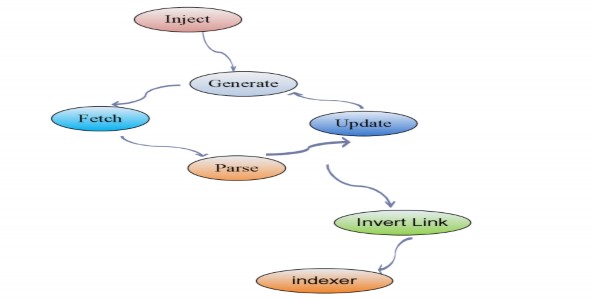
Figure 4-1: Crawler process
We proceed to create a short program to perform sequential work and measure the time of each stage. The code for measuring time is as follows:
start-time = now()
Execute Inject after_inject_time = now()
inject_duration = after_inject_time-start_time for (i=1; i<=depth; i++)
{
Record information for depth=i before_generate_time=now() Execute Generate after_generate_time=now()
generate_duration=after_generate_time – before_generate_time Perform Fetch
after_fetch_time = now()
fetch_duration = after_fetch_time - after_generate_time Perform Parse
after_parse_time = now()
parse_duration = after_parse_time – after_fetch_time Perform Update CrawlDB
after_update_time = now()
update_duration = after_update_time – after_parse_time Record the total number of URLs fetched by the parser
}
before_invert_time = now() Execute Invert link after_invert_time = now()
invert_duration = after_invert_time – before_invert_time Perform index
after_index_time = now()
index_duration = after_index_time – after_invert_time total_duration = after_index_time – start_time
Perform crawling with the following conditions:
Condition
Value | Describe | |
Seek URLs | http://hcm.24h.com.vn | Start the original URL |
Depth | 3 | Repeat crawl loop 3 times |
URL Filter | +^http://([az)-9]*.)*24h.com.vn/ | Only URLs are accepted. belong to 24h.com.vn domain |
Maybe you are interested!
-
![Qos Assurance Methods for Multimedia Communications
zt2i3t4l5ee
zt2a3gs
zt2a3ge
zc2o3n4t5e6n7ts
low. The EF PHB requires a sufficiently large number of output ports to provide low delay, low loss, and low jitter.
EF PHBs can be implemented if the output ports bandwidth is sufficiently large, combined with small buffer sizes and other network resources dedicated to EF packets, to allow the routers service rate for EF packets on an output port to exceed the arrival rate λ of packets at that port.
This means that packets with PHB EF are considered with a pre-allocated amount of output bandwidth and a priority that ensures minimum loss, minimum delay and minimum jitter before being put into operation.
PHB EF is suitable for channel simulation, leased line simulation, and real-time services such as voice, video without compromising on high loss, delay and jitter values.
Figure 2.10 Example of EF installation
Figure 2.10 shows an example of an EF PHB implementation. This is a simple priority queue scheduling technique. At the edges of the DS domain, EF packet traffic is prioritized according to the values agreed upon by the SLA. The EF queue in the figure needs to output packets at a rate higher than the packet arrival rate λ. To provide an EF PHB over an end-to-end DS domain, bandwidth at the output ports of the core routers needs to be allocated in advance to ensure the requirement μ > λ. This can be done by a pre-configured provisioning process. In the figure, EF packets are placed in the priority queue (the upper queue). With such a length, the queue can operate with μ > λ.
Since EF was primarily used for real-time services such as voice and video, and since real-time services use UDP instead of TCP, RED is generally
not suitable for EF queues because applications using UDP will not respond to random packet drop and RED will strip unnecessary packets.
2.2.4.2 Assured Forwarding (AF) PHB
PHB AF is defined by RFC 2597. The purpose of PHB AF is to deliver packets reliably and therefore delay and jitter are considered less important than packet loss. PHB AF is suitable for non-real-time services such as applications using TCP. PHB AF first defines four classes: AF1, AF2, AF3, AF4. For each of these AF classes, packets are then classified into three subclasses with three distinct priority levels.
Table 2.8 shows the four AF classes and 12 AF subclasses and the DSCP values for the 12 AF subclasses defined by RFC 2597. RFC 2597 also allows for more than three separate priority levels to be added for internal use. However, these separate priority levels will only have internal significance.
PHB Class
PHB Subclass
Package type
DSCP
AF4
AF41
Short
100010
AF42
Medium
100100
AF43
High
100110
AF3
AF31
Short
011010
AF32
Medium
011100
AF33
High
011110
AF2
AF21
Short
010010
AF22
Medium
010100
AF23
High
010110
AF1
AF11
Short
001010
AF12
Medium
001100
AF13
High
001110
Table 2.8 AF DSCPs
The AF PHB ensures that packets are forwarded with a high probability of delivery to the destination within the bounds of the rate agreed upon in an SLA. If AF traffic at an ingress port exceeds the pre-priority rate, which is considered non-compliant or “out of profile”, the excess packets will not be delivered to the destination with the same probability as the packets belonging to the defined traffic or “in profile” packets. When there is network congestion, the out of profile packets are dropped before the in profile packets are dropped.
When service levels are defined using AF classes, different quantity and quality between AF classes can be realized by allocating different amounts of bandwidth and buffer space to the four AF classes. Unlike
EF, most AF traffic is non-real-time traffic using TCP, and the RED queue management strategy is an AQM (Adaptive Queue Management) strategy suitable for use in AF PHBs. The four AF PHB layers can be implemented as four separate queues. The output port bandwidth is divided into four AF queues. For each AF queue, packets are marked with three “colors” corresponding to three separate priority levels.
In addition to the 32 DSCP 1 groups defined in Table 2.8, 21 DSCPs have been standardized as follows: one for PHB EF, 12 for PHB AF, and 8 for CSCP. There are 11 DSCP 1 groups still available for other standards.
2.2.5.Example of Differentiated Services
We will look at an example of the Differentiated Service model and mechanism of operation. The architecture of Differentiated Service consists of two basic sets of functions:
Edge functions: include packet classification and traffic conditioning. At the inbound edge of the network, incoming packets are marked. In particular, the DS field in the packet header is set to a certain value. For example, in Figure 2.12, packets sent from H1 to H3 are marked at R1, while packets from H2 to H4 are marked at R2. The labels on the received packets identify the service class to which they belong. Different traffic classes receive different services in the core network. The RFC definition uses the term behavior aggregate rather than the term traffic class. After being marked, a packet can be forwarded immediately into the network, delayed for a period of time before being forwarded, or dropped. We will see that there are many factors that affect how a packet is marked, and whether it is forwarded immediately, delayed, or dropped.
Figure 2.12 DiffServ Example
Core functionality: When a DS-marked packet arrives at a Diffservcapable router, the packet is forwarded to the next router based on
Per-hop behavior is associated with packet classes. Per-hop behavior affects router buffers and the bandwidth shared between competing classes. An important principle of the Differentiated Service architecture is that a routers per-hop behavior is based only on the packets marking or the class to which it belongs. Therefore, if packets sent from H1 to H3 as shown in the figure receive the same marking as packets from H2 to H4, then the network routers treat the packets exactly the same, regardless of whether the packet originated from H1 or H2. For example, R3 does not distinguish between packets from h1 and H2 when forwarding packets to R4. Therefore, the Differentiated Service architecture avoids the need to maintain router state about separate source-destination pairs, which is important for network scalability.
Chapter Conclusion
Chapter 2 has presented and clarified two main models of deploying and installing quality of service in IP networks. While the traditional best-effort model has many disadvantages, later models such as IntServ and DiffServ have partly solved the problems that best-effort could not solve. IntServ follows the direction of ensuring quality of service for each separate flow, it is built similar to the circuit switching model with the use of the RSVP resource reservation protocol. IntSer is suitable for services that require fixed bandwidth that is not shared such as VoIP services, multicast TV services. However, IntSer has disadvantages such as using a lot of network resources, low scalability and lack of flexibility. DiffServ was born with the idea of solving the disadvantages of the IntServ model.
DiffServ follows the direction of ensuring quality based on the principle of hop-by-hop behavior based on the priority of marked packets. The policy for different types of traffic is decided by the administrator and can be changed according to reality, so it is very flexible. DiffServ makes better use of network resources, avoiding idle bandwidth and processing capacity on routers. In addition, the DifServ model can be deployed on many independent domains, so the ability to expand the network becomes easy.
Chapter 3: METHODS TO ENSURE QoS FOR MULTIMEDIA COMMUNICATIONS
In packet-switched networks, different packet flows often have to share the transmission medium all the way to the destination station. To ensure the fair and efficient allocation of bandwidth to flows, appropriate serving mechanisms are required at network nodes, especially at gateways or routers, where many different data flows often pass through. The scheduler is responsible for serving packets of the selected flow and deciding which packet will be served next. Here, a flow is understood as a set of packets belonging to the same priority class, or originating from the same source, or having the same source and destination addresses, etc.
In normal state when there is no congestion, packets will be sent as soon as they are delivered. In case of congestion, if QoS assurance methods are not applied, prolonged congestion can cause packet drops, affecting service quality. In some cases, congestion is prolonged and widespread in the network, which can easily lead to the network being frozen, or many packets being dropped, seriously affecting service quality.
Therefore, in this chapter, in sections 3.2 and 3.3, we introduce some typical network traffic load monitoring techniques to predict and prevent congestion before it occurs through the measure of dropping (removing) packets early when there are signs of impending congestion.
3.1. DropTail method
DropTail is a simple, traditional queue management method based on FIFO mechanism. All incoming packets are placed in the queue, when the queue is full, the later packets are dropped.
Due to its simplicity and ease of implementation, DropTail has been used for many years on Internet router systems. However, this algorithm has the following disadvantages:
− Cannot avoid the phenomenon of “Lock out”: Occurs when 1 or several traffic streams monopolize the queue, making packets of other connections unable to pass through the router. This phenomenon greatly affects reliable transmission protocols such as TCP. According to the anti-congestion algorithm, when locked out, the TCP connection stream will reduce the window size and reduce the packet transmission speed exponentially.
− Can cause Global Synchronization: This is the result of a severe “Lock out” phenomenon. Some neighboring routers have their queues monopolized by a number of connections, causing a series of other TCP connections to be unable to pass through and simultaneously reducing the transmission speed. After those monopolized connections are temporarily suspended,
Once the queue is cleared, it takes a considerable amount of time for TCP connections to return to their original speed.
− Full Queue phenomenon: Data transmitted on the Internet often has an explosion, packets arriving at the router are often in clusters rather than in turn. Therefore, the operating mechanism of DropTail makes the queue easily full for a long period of time, leading to the average delay time of large packets. To avoid this phenomenon, with DropTail, the only way is to increase the routers buffer, this method is very expensive and ineffective.
− No QoS guarantee: With the DropTail mechanism, there is no way to prioritize important packets to be transmitted through the router earlier when all are in the queue. Meanwhile, with multimedia communication, ensuring connection and stable speed is extremely important and the DropTail algorithm cannot satisfy.
The problem of choosing the buffer size of the routers in the network is to “absorb” short bursts of traffic without causing too much queuing delay. This is necessary in bursty data transmission. The queue size determines the size of the packet bursts (traffic spikes) that we want to be able to transmit without being dropped at the routers.
In IP-based application networks, packet dropping is an important mechanism for indirectly reporting congestion to end stations. A solution that prevents router queues from filling up while reducing the packet drop rate is called dynamic queue management.
3.2. Random elimination method – RED
3.2.1 Overview
RED (Random Early Detection of congestion; Random Early Drop) is one of the first AQM algorithms proposed in 1993 by Sally Floyd and Van Jacobson, two scientists at the Lawrence Berkeley Laboratory of the University of California, USA. Due to its outstanding advantages compared to previous queue management algorithms, RED has been widely installed and deployed on the Internet.
The most fundamental point of their work is that the most effective place to detect congestion and react to it is at the gateway or router.
Source entities (senders) can also do this by estimating end-to-end delay, throughput variability, or the rate of packet retransmissions due to drop. However, the sender and receiver view of a particular connection cannot tell which gateways on the network are congested, and cannot distinguish between propagation delay and queuing delay. Only the gateway has a true view of the state of the queue, the link share of the connections passing through it at any given time, and the quality of service requirements of the
traffic flows. The RED gateway monitors the average queue length, which detects early signs of impending congestion (average queue length exceeding a predetermined threshold) and reacts appropriately in one of two ways:
− Drop incoming packets with a certain probability, to indirectly inform the source of congestion, the source needs to reduce the transmission rate to keep the queue from filling up, maintaining the ability to absorb incoming traffic spikes.
− Mark “congestion” with a certain probability in the ECN field in the header of TCP packets to notify the source (the receiving entity will copy this bit into the acknowledgement packet).
