Natural Language Processing Foundation
2.2.1. Semantic search
Semantic search is a term used to describe search engines that can understand natural language queries and can go beyond that by understanding the context of the searcher at the time they type the query. A simple example would be: if the query is “jaguar fuel consumption” then there is a high chance that the word “jaguar” means they are looking for information about a car rather than an animal.
Key elements of semantic search:
- Understand natural language
- Context of the query stream
- User context
- Entity recognition

Figure 11: Four important factors in Semantic search
Having a better understanding of user intent maximizes the chances of users having the best search experience. And that’s how search engines are known.
in the world like Google, Bing, Baidu... can bring you the information closest to what you need.
2.2.2. TF-IDF
TF-IDF stands for term frequency – inverse document frequency, which is an index to evaluate the importance of a word to a text or a document set. TF-IDF is often used in information retrieval and data mining problems [2] [3] [4].
2.2.2.1. TF – term frequency
This is the frequency of a word appearing in a text, calculated using the formula:
𝑡𝑓(𝑡, 𝑑) =
𝑓(𝑡, 𝑑)
max {𝑓(𝑤, 𝑑) ∶ 𝑤 ∈ 𝑑}
In there:
- f(t,d): number of times word t appears in text d
- max {𝑓(𝑤, 𝑑) ∶ 𝑤 ∈ 𝑑} : the maximum number of occurrences of any word in the text
- the value of tf(t,d) will be in the range [0, 1]
2.2.2.2. IDF – inverse document frequency
This is the inverse frequency of a word in a corpus, this index is intended to reduce the value of common words. Each word has only one IDF value in a corpus and is calculated using the formula:
In there:
𝑖𝑑𝑓(𝑡, 𝐷) = 𝑙𝑜𝑔
|𝐷|
|{𝑑 ∈ 𝐷 ∶ 𝑡 ∈ 𝑑}|
- |D|: total number of documents in set D
- |{𝑑 ∈ 𝐷 ∶ 𝑡 ∈ 𝑑}| : number of documents containing a certain word, with the condition that t appears in document d, i.e.: 𝑡𝑓(𝑡, 𝑑) ≠ 0 . If the word does not appear in any document in
the denominator will be 0 => division by zero is invalid, so people often replace it with the denominator 1 + |{𝑑 ∈ 𝐷 ∶ 𝑡 ∈ 𝑑}| .
2.2.2.3. TF-IDF value
𝑡𝑓𝑖𝑑𝑓(𝑡, 𝑑, 𝐷) = 𝑡𝑓(𝑡, 𝑑) 𝑥 𝑖𝑑𝑓(𝑡, 𝐷)
Words with high TF-IDF values are words that appear frequently in this document, and appear less frequently in other documents. This helps filter out common words and keep high-value words (keywords of that document).
2.2.3. Word segmentation
Word segmentation is the problem of splitting an input string of characters into independent words.
In English and some other languages that use the Latin alphabet, spaces are a good way to separate words in sentences. However, not all languages have such separators. In Thai and Lao, phrases and sentences are separated but words are not. In Chinese and Japanese, there are sentence separators but no word separators. In Vietnamese, the word separators are separated by syllables. Therefore, the problem of word segmentation is quite difficult.
For example:
Language
Input text | Result | |
English | I am looking for my pen. | I am looking_for my_pen |
Vietnamese | Students learn biology | student student_study |
Japanese | I will continue to work | Next |
… |
Maybe you are interested!
-

 Smart knowledge search system on wikihow domain - 9
Smart knowledge search system on wikihow domain - 9 -
 Integrating word morphology information into English-Vietnamese statistical machine translation system - 1
Integrating word morphology information into English-Vietnamese statistical machine translation system - 1 -
 Car body electrical practice - 8
zt2i3t4l5ee
zt2a3gs
zt2a3ge
zc2o3n4t5e6n7ts
If the voltage is out of specification, replace the wire or connector.
If the voltage is within specification, install the front fog light relay and follow step 5.
