionnaires included in the statistical analysis was 835.
4.1 Demographic characteristics of the sample
The structure of the survey sample is divided and statistically analyzed according to criteria such as gender, age, occupation, education level and personal income. (Detailed statistical table in Appendix 6)
- Gender structure: Of the 835 completed questionnaires, 49.8% of respondents were male, equivalent to 416 people, and 50.2% were female, equivalent to 419 people. The survey results of the study are completely consistent with the gender ratio in the population structure of Vietnam in general and Hanoi in particular (Male/Female: 49/51).
- Age structure: 36.6% of respondents are <23 years old, equivalent to 306 people. People from 23-34 years old
accounting for the highest proportion: 44.8% equivalent to 374 people, people aged 35-45 and >45 are 70 and 85 people equivalent to 8.4% and 10.2% respectively. Looking at the results of this survey, we can see that the young people - youth account for a large proportion of the total number of people participating in the survey. Meanwhile, the middle-aged people including two age groups of 35 - 45 and >45 have a low rate of participation in the survey. This is completely consistent with the reality when Mobile Marketing is identified as a Marketing service aimed at young people (people under 35 years old).
- Structure by educational level: among 835 valid responses, 541 respondents had university degrees, accounting for the highest proportion of ~ 75%, 102 had secondary school degrees, ~ 13.1%, and 93 had post-graduate degrees, ~ 11.9%.
- Occupational structure: office workers and civil servants are the group with the highest rate of participation with 39.4%, followed by students with 36.6%. Self-employed people account for 12%, retired housewives are 7.8% and other occupational groups account for 4.2%. The survey results show that the student group has the same rate as the group aged <23 at 36.6%. This shows the accuracy of the survey data. In addition, the survey results distributed by occupational criteria have a rate almost similar to the sample division rate in chapter 3. Therefore, it can be concluded that the survey data is suitable for use in analysis activities.
- Income structure: the group with income from 3 to 5 million has the highest rate with 39% of the total number of respondents. This is consistent with the income structure of Hanoi people and corresponds to the average income of the group of civil servants and office workers. Those
People with no income account for 23%, income under 3 million VND accounts for 13% and income over 5 million VND accounts for 25%.
4.2 Mobile phone usage in Hanoi inner city area
According to the survey results, most respondents said they had used the phone for more than 1 year, specifically: 68.4% used mobile phones from 4 to 10 years, 23.2% used from 1 to 3 years, 7.8% used for more than 10 years. Those who used mobile phones for less than 1 year accounted for only a very small proportion of ~ 0.6%. (Table 4.1)
Table 4.1: Time spent using mobile phones
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Alid
<1 year
5
.6
.6
.6
1-3 years
194
23.2
23.2
23.8
4-10 years
571
68.4
68.4
92.2
>10 years
65
7.8
7.8
100.0
Total
835
100.0
100.0
The survey indexes on the time of using mobile phones of consumers in the inner city of Hanoi are very impressive for a developing country like Vietnam and also prove that Vietnamese consumers have a lot of experience using this high-tech device. Moreover, with the majority of consumers surveyed having a relatively long time of use (4-10 years), it partly proves that mobile phones have become an important and essential item in people's daily lives.
When asked about the mobile phone network they are using, 31% of respondents said they are using the network of Vietel company, 29% use the network of
of Mobifone company, 27% use Vinaphone company's network and 13% use networks of other providers such as E-VN telecom, S-fone, Beeline, Vietnammobile. (Figure 4.1).
Figure 4.1: Mobile phone network in use
Compared with the announced market share of mobile telecommunications service providers in Vietnam (Vietel: 36%, Mobifone: 29%, Vinaphone: 28%, the remaining networks: 7%), we see that the survey results do not have many differences. However, the statistics show that there is a difference in the market share of other networks because the Hanoi market is one of the two main markets of small networks, so their market share in this area will certainly be higher than that of the whole country.
According to a report by NielsenMobile (2009) [8], the number of prepaid mobile phone subscribers in Hanoi accounts for 95% of the total number of subscribers, however, the results of this survey show that the percentage of prepaid subscribers has decreased by more than 20%, only at 70.8%. On the contrary, the number of postpaid subscribers tends to increase from 5% in 2009 to 19.2%. Those who are simultaneously using both types of subscriptions account for 10%. (Table 4.2).