Figure 3. 1 RED algorithm
The main goal of RED is to avoid congestion by keeping the average queue size within a sufficiently small and stable region, which also means keeping the queuing delay sufficiently small and stable. Achieving this goal also helps: avoid global synchronization, not resist bursty traffic flows (i.e. flows with low average throughput but high volatility), and maintain an upper bound on the average queue size even in the absence of cooperation from transport layer protocols.
To achieve the above goals, RED gateways must do the following:
− The first is to detect congestion early and react appropriately to keep the average queue size small enough to keep the network operating in the low latency, high throughput region, while still allowing the queue size to fluctuate within a certain range to absorb short-term fluctuations. As discussed above, the gateway is the most appropriate place to detect congestion and is also the most appropriate place to decide which specific connection to report congestion to.
− The second thing is to notify the source of congestion. This is done by marking and notifying the source to reduce traffic. Normally the RED gateway will randomly drop packets. However, if congestion
If congestion is detected before the queue is full, it should be combined with packet marking to signal congestion. The RED gateway has two options: drop or mark; where marking is done by marking the ECN field of the packet with a certain probability, to signal the source to reduce the traffic entering the network.
− An important goal that RED gateways need to achieve is to avoid global synchronization and not to resist traffic flows that have a sudden characteristic. Global synchronization occurs when all connections simultaneously reduce their transmission window size, leading to a severe drop in throughput at the same time. On the other hand, Drop Tail or Random Drop strategies are very sensitive to sudden flows; that is, the gateway queue will often overflow when packets from these flows arrive. To avoid these two phenomena, gateways can use special algorithms to detect congestion and decide which connections will be notified of congestion at the gateway. The RED gateway randomly selects incoming packets to mark; with this method, the probability of marking a packet from a particular connection is proportional to the connections shared bandwidth at the gateway.
− Another goal is to control the average queue size even without cooperation from the source entities. This can be done by dropping packets when the average size exceeds an upper threshold (instead of marking it). This approach is necessary in cases where most connections have transmission times that are less than the round-trip time, or where the source entities are not able to reduce traffic in response to marking or dropping packets (such as UDP flows).
3.2.2 Algorithm
This section describes the algorithm for RED gateways. RED gateways calculate the average queue size using a low-pass filter. This average queue size is compared with two thresholds: minth and maxth. When the average queue size is less than the lower threshold, no incoming packets are marked or dropped; when the average queue size is greater than the upper threshold, all incoming packets are dropped. When the average queue size is between minth and maxth, each incoming packet is marked or dropped with a probability pa, where pa is a function of the average queue size avg; the probability of marking or dropping a packet for a particular connection is proportional to the bandwidth share of that connection at the gateway. The general algorithm for a RED gateway is described as follows: [5]
For each packet arrival
Caculate the average queue size avg If minth ≤ avg < maxth
div.maincontent .s1 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 15pt; }
div.maincontent .s2 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent .s3 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s4 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s5 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s6 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s7 { color: black; font-family:Wingdings; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s8 { color: black; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .s9 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s10 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 6pt; }
div.maincontent .s11 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s12 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; }
div.maincontent .s13 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-d](https://tailieuthamkhao.com/uploads/2022/05/15/danh-gia-hieu-qua-dam-bao-qos-cho-truyen-thong-da-phuong-tien-cua-chien-6-1-120x90.jpg)
![Qos Assurance Methods for Multimedia Communications
zt2i3t4l5ee
zt2a3gs
zt2a3ge
zc2o3n4t5e6n7ts
low. The EF PHB requires a sufficiently large number of output ports to provide low delay, low loss, and low jitter.
EF PHBs can be implemented if the output ports bandwidth is sufficiently large, combined with small buffer sizes and other network resources dedicated to EF packets, to allow the routers service rate for EF packets on an output port to exceed the arrival rate λ of packets at that port.
This means that packets with PHB EF are considered with a pre-allocated amount of output bandwidth and a priority that ensures minimum loss, minimum delay and minimum jitter before being put into operation.
PHB EF is suitable for channel simulation, leased line simulation, and real-time services such as voice, video without compromising on high loss, delay and jitter values.
Figure 2.10 Example of EF installation
Figure 2.10 shows an example of an EF PHB implementation. This is a simple priority queue scheduling technique. At the edges of the DS domain, EF packet traffic is prioritized according to the values agreed upon by the SLA. The EF queue in the figure needs to output packets at a rate higher than the packet arrival rate λ. To provide an EF PHB over an end-to-end DS domain, bandwidth at the output ports of the core routers needs to be allocated in advance to ensure the requirement μ > λ. This can be done by a pre-configured provisioning process. In the figure, EF packets are placed in the priority queue (the upper queue). With such a length, the queue can operate with μ > λ.
Since EF was primarily used for real-time services such as voice and video, and since real-time services use UDP instead of TCP, RED is generally
not suitable for EF queues because applications using UDP will not respond to random packet drop and RED will strip unnecessary packets.
2.2.4.2 Assured Forwarding (AF) PHB
PHB AF is defined by RFC 2597. The purpose of PHB AF is to deliver packets reliably and therefore delay and jitter are considered less important than packet loss. PHB AF is suitable for non-real-time services such as applications using TCP. PHB AF first defines four classes: AF1, AF2, AF3, AF4. For each of these AF classes, packets are then classified into three subclasses with three distinct priority levels.
Table 2.8 shows the four AF classes and 12 AF subclasses and the DSCP values for the 12 AF subclasses defined by RFC 2597. RFC 2597 also allows for more than three separate priority levels to be added for internal use. However, these separate priority levels will only have internal significance.
PHB Class
PHB Subclass
Package type
DSCP
AF4
AF41
Short
100010
AF42
Medium
100100
AF43
High
100110
AF3
AF31
Short
011010
AF32
Medium
011100
AF33
High
011110
AF2
AF21
Short
010010
AF22
Medium
010100
AF23
High
010110
AF1
AF11
Short
001010
AF12
Medium
001100
AF13
High
001110
Table 2.8 AF DSCPs
The AF PHB ensures that packets are forwarded with a high probability of delivery to the destination within the bounds of the rate agreed upon in an SLA. If AF traffic at an ingress port exceeds the pre-priority rate, which is considered non-compliant or “out of profile”, the excess packets will not be delivered to the destination with the same probability as the packets belonging to the defined traffic or “in profile” packets. When there is network congestion, the out of profile packets are dropped before the in profile packets are dropped.
When service levels are defined using AF classes, different quantity and quality between AF classes can be realized by allocating different amounts of bandwidth and buffer space to the four AF classes. Unlike
EF, most AF traffic is non-real-time traffic using TCP, and the RED queue management strategy is an AQM (Adaptive Queue Management) strategy suitable for use in AF PHBs. The four AF PHB layers can be implemented as four separate queues. The output port bandwidth is divided into four AF queues. For each AF queue, packets are marked with three “colors” corresponding to three separate priority levels.
In addition to the 32 DSCP 1 groups defined in Table 2.8, 21 DSCPs have been standardized as follows: one for PHB EF, 12 for PHB AF, and 8 for CSCP. There are 11 DSCP 1 groups still available for other standards.
2.2.5.Example of Differentiated Services
We will look at an example of the Differentiated Service model and mechanism of operation. The architecture of Differentiated Service consists of two basic sets of functions:
Edge functions: include packet classification and traffic conditioning. At the inbound edge of the network, incoming packets are marked. In particular, the DS field in the packet header is set to a certain value. For example, in Figure 2.12, packets sent from H1 to H3 are marked at R1, while packets from H2 to H4 are marked at R2. The labels on the received packets identify the service class to which they belong. Different traffic classes receive different services in the core network. The RFC definition uses the term behavior aggregate rather than the term traffic class. After being marked, a packet can be forwarded immediately into the network, delayed for a period of time before being forwarded, or dropped. We will see that there are many factors that affect how a packet is marked, and whether it is forwarded immediately, delayed, or dropped.
Figure 2.12 DiffServ Example
Core functionality: When a DS-marked packet arrives at a Diffservcapable router, the packet is forwarded to the next router based on
Per-hop behavior is associated with packet classes. Per-hop behavior affects router buffers and the bandwidth shared between competing classes. An important principle of the Differentiated Service architecture is that a routers per-hop behavior is based only on the packets marking or the class to which it belongs. Therefore, if packets sent from H1 to H3 as shown in the figure receive the same marking as packets from H2 to H4, then the network routers treat the packets exactly the same, regardless of whether the packet originated from H1 or H2. For example, R3 does not distinguish between packets from h1 and H2 when forwarding packets to R4. Therefore, the Differentiated Service architecture avoids the need to maintain router state about separate source-destination pairs, which is important for network scalability.
Chapter Conclusion
Chapter 2 has presented and clarified two main models of deploying and installing quality of service in IP networks. While the traditional best-effort model has many disadvantages, later models such as IntServ and DiffServ have partly solved the problems that best-effort could not solve. IntServ follows the direction of ensuring quality of service for each separate flow, it is built similar to the circuit switching model with the use of the RSVP resource reservation protocol. IntSer is suitable for services that require fixed bandwidth that is not shared such as VoIP services, multicast TV services. However, IntSer has disadvantages such as using a lot of network resources, low scalability and lack of flexibility. DiffServ was born with the idea of solving the disadvantages of the IntServ model.
DiffServ follows the direction of ensuring quality based on the principle of hop-by-hop behavior based on the priority of marked packets. The policy for different types of traffic is decided by the administrator and can be changed according to reality, so it is very flexible. DiffServ makes better use of network resources, avoiding idle bandwidth and processing capacity on routers. In addition, the DifServ model can be deployed on many independent domains, so the ability to expand the network becomes easy.
Chapter 3: METHODS TO ENSURE QoS FOR MULTIMEDIA COMMUNICATIONS
In packet-switched networks, different packet flows often have to share the transmission medium all the way to the destination station. To ensure the fair and efficient allocation of bandwidth to flows, appropriate serving mechanisms are required at network nodes, especially at gateways or routers, where many different data flows often pass through. The scheduler is responsible for serving packets of the selected flow and deciding which packet will be served next. Here, a flow is understood as a set of packets belonging to the same priority class, or originating from the same source, or having the same source and destination addresses, etc.
In normal state when there is no congestion, packets will be sent as soon as they are delivered. In case of congestion, if QoS assurance methods are not applied, prolonged congestion can cause packet drops, affecting service quality. In some cases, congestion is prolonged and widespread in the network, which can easily lead to the network being frozen, or many packets being dropped, seriously affecting service quality.
Therefore, in this chapter, in sections 3.2 and 3.3, we introduce some typical network traffic load monitoring techniques to predict and prevent congestion before it occurs through the measure of dropping (removing) packets early when there are signs of impending congestion.
3.1. DropTail method
DropTail is a simple, traditional queue management method based on FIFO mechanism. All incoming packets are placed in the queue, when the queue is full, the later packets are dropped.
Due to its simplicity and ease of implementation, DropTail has been used for many years on Internet router systems. However, this algorithm has the following disadvantages:
− Cannot avoid the phenomenon of “Lock out”: Occurs when 1 or several traffic streams monopolize the queue, making packets of other connections unable to pass through the router. This phenomenon greatly affects reliable transmission protocols such as TCP. According to the anti-congestion algorithm, when locked out, the TCP connection stream will reduce the window size and reduce the packet transmission speed exponentially.
− Can cause Global Synchronization: This is the result of a severe “Lock out” phenomenon. Some neighboring routers have their queues monopolized by a number of connections, causing a series of other TCP connections to be unable to pass through and simultaneously reducing the transmission speed. After those monopolized connections are temporarily suspended,
Once the queue is cleared, it takes a considerable amount of time for TCP connections to return to their original speed.
− Full Queue phenomenon: Data transmitted on the Internet often has an explosion, packets arriving at the router are often in clusters rather than in turn. Therefore, the operating mechanism of DropTail makes the queue easily full for a long period of time, leading to the average delay time of large packets. To avoid this phenomenon, with DropTail, the only way is to increase the routers buffer, this method is very expensive and ineffective.
− No QoS guarantee: With the DropTail mechanism, there is no way to prioritize important packets to be transmitted through the router earlier when all are in the queue. Meanwhile, with multimedia communication, ensuring connection and stable speed is extremely important and the DropTail algorithm cannot satisfy.
The problem of choosing the buffer size of the routers in the network is to “absorb” short bursts of traffic without causing too much queuing delay. This is necessary in bursty data transmission. The queue size determines the size of the packet bursts (traffic spikes) that we want to be able to transmit without being dropped at the routers.
In IP-based application networks, packet dropping is an important mechanism for indirectly reporting congestion to end stations. A solution that prevents router queues from filling up while reducing the packet drop rate is called dynamic queue management.