Step 5 Check the front fog light switch
- Remove the D4 connector of the fog light switch
- Use a multimeter to measure the resistance of the front fog light switch.
Measurement location
Condition
Standard
D4-3 (BFG) -D4-4 (LFG)
Light switchFront Fog OFF
>10kΩ
D4-3 (BFG) -D4-4 (LFG)
Front fog light switchON
<1 Ω
- Standard resistor
D4 connector is located on the combination switch assembly.
If the resistance is out of specification, replace the combination switch (the fog light switch is located in the combination switch).
If the resistance is within specification, follow step 6.
Step 6 Check wiring and connectors (front fog light relay-light selector switch)
- Disconnect connector D4 of the combination switch assembly
- Use a voltmeter to measure the voltage value of jack D4 on the wire side.
Measurement location
Control modecontrol
Standard
D4-3 (BFG) - (-) AQ
TAIL
11 to 14 V
D4 connector for the wiring of the combination switch assembly
If the voltage does not meet the standard, replace the wire or connector.
If the voltage is within standard, there may have been an error in the previous measurements.
Step 7 Check the front fog lights
- Remove the front fog light electrical connector.
- Supply battery voltage to the fog lamp terminals
Jack 8, B9 of front fog lamp on the electrical side
blind first.
Power supply location
Terms and Conditions
Battery positive terminal - Terminal 2Battery negative terminal - Terminal 1
Fog lightsbefore morning
- If the light does not come on, replace the bulb.
If the light is on, re-plug the jack and continue to step 8.
Step 8 Check wiring and connectors (relay and front fog lights)
- Disconnect the B8 and B9 connectors of the front fog lights.
- Use a voltmeter to measure voltage at the following locations:
Measurement location
Switch location
Terms and Conditions
B8-2 - (-) AQ
Electric lock ON TAIL size switchFog switch ON
11 to 14 V
B9-2 - (-) AQ
Electric lock ONTAIL size switch Fog switch ON
11 to 14 V
B8 and B9 connectors on the front fog lamp wiring side
Voltage is not up to standard, repair or replace the jack. If up to standard, there may have been an error in the measurement process.
2.2.4. Procedure for removing, installing and adjusting fog lights 1. Procedure for removing
- Remove the front inner ear pads
Use a screwdriver to remove the 3 screws and remove the front part of the front inner ear liner
-Remove the fog light assembly
+ Disconnect the connector.
+ Use a screwdriver to remove 3 screws to remove the fog light cover
2. Installation sequence
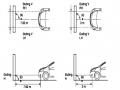
-Rotate the fog lamp bulb in the direction indicated by the arrow as shown in the figure and remove the fog lamp from the fog lamp assembly.
-Rotate the fog light bulb in the direction indicated by the arrow as shown in the figure and install the light into the fog light assembly.
- Use a screwdriver to install the fog light cover
-Install the electrical connector
Attention: Be careful not to damage the plastic thread on the lamp assembly.
- Install the front inner ear pads
Use a screwdriver to install the front inner bumper with 3 screws.
3. Prepare the vehicle to adjust the fog light convergence. Prepare the vehicle:
- Make sure there is no damage or deformation to the vehicle body around the fog lights.
- Add fuel to the fuel tank
- Add oil to standard level.
- Add engine coolant to standard level.
- Inflate the tire to standard pressure.
- Place spare tire, tools and jack in original design position
- Do not leave any load in the luggage compartment.
- Let a person weighing about 75 kg sit in the driver's seat.
4. Prepare to check the fog light convergence
a/ Prepare the vehicle status as follows:
- Place the car in a dark enough place to see the lines. The lines are the dividing line, below which the light from the fog lights can be seen but above which it cannot.
- Place the car perpendicular to the wall.
- Keep a distance of 7.62 m between the center of the fog lamp and the wall.
- Park the car on level ground.
- Press the car down a few times to stabilize the suspension.