Table 4.2: Types of mobile phone subscribers
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Prepay
591
70.8
70.8
70.8
Pay later
160
19.2
19.2
89.9
Both of the above
84
10.1
10.1
100.0
Total
835
100.0
100.0
The above figures show the change in the psychology and consumption habits of Vietnamese consumers towards mobile telecommunications services, when the use of prepaid subscriptions and junk SIMs is replaced by the use of two types of subscriptions for different purposes and needs or switching to postpaid subscriptions to enjoy better customer care services.
In addition, the majority of respondents have an average spending level for mobile phone services from 100 to 300 thousand VND (406 ~ 48.6% of total respondents). The high spending level (> 500 thousand VND) is the spending level with the lowest number of people with only 8.4%, on the contrary, the low spending level (under 100 thousand VND) accounts for the second highest proportion among the groups of respondents with 25.4%. People with low spending levels mainly fall into the group of students and retirees/housewives - those who have little need to use or mainly use promotional SIM cards. (Table 4.3).
Table 4.3: Spending on mobile phone charges
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<100,000
212
25.4
25.4
25.4
100-300,000
406
48.6
48.6
74.0
300,000-500,000
147
17.6
17.6
91.6
>500,000
70
8.4
8.4
100.0
Total
835
100.0
100.0
The statistics in Table 4.3 are similar to the percentages in the NielsenMobile survey results (2009) with 73% of mobile phone users having medium spending levels and only 13% having high spending levels.
The survey results also showed that up to 31% ~ nearly one-third of respondents said they sent more than 10 SMS messages/day, meaning that on average they sent 1 SMS message for every working hour. Those with an average SMS message volume (from 3 to 10 messages/day) accounted for 51.1% and those with a low SMS message volume (less than 3 messages/day) accounted for 17%. (Table 4.4)
Table 4.4: Number of SMS messages sent per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
142
17.0
17.0
17.0
3-10 news
427
51.1
51.1
68.1
>10 news
266
31.9
31.9
100.0
Total
835
100.0
100.0
Similar to sending messages, those with an average message receiving rate (from 3-10 messages/day) accounted for the highest percentage of ~ 55%, followed by those with a high number of messages (over 10 messages/day) ~ 24% and those with a low number of messages received daily (under 3 messages/day) remained at the bottom with 21%. (Table 4.5)
Table 4.5: Number of SMS messages received per day
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
<3 news
175
21.0
21.0
21.0
3-10 news
436
55.0
55.0
76.0
>10 news
197
24.0
24.0
100.0
Total
835
100.0
100.0
When comparing the data of the two result tables 4.4 and 4.5, we can see the reasonableness between the ratio of the number of messages sent and the number of messages received daily by the interview participants.
4.3 Current status of SMS advertising and Mobile Marketing
According to the interview results, in the 3 months from the time of the survey and before, 94% of respondents, equivalent to 785 people, said they received advertising messages, while only a very small percentage of 6% (only 50 people) did not receive advertising messages (Table 4.6).
Table 4.6: Percentage of people receiving advertising messages in the last 3 months
Frequency
Ratio (%)
Valid Percentage
Cumulative Percentage
Valid
Have
785
94.0
94.0
94.0
Are not
50
6.0
6.0
100.0
Total
835
100.0
100.0
The results of Table 4.6 show that consumers in the inner city of Hanoi are very familiar with advertising messages. This result is also the basis for assessing the knowledge, experience and understanding of the respondents in the interview. This is also one of the important factors determining the accuracy of the survey results.