3.2. Random elimination method – RED
3.2.1 Overview
RED (Random Early Detection of congestion; Random Early Drop) is one of the first AQM algorithms proposed in 1993 by Sally Floyd and Van Jacobson, two scientists at the Lawrence Berkeley Laboratory of the University of California, USA. Due to its outstanding advantages compared to previous queue management algorithms, RED has been widely installed and deployed on the Internet.
The most fundamental point of their work is that the most effective place to detect congestion and react to it is at the gateway or router.
Source entities (senders) can also do this by estimating end-to-end delay, throughput variability, or the rate of packet retransmissions due to drop. However, the sender and receiver view of a particular connection cannot tell which gateways on the network are congested, and cannot distinguish between propagation delay and queuing delay. Only the gateway has a true view of the state of the queue, the link share of the connections passing through it at any given time, and the quality of service requirements of the
traffic flows. The RED gateway monitors the average queue length, which detects early signs of impending congestion (average queue length exceeding a predetermined threshold) and reacts appropriately in one of two ways:
− Drop incoming packets with a certain probability, to indirectly inform the source of congestion, the source needs to reduce the transmission rate to keep the queue from filling up, maintaining the ability to absorb incoming traffic spikes.
− Mark “congestion” with a certain probability in the ECN field in the header of TCP packets to notify the source (the receiving entity will copy this bit into the acknowledgement packet).
Figure 3. 1 RED algorithm
The main goal of RED is to avoid congestion by keeping the average queue size within a sufficiently small and stable region, which also means keeping the queuing delay sufficiently small and stable. Achieving this goal also helps: avoid global synchronization, not resist bursty traffic flows (i.e. flows with low average throughput but high volatility), and maintain an upper bound on the average queue size even in the absence of cooperation from transport layer protocols.
To achieve the above goals, RED gateways must do the following:
− The first is to detect congestion early and react appropriately to keep the average queue size small enough to keep the network operating in the low latency, high throughput region, while still allowing the queue size to fluctuate within a certain range to absorb short-term fluctuations. As discussed above, the gateway is the most appropriate place to detect congestion and is also the most appropriate place to decide which specific connection to report congestion to.
− The second thing is to notify the source of congestion. This is done by marking and notifying the source to reduce traffic. Normally the RED gateway will randomly drop packets. However, if congestion
If congestion is detected before the queue is full, it should be combined with packet marking to signal congestion. The RED gateway has two options: drop or mark; where marking is done by marking the ECN field of the packet with a certain probability, to signal the source to reduce the traffic entering the network.
− An important goal that RED gateways need to achieve is to avoid global synchronization and not to resist traffic flows that have a sudden characteristic. Global synchronization occurs when all connections simultaneously reduce their transmission window size, leading to a severe drop in throughput at the same time. On the other hand, Drop Tail or Random Drop strategies are very sensitive to sudden flows; that is, the gateway queue will often overflow when packets from these flows arrive. To avoid these two phenomena, gateways can use special algorithms to detect congestion and decide which connections will be notified of congestion at the gateway. The RED gateway randomly selects incoming packets to mark; with this method, the probability of marking a packet from a particular connection is proportional to the connections shared bandwidth at the gateway.
− Another goal is to control the average queue size even without cooperation from the source entities. This can be done by dropping packets when the average size exceeds an upper threshold (instead of marking it). This approach is necessary in cases where most connections have transmission times that are less than the round-trip time, or where the source entities are not able to reduce traffic in response to marking or dropping packets (such as UDP flows).
3.2.2 Algorithm
This section describes the algorithm for RED gateways. RED gateways calculate the average queue size using a low-pass filter. This average queue size is compared with two thresholds: minth and maxth. When the average queue size is less than the lower threshold, no incoming packets are marked or dropped; when the average queue size is greater than the upper threshold, all incoming packets are dropped. When the average queue size is between minth and maxth, each incoming packet is marked or dropped with a probability pa, where pa is a function of the average queue size avg; the probability of marking or dropping a packet for a particular connection is proportional to the bandwidth share of that connection at the gateway. The general algorithm for a RED gateway is described as follows: [5]
For each packet arrival
Caculate the average queue size avg If minth ≤ avg < maxth
div.maincontent .s1 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 15pt; }
div.maincontent .s2 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent .s3 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s4 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s5 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s6 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s7 { color: black; font-family:Wingdings; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s8 { color: black; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .s9 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s10 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 6pt; }
div.maincontent .s11 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s12 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; }
div.maincontent .s13 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-d](data:image/svg+xml,%3Csvg%20xmlns=%22http://www.w3.org/2000/svg%22%20viewBox=%220%200%2075%2075%22%3E%3C/svg%3E) Qos Assurance Methods for Multimedia Communications
zt2i3t4l5ee
zt2a3gs
zt2a3ge
zc2o3n4t5e6n7ts
low. The EF PHB requires a sufficiently large number of output ports to provide low delay, low loss, and low jitter.
EF PHBs can be implemented if the output port's bandwidth is sufficiently large, combined with small buffer sizes and other network resources dedicated to EF packets, to allow the router's service rate for EF packets on an output port to exceed the arrival rate λ of packets at that port.
This means that packets with PHB EF are considered with a pre-allocated amount of output bandwidth and a priority that ensures minimum loss, minimum delay and minimum jitter before being put into operation.
PHB EF is suitable for channel simulation, leased line simulation, and real-time services such as voice, video without compromising on high loss, delay and jitter values.
Figure 2.10 Example of EF installation
Figure 2.10 shows an example of an EF PHB implementation. This is a simple priority queue scheduling technique. At the edges of the DS domain, EF packet traffic is prioritized according to the values agreed upon by the SLA. The EF queue in the figure needs to output packets at a rate higher than the packet arrival rate λ. To provide an EF PHB over an end-to-end DS domain, bandwidth at the output ports of the core routers needs to be allocated in advance to ensure the requirement μ > λ. This can be done by a pre-configured provisioning process. In the figure, EF packets are placed in the priority queue (the upper queue). With such a length, the queue can operate with μ > λ.
Since EF was primarily used for real-time services such as voice and video, and since real-time services use UDP instead of TCP, RED is generally
not suitable for EF queues because applications using UDP will not respond to random packet drop and RED will strip unnecessary packets.
2.2.4.2 Assured Forwarding (AF) PHB
PHB AF is defined by RFC 2597. The purpose of PHB AF is to deliver packets reliably and therefore delay and jitter are considered less important than packet loss. PHB AF is suitable for non-real-time services such as applications using TCP. PHB AF first defines four classes: AF1, AF2, AF3, AF4. For each of these AF classes, packets are then classified into three subclasses with three distinct priority levels.
Table 2.8 shows the four AF classes and 12 AF subclasses and the DSCP values for the 12 AF subclasses defined by RFC 2597. RFC 2597 also allows for more than three separate priority levels to be added for internal use. However, these separate priority levels will only have internal significance.
PHB Class
PHB Subclass
Package type
DSCP
AF4
AF41
Short
100010
AF42
Medium
100100
AF43
High
100110
AF3
AF31
Short
011010
AF32
Medium
011100
AF33
High
011110
AF2
AF21
Short
010010
AF22
Medium
010100
AF23
High
010110
AF1
AF11
Short
001010
AF12
Medium
001100
AF13
High
001110
Table 2.8 AF DSCPs
The AF PHB ensures that packets are forwarded with a high probability of delivery to the destination within the bounds of the rate agreed upon in an SLA. If AF traffic at an ingress port exceeds the pre-priority rate, which is considered non-compliant or “out of profile”, the excess packets will not be delivered to the destination with the same probability as the packets belonging to the defined traffic or “in profile” packets. When there is network congestion, the out of profile packets are dropped before the in profile packets are dropped.
When service levels are defined using AF classes, different quantity and quality between AF classes can be realized by allocating different amounts of bandwidth and buffer space to the four AF classes. Unlike
EF, most AF traffic is non-real-time traffic using TCP, and the RED queue management strategy is an AQM (Adaptive Queue Management) strategy suitable for use in AF PHBs. The four AF PHB layers can be implemented as four separate queues. The output port bandwidth is divided into four AF queues. For each AF queue, packets are marked with three “colors” corresponding to three separate priority levels.
In addition to the 32 DSCP 1 groups defined in Table 2.8, 21 DSCPs have been standardized as follows: one for PHB EF, 12 for PHB AF, and 8 for CSCP. There are 11 DSCP 1 groups still available for other standards.
2.2.5.Example of Differentiated Services
We will look at an example of the Differentiated Service model and mechanism of operation. The architecture of Differentiated Service consists of two basic sets of functions:
Edge functions: include packet classification and traffic conditioning. At the inbound edge of the network, incoming packets are marked. In particular, the DS field in the packet header is set to a certain value. For example, in Figure 2.12, packets sent from H1 to H3 are marked at R1, while packets from H2 to H4 are marked at R2. The labels on the received packets identify the service class to which they belong. Different traffic classes receive different services in the core network. The RFC definition uses the term behavior aggregate rather than the term traffic class. After being marked, a packet can be forwarded immediately into the network, delayed for a period of time before being forwarded, or dropped. We will see that there are many factors that affect how a packet is marked, and whether it is forwarded immediately, delayed, or dropped.
Figure 2.12 DiffServ Example
Core functionality: When a DS-marked packet arrives at a Diffservcapable router, the packet is forwarded to the next router based on
Per-hop behavior is associated with packet classes. Per-hop behavior affects router buffers and the bandwidth shared between competing classes. An important principle of the Differentiated Service architecture is that a router's per-hop behavior is based only on the packet's marking or the class to which it belongs. Therefore, if packets sent from H1 to H3 as shown in the figure receive the same marking as packets from H2 to H4, then the network routers treat the packets exactly the same, regardless of whether the packet originated from H1 or H2. For example, R3 does not distinguish between packets from h1 and H2 when forwarding packets to R4. Therefore, the Differentiated Service architecture avoids the need to maintain router state about separate source-destination pairs, which is important for network scalability.
Chapter Conclusion
Chapter 2 has presented and clarified two main models of deploying and installing quality of service in IP networks. While the traditional best-effort model has many disadvantages, later models such as IntServ and DiffServ have partly solved the problems that best-effort could not solve. IntServ follows the direction of ensuring quality of service for each separate flow, it is built similar to the circuit switching model with the use of the RSVP resource reservation protocol. IntSer is suitable for services that require fixed bandwidth that is not shared such as VoIP services, multicast TV services. However, IntSer has disadvantages such as using a lot of network resources, low scalability and lack of flexibility. DiffServ was born with the idea of solving the disadvantages of the IntServ model.
DiffServ follows the direction of ensuring quality based on the principle of hop-by-hop behavior based on the priority of marked packets. The policy for different types of traffic is decided by the administrator and can be changed according to reality, so it is very flexible. DiffServ makes better use of network resources, avoiding idle bandwidth and processing capacity on routers. In addition, the DifServ model can be deployed on many independent domains, so the ability to expand the network becomes easy.
Chapter 3: METHODS TO ENSURE QoS FOR MULTIMEDIA COMMUNICATIONS
In packet-switched networks, different packet flows often have to share the transmission medium all the way to the destination station. To ensure the fair and efficient allocation of bandwidth to flows, appropriate serving mechanisms are required at network nodes, especially at gateways or routers, where many different data flows often pass through. The scheduler is responsible for serving packets of the selected flow and deciding which packet will be served next. Here, a flow is understood as a set of packets belonging to the same priority class, or originating from the same source, or having the same source and destination addresses, etc.
In normal state when there is no congestion, packets will be sent as soon as they are delivered. In case of congestion, if QoS assurance methods are not applied, prolonged congestion can cause packet drops, affecting service quality. In some cases, congestion is prolonged and widespread in the network, which can easily lead to the network being "frozen", or many packets being dropped, seriously affecting service quality.
Therefore, in this chapter, in sections 3.2 and 3.3, we introduce some typical network traffic load monitoring techniques to predict and prevent congestion before it occurs through the measure of dropping (removing) packets early when there are signs of impending congestion.
3.1. DropTail method
DropTail is a simple, traditional queue management method based on FIFO mechanism. All incoming packets are placed in the queue, when the queue is full, the later packets are dropped.
Due to its simplicity and ease of implementation, DropTail has been used for many years on Internet router systems. However, this algorithm has the following disadvantages:
− Cannot avoid the phenomenon of “Lock out”: Occurs when 1 or several traffic streams monopolize the queue, making packets of other connections unable to pass through the router. This phenomenon greatly affects reliable transmission protocols such as TCP. According to the anti-congestion algorithm, when locked out, the TCP connection stream will reduce the window size and reduce the packet transmission speed exponentially.
− Can cause Global Synchronization: This is the result of a severe “Lock out” phenomenon. Some neighboring routers have their queues monopolized by a number of connections, causing a series of other TCP connections to be unable to pass through and simultaneously reducing the transmission speed. After those monopolized connections are temporarily suspended,
Once the queue is cleared, it takes a considerable amount of time for TCP connections to return to their original speed.