Note: A distance of approximately 7.62 m is required between the vehicle (fog lamp center) and the wall to adjust the convergence correctly. If the distance of 7.62 m cannot be achieved, set the correct distance of 3 m to check and adjust the fog lamp convergence. (Since the target area varies with the distance, please follow the instructions as shown in the figure.)
b/ Prepare a piece of thick white paper about 2 m high and 4 m wide to use as a screen.
c/ Draw a vertical line through the center of the screen (line V).
d/ Set the screen as shown in the picture. Note:
- Keep the screen perpendicular to the ground.
- Align the V line on the screen with the center of the vehicle.
e/Draw the reference lines (H, V LH and V RH lines) on the screen as shown in the figure.HINT:
Mark the center of the fog lamp on the screen. If the center mark cannot be seen on the fog lamp, use the center of the fog lamp or the manufacturer's name mark on the fog lamp as the center mark.
H line (fog light height):
Draw a line across the screen so that it passes through the center mark. Line H should be at the same height as the center mark of the fog light bulb.
Line V LH, V RH (center mark position of left fog lamp LH and right fog lamp RH):
Draw two lines so that they intersect line H at the center marks.
5. Check the fog light convergence
a/ Cover the fog lamp or remove the connector of the other side fog lamp to prevent light from the unchecked fog lamp from affecting the fog lamp convergence test.
b/ Start the engine.
c/ Turn on the fog lights and make sure that the dividing line is outside the standard area as shown in the drawing.
6. Adjust the fog light convergence
Use a screwdriver to adjust the fog light to the standard area by turning the toe adjustment screw.
Note: If the screw is adjusted too far, loosen it and then tighten it again, so that the last rotation of the light adjustment screw is clockwise.
3. Self-study questions
1. Describe the operating principle of the lighting system with automatic headlight function
2. Describe the operating principle of the lighting system with the function of rotating headlights when turning
3. Draw diagram and connect lighting system on Hyundai Porter car
4. Draw diagram and connect lighting system on Honda Accord 1992
5. Draw the lighting circuit on a 1993 Toyota Lexus
LESSON 3 MAINTENANCE AND REPAIR OF SIGNAL SYSTEM
I. IMPLEMENTATION GOAL
After completing this lesson, students will be able to:
- Distinguish between types of signals on cars
- Correctly describe common symptoms and suspected areas causing damage.
- Connecting signal circuits ensures technical requirements
- Disassemble, install, check, maintain and repair the signal system to ensure technical requirements.
- Ensure safety in work and industrial hygiene
II. LESSON CONTENT
1. General description
The signal system equipped on cars aims to create signals to notify other vehicles participating in traffic about the vehicle's operating status such as: stopping, parking, braking, reversing, turning...
Signals are used either by light such as headlamps, brake lights, turn signals….. or by sound such as horns, reverse music….
Just like the lighting system. A signal system circuit usually consists of: battery, fuse, wire, relay, electrical load and control switch. Only some switches of the signal system are on the combination switch. The switches of other signals are usually located in different locations such as in the gearbox or brake pedal……
2. Maintenance and repair
2.1. Turn signals and hazard lights
The installation location of the turn signal is shown in Figure 3.1. The turn signal control switch is located in the combination switch under the steering wheel. Turning this switch to the right or left will make the turn signal turn right or left.
The hazard light switch is used when the vehicle has a problem while participating in traffic. When the hazard light switch is turned on, all the turn signals on the vehicle will light up at a certain frequency. The hazard light switch is usually placed separately from the turn signal switch (some old cars integrate the hazard and turn signal switches on the same combination switch cluster).
Figure 3.1 Turn signal switch Figure 3.2 Hazard switch
The part that generates the flashing frequency for the lights is called a turn signal relay. The turn signal relay usually has 3 terminals: B (positive power supply); E (negative power supply); L (providing the turn signal switch to distribute to the
lamp)
2.1.1. Circuit diagram
To generate the frequency for the turn signal, a turn signal relay is used in the turn signal circuit. The current from the turn signal relay will be sent to the turn signal switch assembly to distribute the current to the turn signal lights for the driver's purpose.