In addition, most respondents said they had received promotional messages, but only 24% of them had ever taken the action of registering to receive promotional messages, while 76% of the remaining respondents did not register to receive promotional messages but still received promotional messages every day. This is the first sign indicating the weaknesses and shortcomings of lax management of this activity in Vietnam. (Table 4.7)
div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s13 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s14 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s15 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: 6pt; } div.maincontent .s16 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 5.5pt; vertical-align: 3pt; } div.maincontent .s17 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 8.5pt; } div.maincontent .s18 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; font-size: 14pt; } div.maincontent .s19 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; font-size: 14pt; } div.maincontent .s20 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s21 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s22 { color: black; font-family:"Courier New", monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s23 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s24 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s25 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s26 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s27 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 1.5pt; } div.maincontent .s28 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s29 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s30 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s31 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s32 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s33 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s36 { color: #F00; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s37 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s38 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 8.5pt; vertical-align: 5pt; } div.maincontent .s39 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s40 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 4pt; } div.maincontent .s41 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s42 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s43 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7.5pt; vertical-align: 5pt; } div.maincontent .s44 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s45 { color: #F00; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 10.5pt; } div.maincontent .s46 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 7pt; vertical-align: 5pt; } div.maincontent .s47 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 11pt; } div.maincontent .s48 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s49 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s50 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s51 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s52 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -2pt; } div.maincontent .s53 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s54 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; vertical-align: -1pt; } div.maincontent .s55 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; } div.maincontent .s56 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s57 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s58 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 14pt; } div.maincontent .s59 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s60 { color: #00F; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; font-size: 13pt; } div.maincontent .s61 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s62 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s63 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .content_head2 { color: #F00; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; } div.maincontent .s64 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 13pt; } div.maincontent .s67 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; } div.maincontent .s68 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 12pt; } div.maincontent .s69 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 12pt; } div.maincontent .s70 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; tex
Classification)
Entity
Extraction)
Figure 1.3: Main processing steps in the NLU pipeline [1]
In this pipeline, you can customize components from data preprocessing, language modeling, algorithms used for word segmentation and entity information extraction…
Extract information in pipelined
“12 month loan interest rate?”
{“loan”:”loan”,“term”:”12 months”}
Tokenizer
Entity extraction
Chunker
Name entity recognition
Part of Speech Tagger
Pipelined intent classification
“12 month loan interest rate?” {intent:” interest”}
Vectorization
Intent classification
12 month loan interest rate?
Natural Language Understanding (NLU)
For details on the processing steps, see model 1.4: In which the entity extraction step is the slot filling step in figure 1.3.
Figure 1.4: Processing steps in NLU [2]
To classify user intent, we need language modeling, which is the representation of language in a vector form that can be understood by machines (vectorization). The most popular method today is word embedding. Word embedding is the general name for a set of language models and feature learning methods in natural language processing (NLP), where words or phrases from the vocabulary are mapped to real-number vectors. Conceptually, it involves mathematically embedding from a space with one dimension for each word into a continuous vector space with much lower dimensions. Some popular representation methods such as Word2Vec, GloVe or the newer FastText will be introduced in the following section.
After language modeling including training input data for the bot, determining user intent from user questions based on the trained set is the intent classification or text classification step. In this step, we can use some techniques such as: Naive Bayes, Decision Tree (Random Forest), Vector Support Machine (SVM), Convolution Neural Network (CNN), Recurrent Neural Network (RNN), Long Short-Term Memory (LSTM, Bi-LSTM). Most current chatbots apply deep learning models such as RNN and LSTM to classify user intent. The biggest challenge for chatbots in this step is to identify multiple intents in a user statement. For example, if you say "hello, check my account balance", the bot must identify 2 intentions "hello" and "check balance" in the user statement. If the bot can understand and answer this type of question, it will make interacting with the bot more natural.
Next is the extraction of information in the user dialogue. The information to be extracted is usually in the form of numbers, strings or times and they must be declared and trained in advance.
Segmenting words (Tokenization or word segmentation): Word segmentation is a processing process aimed at determining the boundaries of words in a sentence. It can also be simply understood that word segmentation is the process of determining single words, compound words, etc. in a sentence. For language processing, in order to determine the grammatical structure of a sentence, to determine the word class of a word in a sentence, it is essential to determine which word is in the sentence. This problem seems simple to humans, but for computers, this is a very difficult problem to solve. Normally, languages separate words by spaces, but in Vietnamese, there are many compound words and phrases. For example, the compound word "account" is created by 2 single words "tai" and "khoan". There are a number of algorithms that support solving this problem such as the longest matching model, the extreme matching model, etc.
Maximum Matching, Hidden Markov Models (HMM) or CRF (conditional random field) model...