− Full Queue phenomenon: Data transmitted on the Internet often has an explosion, packets arriving at the router are often in clusters rather than in turn. Therefore, the operating mechanism of DropTail makes the queue easily full for a long period of time, leading to the average delay time of large packets. To avoid this phenomenon, with DropTail, the only way is to increase the router's buffer, this method is very expensive and ineffective.
− No QoS guarantee: With the DropTail mechanism, there is no way to prioritize important packets to be transmitted through the router earlier when all are in the queue. Meanwhile, with multimedia communication, ensuring connection and stable speed is extremely important and the DropTail algorithm cannot satisfy.
The problem of choosing the buffer size of the routers in the network is to “absorb” short bursts of traffic without causing too much queuing delay. This is necessary in bursty data transmission. The queue size determines the size of the packet bursts (traffic spikes) that we want to be able to transmit without being dropped at the routers.
In IP-based application networks, packet dropping is an important mechanism for indirectly reporting congestion to end stations. A solution that prevents router queues from filling up while reducing the packet drop rate is called dynamic queue management.
3.2. Random elimination method – RED
3.2.1 Overview
RED (Random Early Detection of congestion; Random Early Drop) is one of the first AQM algorithms proposed in 1993 by Sally Floyd and Van Jacobson, two scientists at the Lawrence Berkeley Laboratory of the University of California, USA. Due to its outstanding advantages compared to previous queue management algorithms, RED has been widely installed and deployed on the Internet.
The most fundamental point of their work is that the most effective place to detect congestion and react to it is at the gateway or router.
Source entities (senders) can also do this by estimating end-to-end delay, throughput variability, or the rate of packet retransmissions due to drop. However, the sender and receiver view of a particular connection cannot tell which gateways on the network are congested, and cannot distinguish between propagation delay and queuing delay. Only the gateway has a true view of the state of the queue, the link share of the connections passing through it at any given time, and the quality of service requirements of the
traffic flows. The RED gateway monitors the average queue length, which detects early signs of impending congestion (average queue length exceeding a predetermined threshold) and reacts appropriately in one of two ways:
− Drop incoming packets with a certain probability, to indirectly inform the source of congestion, the source needs to reduce the transmission rate to keep the queue from filling up, maintaining the ability to absorb incoming traffic spikes.
− Mark “congestion” with a certain probability in the ECN field in the header of TCP packets to notify the source (the receiving entity will copy this bit into the acknowledgement packet).
Figure 3. 1 RED algorithm
The main goal of RED is to avoid congestion by keeping the average queue size within a sufficiently small and stable region, which also means keeping the queuing delay sufficiently small and stable. Achieving this goal also helps: avoid global synchronization, not resist bursty traffic flows (i.e. flows with low average throughput but high volatility), and maintain an upper bound on the average queue size even in the absence of cooperation from transport layer protocols.
To achieve the above goals, RED gateways must do the following:
− The first is to detect congestion early and react appropriately to keep the average queue size small enough to keep the network operating in the low latency, high throughput region, while still allowing the queue size to fluctuate within a certain range to absorb short-term fluctuations. As discussed above, the gateway is the most appropriate place to detect congestion and is also the most appropriate place to decide which specific connection to report congestion to.
− The second thing is to notify the source of congestion. This is done by marking and notifying the source to reduce traffic. Normally the RED gateway will randomly drop packets. However, if congestion
If congestion is detected before the queue is full, it should be combined with packet marking to signal congestion. The RED gateway has two options: drop or mark; where marking is done by marking the ECN field of the packet with a certain probability, to signal the source to reduce the traffic entering the network.
− An important goal that RED gateways need to achieve is to avoid global synchronization and not to resist traffic flows that have a sudden characteristic. Global synchronization occurs when all connections simultaneously reduce their transmission window size, leading to a severe drop in throughput at the same time. On the other hand, Drop Tail or Random Drop strategies are very sensitive to sudden flows; that is, the gateway queue will often overflow when packets from these flows arrive. To avoid these two phenomena, gateways can use special algorithms to detect congestion and decide which connections will be notified of congestion at the gateway. The RED gateway randomly selects incoming packets to mark; with this method, the probability of marking a packet from a particular connection is proportional to the connection's shared bandwidth at the gateway.
− Another goal is to control the average queue size even without cooperation from the source entities. This can be done by dropping packets when the average size exceeds an upper threshold (instead of marking it). This approach is necessary in cases where most connections have transmission times that are less than the round-trip time, or where the source entities are not able to reduce traffic in response to marking or dropping packets (such as UDP flows).
3.2.2 Algorithm
This section describes the algorithm for RED gateways. RED gateways calculate the average queue size using a low-pass filter. This average queue size is compared with two thresholds: minth and maxth. When the average queue size is less than the lower threshold, no incoming packets are marked or dropped; when the average queue size is greater than the upper threshold, all incoming packets are dropped. When the average queue size is between minth and maxth, each incoming packet is marked or dropped with a probability pa, where pa is a function of the average queue size avg; the probability of marking or dropping a packet for a particular connection is proportional to the bandwidth share of that connection at the gateway. The general algorithm for a RED gateway is described as follows: [5]
For each packet arrival
Caculate the average queue size avg If minth ≤ avg < maxth
div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 15pt; }
div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s7 { color: black; font-family:Wingdings; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s8 { color: black; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .s9 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s10 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 6pt; }
div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s12 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; }
div.maincontent .s13 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-d
Qos Assurance Methods for Multimedia Communications
zt2i3t4l5ee
zt2a3gs
zt2a3ge
zc2o3n4t5e6n7ts
low. The EF PHB requires a sufficiently large number of output ports to provide low delay, low loss, and low jitter.
EF PHBs can be implemented if the output port's bandwidth is sufficiently large, combined with small buffer sizes and other network resources dedicated to EF packets, to allow the router's service rate for EF packets on an output port to exceed the arrival rate λ of packets at that port.
This means that packets with PHB EF are considered with a pre-allocated amount of output bandwidth and a priority that ensures minimum loss, minimum delay and minimum jitter before being put into operation.
PHB EF is suitable for channel simulation, leased line simulation, and real-time services such as voice, video without compromising on high loss, delay and jitter values.
Figure 2.10 Example of EF installation
Figure 2.10 shows an example of an EF PHB implementation. This is a simple priority queue scheduling technique. At the edges of the DS domain, EF packet traffic is prioritized according to the values agreed upon by the SLA. The EF queue in the figure needs to output packets at a rate higher than the packet arrival rate λ. To provide an EF PHB over an end-to-end DS domain, bandwidth at the output ports of the core routers needs to be allocated in advance to ensure the requirement μ > λ. This can be done by a pre-configured provisioning process. In the figure, EF packets are placed in the priority queue (the upper queue). With such a length, the queue can operate with μ > λ.
Since EF was primarily used for real-time services such as voice and video, and since real-time services use UDP instead of TCP, RED is generally
not suitable for EF queues because applications using UDP will not respond to random packet drop and RED will strip unnecessary packets.
2.2.4.2 Assured Forwarding (AF) PHB
PHB AF is defined by RFC 2597. The purpose of PHB AF is to deliver packets reliably and therefore delay and jitter are considered less important than packet loss. PHB AF is suitable for non-real-time services such as applications using TCP. PHB AF first defines four classes: AF1, AF2, AF3, AF4. For each of these AF classes, packets are then classified into three subclasses with three distinct priority levels.
Table 2.8 shows the four AF classes and 12 AF subclasses and the DSCP values for the 12 AF subclasses defined by RFC 2597. RFC 2597 also allows for more than three separate priority levels to be added for internal use. However, these separate priority levels will only have internal significance.
PHB Class
PHB Subclass
Package type
DSCP
AF4
AF41
Short
100010
AF42
Medium
100100
AF43
High
100110
AF3
AF31
Short
011010
AF32
Medium
011100
AF33
High
011110
AF2
AF21
Short
010010
AF22
Medium
010100
AF23
High
010110
AF1
AF11
Short
001010
AF12
Medium
001100
AF13
High
001110
Table 2.8 AF DSCPs
The AF PHB ensures that packets are forwarded with a high probability of delivery to the destination within the bounds of the rate agreed upon in an SLA. If AF traffic at an ingress port exceeds the pre-priority rate, which is considered non-compliant or “out of profile”, the excess packets will not be delivered to the destination with the same probability as the packets belonging to the defined traffic or “in profile” packets. When there is network congestion, the out of profile packets are dropped before the in profile packets are dropped.
When service levels are defined using AF classes, different quantity and quality between AF classes can be realized by allocating different amounts of bandwidth and buffer space to the four AF classes. Unlike
EF, most AF traffic is non-real-time traffic using TCP, and the RED queue management strategy is an AQM (Adaptive Queue Management) strategy suitable for use in AF PHBs. The four AF PHB layers can be implemented as four separate queues. The output port bandwidth is divided into four AF queues. For each AF queue, packets are marked with three “colors” corresponding to three separate priority levels.
In addition to the 32 DSCP 1 groups defined in Table 2.8, 21 DSCPs have been standardized as follows: one for PHB EF, 12 for PHB AF, and 8 for CSCP. There are 11 DSCP 1 groups still available for other standards.
2.2.5.Example of Differentiated Services
We will look at an example of the Differentiated Service model and mechanism of operation. The architecture of Differentiated Service consists of two basic sets of functions:
Edge functions: include packet classification and traffic conditioning. At the inbound edge of the network, incoming packets are marked. In particular, the DS field in the packet header is set to a certain value. For example, in Figure 2.12, packets sent from H1 to H3 are marked at R1, while packets from H2 to H4 are marked at R2. The labels on the received packets identify the service class to which they belong. Different traffic classes receive different services in the core network. The RFC definition uses the term behavior aggregate rather than the term traffic class. After being marked, a packet can be forwarded immediately into the network, delayed for a period of time before being forwarded, or dropped. We will see that there are many factors that affect how a packet is marked, and whether it is forwarded immediately, delayed, or dropped.
Figure 2.12 DiffServ Example
Core functionality: When a DS-marked packet arrives at a Diffservcapable router, the packet is forwarded to the next router based on
Per-hop behavior is associated with packet classes. Per-hop behavior affects router buffers and the bandwidth shared between competing classes. An important principle of the Differentiated Service architecture is that a router's per-hop behavior is based only on the packet's marking or the class to which it belongs. Therefore, if packets sent from H1 to H3 as shown in the figure receive the same marking as packets from H2 to H4, then the network routers treat the packets exactly the same, regardless of whether the packet originated from H1 or H2. For example, R3 does not distinguish between packets from h1 and H2 when forwarding packets to R4. Therefore, the Differentiated Service architecture avoids the need to maintain router state about separate source-destination pairs, which is important for network scalability.
Chapter Conclusion
Chapter 2 has presented and clarified two main models of deploying and installing quality of service in IP networks. While the traditional best-effort model has many disadvantages, later models such as IntServ and DiffServ have partly solved the problems that best-effort could not solve. IntServ follows the direction of ensuring quality of service for each separate flow, it is built similar to the circuit switching model with the use of the RSVP resource reservation protocol. IntSer is suitable for services that require fixed bandwidth that is not shared such as VoIP services, multicast TV services. However, IntSer has disadvantages such as using a lot of network resources, low scalability and lack of flexibility. DiffServ was born with the idea of solving the disadvantages of the IntServ model.
DiffServ follows the direction of ensuring quality based on the principle of hop-by-hop behavior based on the priority of marked packets. The policy for different types of traffic is decided by the administrator and can be changed according to reality, so it is very flexible. DiffServ makes better use of network resources, avoiding idle bandwidth and processing capacity on routers. In addition, the DifServ model can be deployed on many independent domains, so the ability to expand the network becomes easy.
Chapter 3: METHODS TO ENSURE QoS FOR MULTIMEDIA COMMUNICATIONS
In packet-switched networks, different packet flows often have to share the transmission medium all the way to the destination station. To ensure the fair and efficient allocation of bandwidth to flows, appropriate serving mechanisms are required at network nodes, especially at gateways or routers, where many different data flows often pass through. The scheduler is responsible for serving packets of the selected flow and deciding which packet will be served next. Here, a flow is understood as a set of packets belonging to the same priority class, or originating from the same source, or having the same source and destination addresses, etc.
In normal state when there is no congestion, packets will be sent as soon as they are delivered. In case of congestion, if QoS assurance methods are not applied, prolonged congestion can cause packet drops, affecting service quality. In some cases, congestion is prolonged and widespread in the network, which can easily lead to the network being "frozen", or many packets being dropped, seriously affecting service quality.
Therefore, in this chapter, in sections 3.2 and 3.3, we introduce some typical network traffic load monitoring techniques to predict and prevent congestion before it occurs through the measure of dropping (removing) packets early when there are signs of impending congestion.
