Call the alignment from 𝑎 𝑗 : 𝑗 → 𝑖 linking the 𝑗th English word to the 𝑖th and 𝑎th Vietnamese words
is the set of conjunctions from all the words in the sentence e
𝑎 = 𝑎 1 , 𝑎, … 𝑎 𝑚
From the word alignment probability, we can calculate the translation probability according to the formula:
Maybe you are interested!
-

 Integrating word morphology information into English-Vietnamese statistical machine translation system - 1
Integrating word morphology information into English-Vietnamese statistical machine translation system - 1 -
 Proposing a Model for Developing Community-Based Tourism in Quan Lan Commune, Van Don, Quang Ninh.
Proposing a Model for Developing Community-Based Tourism in Quan Lan Commune, Van Don, Quang Ninh. -
 Assessing the current status and proposing a community-based mangrove conservation model in Le Loi commune, Hoanh Bo district, Quang Ninh province - 15
Assessing the current status and proposing a community-based mangrove conservation model in Le Loi commune, Hoanh Bo district, Quang Ninh province - 15 -
 Situational-Based Interactive Learning Model - Research
Situational-Based Interactive Learning Model - Research -
 Assessing the current status and proposing a community-based mangrove conservation model in Le Loi commune, Hoanh Bo district, Quang Ninh province - 14
Assessing the current status and proposing a community-based mangrove conservation model in Le Loi commune, Hoanh Bo district, Quang Ninh province - 14
𝑝 𝑣 𝑒 = 𝑝 𝑎, 𝑒 𝑣
𝑎
(2.6)
The probability of word alignment between words in the sentence pair, 𝑝 𝑎, 𝑒 𝑣 is calculated as follows:
𝑚
𝑝 𝑎, 𝑒 𝑣 = 𝑡 𝑒 𝑗𝑣 𝑖
𝑗 =1
(2.7)
In which, 𝑡 𝑒 𝑗𝑣 𝑖is calculated based on the word (language) alignments in the bilingual corpus. However, generating the word (language) alignment corpus requires a lot of effort for labeling. Therefore, the Expectation Maximization (EM) algorithm was proposed in [24] to estimate these word (language) alignments.
The idea of the EM algorithm is as follows:
First, for every pair of bilingual sentences in the corpus, we assume that all words in the source sentence have word alignment with all words in the target sentence, and the word alignment probabilities are initialized to the same value.
… my house … small house … my mobile …
… my house … small house … my phone …
Then, over each iteration, the most frequently aligned word pairs are identified.
The link between “my” and “mine” is determined:
… my house … small house … my mobile …
… my house … small house … my phone …
The link “house” and “home” is defined:
… my house … small house … my mobile …
… my house … small house … my phone …
Other links identified:
… my house … small house … my mobile …
… my house … small house … my phone …
Final word alignment result:
… my house … small house … my mobile …
… my house … small house … my phone …
Eventually, the word alignment probabilities will converge, and the values will not change much. Then we get both information about the word alignment and the corresponding probability values.
Using the EM algorithm, Stephan Vogel proposed IBM models named IBM1, IBM2, IBM3, IBM4, IBM5 respectively and Franz-Joseph Och proposed model 6 to generate word alignment on bilingual sentence pairs.
Currently, the most popular tool for word alignment is GIZA++. This tool is built on IBM models. However, this tool has the limitation of only allowing to align one word in the source language with one or more words in the target language.
[10] proposed a heuristic-based approach to improve the word alignment results obtained from GIZA++. All points located in the intersection region of two word alignments are retained and the word alignment region is expanded to a maximum not exceeding the intersection region of two word alignments.
First, the bilingual corpus is aligned from both directions, from the source language to the target language and from the target language to the source language. This process produces two word alignments. If we take the intersection of these two word alignments, we will get a high-precision word alignment. Conversely, if we take the union of the two word alignments, we will get a high-recall word alignment.
Figure 2.2 illustrates this process. In the figure, points within the intersection region are colored black, and points extending are colored gray.
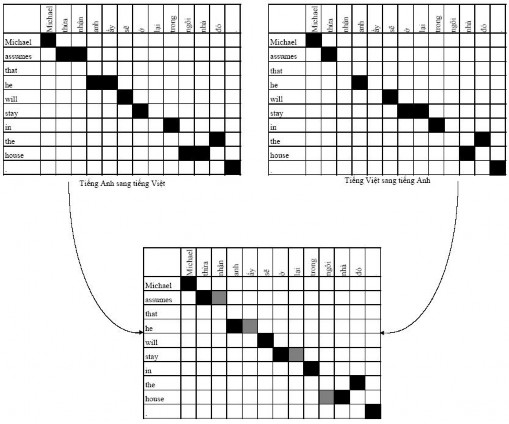
Figure 2.3. Illustration of the process of improving the alignment from
2.1.1.3.Decoding process
The task of this process is to find the most appropriate translation given the source sentence.
- Split the source sentence into several words or phrases.
- Look in the glossary to find the corresponding translations.
- Combine the found phrases into sentences and choose the sentences with the largest translation model probability multiplied by the language model probability.
2.1.2 . Statistical machine translation model based on language
The disadvantage of word-based statistical machine translation is that it does not take contextual information and is based only on statistical analysis of words. The semantic-based statistical machine translation model is more advanced in that it processes on the semantics instead of words. This allows the system to translate phrases that avoid word-by-word translation.
In the semantic-based statistical machine translation system [26], sentences in the source language e are
polyglot
(is a sequence of words, not necessarily grammatically correct)
(The punctuation mark is also considered as a word.) Each 𝑒 𝑖 phrase is translated into
The corresponding 𝑣 𝑖 is based on the probability distribution 𝜙(𝑒 𝑖|𝑣 𝑖 ) . Then the terms 𝑣 𝑖
will be
The order conversion is based on the conversion model 𝑑(𝑎 𝑖 − 𝑏 𝑖−1 ) , where 𝑎 𝑖 is the starting position of phrase 𝑒 𝑖 and 𝑏 𝑖−1 is the ending position of phrase 𝑣 𝑖 . Therefore, the statistical translation system on the language will learn bilingual phrase pairs, especially idiomatic sentences.
Thus, the best translation that satisfies formula (2.1) will be rewritten as:
𝑚
𝑝 𝑒 𝑖𝑣 𝑖= 𝜙(𝑒 𝑖|𝑣 𝑖 ) × 𝑑(𝑎 𝑖 − 𝑏 𝑖−1 )
𝑖=1
(2.6)
takes a
small green box
.
little blue box
.
She
Figure 2.4 illustrates the process of statistical machine translation based on phrases. The English input sentence is broken down into many phrases, also known as phrases. The phrases are translated into the corresponding Vietnamese phrases, and the output Vietnamese phrases can change the order in the sentence to match Vietnamese.
She
take one
Figure 2.4. Example of semantic-based statistical translation
Because of the statistics on pairs of words, this translation system can convert the order between words in a sentence, but it still cannot automatically convert the order of phrases that are far apart in a sentence.
There are different ways to extract word pairs from bilingual corpora. [16] tested the following three methods:
i. Get the word based on the word alignment results
The author uses the GIZA++ tool to align words in the bilingual corpus. Then, Koehn uses some heuristics to further improve the alignment results and get all the pairs of words containing linked words. Then, 𝜙(𝑒 𝑖|𝑣 𝑖 ) is calculated as follows:
𝜙𝑒𝑣= 𝑐𝑜𝑢𝑛𝑡(𝑒 |𝑣 )
ii. Syntactic Separation
𝑖 𝑖
𝑒 𝑐𝑜𝑢𝑛𝑡(𝑒 |𝑣 )
(2.7)
First, the author aligns the words for the bilingual sentence pairs, then analyzes the sentence pairs into a syntax tree. The author extracts the bilingual language pairs by taking the word strings that are in the subtree of the syntax tree and have word alignment links. The translation probability of the language pair is calculated similarly to the above model.
iii. Using the combined model proposed by Marcu, D. and Wong, W: Direct phrase formation on bilingual corpus
Through experiments, the author concluded that the word alignment based model gives the best results among the three models.
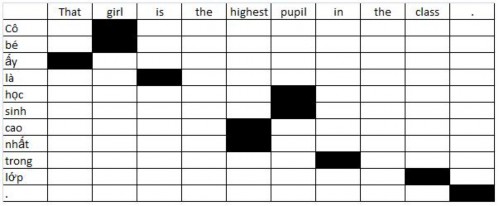
Consider the pair of bilingual sentences:
That girl is the highest pupil in the class.
That girl is the tallest student in the class.
The model extracts the following pairs of words from the word alignment results: From the word alignment results of the sentence pair:
The extracted pairs of terms must be consistent as in figure (a), words that are linked to words in the source term are also included in the target term. The extraction in figure (b) is incorrect because the word “là” is linked to the word “is” but is not included in the term.