1.3.1 Determine user intent
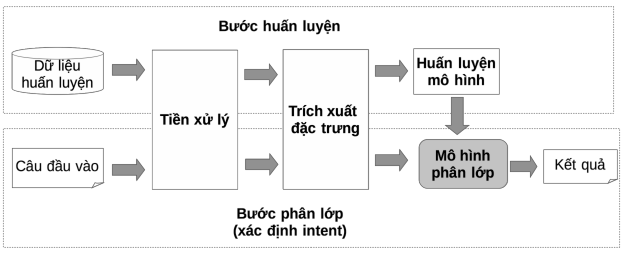
Figure 1.5: Model of steps to determine intention The user intention classification system has several basic steps:
Data preprocessing
Feature extraction
Model training
Classification
The data preprocessing step is the operation of “cleaning” the data such as: removing redundant information, standardizing data and converting misspelled words to correct spelling, standardizing abbreviations, etc. The data preprocessing step plays an important role in the chatbot system. If the input data is processed in this step, it will increase the accuracy and intelligence of the bot.
Next is the feature extraction step (feature extraction or feature engineering) from the cleaned data. In the traditional machine learning model (before the deep learning model was widely applied), the feature extraction step greatly affects the accuracy of the classification model. To extract good features, we need to analyze the data quite meticulously and also need expert knowledge in each specific application domain.
The training step takes as input the extracted features and applies machine learning algorithms to learn a classification model. The classification models can be classification rules (if using decision tree) or weight vectors.
corresponding to the extracted features (as in logistic regression, SVM, or Neural network models).
Once we have an intent classification model, we can use it to classify a new sentence. This sentence also goes through preprocessing and feature extraction steps, then the classification model will determine a “score” for each intent in the set of intents and give the highest-scoring intent.
To provide accurate support, chatbots need to identify the user's intent. Identifying the user's intent will determine how the next conversation between the person and the chatbot will take place. Therefore, if the user's intent is incorrectly identified, the chatbot will give incorrect, out-of-context responses. At that time, the user may feel annoyed and not return to use the system. The problem of identifying user intent therefore plays a very important role in the chatbot system.
For a closed application domain, we can limit the number of user intentions to a finite set of predefined intentions that are relevant to the tasks that the chatbot can support. With this limit, the problem of determining user intentions can be reduced to the problem of text classification. Given a user sentence as input, the classification system will determine the intent corresponding to that sentence in the set of predefined intents.
To build an intent classification model, we need a training dataset that includes different expressions for each intent. For example, the same intent asking about a user's account balance can use the following expressions:
Account information?
Account lookup?
Account balance?
How much money is in the account?
It can be said that the step of creating training data for the intent classification problem is one of the most important tasks when developing a chatbot system and greatly affects the quality of the chatbot system's products later. This task also requires a lot of time and effort from the chatbot developer.
1.4 Conversation Management (DM)
In long conversations between humans and chatbots, chatbots will need to remember contextual information or manage conversation states.
(dialog state). The issue of dialogue management is then important to ensure that the exchange between humans and machines is smooth.
The function of the dialogue management component is to receive input from the NLU component, manage dialogue states, dialogue contexts, and transmit output to the Natural Language Generation (NLG) component.
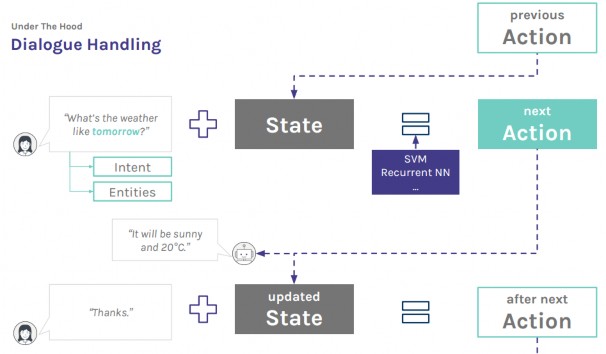
Figure 1.6: State management model and action decision in conversation [2]
The dialog state is saved and based on the dialog policy to decide the next action for the bot's response in a dialog scenario, or the action depends only on its previous dialog state.
For example, the dialogue management module in a chatbot serving airline ticket booking needs to know when the user has provided enough information for booking to create a ticket to the system or when it needs to reconfirm the information entered by the user. Currently, chatbot products often use the Finite State Automata (FSA) model, the Frame-based (Slot Filling) model, or a combination of these two models. Some new research directions apply the ANN model to dialogue management to help bots become smarter, see section 2.5 for details.