3.1. DropTail method
DropTail is a simple, traditional queue management method based on FIFO mechanism. All incoming packets are placed in the queue, when the queue is full, the later packets are dropped.
Due to its simplicity and ease of implementation, DropTail has been used for many years on Internet router systems. However, this algorithm has the following disadvantages:
− Cannot avoid the phenomenon of “Lock out”: Occurs when 1 or several traffic streams monopolize the queue, making packets of other connections unable to pass through the router. This phenomenon greatly affects reliable transmission protocols such as TCP. According to the anti-congestion algorithm, when locked out, the TCP connection stream will reduce the window size and reduce the packet transmission speed exponentially.
− Can cause Global Synchronization: This is the result of a severe “Lock out” phenomenon. Some neighboring routers have their queues monopolized by a number of connections, causing a series of other TCP connections to be unable to pass through and simultaneously reducing the transmission speed. After those monopolized connections are temporarily suspended,
Once the queue is cleared, it takes a considerable amount of time for TCP connections to return to their original speed.
− Full Queue phenomenon: Data transmitted on the Internet often has an explosion, packets arriving at the router are often in clusters rather than in turn. Therefore, the operating mechanism of DropTail makes the queue easily full for a long period of time, leading to the average delay time of large packets. To avoid this phenomenon, with DropTail, the only way is to increase the router's buffer, this method is very expensive and ineffective.
− No QoS guarantee: With the DropTail mechanism, there is no way to prioritize important packets to be transmitted through the router earlier when all are in the queue. Meanwhile, with multimedia communication, ensuring connection and stable speed is extremely important and the DropTail algorithm cannot satisfy.
The problem of choosing the buffer size of the routers in the network is to “absorb” short bursts of traffic without causing too much queuing delay. This is necessary in bursty data transmission. The queue size determines the size of the packet bursts (traffic spikes) that we want to be able to transmit without being dropped at the routers.
In IP-based application networks, packet dropping is an important mechanism for indirectly reporting congestion to end stations. A solution that prevents router queues from filling up while reducing the packet drop rate is called dynamic queue management.
3.2. Random elimination method – RED
3.2.1 Overview
RED (Random Early Detection of congestion; Random Early Drop) is one of the first AQM algorithms proposed in 1993 by Sally Floyd and Van Jacobson, two scientists at the Lawrence Berkeley Laboratory of the University of California, USA. Due to its outstanding advantages compared to previous queue management algorithms, RED has been widely installed and deployed on the Internet.
The most fundamental point of their work is that the most effective place to detect congestion and react to it is at the gateway or router.
Source entities (senders) can also do this by estimating end-to-end delay, throughput variability, or the rate of packet retransmissions due to drop. However, the sender and receiver view of a particular connection cannot tell which gateways on the network are congested, and cannot distinguish between propagation delay and queuing delay. Only the gateway has a true view of the state of the queue, the link share of the connections passing through it at any given time, and the quality of service requirements of the
traffic flows. The RED gateway monitors the average queue length, which detects early signs of impending congestion (average queue length exceeding a predetermined threshold) and reacts appropriately in one of two ways:
− Drop incoming packets with a certain probability, to indirectly inform the source of congestion, the source needs to reduce the transmission rate to keep the queue from filling up, maintaining the ability to absorb incoming traffic spikes.
− Mark “congestion” with a certain probability in the ECN field in the header of TCP packets to notify the source (the receiving entity will copy this bit into the acknowledgement packet).
Figure 3. 1 RED algorithm
The main goal of RED is to avoid congestion by keeping the average queue size within a sufficiently small and stable region, which also means keeping the queuing delay sufficiently small and stable. Achieving this goal also helps: avoid global synchronization, not resist bursty traffic flows (i.e. flows with low average throughput but high volatility), and maintain an upper bound on the average queue size even in the absence of cooperation from transport layer protocols.
To achieve the above goals, RED gateways must do the following:
− The first is to detect congestion early and react appropriately to keep the average queue size small enough to keep the network operating in the low latency, high throughput region, while still allowing the queue size to fluctuate within a certain range to absorb short-term fluctuations. As discussed above, the gateway is the most appropriate place to detect congestion and is also the most appropriate place to decide which specific connection to report congestion to.
− The second thing is to notify the source of congestion. This is done by marking and notifying the source to reduce traffic. Normally the RED gateway will randomly drop packets. However, if congestion
If congestion is detected before the queue is full, it should be combined with packet marking to signal congestion. The RED gateway has two options: drop or mark; where marking is done by marking the ECN field of the packet with a certain probability, to signal the source to reduce the traffic entering the network.
− An important goal that RED gateways need to achieve is to avoid global synchronization and not to resist traffic flows that have a sudden characteristic. Global synchronization occurs when all connections simultaneously reduce their transmission window size, leading to a severe drop in throughput at the same time. On the other hand, Drop Tail or Random Drop strategies are very sensitive to sudden flows; that is, the gateway queue will often overflow when packets from these flows arrive. To avoid these two phenomena, gateways can use special algorithms to detect congestion and decide which connections will be notified of congestion at the gateway. The RED gateway randomly selects incoming packets to mark; with this method, the probability of marking a packet from a particular connection is proportional to the connection's shared bandwidth at the gateway.
− Another goal is to control the average queue size even without cooperation from the source entities. This can be done by dropping packets when the average size exceeds an upper threshold (instead of marking it). This approach is necessary in cases where most connections have transmission times that are less than the round-trip time, or where the source entities are not able to reduce traffic in response to marking or dropping packets (such as UDP flows).
3.2.2 Algorithm
This section describes the algorithm for RED gateways. RED gateways calculate the average queue size using a low-pass filter. This average queue size is compared with two thresholds: minth and maxth. When the average queue size is less than the lower threshold, no incoming packets are marked or dropped; when the average queue size is greater than the upper threshold, all incoming packets are dropped. When the average queue size is between minth and maxth, each incoming packet is marked or dropped with a probability pa, where pa is a function of the average queue size avg; the probability of marking or dropping a packet for a particular connection is proportional to the bandwidth share of that connection at the gateway. The general algorithm for a RED gateway is described as follows: [5]
For each packet arrival
Caculate the average queue size avg If minth ≤ avg < maxth
div.maincontent .s1 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 15pt; }
div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s7 { color: black; font-family:Wingdings; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s8 { color: black; font-family:Arial, sans-serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 15pt; }
div.maincontent .s9 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s10 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 6pt; }
div.maincontent .s11 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s12 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; }
div.maincontent .s13 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-d -
![Pre-tax Profit of Bidv Tien Giang in the Period 2011-2015
zt2i3t4l5ee
zt2a3gsnon-credit services, joint stock commercial bank
zt2a3ge
zc2o3n4t5e6n7ts
At that time, the Branch had to set aside a provision for credit risks, which reduced the Branchs income.
Chart 2.2. Pre-tax profit of BIDV Tien Giang in the period 2011-2015
Unit: Billion VND
140
120
100
80
60
40
20
0
63.3
80.34
89.29
110.08
131.99
2011 2012 2013 2014 2015
Profit before tax
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
However, through chart 2.2, it can be seen that BIDV Tien Giangs profit is still increasing continuously, and its operating efficiency is currently leaking. This is a contribution of non-credit services, and this service segment will be increasingly focused on growth by BIDV Tien Giang to ensure the highest profit safety because credit activities have many potential risks. At the same time, focusing on developing non-credit services is consistent with one of the contents of restructuring the financial activities of credit institutions in the project Restructuring the system of credit institutions in the period 2011-2015 approved by the Prime Minister in Decision No. 254/QD-TTg dated March 1, 2012 [14]: Gradually shifting the business model of commercial banks towards reducing dependence on credit activities and increasing income from non-credit services.
2.2. Current status of non-credit service development at BIDV Tien Giang.
2.2.1. BIDV Tien Giang has deployed the development of non-credit services in recent times.
Along with the development of the Head Office, BIDV Tien Giangs products and services are constantly improved and deployed in a diverse manner to ensure provision for many different customer groups in the area: individual customers, corporate customers, and financial institutions. Typical services are as follows: Payment services, treasury services, guarantee services, card services, trade finance, other services: Western Union, insurance commissions, consulting services, foreign exchange derivatives trading, e-banking services,...
2.2.1.1. Payment services:
In accordance with the Prime Ministers Project to promote non-cash payments in Vietnam [15], banks in Tien Giang province have continuously developed payment services to reduce customers cash usage habits through card services and electronic banking services such as: salary payment through accounts, focusing on developing card acceptance points, developing multi-purpose cards, paying social insurance by transfer, paying bills through banks, etc.
Chart 2.3. Net income from payment services in the period 2011-2015
Unit: Million VND
6000
5000
4000
3000
2000
1000
0
3922 4065
4720 5084 5324
2011 2012 2013 2014 2015
Net income from payment services
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
Along with the technological development of the entire system, BIDV Tien Giang has a payment system with a fairly stable transaction processing speed, bringing many conveniences to customers. The results of observing chart 2.3 show that the income from payment services that the Branch has achieved has grown over the years but the speed is not high and the products are not outstanding compared to other banks. Domestic payment products such as: Online bill payment, electricity bills, water bills, insurance premiums, cable TV bills, telecommunications fees, airline tickets, etc. bring many conveniences to customers. Regarding international payment, this is an indispensable activity for foreign economic activities, BIDV Tien Giang is providing international payment methods for small enterprises producing agriculture, aquatic food and seafood that have credit relationships with banks in industrial parks in Tien Giang province such as: money transfer, collection, L/C payment.
2.2.1.2. Treasury services:
BIDV Tien Giang always focuses on ensuring treasury safety and currency security, always complies with legal regulations, and minimizes risks in operations such as: counting and collecting money from customers, receiving and delivering internal transactions, collecting from the State Bank (SBV) or other credit institutions, receiving ATM funds, bundling money, etc. BIDV Tien Giangs treasury service management department is always fully equipped with modern machinery and equipment such as: money transport vehicles, fire prevention tools, money counters, money detectors, magnifying glasses, etc. to ensure absolute safety in treasury operations, immediately identifying real and fake money and other risks that may affect people and assets of the bank and customers. In addition, implementing regulation 2480/QC dated October 28, 2008 between the State Bank of Tien Giang province and the Provincial Police on coordination in the fight against counterfeit money, in the 3-year review of implementation, BIDV Tien Giang discovered, seized and submitted to the State Bank of Tien Giang province 475 banknotes of various denominations and was commended by the Provincial Police and the State Bank of Tien Giang province [17].
Chart 2.4. Net income from treasury services in the period 2011-2015
Unit: Million VND
350
300
250
200
150
100
50
0
105 122
309 289 279
2011 2012 2013 2014 2015
Net income from treasury services
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
However, as shown in Figure 2.4, income from treasury operations is not high and fluctuates. Specifically, in the period 2011-2013, net income increased and increased most sharply in 2013, then in the period 2013-2015, there was a downward trend. This fluctuation is due to the fact that fees collected from treasury services are often very low and can even be waived to attract customers to use other services.
2.2.1.3. Guarantee and trade finance services:
BIDV Tien Giang, thanks to the advantages of the province and the favorable location of the Branch, has continuously focused on developing income from guarantee services and trade finance.
Chart 2.5. Net income from guarantee and trade finance services in the period 2011-2015
Unit: Million VND
14000
12000
10000
8000
6000
4000
2000
0
5193 5695
2742 3420
8889
3992
11604 12206
5143 5312
2011 2012 2013 2014 2015
Net income from guarantee services Net income from Trade Finance
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
Through chart 2.5, we can see that BIDV Tien Giangs income from guarantee services and trade finance has grown over the years. The reason is: Among BIDV Tien Giangs corporate customers, the construction industry is the industry with the highest proportion of customers after the trading industry, this is a group of customers with potential to develop guarantee services. The second group of customers is corporate customers in the fields of agricultural production, livestock and seafood processing with high import and export turnover in the area.
are the target of trade finance development. In addition, BIDV Tien Giang also focuses on continuously developing these customer groups to increase revenue for many other products and services in the future.
2.2.1.4. Card and POS services:
As a service that BIDV Tien Giang has recently developed strongly, it can be said that this is a very potential market and has the ability to develop even more strongly in the future. Card services with outstanding advantages such as fast payment time, wide payment range, quite safe, effective and suitable for the integration trend and the Project to promote non-cash payments in Vietnam. Cards have become a modern and popular payment tool. BIDV Tien Giang early identified that developing card services is to expand the market to people in society, create capital mobilized from card-opened accounts, contribute to diversifying banking activities, enhance the image of the bank, bring the BIDV Tien Giang brand to people as quickly and easily as possible. BIDV Tien Giang is currently providing card types such as: credit cards (BIDV MasterCard Platinum, BIDV Visa Gold Precious, BIDV Visa Manchester United, BIDV Visa Classic), international debit cards (BIDV Ready Card, BIDV Manu Debit Card), domestic debit cards (BIDV Harmony Card, BIDV eTrans Card, BIDV Moving Card, BIDV-Lingo Co-branded Card, BIDV-Co.opmart Co-branded Card). These cards can be paid via POS/EDC or on the ATM system. In addition, with debit cards, customers can not only withdraw money via ATMs but also perform utilities such as mobile top-up, online payment, money transfer,... through electronic banking services.