Figure 3.3. Schematic diagram of a turn signal circuit without a hazard switch
1. Battery; 2. Electric lock; 3. Turn signal relay; 4. Turn signal switch; 5. Turn signal lamp; 6. Turn signal lamp; 7. Hazard switch
Figure 3.4 Schematic diagram of turn signal circuit with hazard switch
1. Battery; 2. Combination switch cluster; 3. Turn signal;
4. Turn signal light; 5. Turn signal relay
Today's cars no longer use three-pin turn signal relays (B, L, E) but use eight-pin turn signal relays (figure 3.5) (pin number 8 is used for hazard lights).
For this type, the current supplying the turn signal lights is supplied directly from the turn signal relay to the lights.
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; vertical-align: 1pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; vertical-align: -9pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s9 { color: #008000; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; te
Car body electrical practice - 8
zt2i3t4l5ee
zt2a3gs
zt2a3ge
zc2o3n4t5e6n7ts
If the voltage is out of specification, replace the wire or connector.
If the voltage is within specification, install the front fog light relay and follow step 5.
Step 5 Check the front fog light switch
- Remove the D4 connector of the fog light switch
- Use a multimeter to measure the resistance of the front fog light switch.
Measurement location
Condition
Standard
D4-3 (BFG) -D4-4 (LFG)
Light switchFront Fog OFF
>10kΩ
D4-3 (BFG) -D4-4 (LFG)
Front fog light switchON
<1 Ω
- Standard resistor
D4 connector is located on the combination switch assembly.
If the resistance is out of specification, replace the combination switch (the fog light switch is located in the combination switch).
If the resistance is within specification, follow step 6.
Step 6 Check wiring and connectors (front fog light relay-light selector switch)
- Disconnect connector D4 of the combination switch assembly
- Use a voltmeter to measure the voltage value of jack D4 on the wire side.
Measurement location
Control modecontrol
Standard
D4-3 (BFG) - (-) AQ
TAIL
11 to 14 V
D4 connector for the wiring of the combination switch assembly
If the voltage does not meet the standard, replace the wire or connector.
If the voltage is within standard, there may have been an error in the previous measurements.
Step 7 Check the front fog lights
- Remove the front fog light electrical connector.
- Supply battery voltage to the fog lamp terminals
Jack 8, B9 of front fog lamp on the electrical side
blind first.
Power supply location
Terms and Conditions
Battery positive terminal - Terminal 2Battery negative terminal - Terminal 1
Fog lightsbefore morning
- If the light does not come on, replace the bulb.
If the light is on, re-plug the jack and continue to step 8.
Step 8 Check wiring and connectors (relay and front fog lights)
- Disconnect the B8 and B9 connectors of the front fog lights.
- Use a voltmeter to measure voltage at the following locations:
Measurement location
Switch location
Terms and Conditions
B8-2 - (-) AQ
Electric lock ON TAIL size switchFog switch ON
11 to 14 V
B9-2 - (-) AQ
Electric lock ONTAIL size switch Fog switch ON
11 to 14 V
B8 and B9 connectors on the front fog lamp wiring side
Voltage is not up to standard, repair or replace the jack. If up to standard, there may have been an error in the measurement process.
2.2.4. Procedure for removing, installing and adjusting fog lights 1. Procedure for removing
- Remove the front inner ear pads
Use a screwdriver to remove the 3 screws and remove the front part of the front inner ear liner
-Remove the fog light assembly
+ Disconnect the connector.
+ Use a screwdriver to remove 3 screws to remove the fog light cover
2. Installation sequence
-Rotate the fog lamp bulb in the direction indicated by the arrow as shown in the figure and remove the fog lamp from the fog lamp assembly.
-Rotate the fog light bulb in the direction indicated by the arrow as shown in the figure and install the light into the fog light assembly.
- Use a screwdriver to install the fog light cover
-Install the electrical connector
Attention: Be careful not to damage the plastic thread on the lamp assembly.
- Install the front inner ear pads
Use a screwdriver to install the front inner bumper with 3 screws.