Initially, we can get the terms from the alignment links from

(That, that), (girl, cô bé), (is, là), (highest, cao nhất), (pupil, học sinh), (in, trong), (class, giá), (., .)
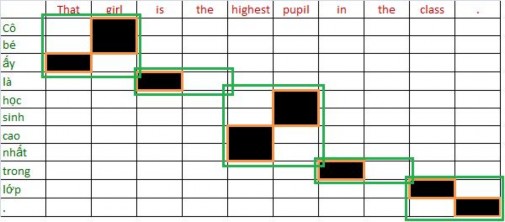
(That, that), (girl, Cô bé), (is, là), (highest, cao nhất), (pupil, học sinh), (in, trong), (class, lớp), (., .), (That girl, Cô bé mà), (is the, là), (highest pupil, học sinh cao nhất), (the class, trong học)
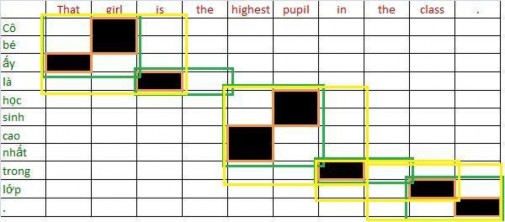
(That, that), (girl, Cô bé), (is, là), (highest, cao nhất), (pupil, học sinh), (in, trong), (class, lớp), (., .), (That girl, Cô bé mà), (is the, là), (highest pupil, học sinh cao nhất), (the class, trong học), (That girl is, Cô bé mà là), (highest pupil in, học sinh cao nhất trong), (in the class, trong học), (the class . , trong học .)
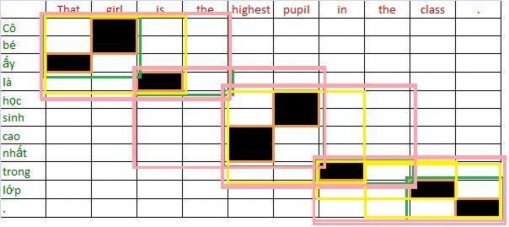
(That, that), (girl, Cô bé), (is, là), (highest, cao nhất), (pupil, học sinh), (in, trong), (class, lớp), (., .), (That girl, Cô bé mà), (is the, là), (highest pupil, học sinh cao nhất), (the class, trong học), (That girl is, Cô bé mà là), (highest pupil in, học sinh cao nhất trong), (in the class, trong học), (the class . , trong học .), (That girl is the, Cô bé mà là), (is the highest pupil, là học sinh cao nhất), (highest pupil in the, cao nhất trong), (in the class, trong học)