In order to attract customers with card services, BIDV Tien Giang has continuously increased the installation of ATMs. As of December 31, 2015, BIDV Tien Giang has 23 ATMs combined with 7 ATMs in the same system of BIDV My Tho, so the number of ATMs is quite large, especially in the center of My Tho City, but is not yet fully present in the districts. Basic services on ATMs such as withdrawing money, checking balances, printing short statements,... BIDV ATMs accept cards from banks in the system.
Banknetvn and Smartlink, cards branded by international card organizations Union Pay (CUP), VISA, MasterCard and cards of banks in the Asian Payment Network. From here, cardholders can make bill payments for themselves or others at ATMs, by simply entering the subscriber number or customer code, booking code that service providers notify and make bill payments.
Chart 2.6. Net income from card services in the period 2011-2015
Unit: Million VND
3500
3000
2500
2000
1500
1000
500
0
687
1023
1547
2267
3104
2011 2012 2013 2014 2015
Net income from card services
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
Through chart 2.6, it can be seen that BIDV Tien Giangs card service income is constantly growing because the Branch focuses on developing businesses operating in industrial parks, which are the source of customers for salary payment products, ATMs, BSMS. Specifically, there are companies such as Freeview, Quang Viet, Dai Thanh, which are businesses with a large number of card openings at the Branch, contributing to the increase in card service fees [25].
Table 2.6. Number of ATMs and POS machines in 2015 of some banks in Tien Giang area.
Unit: Machine
STT
Bank name
Number of ATMs
Cumulative number of ATM cards
POS machine
1
BIDV Tien Giang
23
97,095
22
2
BIDV My Tho
7
21,325
0
3
Agribank Tien Giang
29
115,743
77
4
Vietinbank Tien Giang
16
100,052
54
5
Dong A Tien Giang
26
97,536
11
6
Sacombank Tien Giang
24
88,513
27
7
Vietcombank Tien Giang
15
61,607
96
8
Vietinbank - Tay Tien Giang Branch
6
46,042
38
(Source: 2015 Banking Activity Data Report of the General and Internal Control Department of the Provincial State Bank [21])
Through table 2.6, the author finds that the number of ATMs of BIDV Tien Giang is not much, ranking fourth after Agribank Tien Giang, Dong A Tien Giang, Sacombank Tien Giang. The number of POS machines of BIDV Tien Giang is very small, only higher than Dong A Tien Giang and BIDV My Tho in the initial stages of merging the BIDV system. Besides, BIDV Tien Giang has a high number of cards increasing over the years (table 2.7) but the cumulative number of cards issued up to December 31, 2015 is still relatively low compared to Agribank, Vietcombank, Dong A (table 2.6).
div.maincontent .content_head3 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent p { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent .s1 { color: black; font-family:Courier New, monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s2 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s3 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s4 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s5 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s6 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s7 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13.5pt; }
div.maincontent .s8 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; }
div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -2pt; }
div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 5pt; }
div.maincontent .s11 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -5pt; }
div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -3pt; }
div.maincontent .s13 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -4pt; }
div.maincontent .s14 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7.5pt; }
div.maincontent .s15 { color: black; font-family:Times New Roman, serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s16 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s17 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; }
div.maincontent .s18 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -1pt; }
div.maincontent .s19 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -5pt; }
div.maincontent .s20 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -2pt; }
div.maincontent .s21 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; }
div.maincontent .s22 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s23 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -3pt; }
div.maincontent .s24 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -5pt; }
div.maincontent .s25 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s26 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -4pt; }
div.maincontent .s27 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -6pt; }
div.maincontent .s28 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -1pt; }
div.maincontent .s29 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11.5pt; }
div.maincontent .s30 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; }
div.maincontent .s31 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; }
div.maincontent .s32 { color: black; font-family:.VnTime, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s33 { color: black; font-family:Cambria, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s34 { color: black; font-family:Cambria, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -4pt; }
div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11.5pt; }
div.maincontent .s36 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s37 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; }
div.maincontent .s38 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s39 { color: black; font-family:Times New Roman, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 15pt; }
div.maincontent .s40 { color: black; font-family:Times New Roman, serif; font-style: normal; fo](https://tailieuthamkhao.com/uploads/2022/06/06/dich-vu-phi-tin-dung-tai-ngan-hang-thuong-mai-co-phan-dau-tu-va-phat-8-1-120x90.png) Pre-tax Profit of Bidv Tien Giang in the Period 2011-2015
zt2i3t4l5ee
zt2a3gsnon-credit services, joint stock commercial bank
zt2a3ge
zc2o3n4t5e6n7ts
At that time, the Branch had to set aside a provision for credit risks, which reduced the Branch's income.
Chart 2.2. Pre-tax profit of BIDV Tien Giang in the period 2011-2015
Unit: Billion VND
140
120
100
80
60
40
20
0
63.3
80.34
89.29
110.08
131.99
2011 2012 2013 2014 2015
Profit before tax
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
However, through chart 2.2, it can be seen that BIDV Tien Giang's profit is still increasing continuously, and its operating efficiency is currently leaking. This is a contribution of non-credit services, and this service segment will be increasingly focused on growth by BIDV Tien Giang to ensure the highest profit safety because credit activities have many potential risks. At the same time, focusing on developing non-credit services is consistent with one of the contents of restructuring the financial activities of credit institutions in the project "Restructuring the system of credit institutions in the period 2011-2015" approved by the Prime Minister in Decision No. 254/QD-TTg dated March 1, 2012 [14]: "Gradually shifting the business model of commercial banks towards reducing dependence on credit activities and increasing income from non-credit services".
2.2. Current status of non-credit service development at BIDV Tien Giang.
2.2.1. BIDV Tien Giang has deployed the development of non-credit services in recent times.
Along with the development of the Head Office, BIDV Tien Giang's products and services are constantly improved and deployed in a diverse manner to ensure provision for many different customer groups in the area: individual customers, corporate customers, and financial institutions. Typical services are as follows: Payment services, treasury services, guarantee services, card services, trade finance, other services: Western Union, insurance commissions, consulting services, foreign exchange derivatives trading, e-banking services,...
2.2.1.1. Payment services:
In accordance with the Prime Minister's Project to promote non-cash payments in Vietnam [15], banks in Tien Giang province have continuously developed payment services to reduce customers' cash usage habits through card services and electronic banking services such as: salary payment through accounts, focusing on developing card acceptance points, developing multi-purpose cards, paying social insurance by transfer, paying bills through banks, etc.
Chart 2.3. Net income from payment services in the period 2011-2015
Unit: Million VND
6000
5000
4000
3000
2000
1000
0
3922 4065
4720 5084 5324
2011 2012 2013 2014 2015
Net income from payment services
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
Along with the technological development of the entire system, BIDV Tien Giang has a payment system with a fairly stable transaction processing speed, bringing many conveniences to customers. The results of observing chart 2.3 show that the income from payment services that the Branch has achieved has grown over the years but the speed is not high and the products are not outstanding compared to other banks. Domestic payment products such as: Online bill payment, electricity bills, water bills, insurance premiums, cable TV bills, telecommunications fees, airline tickets, etc. bring many conveniences to customers. Regarding international payment, this is an indispensable activity for foreign economic activities, BIDV Tien Giang is providing international payment methods for small enterprises producing agriculture, aquatic food and seafood that have credit relationships with banks in industrial parks in Tien Giang province such as: money transfer, collection, L/C payment.
2.2.1.2. Treasury services:
BIDV Tien Giang always focuses on ensuring treasury safety and currency security, always complies with legal regulations, and minimizes risks in operations such as: counting and collecting money from customers, receiving and delivering internal transactions, collecting from the State Bank (SBV) or other credit institutions, receiving ATM funds, bundling money, etc. BIDV Tien Giang's treasury service management department is always fully equipped with modern machinery and equipment such as: money transport vehicles, fire prevention tools, money counters, money detectors, magnifying glasses, etc. to ensure absolute safety in treasury operations, immediately identifying real and fake money and other risks that may affect people and assets of the bank and customers. In addition, implementing regulation 2480/QC dated October 28, 2008 between the State Bank of Tien Giang province and the Provincial Police on coordination in the fight against counterfeit money, in the 3-year review of implementation, BIDV Tien Giang discovered, seized and submitted to the State Bank of Tien Giang province 475 banknotes of various denominations and was commended by the Provincial Police and the State Bank of Tien Giang province [17].
Chart 2.4. Net income from treasury services in the period 2011-2015
Unit: Million VND
350
300
250
200
150
100
50
0
105 122
309 289 279
2011 2012 2013 2014 2015
Net income from treasury services
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
However, as shown in Figure 2.4, income from treasury operations is not high and fluctuates. Specifically, in the period 2011-2013, net income increased and increased most sharply in 2013, then in the period 2013-2015, there was a downward trend. This fluctuation is due to the fact that fees collected from treasury services are often very low and can even be waived to attract customers to use other services.
2.2.1.3. Guarantee and trade finance services:
BIDV Tien Giang, thanks to the advantages of the province and the favorable location of the Branch, has continuously focused on developing income from guarantee services and trade finance.
Chart 2.5. Net income from guarantee and trade finance services in the period 2011-2015
Unit: Million VND
14000
12000
10000
8000
6000
4000
2000
0
5193 5695
2742 3420
8889
3992
11604 12206
5143 5312
2011 2012 2013 2014 2015
Net income from guarantee services Net income from Trade Finance
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
Through chart 2.5, we can see that BIDV Tien Giang's income from guarantee services and trade finance has grown over the years. The reason is: Among BIDV Tien Giang's corporate customers, the construction industry is the industry with the highest proportion of customers after the trading industry, this is a group of customers with potential to develop guarantee services. The second group of customers is corporate customers in the fields of agricultural production, livestock and seafood processing with high import and export turnover in the area.
are the target of trade finance development. In addition, BIDV Tien Giang also focuses on continuously developing these customer groups to increase revenue for many other products and services in the future.
2.2.1.4. Card and POS services:
As a service that BIDV Tien Giang has recently developed strongly, it can be said that this is a very potential market and has the ability to develop even more strongly in the future. Card services with outstanding advantages such as fast payment time, wide payment range, quite safe, effective and suitable for the integration trend and the Project to promote non-cash payments in Vietnam. Cards have become a modern and popular payment tool. BIDV Tien Giang early identified that developing card services is to expand the market to people in society, create capital mobilized from card-opened accounts, contribute to diversifying banking activities, enhance the image of the bank, bring the BIDV Tien Giang brand to people as quickly and easily as possible. BIDV Tien Giang is currently providing card types such as: credit cards (BIDV MasterCard Platinum, BIDV Visa Gold Precious, BIDV Visa Manchester United, BIDV Visa Classic), international debit cards (BIDV Ready Card, BIDV Manu Debit Card), domestic debit cards (BIDV Harmony Card, BIDV eTrans Card, BIDV Moving Card, BIDV-Lingo Co-branded Card, BIDV-Co.opmart Co-branded Card). These cards can be paid via POS/EDC or on the ATM system. In addition, with debit cards, customers can not only withdraw money via ATMs but also perform utilities such as mobile top-up, online payment, money transfer,... through electronic banking services.
In order to attract customers with card services, BIDV Tien Giang has continuously increased the installation of ATMs. As of December 31, 2015, BIDV Tien Giang has 23 ATMs combined with 7 ATMs in the same system of BIDV My Tho, so the number of ATMs is quite large, especially in the center of My Tho City, but is not yet fully present in the districts. Basic services on ATMs such as withdrawing money, checking balances, printing short statements,... BIDV ATMs accept cards from banks in the system.
Banknetvn and Smartlink, cards branded by international card organizations Union Pay (CUP), VISA, MasterCard and cards of banks in the Asian Payment Network. From here, cardholders can make bill payments for themselves or others at ATMs, by simply entering the subscriber number or customer code, booking code that service providers notify and make bill payments.
Chart 2.6. Net income from card services in the period 2011-2015
Unit: Million VND
3500
3000
2500
2000
1500
1000
500
0
687
1023
1547
2267
3104
2011 2012 2013 2014 2015
Net income from card services
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
Through chart 2.6, it can be seen that BIDV Tien Giang's card service income is constantly growing because the Branch focuses on developing businesses operating in industrial parks, which are the source of customers for salary payment products, ATMs, BSMS. Specifically, there are companies such as Freeview, Quang Viet, Dai Thanh, which are businesses with a large number of card openings at the Branch, contributing to the increase in card service fees [25].