3. Prepare the vehicle to adjust the fog light convergence. Prepare the vehicle:
- Make sure there is no damage or deformation to the vehicle body around the fog lights.
- Add fuel to the fuel tank
- Add oil to standard level.
- Add engine coolant to standard level.
- Inflate the tire to standard pressure.
- Place spare tire, tools and jack in original design position
- Do not leave any load in the luggage compartment.
- Let a person weighing about 75 kg sit in the driver's seat.
4. Prepare to check the fog light convergence
a/ Prepare the vehicle status as follows:
- Place the car in a dark enough place to see the lines. The lines are the dividing line, below which the light from the fog lights can be seen but above which it cannot.
- Place the car perpendicular to the wall.
- Keep a distance of 7.62 m between the center of the fog lamp and the wall.
- Park the car on level ground.
- Press the car down a few times to stabilize the suspension.
Note: A distance of approximately 7.62 m is required between the vehicle (fog lamp center) and the wall to adjust the convergence correctly. If the distance of 7.62 m cannot be achieved, set the correct distance of 3 m to check and adjust the fog lamp convergence. (Since the target area varies with the distance, please follow the instructions as shown in the figure.)
b/ Prepare a piece of thick white paper about 2 m high and 4 m wide to use as a screen.
c/ Draw a vertical line through the center of the screen (line V).
d/ Set the screen as shown in the picture. Note:
- Keep the screen perpendicular to the ground.
- Align the V line on the screen with the center of the vehicle.
e/Draw the reference lines (H, V LH and V RH lines) on the screen as shown in the figure.HINT:
Mark the center of the fog lamp on the screen. If the center mark cannot be seen on the fog lamp, use the center of the fog lamp or the manufacturer's name mark on the fog lamp as the center mark.
H line (fog light height):
Draw a line across the screen so that it passes through the center mark. Line H should be at the same height as the center mark of the fog light bulb.
Line V LH, V RH (center mark position of left fog lamp LH and right fog lamp RH):
Draw two lines so that they intersect line H at the center marks.
5. Check the fog light convergence
a/ Cover the fog lamp or remove the connector of the other side fog lamp to prevent light from the unchecked fog lamp from affecting the fog lamp convergence test.
b/ Start the engine.
c/ Turn on the fog lights and make sure that the dividing line is outside the standard area as shown in the drawing.
6. Adjust the fog light convergence
Use a screwdriver to adjust the fog light to the standard area by turning the toe adjustment screw.
Note: If the screw is adjusted too far, loosen it and then tighten it again, so that the last rotation of the light adjustment screw is clockwise.
3. Self-study questions
1. Describe the operating principle of the lighting system with automatic headlight function
2. Describe the operating principle of the lighting system with the function of rotating headlights when turning
3. Draw diagram and connect lighting system on Hyundai Porter car
4. Draw diagram and connect lighting system on Honda Accord 1992
5. Draw the lighting circuit on a 1993 Toyota Lexus
LESSON 3 MAINTENANCE AND REPAIR OF SIGNAL SYSTEM
I. IMPLEMENTATION GOAL
After completing this lesson, students will be able to:
- Distinguish between types of signals on cars
- Correctly describe common symptoms and suspected areas causing damage.
- Connecting signal circuits ensures technical requirements
- Disassemble, install, check, maintain and repair the signal system to ensure technical requirements.
- Ensure safety in work and industrial hygiene
II. LESSON CONTENT
1. General description
The signal system equipped on cars aims to create signals to notify other vehicles participating in traffic about the vehicle's operating status such as: stopping, parking, braking, reversing, turning...
Signals are used either by light such as headlamps, brake lights, turn signals….. or by sound such as horns, reverse music….
Just like the lighting system. A signal system circuit usually consists of: battery, fuse, wire, relay, electrical load and control switch. Only some switches of the signal system are on the combination switch. The switches of other signals are usually located in different locations such as in the gearbox or brake pedal……
2. Maintenance and repair
2.1. Turn signals and hazard lights
The installation location of the turn signal is shown in Figure 3.1. The turn signal control switch is located in the combination switch under the steering wheel. Turning this switch to the right or left will make the turn signal turn right or left.