1.4.1 FSA finite state machine model
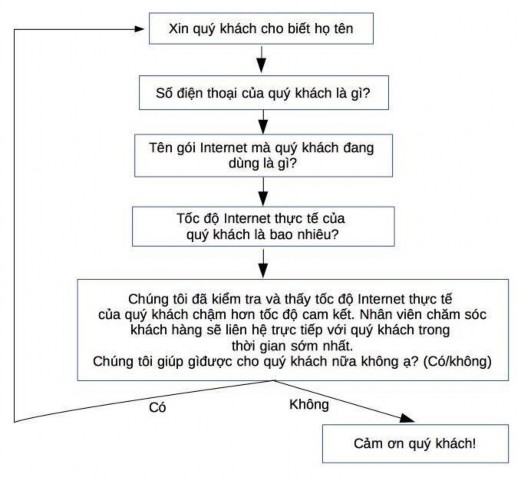
Figure 1.7: Conversation management based on FSA finite state machine model
The simplest FSA model manages dialogues. For example, a customer care system of a telecommunications company serves customers who complain about slow internet. The task of the chatbot is to ask the customer's name, phone number, the name of the Internet package the customer is using, and the actual Internet speed of the customer. The figure illustrates a dialogue management model for a customer care chatbot. The states of the FSA correspond to the questions that the dialogue manager asks the user. The arcs connecting the states correspond to the actions that the chatbot will perform. These actions depend on the user's response to the questions. In the FSA model, the chatbot is the user-oriented side of the conversation.
The advantage of the FSA model is that it is simple and the chatbot will predetermine the desired response format from the user. However, the FSA model is not really suitable for complex chatbot systems or when the user provides different information in the same conversation. In the chatbot example above, when the user provides both name and phone number at the same time, if the chatbot continues to ask for the phone number, the user may feel annoyed.
1.4.2 Frame-based model
The Frame-based model (or Form-based model) can solve the problem that the FSA model encounters. The Frame-based model relies on pre-defined frames to guide the conversation. Each frame will include information (slots) to be filled in and corresponding questions that the dialogue manager asks the user. This model allows the user to fill in information in many different slots in the frame. The figure above is an example of a frame for a chatbot.
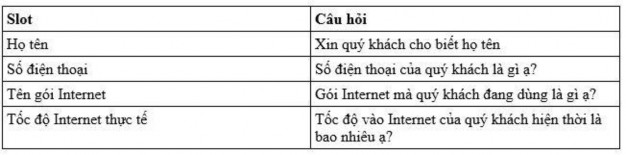
Figure 1.8: Frame for chatbot asking for customer information
The Frame-based dialogue management component will ask questions to customers, fill in the slots based on the information provided by the customer until it has enough necessary information. When the user answers multiple questions at the same time, the system will have to fill in the corresponding slots and remember to not ask questions that have already been answered.
In complex application domains, a conversation may have multiple frames. The problem for chatbot developers is how to know when to switch between frames. A common approach to managing the transfer of control between frames is to define production rules. These rules are based on a number of factors such as the most recent conversational statement or question asked by the user.
1.5 Generative Language Components (NLG)
NLG is the response generation component of a chatbot. It relies on mapping the actions of the conversation manager into natural language to respond to the user.

There are 4 commonly used mapping methods: Template-Base, Plan-based, Class-base, RNN-base
1.5.1 Template-based NLG
This answer mapping method uses predefined bot answer templates to generate answers.

Figure 1.9: Language generation method based on response sample set [1]
- Advantages : simple, easy to control. Suitable for closed domain problems.
- Disadvantages : time consuming to define rules, not natural in the answer. For large systems, it is difficult to control the rules, leading to the system being difficult to develop and maintain.
1.5.2 Plan-based NLG
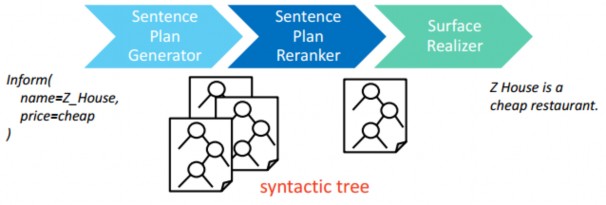
Figure 1.10: Plan-based language generation method [1]
- Advantages: Can model complex language structures
- Disadvantages: Heavy design, requires clear knowledge domain