Table 2.6. Number of ATMs and POS machines in 2015 of some banks in Tien Giang area.
Unit: Machine
STT
Bank name
Number of ATMs
Cumulative number of ATM cards
POS machine
1
BIDV Tien Giang
23
97,095
22
2
BIDV My Tho
7
21,325
0
3
Agribank Tien Giang
29
115,743
77
4
Vietinbank Tien Giang
16
100,052
54
5
Dong A Tien Giang
26
97,536
11
6
Sacombank Tien Giang
24
88,513
27
7
Vietcombank Tien Giang
15
61,607
96
8
Vietinbank - Tay Tien Giang Branch
6
46,042
38
(Source: 2015 Banking Activity Data Report of the General and Internal Control Department of the Provincial State Bank [21])
Through table 2.6, the author finds that the number of ATMs of BIDV Tien Giang is not much, ranking fourth after Agribank Tien Giang, Dong A Tien Giang, Sacombank Tien Giang. The number of POS machines of BIDV Tien Giang is very small, only higher than Dong A Tien Giang and BIDV My Tho in the initial stages of merging the BIDV system. Besides, BIDV Tien Giang has a high number of cards increasing over the years (table 2.7) but the cumulative number of cards issued up to December 31, 2015 is still relatively low compared to Agribank, Vietcombank, Dong A (table 2.6).
div.maincontent .content_head3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent .s1 { color: black; font-family:"Courier New", monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13.5pt; }
div.maincontent .s8 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; }
div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -2pt; }
div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 5pt; }
div.maincontent .s11 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -5pt; }
div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -3pt; }
div.maincontent .s13 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -4pt; }
div.maincontent .s14 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7.5pt; }
div.maincontent .s15 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s16 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s17 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; }
div.maincontent .s18 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -1pt; }
div.maincontent .s19 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -5pt; }
div.maincontent .s20 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -2pt; }
div.maincontent .s21 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; }
div.maincontent .s22 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s23 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -3pt; }
div.maincontent .s24 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -5pt; }
div.maincontent .s25 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s26 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -4pt; }
div.maincontent .s27 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -6pt; }
div.maincontent .s28 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -1pt; }
div.maincontent .s29 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11.5pt; }
div.maincontent .s30 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; }
div.maincontent .s31 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; }
div.maincontent .s32 { color: black; font-family:.VnTime, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s33 { color: black; font-family:Cambria, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s34 { color: black; font-family:Cambria, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -4pt; }
div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11.5pt; }
div.maincontent .s36 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s37 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; }
div.maincontent .s38 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s39 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 15pt; }
div.maincontent .s40 { color: black; font-family:"Times New Roman", serif; font-style: normal; fo
Pre-tax Profit of Bidv Tien Giang in the Period 2011-2015
zt2i3t4l5ee
zt2a3gsnon-credit services, joint stock commercial bank
zt2a3ge
zc2o3n4t5e6n7ts
At that time, the Branch had to set aside a provision for credit risks, which reduced the Branch's income.
Chart 2.2. Pre-tax profit of BIDV Tien Giang in the period 2011-2015
Unit: Billion VND
140
120
100
80
60
40
20
0
63.3
80.34
89.29
110.08
131.99
2011 2012 2013 2014 2015
Profit before tax
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
However, through chart 2.2, it can be seen that BIDV Tien Giang's profit is still increasing continuously, and its operating efficiency is currently leaking. This is a contribution of non-credit services, and this service segment will be increasingly focused on growth by BIDV Tien Giang to ensure the highest profit safety because credit activities have many potential risks. At the same time, focusing on developing non-credit services is consistent with one of the contents of restructuring the financial activities of credit institutions in the project "Restructuring the system of credit institutions in the period 2011-2015" approved by the Prime Minister in Decision No. 254/QD-TTg dated March 1, 2012 [14]: "Gradually shifting the business model of commercial banks towards reducing dependence on credit activities and increasing income from non-credit services".
2.2. Current status of non-credit service development at BIDV Tien Giang.
2.2.1. BIDV Tien Giang has deployed the development of non-credit services in recent times.
Along with the development of the Head Office, BIDV Tien Giang's products and services are constantly improved and deployed in a diverse manner to ensure provision for many different customer groups in the area: individual customers, corporate customers, and financial institutions. Typical services are as follows: Payment services, treasury services, guarantee services, card services, trade finance, other services: Western Union, insurance commissions, consulting services, foreign exchange derivatives trading, e-banking services,...
2.2.1.1. Payment services:
In accordance with the Prime Minister's Project to promote non-cash payments in Vietnam [15], banks in Tien Giang province have continuously developed payment services to reduce customers' cash usage habits through card services and electronic banking services such as: salary payment through accounts, focusing on developing card acceptance points, developing multi-purpose cards, paying social insurance by transfer, paying bills through banks, etc.
Chart 2.3. Net income from payment services in the period 2011-2015
Unit: Million VND
6000
5000
4000
3000
2000
1000
0
3922 4065
4720 5084 5324
2011 2012 2013 2014 2015
Net income from payment services
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
Along with the technological development of the entire system, BIDV Tien Giang has a payment system with a fairly stable transaction processing speed, bringing many conveniences to customers. The results of observing chart 2.3 show that the income from payment services that the Branch has achieved has grown over the years but the speed is not high and the products are not outstanding compared to other banks. Domestic payment products such as: Online bill payment, electricity bills, water bills, insurance premiums, cable TV bills, telecommunications fees, airline tickets, etc. bring many conveniences to customers. Regarding international payment, this is an indispensable activity for foreign economic activities, BIDV Tien Giang is providing international payment methods for small enterprises producing agriculture, aquatic food and seafood that have credit relationships with banks in industrial parks in Tien Giang province such as: money transfer, collection, L/C payment.
2.2.1.2. Treasury services:
BIDV Tien Giang always focuses on ensuring treasury safety and currency security, always complies with legal regulations, and minimizes risks in operations such as: counting and collecting money from customers, receiving and delivering internal transactions, collecting from the State Bank (SBV) or other credit institutions, receiving ATM funds, bundling money, etc. BIDV Tien Giang's treasury service management department is always fully equipped with modern machinery and equipment such as: money transport vehicles, fire prevention tools, money counters, money detectors, magnifying glasses, etc. to ensure absolute safety in treasury operations, immediately identifying real and fake money and other risks that may affect people and assets of the bank and customers. In addition, implementing regulation 2480/QC dated October 28, 2008 between the State Bank of Tien Giang province and the Provincial Police on coordination in the fight against counterfeit money, in the 3-year review of implementation, BIDV Tien Giang discovered, seized and submitted to the State Bank of Tien Giang province 475 banknotes of various denominations and was commended by the Provincial Police and the State Bank of Tien Giang province [17].
Chart 2.4. Net income from treasury services in the period 2011-2015
Unit: Million VND
350
300
250
200
150
100
50
0
105 122
309 289 279
2011 2012 2013 2014 2015
Net income from treasury services
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
However, as shown in Figure 2.4, income from treasury operations is not high and fluctuates. Specifically, in the period 2011-2013, net income increased and increased most sharply in 2013, then in the period 2013-2015, there was a downward trend. This fluctuation is due to the fact that fees collected from treasury services are often very low and can even be waived to attract customers to use other services.
2.2.1.3. Guarantee and trade finance services:
BIDV Tien Giang, thanks to the advantages of the province and the favorable location of the Branch, has continuously focused on developing income from guarantee services and trade finance.
Chart 2.5. Net income from guarantee and trade finance services in the period 2011-2015
Unit: Million VND
14000
12000
10000
8000
6000
4000
2000
0
5193 5695
2742 3420
8889
3992
11604 12206
5143 5312
2011 2012 2013 2014 2015
Net income from guarantee services Net income from Trade Finance
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
Through chart 2.5, we can see that BIDV Tien Giang's income from guarantee services and trade finance has grown over the years. The reason is: Among BIDV Tien Giang's corporate customers, the construction industry is the industry with the highest proportion of customers after the trading industry, this is a group of customers with potential to develop guarantee services. The second group of customers is corporate customers in the fields of agricultural production, livestock and seafood processing with high import and export turnover in the area.
are the target of trade finance development. In addition, BIDV Tien Giang also focuses on continuously developing these customer groups to increase revenue for many other products and services in the future.
2.2.1.4. Card and POS services:
As a service that BIDV Tien Giang has recently developed strongly, it can be said that this is a very potential market and has the ability to develop even more strongly in the future. Card services with outstanding advantages such as fast payment time, wide payment range, quite safe, effective and suitable for the integration trend and the Project to promote non-cash payments in Vietnam. Cards have become a modern and popular payment tool. BIDV Tien Giang early identified that developing card services is to expand the market to people in society, create capital mobilized from card-opened accounts, contribute to diversifying banking activities, enhance the image of the bank, bring the BIDV Tien Giang brand to people as quickly and easily as possible. BIDV Tien Giang is currently providing card types such as: credit cards (BIDV MasterCard Platinum, BIDV Visa Gold Precious, BIDV Visa Manchester United, BIDV Visa Classic), international debit cards (BIDV Ready Card, BIDV Manu Debit Card), domestic debit cards (BIDV Harmony Card, BIDV eTrans Card, BIDV Moving Card, BIDV-Lingo Co-branded Card, BIDV-Co.opmart Co-branded Card). These cards can be paid via POS/EDC or on the ATM system. In addition, with debit cards, customers can not only withdraw money via ATMs but also perform utilities such as mobile top-up, online payment, money transfer,... through electronic banking services.
In order to attract customers with card services, BIDV Tien Giang has continuously increased the installation of ATMs. As of December 31, 2015, BIDV Tien Giang has 23 ATMs combined with 7 ATMs in the same system of BIDV My Tho, so the number of ATMs is quite large, especially in the center of My Tho City, but is not yet fully present in the districts. Basic services on ATMs such as withdrawing money, checking balances, printing short statements,... BIDV ATMs accept cards from banks in the system.
Banknetvn and Smartlink, cards branded by international card organizations Union Pay (CUP), VISA, MasterCard and cards of banks in the Asian Payment Network. From here, cardholders can make bill payments for themselves or others at ATMs, by simply entering the subscriber number or customer code, booking code that service providers notify and make bill payments.
Chart 2.6. Net income from card services in the period 2011-2015
Unit: Million VND
3500
3000
2500
2000
1500
1000
500
0
687
1023
1547
2267
3104
2011 2012 2013 2014 2015
Net income from card services
(Source: Report on the implementation of the annual business plan of the General Planning Department of BIDV Tien Giang [24])
Through chart 2.6, it can be seen that BIDV Tien Giang's card service income is constantly growing because the Branch focuses on developing businesses operating in industrial parks, which are the source of customers for salary payment products, ATMs, BSMS. Specifically, there are companies such as Freeview, Quang Viet, Dai Thanh, which are businesses with a large number of card openings at the Branch, contributing to the increase in card service fees [25].
Table 2.6. Number of ATMs and POS machines in 2015 of some banks in Tien Giang area.