The hazard light switch is used when the vehicle has a problem while participating in traffic. When the hazard light switch is turned on, all the turn signals on the vehicle will light up at a certain frequency. The hazard light switch is usually placed separately from the turn signal switch (some old cars integrate the hazard and turn signal switches on the same combination switch cluster).
Figure 3.1 Turn signal switch Figure 3.2 Hazard switch
The part that generates the flashing frequency for the lights is called a turn signal relay. The turn signal relay usually has 3 terminals: B (positive power supply); E (negative power supply); L (providing the turn signal switch to distribute to the
lamp)
2.1.1. Circuit diagram
To generate the frequency for the turn signal, a turn signal relay is used in the turn signal circuit. The current from the turn signal relay will be sent to the turn signal switch assembly to distribute the current to the turn signal lights for the driver's purpose.
Figure 3.3. Schematic diagram of a turn signal circuit without a hazard switch
1. Battery; 2. Electric lock; 3. Turn signal relay; 4. Turn signal switch; 5. Turn signal lamp; 6. Turn signal lamp; 7. Hazard switch
Figure 3.4 Schematic diagram of turn signal circuit with hazard switch
1. Battery; 2. Combination switch cluster; 3. Turn signal;
4. Turn signal light; 5. Turn signal relay
Today's cars no longer use three-pin turn signal relays (B, L, E) but use eight-pin turn signal relays (figure 3.5) (pin number 8 is used for hazard lights).
For this type, the current supplying the turn signal lights is supplied directly from the turn signal relay to the lights.
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; } div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; } div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; vertical-align: 1pt; } div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; vertical-align: -9pt; } div.maincontent .s8 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; } div.maincontent .s9 { color: #008000; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; } div.maincontent .s10 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; te -
 The Nature and Role of the Internal Control System
The Nature and Role of the Internal Control System -
 Some Solutions to Improve the Legal System of Alimony
Some Solutions to Improve the Legal System of Alimony
Table 3: Word Segmentation in Different Languages
There are many approaches to solve this problem [5].
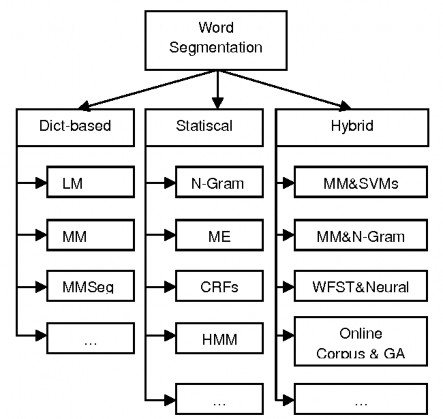
Figure 12: Approaches to the word segmentation problem
These methods are classified into three main groups:
- Dict-based: is to create a dictionary and split the input text into words in that dictionary. The two most effective approaches of this method are Maximun Matching and Longest Matching.
- Statiscal: relies on the use of a very large labeled dataset. Some popular methods are N-gram Language Model [6], Hidden Markov Model (HMM) [7], Conditional Random Fields (CRFs) [8] and Maximum Entropy (ME) [9].
- Hybrid: is a combination of different methods to take advantage of the advantages of each method and limit their disadvantages. Many hybrid models have been published and applied to many different languages. They include dictionary-based techniques (Maximun Matching, Longest Matching), statistics-based (N-
gram, CRFs, ME) and machine learning algorithms (Support Vector Machines - SVMs, Genetic Algorithm - GA) [10] [11] [12].
2.2.4. Part of speech tagging (POStag)
POSTag, also known as grammatical tagging, is the process of marking a word in a text as corresponding to a part of speech, based on both the definition and the context, the relationship of that word to surrounding words and related words in phrases, sentences, paragraphs. For example, some word classes in English are nouns, prepositions, pronouns, conjunctions, verbs, adjectives, adverbs, etc. One of the mandatory preprocessing steps of POSTag is word segmentation.