Unit: Machine
STT
Bank name
Number of ATMs
Cumulative number of ATM cards
POS machine
1
BIDV Tien Giang
23
97,095
22
2
BIDV My Tho
7
21,325
0
3
Agribank Tien Giang
29
115,743
77
4
Vietinbank Tien Giang
16
100,052
54
5
Dong A Tien Giang
26
97,536
11
6
Sacombank Tien Giang
24
88,513
27
7
Vietcombank Tien Giang
15
61,607
96
8
Vietinbank - Tay Tien Giang Branch
6
46,042
38
(Source: 2015 Banking Activity Data Report of the General and Internal Control Department of the Provincial State Bank [21])
Through table 2.6, the author finds that the number of ATMs of BIDV Tien Giang is not much, ranking fourth after Agribank Tien Giang, Dong A Tien Giang, Sacombank Tien Giang. The number of POS machines of BIDV Tien Giang is very small, only higher than Dong A Tien Giang and BIDV My Tho in the initial stages of merging the BIDV system. Besides, BIDV Tien Giang has a high number of cards increasing over the years (table 2.7) but the cumulative number of cards issued up to December 31, 2015 is still relatively low compared to Agribank, Vietcombank, Dong A (table 2.6).
div.maincontent .content_head3 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent p { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; margin:0pt; }
div.maincontent .s1 { color: black; font-family:"Courier New", monospace; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s2 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s3 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s4 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s5 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s6 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s7 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13.5pt; }
div.maincontent .s8 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; }
div.maincontent .s9 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -2pt; }
div.maincontent .s10 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: 5pt; }
div.maincontent .s11 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -5pt; }
div.maincontent .s12 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -3pt; }
div.maincontent .s13 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9pt; vertical-align: -4pt; }
div.maincontent .s14 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 7.5pt; }
div.maincontent .s15 { color: black; font-family:"Times New Roman", serif; font-style: italic; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s16 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s17 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 9.5pt; }
div.maincontent .s18 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -1pt; }
div.maincontent .s19 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -5pt; }
div.maincontent .s20 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -2pt; }
div.maincontent .s21 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10pt; }
div.maincontent .s22 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s23 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -3pt; }
div.maincontent .s24 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -5pt; }
div.maincontent .s25 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s26 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -4pt; }
div.maincontent .s27 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -6pt; }
div.maincontent .s28 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -1pt; }
div.maincontent .s29 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11.5pt; }
div.maincontent .s30 { color: black; font-family:Calibri, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; }
div.maincontent .s31 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11pt; }
div.maincontent .s32 { color: black; font-family:.VnTime, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 14pt; }
div.maincontent .s33 { color: black; font-family:Cambria, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; }
div.maincontent .s34 { color: black; font-family:Cambria, serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 10.5pt; vertical-align: -4pt; }
div.maincontent .s35 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 11.5pt; }
div.maincontent .s36 { color: black; font-family:Arial, sans-serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 14pt; }
div.maincontent .s37 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: bold; text-decoration: none; font-size: 13pt; }
div.maincontent .s38 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 13pt; }
div.maincontent .s39 { color: black; font-family:"Times New Roman", serif; font-style: normal; font-weight: normal; text-decoration: none; font-size: 15pt; }
div.maincontent .s40 { color: black; font-family:"Times New Roman", serif; font-style: normal; fo -
 Summary of Sem Linear Structural Model Data
Summary of Sem Linear Structural Model Data -
 Initial Research Model on Factors Affecting the Internal Control System on Social Insurance Collection
Initial Research Model on Factors Affecting the Internal Control System on Social Insurance Collection -
 Credit Rating Levels of Developed Economies in the 2013 - 2015 Research Data Sample
Credit Rating Levels of Developed Economies in the 2013 - 2015 Research Data Sample
Table 1: Experimental crawl conditions
We run this program on two environments as described below.
The time results are saved to a log file for comparison and evaluation.
5.2.3.1 Stand alone
Run the system in Stand alone mode on machine is_aupelf04, hardware configuration as described above.
5.2.3.2 Distributed
Run the system on a Hadoop cluster as follows:
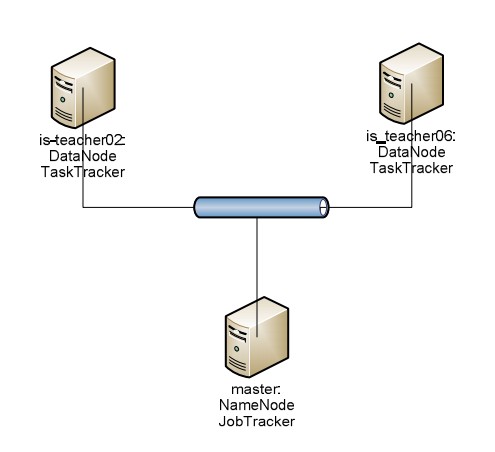
Figure 4-2: Empirical model of distributed crawler
5.2.4 Results
The results of the statistical time of the processes are as follows (Faster times will be italicized):
Implementation process
Stand alone (seconds) (1) | Distributed(seconds) (2) | Ratio % (2)/(1) | |||
Injection | 33 | 180 | 545% | ||
Crawl Loop | Dept=1 | Generate | 54 | 256 | 474% |
Fetch | 150 | 345 | 230% | ||
(Number of URLs=1) | Parse | 210 | 260 | 124% | |
Update DB | 157 | 340 | 217% | ||
Total | 571 | 1201 | 210% | ||
Dept=2 | Generate | 183 | 301 | 164% | |
Fetch | 2112 | 1683 | 80% | ||
(URL Number=149) | Parse | 1385 | 1079 | 78% | |
Update DB | 851 | 902 | 106% | ||
Total | 4531 | 3965 | 88% | ||
Dept=3 | Generate | 2095 | 1982 | 95% | |
Fetch | 27365 | 18910 | 69% | ||
(URL Number=10390) | Parse | 6307 | 3550 | 56% | |
Update DB | 2381 | 2053 | 86% | ||
Total | 38184 | 26495 | 69% | ||
Invert Link | 2581 | 2275 | 88% | ||
Index | 3307 | 2557 | 77% | ||
Total time | 49171 | 36673 | 75% | ||
Table 2: Statistical results of experimental evaluation of crawling in standalone and Distributed modes.
However, since time measured in seconds is difficult to assess, we will switch to a more intuitive form:
Implementation process
Stand alone (seconds) (1) | Distributed(seconds) (2) | Ratio % (2)/(1) | |||
Injection | 33 seconds | 180 seconds | 545% | ||
Crawl Loop | Dept=1 | Generate | 54 seconds | 256 seconds | 474% |
Fetch | 150 seconds | 345 seconds | 230% | ||
(Number of URLs=1) | Parse | 210 seconds | 260 seconds | 124% | |
Update DB | 157 seconds | 340 seconds | 217% | ||
Total | 571 seconds | 1201 seconds | 210% | ||
Dept=2 | Generate | 183 seconds | 301 seconds | 164% | |
Fetch | 35 minutes | 28 minutes | 80% | ||
(URL Number=149) | Parse | 23 minutes | 18 minutes | 78% | |
Update DB | 14 minutes | 15 minutes | 106% | ||
Total | 1 hour 16 minutes | 1 hour 6 minutes | 88% | ||
Dept=3 | Generate | 35 minutes | 33 minutes | 95% | |
Fetch | 7 hours 36 minutes | 5 hours 15 minutes | 69% | ||
(URL Number=10390) | Parse | 1 hour 45 minutes | 59 minutes | 56% | |
Update DB | 40 minutes | 34 minutes | 86% | ||
Total | 10 hours 36 minutes | 7 hours 22 minutes | 69% | ||
Invert Link | 43 minutes | 38 minutes | 88% | ||
Index | 55 minutes | 41 minutes | 77% | ||
Total time | 12 hours 16 minutes | 10 hours 11 minutes | 75% | ||
Table 3: Statistical results of experimental evaluation of crawling in standalone and Distributed modes – More intuitive
(Note: The results of the experimental process, i.e. the execution times of the stages, are measured in seconds. However, due to the long time period, we have converted them to minutes, hours and rounded off some insignificant fractions where appropriate.)
5.2.5 Evaluation
We see that in stages where the amount of data to be processed is small, the execution time using stand alone is faster than executing on a distributed environment using MapReduce.
When the data to be processed increases, such as when the processing in the crawl loops is at depth=2, depth=3, the processing speed on the distributed system gradually becomes more dominant than the local processing. Typically, when depth=2, the total time to execute the crawl loop of the distributed system is 88% of the local system. When depth=3, the number of URLs to be processed is up to more than 10,000, the speed when performing distributed execution is 69% of the local execution. This is consistent with the theory: MapReduce and HDFS will be more suitable for processing and storing large data blocks.
The total crawling time on a distributed system is 75% of the crawling time on a single machine, demonstrating the benefits of applying distributed computing to Search Engines (crawling and indexing).
5.2.6 Conclusion
The results were not as expected because the amount of data to be processed was still small. If we crawled deeper (increased the depth), the results would probably be better. However, the deeper crawling failed for the following reason: The number of URLs to be processed with depth=4 increased quite a lot. The execution time was extended by a few
days. But after the system has been running for about a day or two, some machines reset (probably due to voltage or loose power cord).
5.3 Experimental search on the index set
5.3.1 Data sample:
Data is obtained from the process of crawling 10 major newspaper websites in Vietnam with a depth of 4.
Number of web pages loaded and indexed: 104000 web pages. Data block size: 2.5 GB
Crawling time (fetch + parse + index): 3 days.
5.3.2 Hardware
Experimental hardware includes:
5.3.3 Implementation method
5.3.3.1 Search locally (stand alone mode):
-teacher02
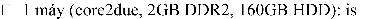
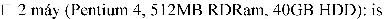
-aupelf04, is-teacher06
The data is placed entirely on the local file system of the machine is-aupelf04.
5.3.3.2 Search on HDFS:
The data is placed on a distributed file system with Namenode configuration: is-aupelf04
Datanodes: is-teacher02, is-teacher06
5.3.3.3 Add data and distribute to Search servers
The data sample is split into two equal, non-intersecting parts (i.e. the two sub-samples do not share any URL) and distributed to two search servers is- teacher02, isteacher06, port 2010.
5.3.4 Query execution result table
Query
Execution time | Rate compared to Local | Number of results | ||||
HDFS | Local | Search server | HDFS | Search server | ||
"human" | 3762 | 398 | 205 | 945 % | 52 | 6503 |
"football" | 5003 | 443 | 411 | 1129 % | 93 | 35258 |
"music" | 1329 | 211 | 194 | 630 % | 92 | 16346 |
"sport"
3137 | 306 | 304 | 1025 % | 99 | 51650 | |
"society" | 1184 | 205 | 200 | 578 % | 98 | 13922 |
"author" | 977 | 233 | 165 | 428 % | 71 | 6431 |
"topic" | 1524 | 168 | 181 | 907 % | 108 | 1908 |
"family" | 1536 | 237 | 272 | 648 % | 115 | 18944 |
"information system" | 8138 | 462 | 391 | 1761 % | 85 | 127 |
"organization" | 4053 | 189 | 193 | 2144 % | 102 | 16649 |
"traffic accident" | 5669 | 221 | 212 | 2565 % | 96 | 1663 |
"love" + "family" | 4672 | 301 | 309 | 1552 % | 103 | 7087 |
"security and order" | 1495 | 197 | 260 | 759 % | 132 | 115 |
"life" | 1211 | 155 | 162 | 781 % | 105 | 5261 |
"cook" | 429 | 81 | 69 | 530 % | 85 | 1584 |
"culture" | 1246 | 163 | 161 | 764 % | 99 | 13167 |
"tourist destination" | 4003 | 456 | 312 | 878 % | 68 | 41 |
"rules" | 958 | 165 | 130 | 581 % | 79 | 209 |
"criminal" | 5038 | 313 | 268 | 1865 % | 86 | 15149 |
"police" | 1959 | 317 | 182 | 618 % | 57 | 3656 |
"traffic safety" | 3915 | 188 | 141 | 2082 % | 75 | 223 |
"food hygiene" | 3129 | 327 | 411 | 957 % | 126 | 130 |
"company" | 1493 | 184 | 131 | 811 % | 71 | 30591 |
"individual" | 1309 | 226 | 173 | 579 % | 77 | 7112 |
"entertainment" | 1970 | 227 | 185 | 868 % | 81 | 22327 |
"children" | 1627 | 198 | 163 | 822 % | 82 | 6071 |
"education" | 4124 | 190 | 96 | 2171 % | 51 | 23190 |
"market moves" concession | 2523 | 177 | 153 | 1425 % | 86 | 1045 |
"image" | 2715 | 200 | 164 | 1358 % | 82 | 1045 |
"star" | 1510 | 233 | 163 | 648 % | 70 | 19515 |
"college entrance exam" | 6442 | 341 | 219 | 1889 % | 64 | 1997 |
"recruitment" | 1440 | 128 | 105 | 1125 % | 82 | 8747 |
"stock market" | 2553 | 138 | 135 | 1850 % | 98 | 722 |
"online game" | 726 | 184 | 186 | 395 % | 101 | 3328 |
Table 4: Query result execution table
5.3.5 Evaluation:
Through the above results, we see that searching on the index set placed on HDFS is completely inappropriate, the execution time is too long (many times longer than the local execution time), just as in theory.
Most queries performed better when executed distributedly than when executed centrally on a single machine, with some queries nearly doubling in speed. However, due to the small size of the dataset, these results are not yet convincing.
Conclusion: Distributing the index and search across Search servers resulted in increased search speed compared to performing on a single machine.
5.4. Conclusion, application and development direction
5.4.1 Results achieved
After the efforts of the past few months, the thesis has achieved the following results:
and models for big data.
on data access control, especially access for data
big.
Hadoop core: HDFS and MapReduce Engine.
5.4.2 Application
apReduce with Hadoop.
- Kis Securities deploys IBM's mid-range data storage drive solution to enhance data storage and processing capabilities.
- ACB Bank builds a modular data center, applying IBM business analysis solutions to process large data blocks.
- Currently, Intel is supporting Da Nang city to deploy solutions related to big data such as turning Da Nang data center into a green data center with cloud computing technology, implementing pilot projects (POC - Proof of concept), in which Intel will preside over POCs on resource management, Intel data center will continue to support Da Nang to establish an open standard data center, connecting all data systems in the area, serving state and business management, developing public services on modern network technology to provide to citizens and organizations.