The problem with POS tagging is that it handles ambiguity, choosing the right tag for the right context. For example, the word “stone” in the sentence “This horse is made of stone” is a noun, but in the sentence “The children are playing soccer” it is a verb.
Some examples of POSTag:
- Input text: Student student student_study
- Result after labeling word types: Student/N learn/V student/N (Where /N is noun, /V is verb)
Support tools
2.3.1. VnCoreNLP
VnCoreNLP [13] is a Vietnamese language labeling toolkit, providing natural language processing tools such as: Word Segmentation, POS tagging, Named Entity Recognition and Dependency Parsing.
Features of VnCoreNLP:
- Accuracy: VnCoreNLP is a Vietnamese language processing toolkit with high accuracy. With a standard data set, VnCoreNLP gives a result higher than all previously published tools.
- Process large data sets in very fast time.
- Easy to deploy.
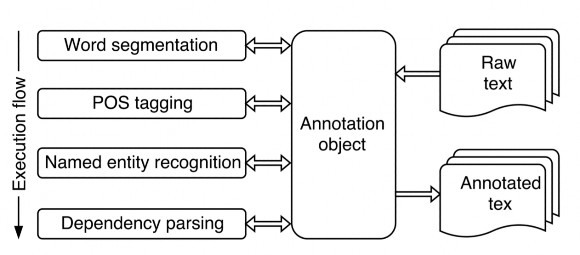
Figure 13: VnCoreNLP processing flow
2.3.2. Word2vec
Word2vec is a natural language processing technique. This algorithm uses a neural network model to learn associations from a large data set. After training a large enough set, this model can detect synonyms or can be applied to the problem of suggesting words for a word or a piece of text.
This technique assigns a vector value (a list of specific numbers) to each individual word. These vectors are calculated so that: the more similar two words are semantically, the higher the cosine similarity between the two vectors representing them.
Word2vec has two models, skip-grams and CBOW:
- Skip-grams is a model that predicts surrounding words. For example, when applying a window size of 3 to the sentence “I love you so much”, the set {(I, love), love}, {(love, so), you},
{(you, much), so}. When given the input word “love”, this model will predict the surrounding words “I” and “you”.
- CBOW (continuous bag of word), this model is the opposite of Skip-grams, that is, the input will be words and the model will calculate to predict words related to the input words.
In our experiments, CBOW trains data faster but the accuracy is not higher than skip-grams and vice versa, and we only apply one of the two models to train the data set.
2.3.3. Elasticsearch
As introduced, Elasticsearch is an open source distributed search engine for all types of data including text, numeric, geospatial, structured and unstructured. Elasticsearch provides RESTful APIs to perform tasks on separate servers so it can be easily integrated with any system.
Chapter 3
Knowledge search system on Wikihow domain
Calculate similarity between two sentences
In this thesis, I propose a method to calculate the similarity between two sentences based on the Jaccard Similarity index.
The Jaccard index, also known as the similarity coefficient, can be used to calculate the similarity between finite sets of samples (in which the elements are not duplicated) and is defined as the size of the intersection divided by the size of the union of the sample sets.
The mathematical expression of the index is represented as follows:
𝐽(𝐴, 𝐵) =
|𝐴 ∩ 𝐵|
=
|𝐴 ∪ 𝐵|
|𝐴 ∩ 𝐵|
|𝐴| + |𝐵| − |𝐴 ∩ 𝐵|
The value will be in the range [0, 1] and equal to 1 when these two sets have identical elements.
This index can be applied to calculate the similarity between two sentences when we consider each word in the sentence as an element in a set of words that are not duplicated. But if we simply find the elements in the two sets of words that need to be compared to see if they appear in the other set of words to calculate the number of intersecting words between the two sets, it will not solve the problem of synonyms. Here I want to say that, to calculate the similarity of two sentences based on Jaccard Similarity, the intersection part , in addition to calculating the number of words appearing in both sentences based on characters, must also calculate the semantic similarity. Therefore, I propose a formula to calculate the similarity for two character strings X and Y as follows: